Subject classification of Chinese scientific literature based on feed shot learning
In recent years, machine learning and deep learning have achieved success in many fields. However, the success of deep learning model depends on a large number of training data. In the real world, some categories have only a small amount of data or a small amount of labeled data, and labeling unlabeled data will consume a lot of time and manpower. On the contrary, humans only need a small amount of data to achieve rapid learning. For example, a junior high school student with normal intelligence, even a primary school student, only needs to learn a small amount of ancient poetry, and can create new ancient poetry according to his own ideas. This is the gap between machine learning and human learning. The concept of feed shot learning is put forward, which helps machine learning to be closer to human thinking.
The feed shot task aims to study how to learn a good generalization model from a small number of supervised training samples, which is of great value in application scenarios where there is little training data or the cost of obtaining supervision data is very high.
1, Data set introduction
Small sample learning evaluation benchmark
FewCLUE is a small sample learning evaluation benchmark customized for Chinese NLP. There are sub datasets for 9 scenarios:
- PRSTMT: Emotional Analysis of e-commerce reviews;
- CSLDCP: discipline classification of Chinese scientific literature;
- TNEWS: news classification;
- IFLYTEK:APP application description topic classification;
- OCNLI: natural language reasoning;
- BUSTM: Dialogue short text matching;
- CHID: idiom reading comprehension;
- CSL: summary judgment keyword discrimination;
- CLUEWSC: pronoun disambiguation
Subject classification data set of Chinese scientific literature
This project is mainly based on CSLDCP: discipline classification data set of Chinese scientific literature in FewCLUE. There are 7979 pieces of data in this data set, including 67 categories of literature. These categories come from 13 categories, ranging from social sciences to natural sciences. The text is the Chinese abstract of the literature.
Data sample
{"content": "Through several years of observation and practice, the cultivation techniques and methods of potted chrysanthemum are preliminarily mastered and summarized, so as to meet people's demand for flower consumption, improve the commodity value of ornamental plants, and provide technical guidance for enterprise production of potted chrysanthemum.",
"label": "Horticulture",
"id": 1770}
{"content": "GPS The accuracy of satellite navigation and positioning largely depends on the distance between stations and satellites(Pseudo range)Measurement error of.The carrier phase smoothing pseudo range is based on ensuring that the loop parameters meet the requirements of dynamic stress error... In this paper, the principle and engineering implementation method of carrier phase smoothing pseudo range are discussed in detail,The simulation is carried out.",
"label": "Aerospace Science and technology",
"id": 979}
Each piece of data has three attributes, ID, sense and label from front to back. Where label label, Positive indicates Positive and Negative indicates Negative.
Data loading
PaddleNLP has built-in FewCLUE data set, which can be directly used for training, evaluation and prediction.
