Experiment 2 compilation and debugging of assembly source program of multiple logic segments
Experiment task 1:
Task 1-1
- test101 source code:
assume ds:data, cs:code, ss:stack
data segment
db 16 dup(0)
data ends
stack segment
db 16 dup(0)
stack ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
mov sp, 16
mov ah, 4ch
int 21h
code ends
end start
-
Screenshot at the end of line17 and before line19:
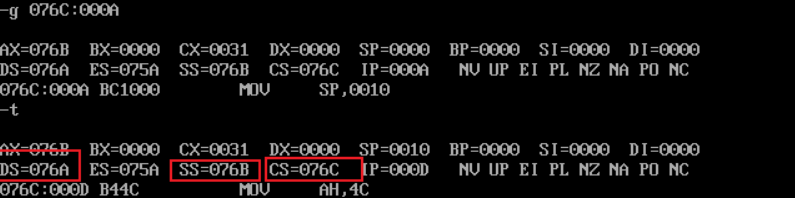
-
① In debug, execute until the end of line17 and before line19. Record this time: register (DS) = 076A, register (SS)= 076B, register (CS) = 076C
② Assuming that the segment address of the code segment is X after the program is loaded, the segment address of the data segment is X_ X-2, the segment address of stack is X-1_.
Because there is a difference of two hex bits between CS 076C and DS 076A, the data segment is X-2. Similarly, the stack segment is X-1
Task 1-2
- test102 source code:
assume ds:data, cs:code, ss:stack
data segment
db 4 dup(0)
data ends
stack segment
db 8 dup(0)
stack ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
mov sp, 8
mov ah, 4ch
int 21h
code ends
end start
-
Screenshot of observing the values of registers DS, CS and SS at the end of debugging to line17 and before line19:

-
① In debug, execute until the end of line17 and before line19. Record this time: register (DS) = 076A, register (SS)= 076B, register (CS) = 076C
② Assuming that the segment address of the code segment is X after the program is loaded, the segment address of the data segment is X_ X-2, the segment address of stack is X-1_.
Because there is a difference of two hex bits between CS 076C and DS 076A, the data segment is X-2. Similarly, the stack segment is X-1
Task 1-3
- test103 source code:
assume ds:data, cs:code, ss:stack
data segment
db 20 dup(0)
data ends
stack segment
db 20 dup(0)
stack ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
mov sp, 20
mov ah, 4ch
int 21h
code ends
end start
-
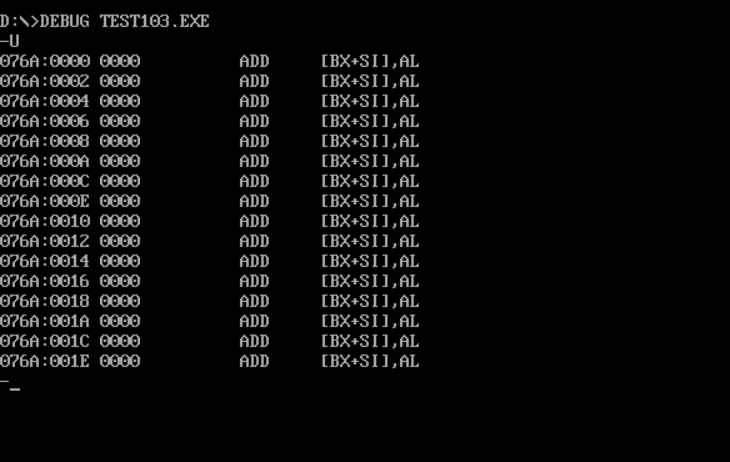
Screenshot of register DS, CS and SS values before line17 and line19 after debugging:
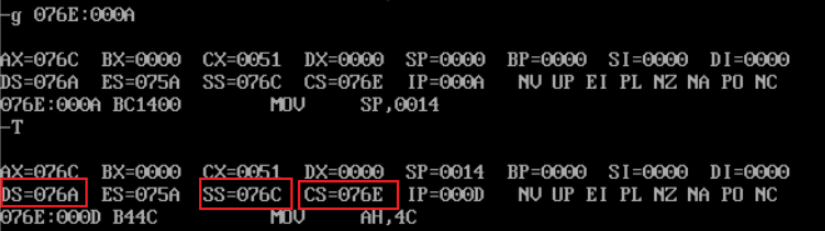
-
① In debug, execute until the end of line17 and before line19. Record this time: register (DS) = 076A, register (SS) =076C, register (CS) = 076E.
