Operation ①:
-
Requirements: specify a website and crawl all the pictures in the website, such as China Meteorological Network( http://www.weather.com.cn ). Single thread and multi thread crawling are used respectively. (the number of crawling pictures is limited to the last 3 digits of the student number)
-
Output information:
Output the downloaded Url information on the console, store the downloaded image in the images subfolder, and give a screenshot.
1. Ideas and codes
Code cloud link:
3/1.py · data acquisition and fusion - Code cloud
1.1 website selection
I browsed through China weather website and finally selected the website of China weather website Picture channel - weather scene To crawl the picture.
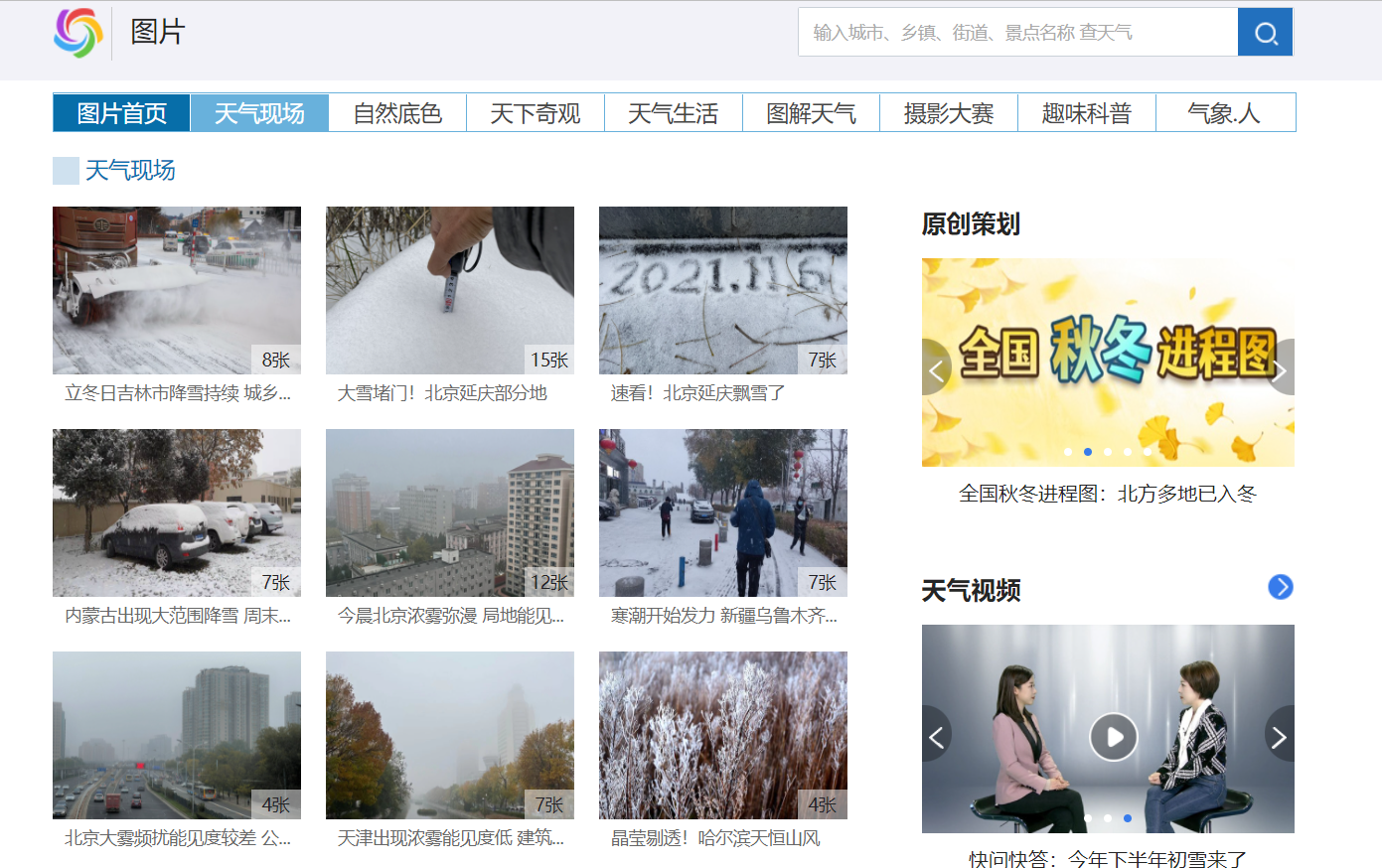
1.2 web page analysis
After analysis, it is found that each web page link to be crawled can be represented by the following CSS statement: div[class="oi"] div[class="bt"] a. after obtaining this element, we only need to take out the href attribute value, which is the web page link we want.