# Install the latest version of PaddleNLP !python -m pip install --upgrade paddlenlp==2.0.2 -i https://mirror.baidu.com/pypi/simple
from paddlenlp.datasets import load_dataset
# By specifying "FewCLUE" and dataset name="csldcp", the csldcp dataset in FewCLUE can be loaded with one click
train_ds, public_test_ds, test_ds = load_dataset("fewclue", name="csldcp", splits=("train_0", "test_public", "test"))
View the first data of training set, verification set and test set:
print(train_ds.data[0])
{'content': 'In order to ensure that the engine has the best ignition advance angle at different speeds,At the same time, the anti-theft ability of motorcycle is improved,An ignition advance angle and anti-theft control method based on speed matching is proposed.Calculation of engine speed using magneto pulse,The line generator adjusts the trigger delay time of the ignition signal,The precise control of ignition advance angle is realized.According to the speed information,combination GSM and GPS Remote ignition enable control of igniter,A digital igniter is designed to track and locate the motorcycle,The software and hardware structure and detailed design of the igniter are given.Bench test and road test show that the designed digital igniter based on engine speed has accurate ignition advance angle control,Good ignition performance,Strong anti-theft ability, fan Weiguang.', 'label': 'Control science and Engineering', 'id': 805}
print(public_test_ds.data[0])
{'content': 'Five stars in the east of Heilongjiang Province Cu-Ni-Pt-Pd The ore body of the deposit and the mafic complex related to mineralization PGE-Au And the geochemical characteristics of iron group and copper loving elements show that:They are all at a loss Cr,IPGE And enrichment Ni,Co,Cu,Pt and Pd(Pt<Pd)Characterized by,Mafic rocks related to mineralization come from basaltic magma formed by partial melting of mantle,Magma(room)The evolution is mainly crystal separation,Concomitant dissociation.Combined with geological and petrographic characteristics,It is preliminarily determined that copper nickel sulfide mineralization is produced on the basis of magmatic detachment,Platinum palladium mineralization mainly occurred after magmatic stage,Mainly produced by hydrothermal metasomatism.therefore,Wuxing deposit is an endogenetic deposit of magmatic copper nickel sulfide and platinum palladium hydrothermal type.', 'label': 'geology/Geological resources and geological engineering', 'id': 0}
print(test_ds.data[0])
{'id': 0, 'content': 'Jinshan gold deposit is a large epithermal gold deposit in Western Tianshan, China,The occurrence of ore body is mainly controlled by various fault structures.Based on years of exploration work,Through field mapping and a large number of exploration line profile analysis,The author summarizes that the fault tectonic activity has experienced three stages: pre mineralization, hydrothermal mineralization and post mineralization.The basic law of fault ore control is:The NW trending fault generally controls the distribution position of the deposit,The late activity of North-South trending faults resulted in superimposed enrichment and mineralization,The early stage of NE trending faults was accompanied by intermediate acid dyke activity,The post metallogenic activities cause the ore body to break and rise and fall,East west direction-The early stage of NW fault was accompanied by volcanic eruption,After mineralization, the activity cuts off the North-South ore body.At the same time, the prospecting evaluation criteria of the mining area are summarized.'}
2, Build a small sample learner through entry
Thesis address: Entailment as Few-Shot Learner
Large pre training language models (LMs) have shown extraordinary ability as small sample learners. However, their success largely depends on the improvement of model parameters, which makes their training, deployment and service challenging.
In entry as feed shot learner, the author proposes a new method called EFL (entry as feed shot learner), which can turn a small language model into a better small sample learner. The key idea of this method is to rephrase the potential NLP task as an entry task, and then fine tune the model with only 8 examples.
The EFL method can:
- Naturally combined with the data enhancement method based on unsupervised comparative learning;
- It is easy to extend to multi language small sample learning.
The systematic evaluation of 18 standard NLP tasks shows that this method improves the existing SOTA probability learning methods by 12% and produces small sample performance competitive with 500 times larger models (such as GPT-3).
At the beginning, I didn't quite understand entertainment. I looked at the training source code of EFL:
model = ppnlp.transformers.ErnieForSequenceClassification.from_pretrained('ernie-1.0', num_classes=2)
The source code of ErnieForSequenceClassification is PaddleNLP/paddlenlp/transformers/ernie/modeling.py. The details are as follows:
class ErnieForSequenceClassification(ErniePretrainedModel):
def __init__(self, ernie, num_classes=2, dropout=None):
super(ErnieForSequenceClassification, self).__init__()
self.num_classes = num_classes
self.ernie = ernie # allow ernie to be config
self.dropout = nn.Dropout(dropout if dropout is not None else
self.ernie.config["hidden_dropout_prob"])
self.classifier = nn.Linear(self.ernie.config["hidden_size"],
num_classes)
self.apply(self.init_weights)
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
_, pooled_output = self.ernie(
input_ids,
token_type_ids=token_type_ids,
position_ids=position_ids,
attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
It can be seen from the code that the core content is Ernie, and then a full connection layer, num, is added at the end_ Classes = 2, that is, EFL uniformly converts NLP fine tune tasks into entry 2 classification tasks.