② Assuming that the segment address of the code segment is X after the program is loaded, the segment address of the data segment is X_ X-4, the segment address of stack is X-2_.
Because there is a difference of four hex bits between CS 076E and DS 076A, the data segment is X-4. Similarly, the stack segment is X-2
Tasks 1-4
- test104 source code:
assume ds:data, cs:code, ss:stack
code segment
start:
mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
mov sp, 20
mov ah, 4ch
int 21h
code ends
data segment
db 20 dup(0)
data ends
stack segment
db 20 dup(0)
stack ends
end start
- Screenshot of register DS, CS and SS values before line17 and line19 after debugging:
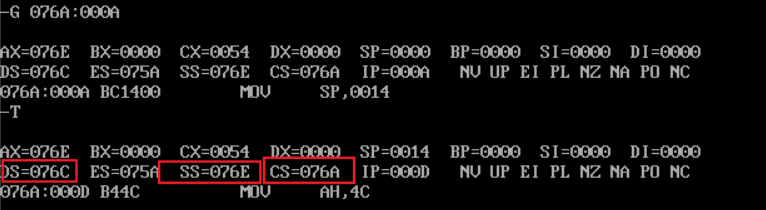
-
① In debug, execute until the end of line9 and before line11. Record this time: register (DS) = 076C, register (SS) =076E, register (CS) = 076A
② Assuming that the segment address of the code segment is X after the program is loaded, the segment address of the data segment is X_ X+2, the segment address of stack is X+4_.
Because CS is 076A and DS is 076C, there is a difference of two hex bits, so the data segment is X+2. Similarly, the stack segment is X+4
Tasks 1-5
① For the segment defined below, after the program is loaded, the actual memory space allocated to the segment is N/16, rounded up and multiplied by 16.
xxx segment db N dup(0) xxx ends