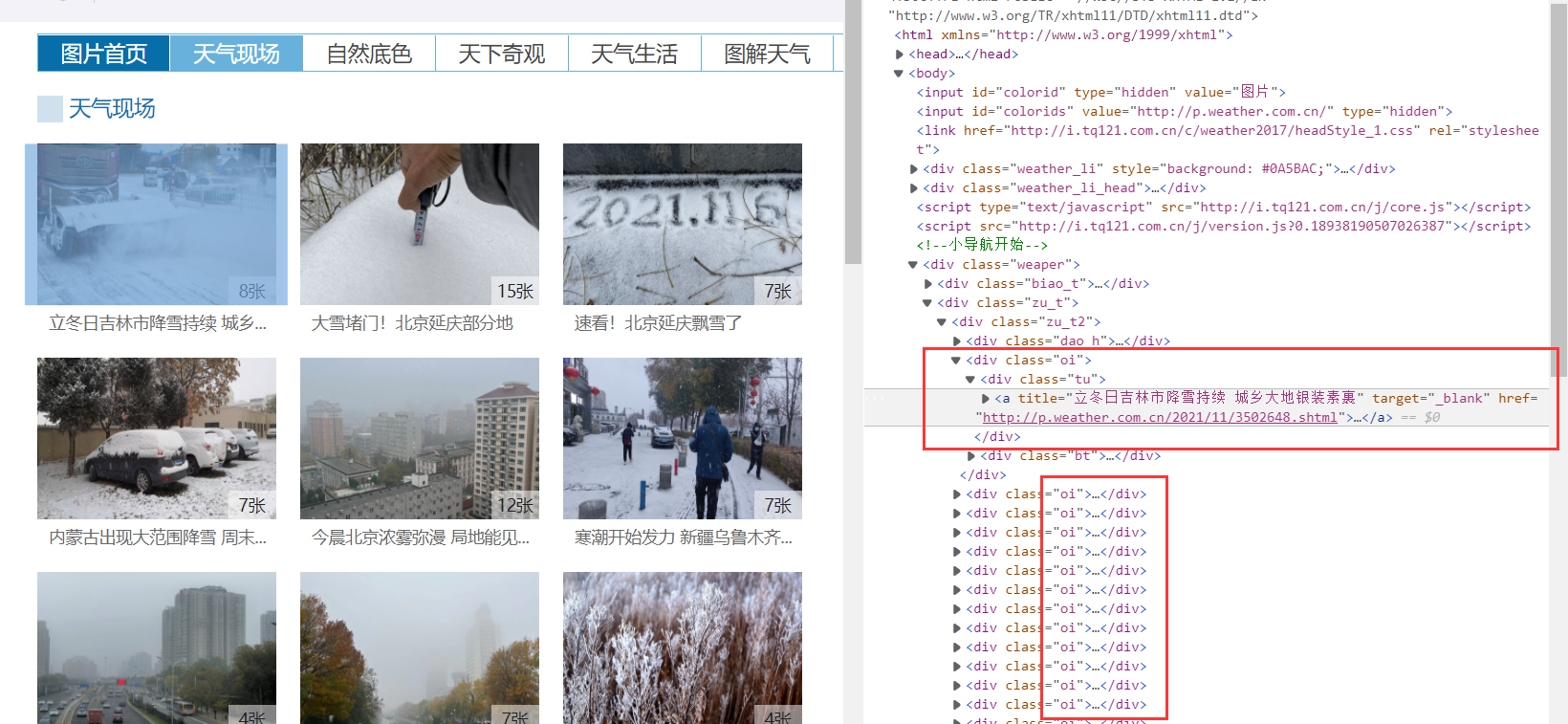
The core code is as follows:
soup = BeautifulSoup(data, 'html.parser')
pageUrl = soup.select('div[class="oi"] div[class="bt"] a')
pageUrl = [x['href'] for x in pageUrl]
Go to one of the web pages and continue to analyze the final target we want to climb. We can find that the pictures we want are under a row of parallel span, so we can extract: div[class="buttons"] span img through CSS statement, and then obtain its src attribute value to get the picture link.
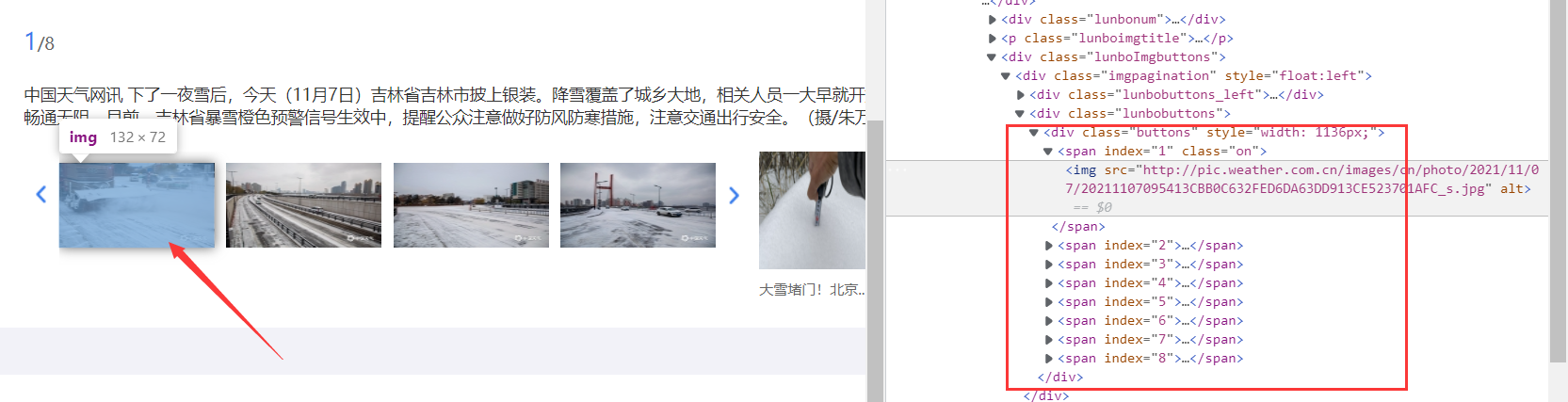
1.3 picture download
Define download function
def downloadPic(pic_url, cnt_t):
"""
:param pic_url: picture url
:param cnt_t: Counter for file naming
"""
if not os.path.exists('pic'):
os.mkdir('pic')
res = requests.get(pic_url)
with open("pic/{}.jpg".format(cnt_t), "wb") as f:
f.write(res.content)
print("{} {}".format(cnt_t, pic_url))
Single threaded download:
For the sake of code simplicity, I combine single thread download and multi thread download, which are controlled by the logical variable doThread. Setting doThread to False is a single thread download.
First extract the img tag, and then obtain the src attribute value, which is the url link of the picture we want, and then execute the downloadPic function to download. When the number of pictures downloaded is greater than 127, stop downloading.
pics = soup.select('div[class="buttons"] span img')
for p in pics:
if doThread:
T = threading.Thread(target=downloadPic, args=(p['src'], cnt))
T.setDaemon(False)
T.start()
threads.append(T)
time.sleep(random.uniform(0.02, 0.05))
else:
downloadPic(p['src'], cnt)
cnt += 1
if cnt > 127:
return
Multithreaded Download:
Similar to single thread, the method of threading library is called to add threads and set them as foreground threads. In order to prevent too fast errors, the interval of starting threads is set to 20~50ms.