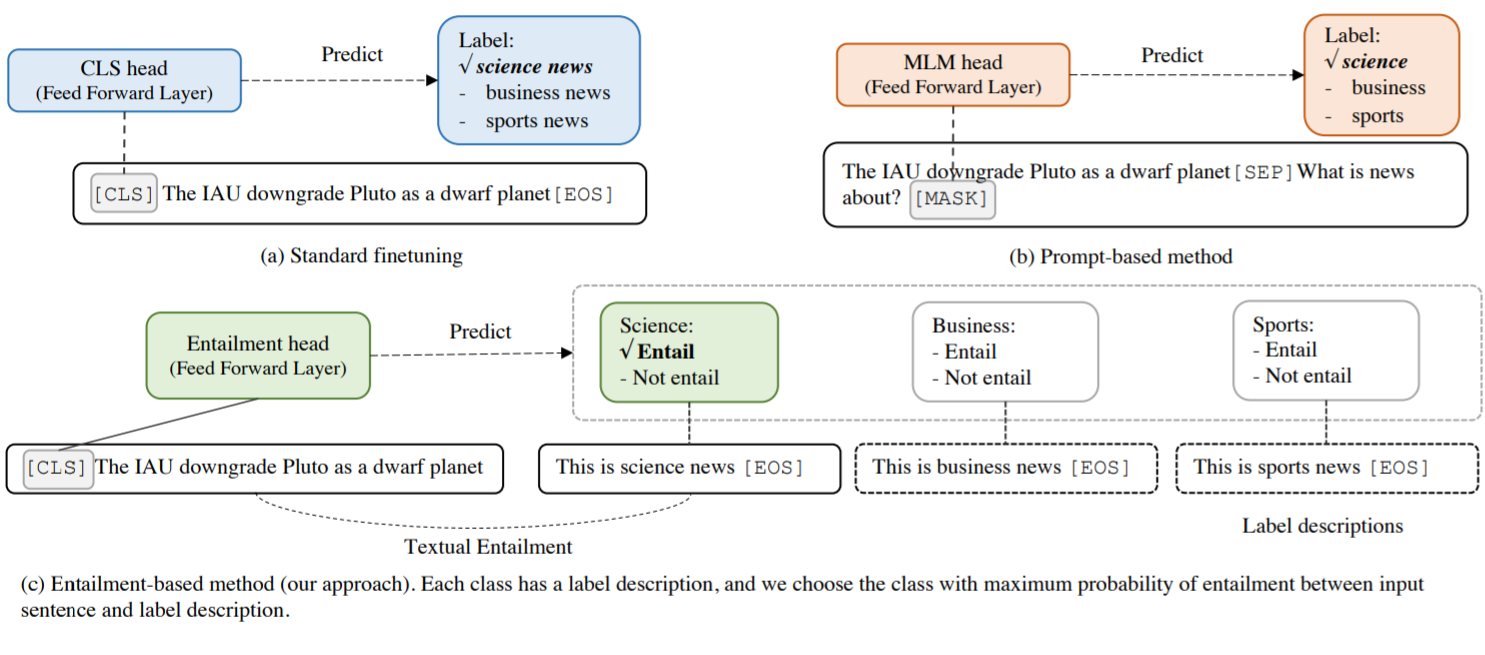
Compared with the prompt based method, the main difference of this method is to redefine the task as an entry task instead of "cloze", and design fine-grained label description instead of a single task description. Therefore, it can achieve good results in small sample scenarios.
Three, model training
The code used in this project has been uploaded to the work folder on the left. You can start the training by running train.py as follows.