② If the program Task1_ 1.asm, task1_ 2.asm, task1_ 3.asm, task1_ 4. In ASM, if the pseudo instruction end start is changed to end, which program can still be executed correctly. The reasons are analyzed and explained in combination with the conclusions obtained from practical observation.
test101:
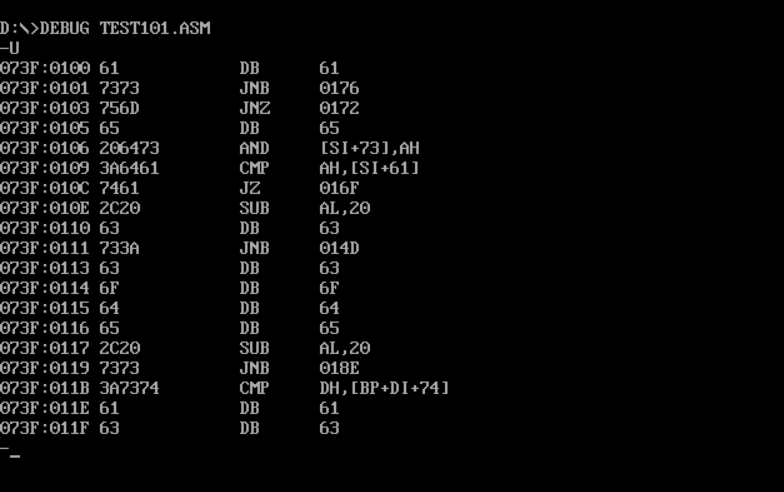
test102:
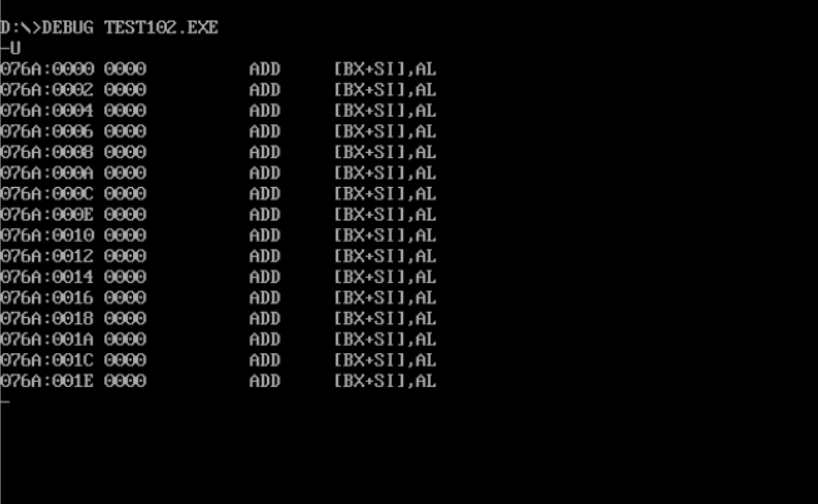
test103:
test104:
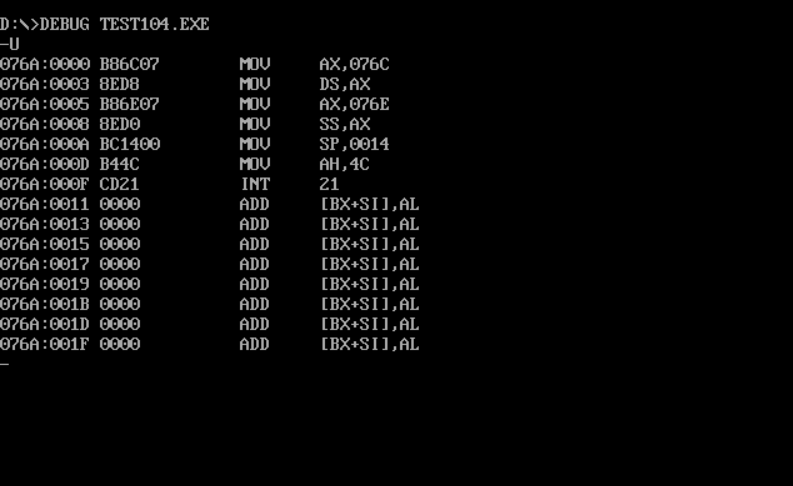
Through practice, it is found that only test104 can be executed normally, so modifying end start to end has no impact on test104. The only difference between test104 and the other three groups of experiments is that the code segment is defined first. It can be inferred that end start indicates that the program entry point is at start. When there is no start, the default entry is the first line of the program, Except for test104, the first line of other programs is namespace, so it cannot be executed normally. Test104 can be executed normally.
Experiment task 2:
Write an assembly source program to realize 160 consecutive bytes to memory units b800:0f00 ~ b800:0f9f, and fill hexadecimal data 03 and 04 repeatedly in turn.
- Source code of test2:
assume cs:code
code segment
start:
mov ax, 0b800h ;Note that hexadecimal cannot start with a letter, so add a 0 before it to distinguish it
mov ds, ax
mov bx, 0f00h
mov cx, 80
s: mov [bx], 0403h
add bx,2
loop s
mov ah,4ch
int 21h
code ends
end start
- Screenshot of operation results:

Experiment task 3:
The data of logical segment data1 and logical segment data2 are added in turn, and the results are saved in logical segment data3.