T = threading.Thread(target=downloadPic, args=(p['src'], cnt)) T.setDaemon(False) # Set as foreground thread T.start() # Start thread threads.append(T) time.sleep(random.uniform(0.02, 0.05)) # Random sleep for 20~50ms
In the main function, the join method of the thread is also used for thread synchronization, that is, after the main thread's task ends, it enters the blocking state and waits for the execution of other sub threads to end, and then the main thread terminates.
if doThread:
for t in threads:
t.join()
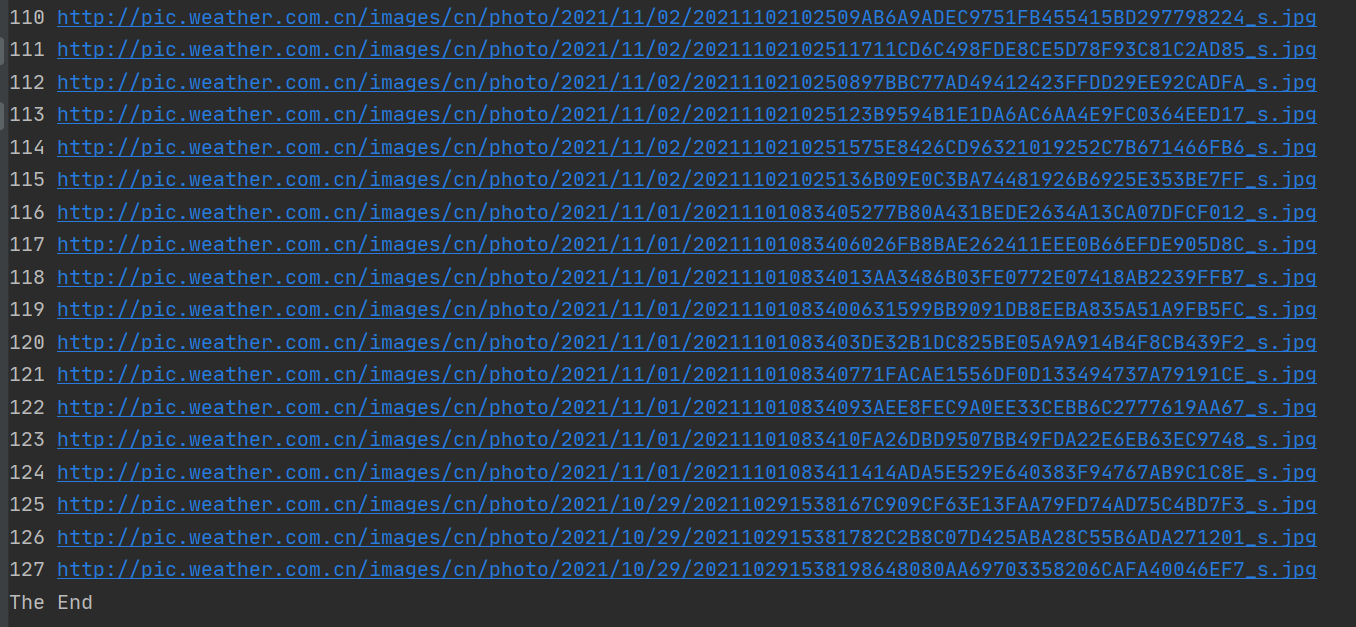
1.4 results
Single thread:
Multithreading:
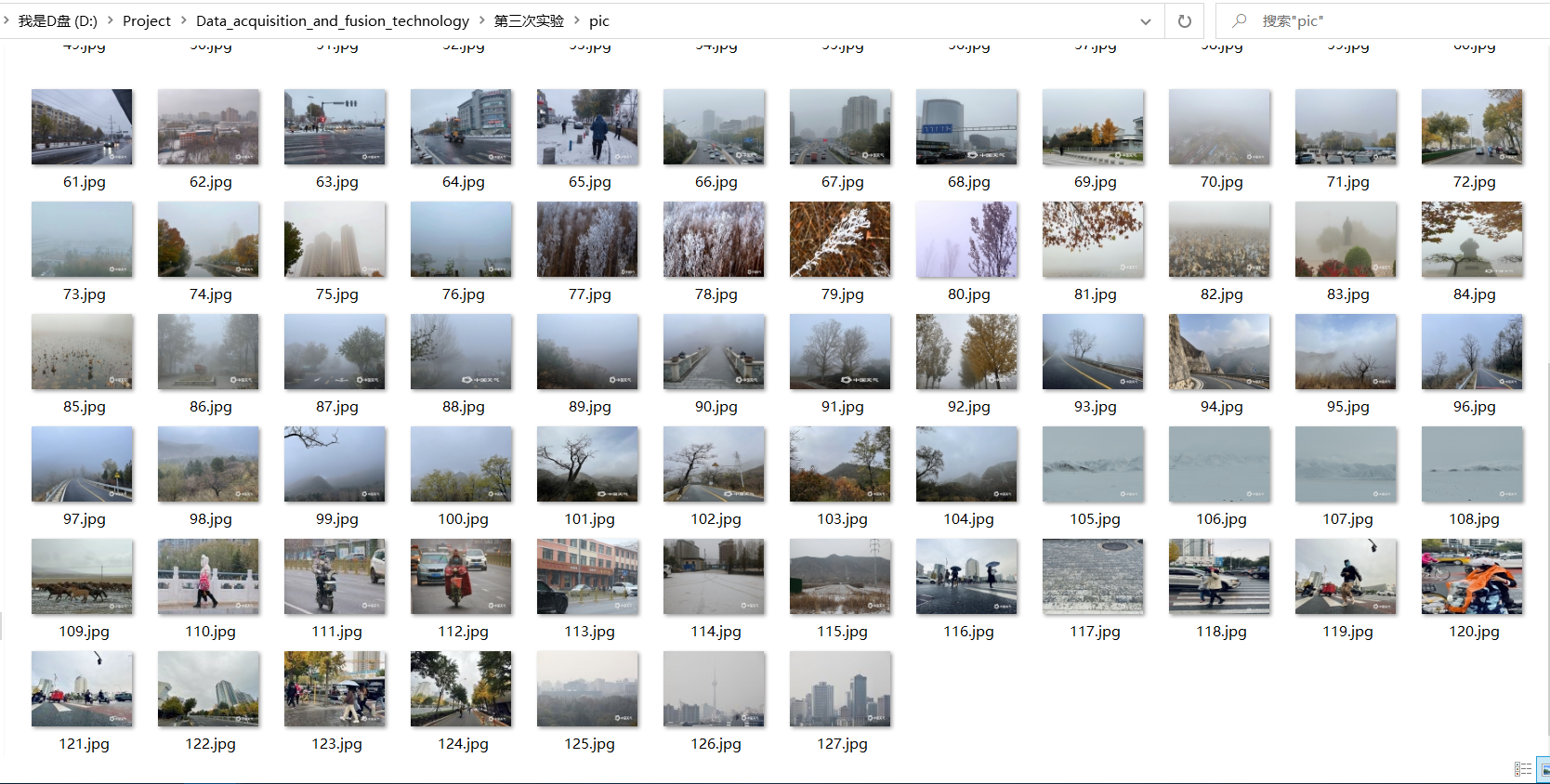
2. Experience
1. In multi-threaded crawling, we should control the speed, prevent errors and reduce the burden on the website. 2. Compared with single thread, the order of multithreading is uncertain. Pay attention to this when programming, otherwise unexpected errors may occur.