Description of the meaning of the train.py parameter:
- task_ Name: dataset name in fewclue
- device: use cpu/gpu for training
- negative_num: number of negative samples. For multi classification tasks, the number of negative samples has a great impact on the effect. The value range of negative sample quantity parameter is [1, class_num - 1]
- save_dir: model storage path
- batch_size: training batch size of each GPU/CPU
- learning_rate: Adam's initial learning rate
- Epichs: total number of workouts to perform
- max_seq_length: the maximum truncation length of the text
!python -u -m paddle.distributed.launch --gpus "0" \
work/train.py \
--task_name "csldcp" \
--device gpu \
--negative_num 66 \
--save_dir "./checkpoints" \
--batch_size 32 \
--learning_rate 1e-5 \
--epochs 2 \
--max_seq_length 512
----------- Configuration Arguments -----------
gpus: 0
heter_worker_num: None
heter_workers:
http_port: None
ips: 127.0.0.1
log_dir: log
nproc_per_node: None
run_mode: None
server_num: None
servers:
training_script: work/train.py
training_script_args: ['--task_name', 'csldcp', '--device', 'gpu', '--negative_num', '66', '--save_dir', './checkpoints', '--batch_size', '32', '--learning_rate', '1e-5', '--epochs', '2', '--max_seq_length', '512']
worker_num: None
workers:
------------------------------------------------
WARNING 2021-06-27 17:55:35,673 launch.py:357] Not found distinct arguments and compiled with cuda or xpu. Default use collective mode
launch train in GPU mode!
INFO 2021-06-27 17:55:35,674 launch_utils.py:510] Local start 1 processes. First process distributed environment info (Only For Debug):
+=======================================================================================+
| Distributed Envs Value |
+---------------------------------------------------------------------------------------+
| PADDLE_TRAINER_ID 0 |
| PADDLE_CURRENT_ENDPOINT 127.0.0.1:41017 |
| PADDLE_TRAINERS_NUM 1 |
| PADDLE_TRAINER_ENDPOINTS 127.0.0.1:41017 |
| PADDLE_RANK_IN_NODE 0 |
| PADDLE_LOCAL_DEVICE_IDS 0 |
| PADDLE_WORLD_DEVICE_IDS 0 |
| FLAGS_selected_gpus 0 |
| FLAGS_selected_accelerators 0 |
+=======================================================================================+
INFO 2021-06-27 17:55:35,675 launch_utils.py:514] details abouts PADDLE_TRAINER_ENDPOINTS can be found in log/endpoints.log, and detail running logs maybe found in log/workerlog.0
launch proc_id:22646 idx:0
[2021-06-27 17:55:37,237] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams
W0627 17:55:37.238456 22646 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W0627 17:55:37.243487 22646 device_context.cc:422] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-06-27 17:55:42,191] [ INFO] - Found /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt
global step 200, epoch: 1, batch: 200, loss: 0.04065, speed: 0.06 step/s
global step 400, epoch: 1, batch: 400, loss: 0.02934, speed: 0.06 step/s
global step 600, epoch: 1, batch: 600, loss: 0.13510, speed: 0.06 step/s
global step 800, epoch: 1, batch: 800, loss: 0.03925, speed: 0.06 step/s
global step 1000, epoch: 1, batch: 1000, loss: 0.00930, speed: 0.06 step/s
epoch:1, dev_accuracy:58.408, total_num:1784
global step 1200, epoch: 2, batch: 77, loss: 0.01942, speed: 0.01 step/s
global step 1400, epoch: 2, batch: 277, loss: 0.00554, speed: 0.06 step/s
global step 1600, epoch: 2, batch: 477, loss: 0.00251, speed: 0.06 step/s
global step 1800, epoch: 2, batch: 677, loss: 0.00384, speed: 0.06 step/s
global step 2000, epoch: 2, batch: 877, loss: 0.00228, speed: 0.06 step/s
global step 2200, epoch: 2, batch: 1077, loss: 0.01744, speed: 0.06 step/s
epoch:2, dev_accuracy:60.594, total_num:1784
INFO 2021-06-27 19:26:53,708 launch.py:266] Local processes completed.