- Complete source code:
assume cs:code data1 segment db 50, 48, 50, 50, 0, 48, 49, 0, 48, 49 data1 ends data2 segment db 0, 0, 0, 0, 47, 0, 0, 47, 0, 0 data2 ends data3 segment db 16 dup(0) data3 ends code segment start: mov ax, data1 mov ss, ax mov ax, data2 mov es, ax mov ax, data3 mov ds, ax mov bx, 0 mov cx, 10 s: mov al, ss:[bx] mov al, es:[bx] mov [bx], al add bx, 1 loop s mov ah, 4ch int 21h code ends end start
- Screenshot of loading, disassembling and debugging in debug:
- debug command and screenshot of the original value of memory space data corresponding to logical segments data1, data2 and data3 before data items are added in turn:
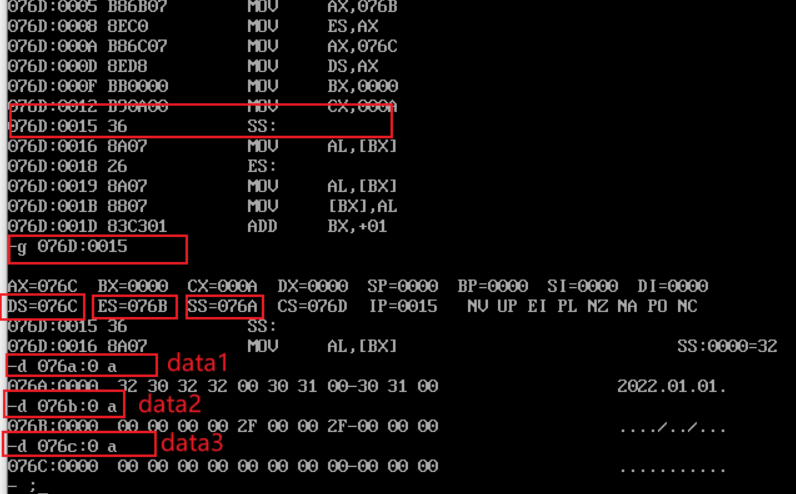
- After adding in sequence, the debug command and screenshot of the original value of memory space data corresponding to logical segments data1, data2 and data3:
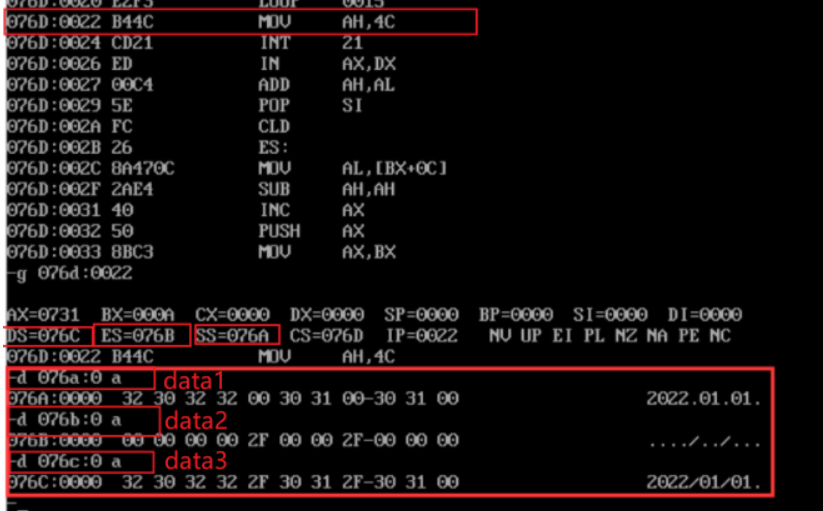
Experiment task 4:
The 8-word data in logical segment data1 is stored in reverse order in logical segment b.
- Complete source code:
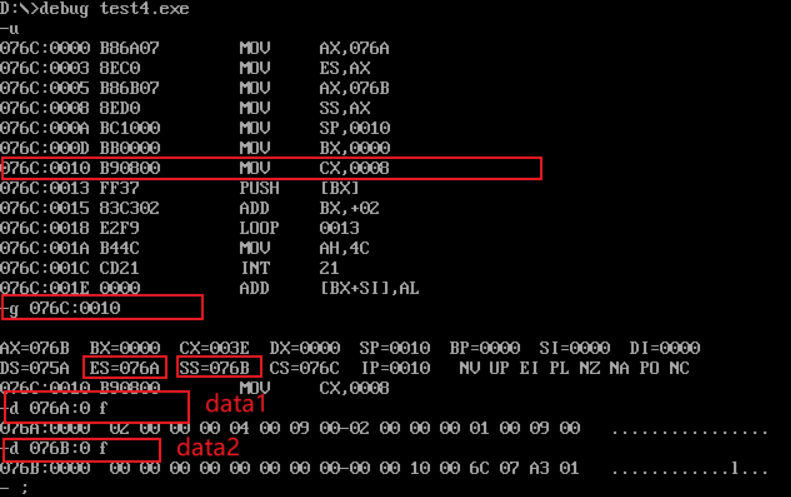
assume cs:code data1 segment dw 2, 0, 4, 9, 2, 0, 1, 9 data1 ends data2 segment dw 8 dup(?) data2 ends code segment start: mov ax, data1 mov es, ax mov ax, data2 mov ss, ax mov sp, 10h mov bx, 0 mov cx, 8 s: push [bx] add bx, 2 loop s mov ah, 4ch int 21h code ends end start
- Screenshot of loading, disassembling and debugging in debug:
- Before the program exits, use the d command to view a screenshot of the memory space corresponding to data segment data2.