Operation ②:
-
Requirements: use the sketch framework to reproduce the operation ①.
-
Output information:
Same as operation ①
1. Ideas and codes
Code cloud link:
3 / operation 2/hw_2. Data acquisition and fusion
1.1 general idea
The process of crawling is similar to that of operation 1.
The first step is to parse the web page and get the link. This step corresponds to the crawler class of scratch.
The second step is to download the picture according to the link, and then the data pipeline class of the graph framework.
The item data item class serves as a connecting link between step 1 and step 2.
1.2 compiling data items
The data item class includes two attributes: the sequence number no of the picture and the link url of the picture. No is used to name the picture and url is used to download the picture
class PicItem(scrapy.Item): no = scrapy.Field() url = scrapy.Field()
1.3 compiling reptiles
Because it is a multi web page image crawler, I define two parse methods, which correspond to link acquisition of multi web pages and image download in web pages.
The first is to initiate the request. The callback function uses the parse method to obtain the link of multiple web pages. Then parse calls the method of parsePage again to download pictures in the web page.
def start_requests(self): source_url = 'http://p.weather.com.cn/tqxc/index.shtml' yield scrapy.Request(url=source_url, callback=self.parse)
# Link acquisition of multiple web pages
def parse(self, response, **kwargs):
data = response.body.decode(response.encoding)
selector = scrapy.Selector(text=data)
pageUrl = selector.xpath('//div[@class="oi"]/div[@class="bt"]/a/@href').extract()
for u in pageUrl:
if self.count <= 127:
yield scrapy.Request(url=u, callback=self.parsePage)
# Image crawling in web pages
def parsePage(self, response, **kwargs):
data = response.body.decode(response.encoding)
selector = scrapy.Selector(text=data)
pics_url = selector.xpath('//div[@class="buttons"]/span/img/@src').extract()
for p in pics_url:
item = PicItem()
item['url'] = p
item['no'] = self.count
if self.count <= 127:
print(self.count, p)
self.count += 1
yield item
1.4 compiling data pipeline
Different from the previous data pipeline class, because scratch has a special data pipeline class imagesipipeline for image download, you can inherit this class and rewrite several methods to achieve efficient image download.
Where, get_ media_ The requests method is used to download images; item_completed to judge whether the download is successful; file_path to rename the file.
class Hw2Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# Download pictures. If a collection is transmitted, it needs to be downloaded circularly
# The data in meta is obtained from the spider, and then passed to the following method through meta: file_path
yield Request(url=item['url'], meta={'name': item['no']})
def item_completed(self, results, item, info):
# Is a tuple, and the first element is a Boolean value indicating success
if not results[0][0]:
raise DropItem('Download failed')
return item
# Rename. If you don't rewrite this function, the image name is hash, which is a bunch of messy names
def file_path(self, request, response=None, info=None, *, item=None):
# Receive the picture name passed from the meta above
name = request.meta['name']
return str(name)+'.jpg'
1.5 setting
First, set whether to comply with the robots protocol to False. The log level is set to Error level to make the output concise. In addition, due to the inheritance of ImagesPipeline, you need to set the storage location of the picture. Finally, set and enable ITEM_PIPELINES.