4, Model effect evaluation
!python -u -m paddle.distributed.launch --gpus "0" \
work/predict.py \
--task_name "csldcp" \
--device gpu \
--init_from_ckpt "./checkpoints/model_2246/model_state.pdparams" \
--output_dir "./output" \
--batch_size 32 \
--max_seq_length 512
----------- Configuration Arguments -----------
gpus: 0
heter_worker_num: None
heter_workers:
http_port: None
ips: 127.0.0.1
log_dir: log
nproc_per_node: None
run_mode: None
server_num: None
servers:
training_script: work/predict.py
training_script_args: ['--task_name', 'csldcp', '--device', 'gpu', '--init_from_ckpt', './checkpoints/model_2246/model_state.pdparams', '--output_dir', './output', '--batch_size', '32', '--max_seq_length', '512']
worker_num: None
workers:
------------------------------------------------
WARNING 2021-06-27 20:34:14,282 launch.py:357] Not found distinct arguments and compiled with cuda or xpu. Default use collective mode
launch train in GPU mode!
INFO 2021-06-27 20:34:14,284 launch_utils.py:510] Local start 1 processes. First process distributed environment info (Only For Debug):
+=======================================================================================+
| Distributed Envs Value |
+---------------------------------------------------------------------------------------+
| PADDLE_TRAINER_ID 0 |
| PADDLE_CURRENT_ENDPOINT 127.0.0.1:49189 |
| PADDLE_TRAINERS_NUM 1 |
| PADDLE_TRAINER_ENDPOINTS 127.0.0.1:49189 |
| PADDLE_RANK_IN_NODE 0 |
| PADDLE_LOCAL_DEVICE_IDS 0 |
| PADDLE_WORLD_DEVICE_IDS 0 |
| FLAGS_selected_gpus 0 |
| FLAGS_selected_accelerators 0 |
+=======================================================================================+
INFO 2021-06-27 20:34:14,284 launch_utils.py:514] details abouts PADDLE_TRAINER_ENDPOINTS can be found in log/endpoints.log, and detail running logs maybe found in log/workerlog.0
launch proc_id:5624 idx:0
[2021-06-27 20:34:15,858] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams
W0627 20:34:15.859658 5624 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W0627 20:34:15.864339 5624 device_context.cc:422] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-06-27 20:34:20,753] [ INFO] - Found /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt
Loaded parameters from ./checkpoints/model_2246/model_state.pdparams
INFO 2021-06-27 20:53:21,567 launch.py:266] Local processes completed.
Download the results. The first 10 prediction results are as follows:
{"id": 0, "label": "mineral engineering"}
{"id": 1, "label": "Transportation Engineering"}
{"id": 2, "label": "Animal husbandry/veterinary medicine"}
{"id": 3, "label": "Public health and Preventive Medicine"}
{"id": 4, "label": "Psychology"}
{"id": 5, "label": "Nuclear science and technology"}
{"id": 6, "label": "Applied Economics"}
{"id": 7, "label": "Art"}
{"id": 8, "label": "Stomatology"}
{"id": 9, "label": "mechanical engineering"}
for item in range(10):
or item in range(10):
print(test_ds.data[item])
{'id': 0, 'content': 'Jinshan gold deposit is a large epithermal gold deposit in Western Tianshan, China,The occurrence of ore body is mainly controlled by various fault structures.Based on years of exploration work,Through field mapping and a large number of exploration line profile analysis,The author summarizes that the fault tectonic activity has experienced three stages: pre mineralization, hydrothermal mineralization and post mineralization.The basic law of fault ore control is:The NW trending fault generally controls the distribution position of the deposit,The late activity of North-South trending faults resulted in superimposed enrichment and mineralization,The early stage of NE trending faults was accompanied by intermediate acid dyke activity,The post metallogenic activities cause the ore body to break and rise and fall,East west direction-The early stage of NW fault was accompanied by volcanic eruption,After mineralization, the activity cuts off the North-South ore body.At the same time, the prospecting evaluation criteria of the mining area are summarized.'}