Before storage:
After storage:

Experiment task 5:
- test5 source code:
assume cs:code, ds:data
data segment
db 'Nuist'
db 2, 3, 4, 5, 6
data ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, 0b800H
mov es, ax
mov cx, 5
mov si, 0
mov di, 0f00h
s: mov al, [si]
and al, 0dfh
mov es:[di], al
mov al, [5+si]
mov es:[di+1], al
inc si
add di, 2
loop s
mov ah, 4ch
int 21h
code ends
end start
- Screenshot of operation results:

- Screenshot after the execution of line25 and before the execution of line27 using the g command:
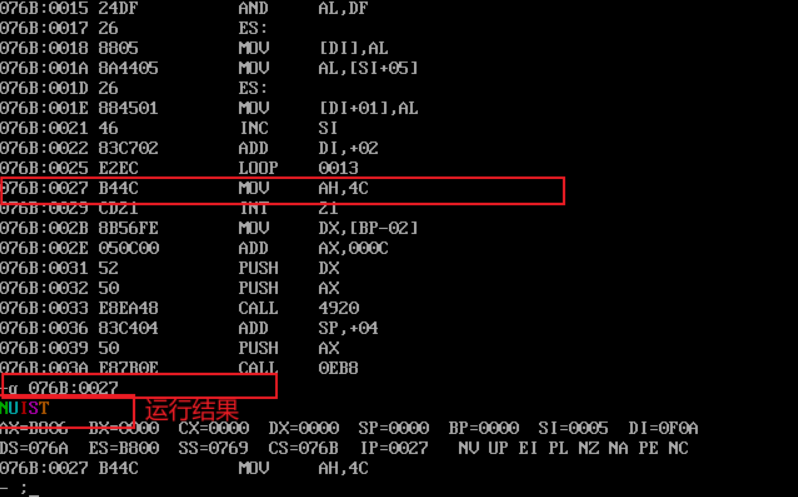
- The function of line19 in the source code is to change the case of letters as shown in the figure below
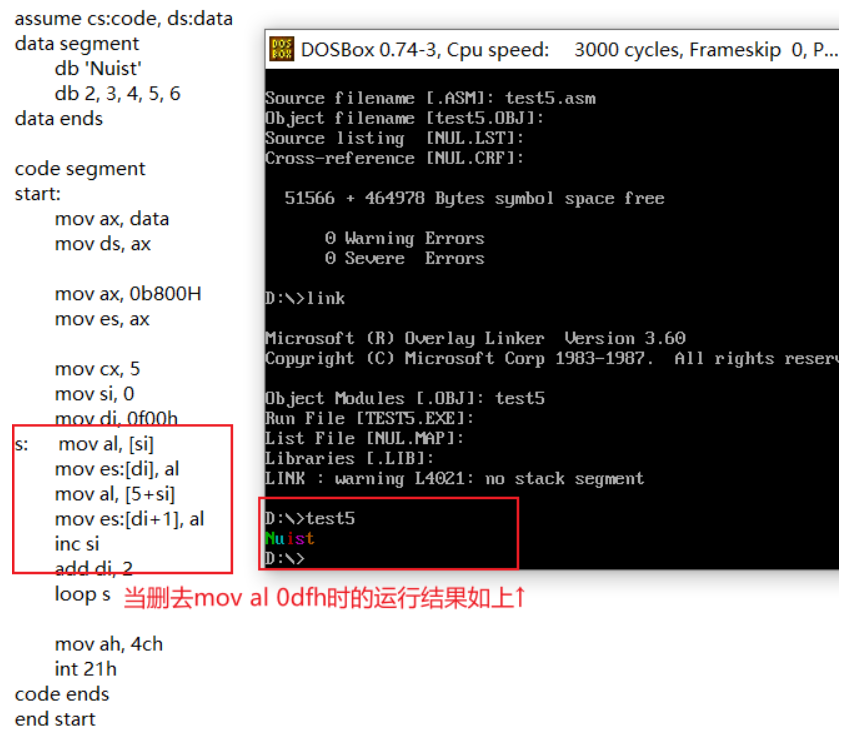
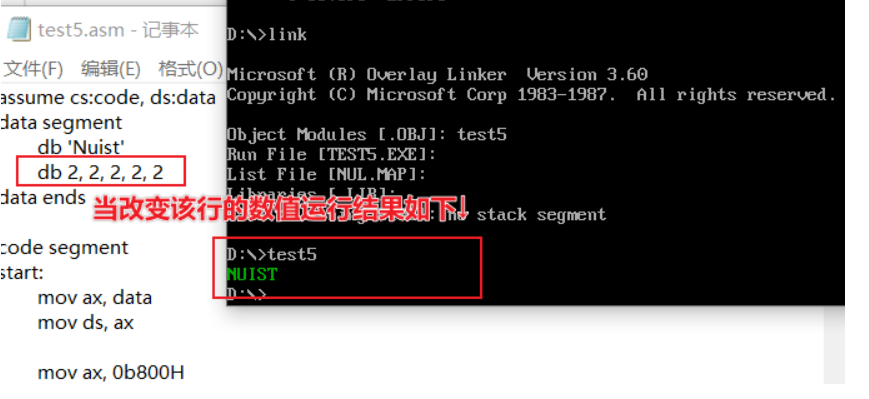
- Purpose of byte data in data segment line4 in the source code: it can be seen from the experiment in the figure below that the function of this line is to change the font color
Experiment task 6:
Change the first word of each line in the data section from uppercase to lowercase.
- test6 source code:
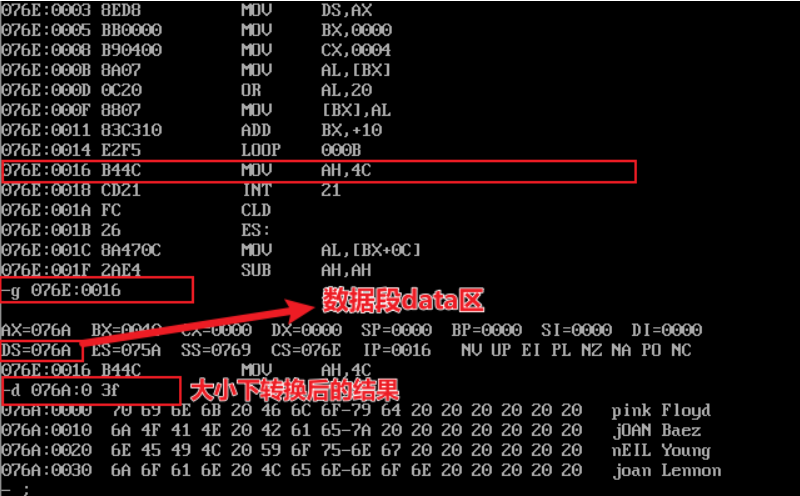
assume cs:code, ds:data data segment db 'Pink Floyd ' db 'JOAN Baez ' db 'NEIL Young ' db 'Joan Lennon ' data ends code segment start: mov ax, data mov ds, ax mov bx, 0 mov cx, 4 s: mov al, [bx] or al, 00100000b mov [bx], al add bx, 16 loop s mov ah, 4ch int 21h code ends end start
- Screenshot of loading, disassembling and debugging in debug:
- Before the program exits, use the d command to view a screenshot of the memory space corresponding to the data segment data:
Experiment task 7:
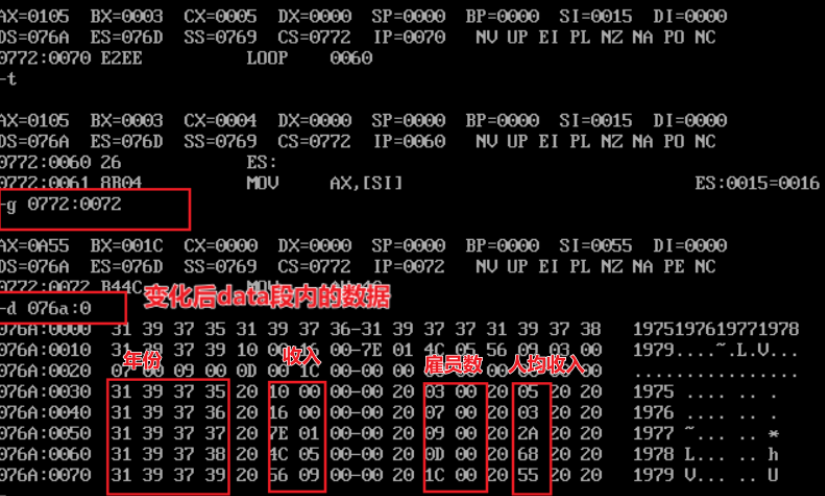
It is required to write the year, income, number of employees and per capita income into the table section in a structured manner. In the table, each row of data occupies 16 bytes in the logical segment table, and the byte size of each data is allocated as follows. During the period, the data is separated by spaces.