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR' # The log level is set to Error level to make the output concise
IMAGES_STORE = './pics'
ITEM_PIPELINES = {
'hw_2.pipelines.Hw2Pipeline': 300,
}
1.6 results
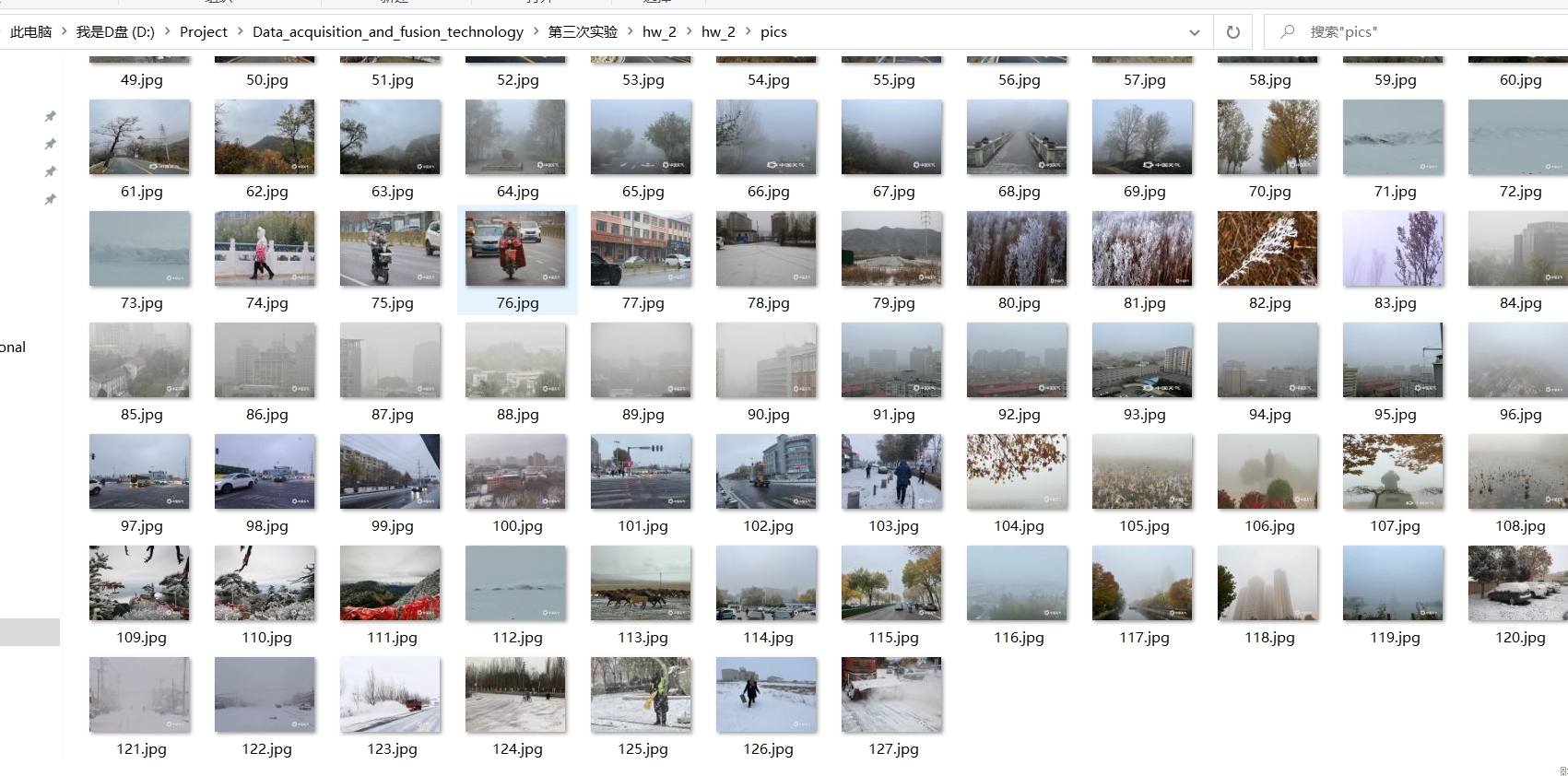
2. Experience
1. When writing a data pipeline class, you must remember to inherit`ImagesPipeline`,Because I forgot to inherit this class when writing the data pipeline class, I haven't downloaded the pictures and spent a lot of time. 2. yes seething The configuration of is very important. After writing the code, remember to setting Make corresponding configuration.
Operation ③:
-
Requirements: crawl the Douban movie data, use scene and xpath, store the content in the database, and store the pictures in the imgs path.
-
Candidate sites: https://movie.douban.com/top250
-
Output information:
Serial number Movie title director performer brief introduction Film rating Film cover 1 The Shawshank Redemption Frank delabond Tim Robbins Want to set people free 9.7 ./imgs/xsk.jpg 2....
1. Ideas and codes
Code cloud link:
3 / operation 3/hw_3. Data acquisition and fusion
1.1 web page analysis
elemental analysis
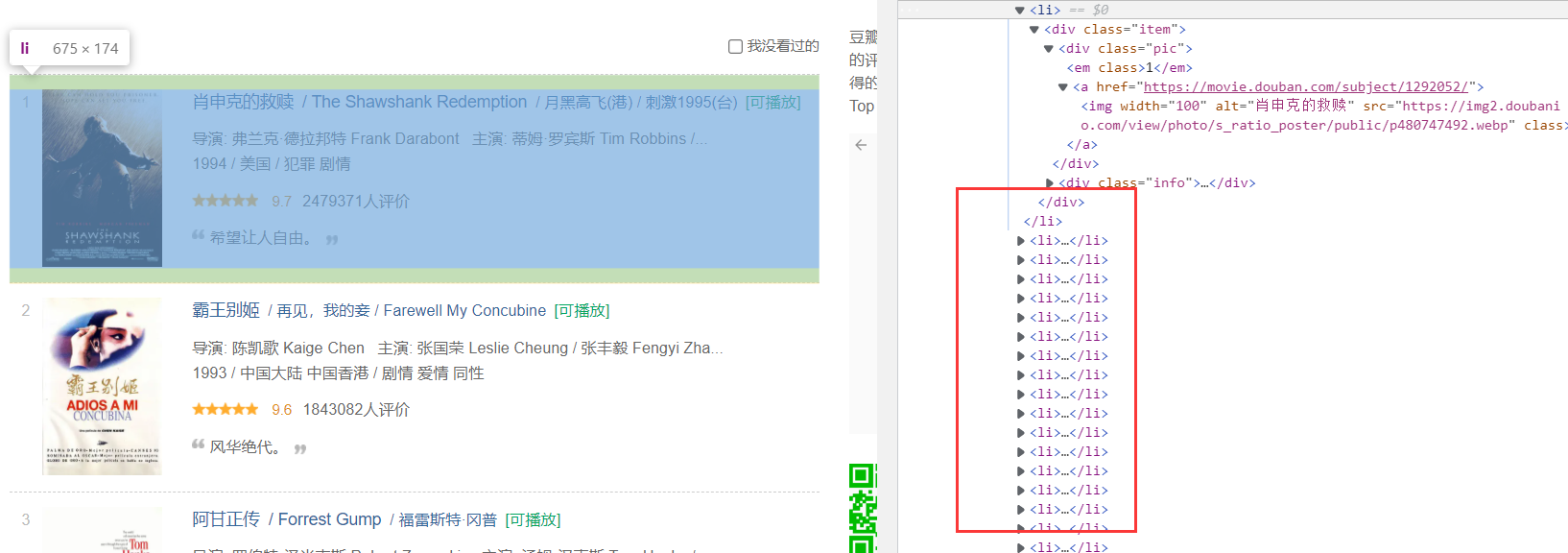
Through analysis, it can be found that each movie is in the li tag, and its fields can be accurately located by xpth.