{'id': 1, 'content': 'To prove"axis-Spoke"Transportation network has economies of scope independent of density economy,Assuming that the density and income of the transportation network remain unchanged, the cost function of the transportation network under the two modes of independent segmented operation and integrated operation is established,Comparative discovery,Adopt independent sectional operation and"axis-Spoke"There is a big difference in the operation cost of transportation network between the two modes of integrated operation,When used"axis-Spoke"Economies of scope can only be realized when the integrated operation mode and the transportation network reach the best operation structure,The reason is that"axis-Spoke"When the integrated operation mode is used to integrate and optimize the operation line, the work efficiency of operating vehicles and personnel can be improved. The results show that,When the density return is constant"axis-Spoke"There is scope economy under the network operation mode,However, the realization of economies of scope can only be realized through the optimization of operation line structure.'}
{'id': 2, 'content': 'The breeding of abdominal fat two-way selection line in broilers was based on the 6th generation of high-fat and low-fat broilers,The differences of abdominal fat weight, abdominal fat rate and body weight between the six generations of high-fat and low-fat broilers were analyzed,Further study on abdominal fat weight(rate)When selecting high and low fat lines as genetic markers,Does it affect body weight and other traits,Plasma very low density lipoprotein was also studied(VLDL)Possibility of indirect selection,To provide materials for the study of chicken lipid metabolism,It also lays a good foundation for the breeding of low-quality broilers in China.'}
{'id': 3, 'content': 'Patient male,35 year.Due to skin rash on trunk and upper limbs with mild pruritus for 4 years,He came to our department on February 8, 2009 for one year.Patients usually like sweets and alcohol,Denied viral hepatitis, diabetes and other visceral diseases and long-term medication history.The patient's parents and family members had no similar diseases.'}
{'id': 4, 'content': 'The research on self implicit social cognition has a solid theoretical foundation,And there are strict empirical research methods,It can promote the in-depth development of self theory.at present,The self-study of implicit social cognition has become a new force of self-study.Finally, the significance and trend of this orientation are prospected.'}
{'id': 5, 'content': 'A multi-layer flat plate ionization chamber is introduced(Or fission chamber)Multiple output method of,This method is helpful to improve the time response of the ionization chamber,Mitigation of problems caused by excessive fissile materialαParticle signal stacking problem,It can make the ionization chamber contain more nuclear materials,Improve detection efficiency.'}
{'id': 6, 'content': 'This paper discusses the decision mechanism of the optimal patent protection width.In a three-stage game model:Social planners first formulate the width of patent protection,Then each manufacturer has a patent competition,Finally, the market imitates the patented products non infringing and leads to Salop monopolistic competition.Model analysis shows that,In the innovation stage,Patent protection width corresponds to patent profit,Determines the innovation incentive of the market;But in the equilibrium of monopoly competition,It also corresponds to the cost of non infringement imitation,It determines the total imitation cost and the transportation cost for consumers to buy products.The impact of these two functions on social welfare is conflicting,The optimal protection width is the result of trade-off between the two.Comparative static analysis shows that,The optimal width under monopoly competition equilibrium is an increasing function of innovation difficulty, importance and uncertainty of innovation environment,It is a subtractive function of consumer diversity preference,But it has nothing to do with the size of the market.'}
{'id': 7, 'content': 'In the text"metamorphosis"It refers to a kind of artistic creation"Crazy"state,Not a psychopath in the usual derogatory sense.such"metamorphosis"Does it contribute to painting performance,It needs to be further confirmed by genetic science,But I think,"metamorphosis"To a certain extent, it has had a certain impact on artistic creation:It promotes artistic creation,Contribute to the expression of emotion in artistic creation;But this metamorphosis is not a simple mental mutation,It works at the same time,Still inseparable from the constraints of rationality.According to the characteristics of artistic creation,This paper expounds this influence from the perspective of psychology.'}