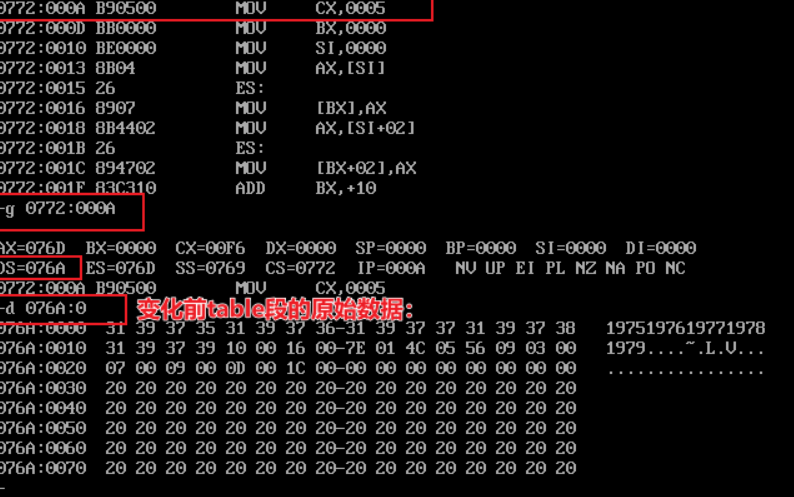
- test7 source code:
assume cs:code, ds:data, es:table
data segment
db '1975', '1976', '1977', '1978', '1979'
dw 16, 22, 382, 1356, 2390
dw 3, 7, 9, 13, 28
data ends
table segment
db 5 dup( 16 dup(' ') ) ;
table ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, table
mov es, ax
mov cx, 5
mov bx, 0
mov si, 0
s: mov ax, [si]
mov es:[bx], ax
mov ax, [si+2]
mov es:[bx+2], ax
add bx, 16
add si, 4
loop s
mov cx, 5
mov bx, 5
mov si, 20
s1: mov ax, [si]
mov es:[bx], ax
mov ax, 0000h
mov es:[bx+2], ax
add bx, 16
add si, 2
loop s1
mov cx, 5
mov bx, 10
mov si, 30
s2: mov ax, [si]
mov es:[bx], ax
add bx, 16
add si, 2
loop s2
mov cx, 5
mov si, 5
s3: mov ax, es:[si]
mov bl, es:[si+5]
div bl
mov es:[si+8], al
add si, 16
loop s3
mov ah, 4ch
int 21h
code ends
end start
-
Debug screenshot
- View the screenshot of the original data information of the table segment:
- Before the program exits, use the d command to view the screenshot of the memory space corresponding to the table segment and confirm whether the information is written to the specified memory structurally as required
Experiment summary:
- If hexadecimal is used to represent data in assembly, when the first value is a letter, a 0 should be added in front of it for the computer to distinguish.
- In assembly, the entry of the program is determined by two factors. If there is an end start pseudo instruction, the program entry is at the start position. If there is no end start pseudo instruction and there is only an end pseudo instruction, the program starts from the first line when the entry is not indicated. When the first line is in the name space, the program cannot run normally.
- db is word data and dw is byte data. Be careful when saving data.