The xpath of each field is as follows:
Ranking: / / div[@class='item']/div[@class='pic']/em/text()
Movie name: / / div[@class='item']/div[@class='info']//span[@class='title'][1]/text()
Director and actor: / / div[@class='item']/div[@class='info']//p[1]/text()[1]
Introduction: / / div[@class='item']/div[@class='info']//p[2]/span/text()
Rating: / / div[@class='item']/div[@class='info']//span[@class='rating_num']/text()
Cover image url: / / div[@class='item']/div[@class='pic']//img/@src
Page turning processing
It can be found that page turning can be handled with the start parameter of the url: https://movie.douban.com/top250?start=100 in start=100 indicates the 25 movies starting from the 101st movie. Therefore, page turning can be realized with the following code:
url = 'https://movie.douban.com/top250?start='
urls = []
for i in range(0, 250, 25):
urls.append("{}{}".format(url, i))
1.2 preliminary ideas
My initial idea is to locate the element list according to the xpath location of each field, and then locate the list of each field one by one to form each record.
item['ranks'] = selector.xpath("//div[@class='item']/div[@class='pic']/em/text()").extract()
item['titles'] = selector.xpath("//div[@class='item']/div[@class='info']//span[@class='title'][1]/text()").extract()
item['members'] = selector.xpath("//div[@class='item']/div[@class='info']//p[1]/text()[1]").extract()
item['introductions'] = selector.xpath("//div[@class='item']/div[@class='info']//p[2]/span/text()").extract()
item['scores'] = selector.xpath(
"//div[@class='item']/div[@class='info']//span[@class='rating_num']/text()").extract()
item['imgUrls'] = selector.xpath("//div[@class='item']/div[@class='pic']//img/@src").extract()
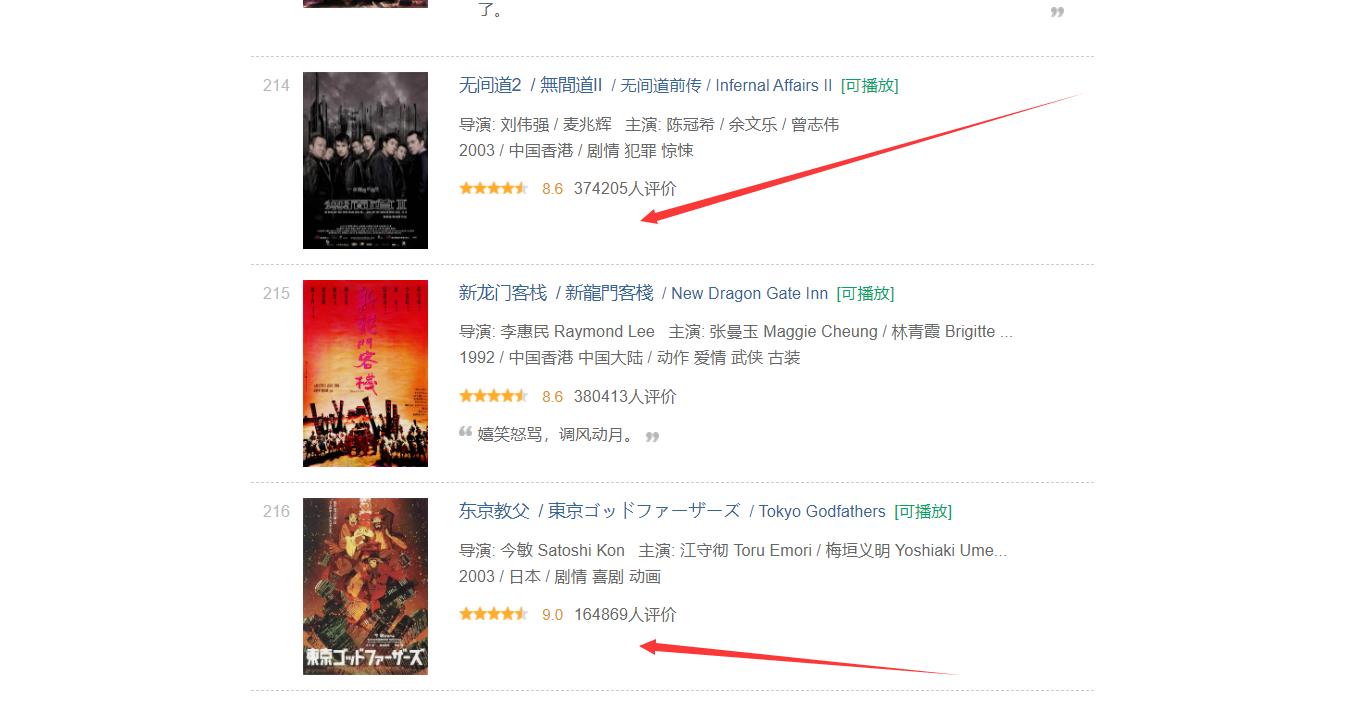
Existing problems
When I finished writing the code according to this idea, I found that this road was blocked, because the "Introduction" field of some movies was empty, so I couldn't correspond one by one.
1.4 final idea
Because the "Introduction" field of some movies is empty, we can only change our thinking.
First, crawl the div tag under the li tag corresponding to each movie to form a list, and then extract the data in each div tag. In this way, each record can be kept corresponding one by one.
1.5 core code
According to the design idea of scrpy framework, crawlers are mainly used to crawl web pages. The data pipeline class is used for data processing. Therefore, the crawler class only needs to obtain the original data we need, and the other data processing operations are completed by the data pipeline class.
Request header:
The request header needs to be set, otherwise it cannot be crawled.