{'id': 8, 'content': 'Objective To observe the different stages of mechanical tension expansion of palatal suture in mice EphB4/ephrinB2 Distribution and expression law.Methods healthy males aged 6 weeks were selected C57BL/6 40 mice,They were randomly divided into control group and experimental expansion group,20 in each group.Tension is applied by double eye spring pantograph expander(0.56 N)In the palatal suture area of mice in the experimental afterburner group.In the experimental group, 1, 3, 7 and 14 d Five mice were selected for immunohistochemistry EphB4/ephrinB2 Organization positioning,The expression pattern was observed and compared with the control group without force.Results expansion group EphB4/ephrinB2 The expression level was higher than that in the control group,The difference was statistically significant.Day 3 experimental group EphB4/ephrinB2 The expression level was the highest.Conclusion the expansion of palatal suture in mice can be induced EphB4/ephrinB2 Increased expression of,explain EphB4/ephrinB2 It is of great significance in the process of palatal suture expansion and new bone reconstruction.'}
{'id': 9, 'content': 'The impact component of rolling bearing fault vibration signal shows significant non Gaussian. High-order cumulant and high-order spectrum technology are good analysis tools for processing non Gaussian signals. In the fourth order cumulant-Teager Based on kurtosis, sliding is proposed Teager Kurtosis analysis method and combined third-order spectrum-1.5 Dimensional spectrum is proposed based on 1.5 dimension Teager Fault diagnosis method of rolling bearing based on kurtosis spectrum. Firstly, the bearing fault signal is sliding Teager Kurtosis is calculated to obtain a response to the impact characteristics of fault signal Teager Kurtosis time series are then calculated Teager Kurtosis time series 1.5 Dimension spectrum to extract the fault characteristic frequency of rolling bearing. The demodulation performance and the ability to extract the characteristics of weak impact fault of rolling bearing are verified by simulation signal analysis. Finally, the experimental test signal of rolling bearing inner ring fault is analyzed, and based on fast Kurtogram The resonance demodulation methods of the algorithm are compared and analyzed to verify the effectiveness of the method.'}
- From the results, it can be seen that the model prediction effect of "mining engineering", "Transportation Engineering", "nuclear science and technology" and "Mechanical Engineering" is better. The reason is that these disciplines are classified obviously, so they are also well distinguished;
- However, "stomatology" is a little biased, and the disciplines are complex. The prediction effect of the model is poor, and the model needs to spend more time learning.
5, Summary and sublimation
Tip
In EFL, because it is a small sample learning, it is very necessary to add data_ The num parameter is used to configure the number of negative samples. For multi classification tasks, the number of negative samples has a great impact on the effect. The value range of the negative sample number parameter is [1, class_num - 1]. This parameter can be as large as possible, so that the effect of the model will be better.
be careful
After saving the model weight, click the folder of the model weight, and an error of "Cannot read property 'length' of undefined" will be reported, as shown in the figure:

This is not a big problem. In fact, the model weights saved in the folder can be seen on the terminal:
Follow up solution: the reason for this error is that the name checkpoints is built in AI Studio. Therefore, just change the name of the folder~
Introduction to the author
Zheng Bopei, 2018 undergraduate majoring in automation, School of robotics, Beijing Union University
Intern, State Key Laboratory of complex system management and control, Institute of automation, Chinese Academy of Sciences
Baidu PaddlePaddle developer technical expert PPDE
Members of Baidu PaddlePaddle's official help group and answering team
Shenzhen firewood maker space certified member
Baidu brain intelligent dialogue trainer
Assistant Engineer of Alibaba cloud artificial intelligence and DevOps
I got the supreme level in AI Studio and lit 10 badges to turn on each other!!!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378