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40'}
Data item class:
Only one field, data, is used to store data for each div tag
class MoviePageItem(scrapy.Item): data = scrapy.Field() # Store data for each div tag pass
Reptiles:
def parse(self, response, **kwargs):
data = response.body.decode(response.encoding)
selector = scrapy.Selector(text=data)
item = MoviePageItem()
item['data'] = selector.xpath("//div[@class='item']").extract()
yield item
Data pipeline class:
Since this topic requires not only the download of pictures, but also the storage of various fields in the database, two data pipeline classes and one database class are required.
Database class: used to connect, create and insert databases
class douBanDB:
def openDB(self):
self.con = sqlite3.connect("DouBan.db")
self.cursor = self.con.cursor()
try:
# Create if database does not exist
self.cursor.execute(
"create table IF NOT EXISTS douban("
"rank TINYINT primary key,"
"name varchar(32),"
"director varchar(32),"
"actor varchar(32),"
"introduction varchar(128),"
"score FLOAT(3,1),"
"path varchar(32))")
except Exception as e:
print(e)
# Method of closing database
def closeDB(self):
self.con.commit()
self.con.close()
# Method of inserting data
def insert(self, data):
try:
self.cursor.execute("insert into douban (rank, name, director, actor, introduction, score, path ) "
"values (?,?,?,?,?,?,?)", data)
except Exception as err:
print(err)
Picture download pipeline class:
class downloadImg(ImagesPipeline):
def get_media_requests(self, item, info):
data = item['data']
for d in data:
selector = scrapy.Selector(text=d)
imgUrl = selector.xpath("//div[@class='pic']//img/@src").extract_first()
title = selector.xpath("//div[@class='info']//span[@class='title'][1]/text()").extract_first()
print("Download cover\t{}".format(title))
yield Request(url=imgUrl, meta={'name': title})
def item_completed(self, results, item, info):
# Is a tuple, and the first element is a Boolean value indicating success
if not results[0][0]:
raise DropItem('Download failed')
return item
# Rename. If you don't rewrite this function, the image name is hash, which is a bunch of messy names
def file_path(self, request, response=None, info=None, *, item=None):
# Receive the picture name passed from the meta above
name = request.meta['name']
return str(name) + '.jpg'
Core code of data processing class:
It mainly includes the analysis and positioning of each field.
Since the director and the actor are connected together, they need to be separated:
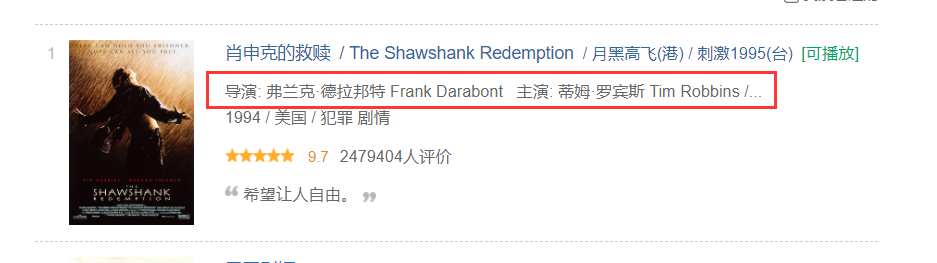
The code is as follows:
members = selector.xpath("//div[@class='info']//p[1]/text()[1]").extract_first().strip() # won director and actor
director = members[3:members.find("main")].strip() # Get director
actor = members[members.find("to star:") + 3:].strip() # performer
if actor == '':
actor = None
setting:
You need to configure the following:
It should be noted that:
1. ROBOTS Protocol to be set to False,Otherwise, the picture cannot be downloaded. 2. Since there are two data pipeline classes, you need to configure two pipelines in the configuration file.
BOT_NAME = 'hw_3'
SPIDER_MODULES = ['hw_3.spiders']
NEWSPIDER_MODULE = 'hw_3.spiders'
LOG_LEVEL = 'WARNING'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.2
IMAGES_STORE = './imgs'
ITEM_PIPELINES = {
'hw_3.pipelines.Hw3Pipeline': 300,
'hw_3.pipelines.downloadImg': 400,
}
1.6 result display
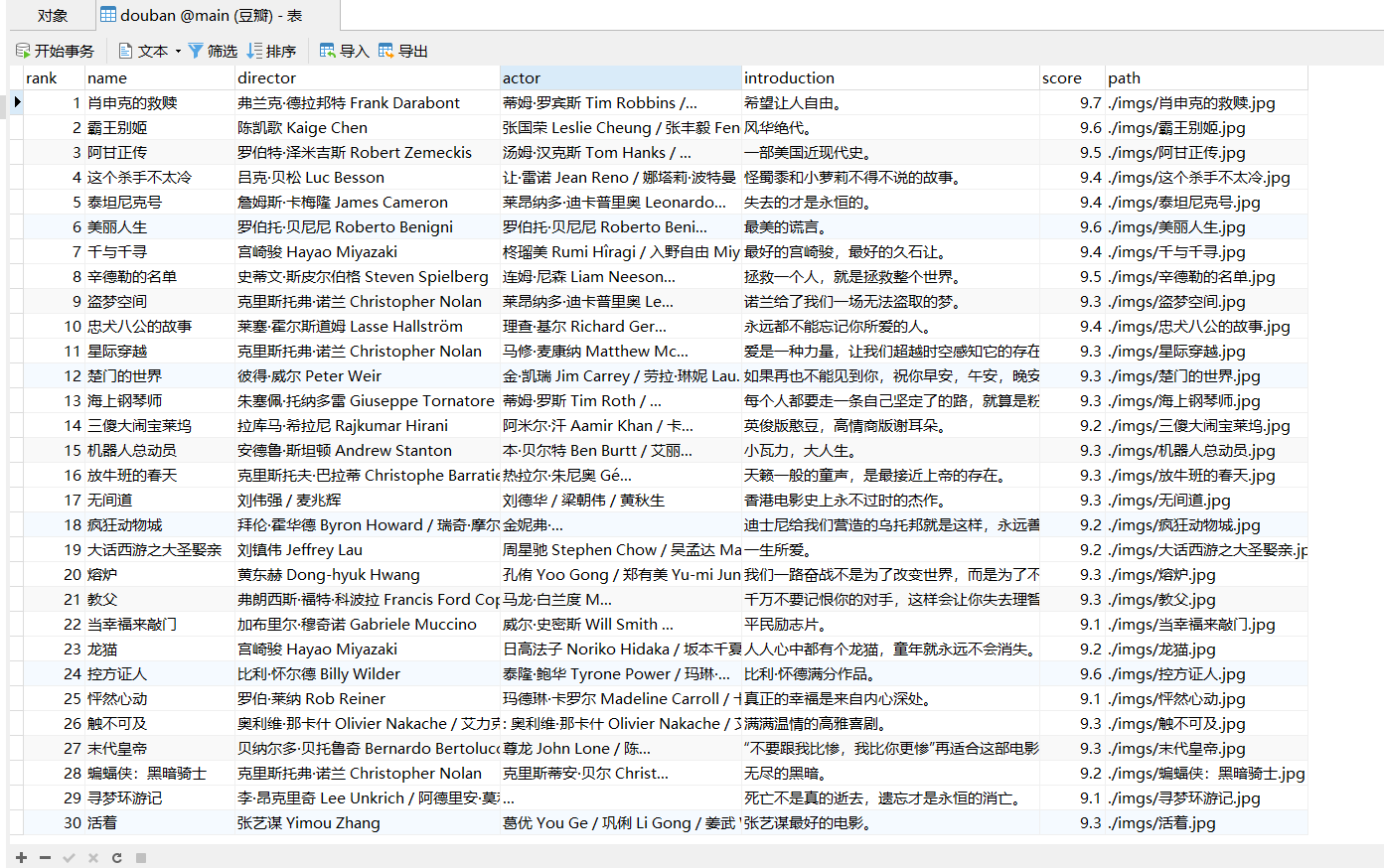
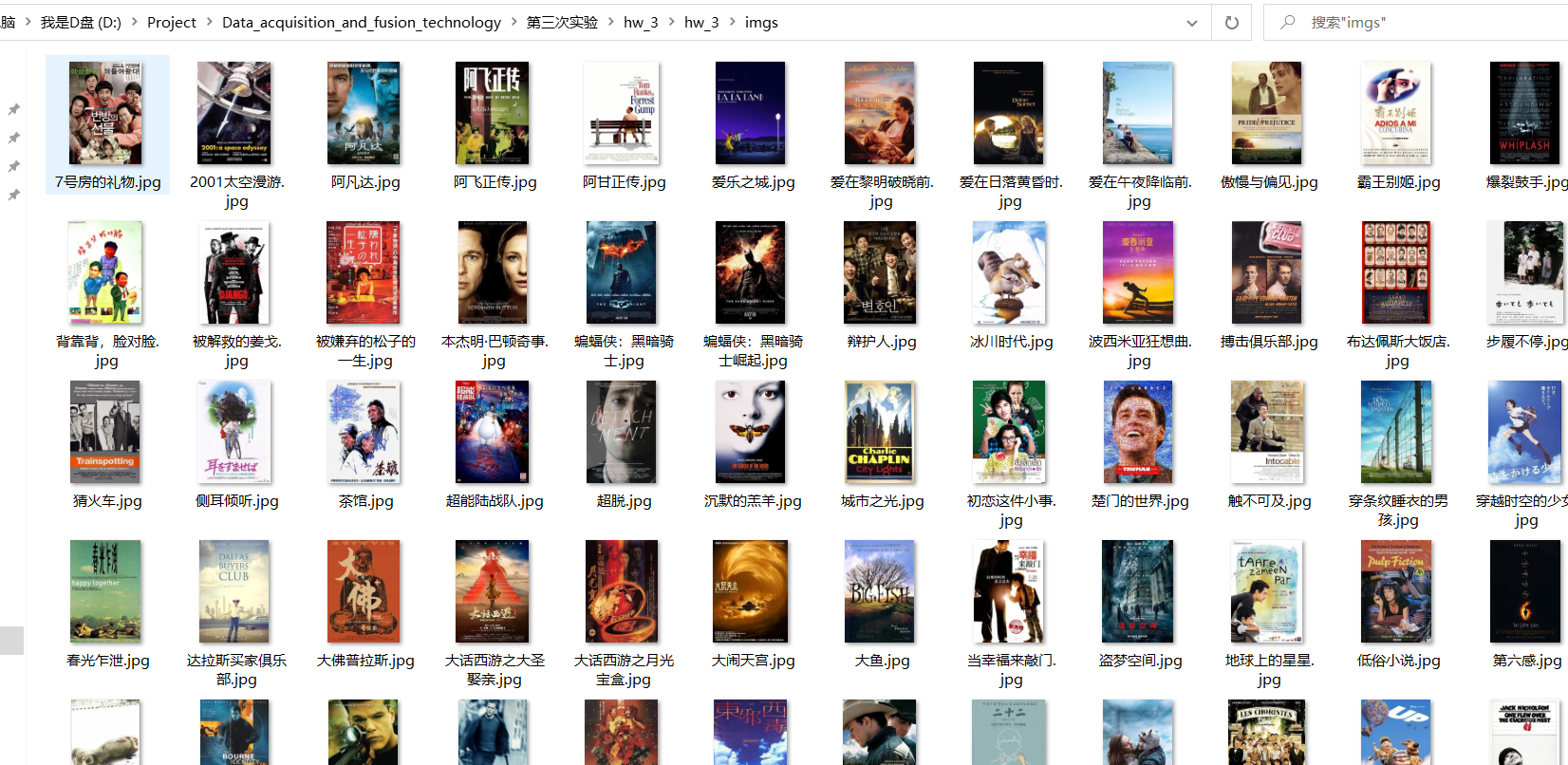
2. Experience
1. The request header needs to be set, otherwise it cannot be crawled. 2. I realize again setting Your settings are important, ROBOTS Protocol to be set to False,Otherwise, the picture cannot be downloaded. Because there are two data pipeline classes, you need to configure two pipelines in the configuration file. 3. After crawling, check whether the results correspond. If not, other ideas can be adopted for crawling.