Share some previous projects and accumulate some project experience
We talked about how to configure the scratch redis earlier. This time, we'll do a collection example
The website is the other shore map network: https://pic.netbian.com/4kmeinv/
analysis
Collect all the pictures under the above link classification, analyze the website is 148 pages, read the link on the next page to the next page, read the picture link above to enter the address of the larger picture for details
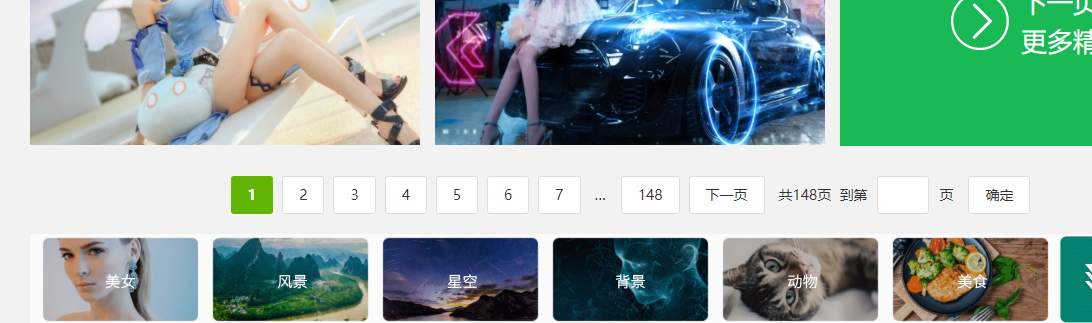
Operation effect
redis storage content

Breakpoint continuation
After stopping halfway, you can also re-enter the command on the command line to continue

Run it again, or start there and continue
data processing
Database design
The database stores the title and download url of the big picture
The table creation statement is
CREATE TABLE `db1`.`pictable` ( `id` INT NOT NULL AUTO_INCREMENT, `title` VARCHAR(100) NOT NULL COMMENT 'Picture title', `picurl` VARCHAR(150) NOT NULL COMMENT 'Picture address', PRIMARY KEY (`id`)) COMMENT = 'Picture address storage table';
items file
The following two fields can be placed in the items file, and the id field is automatically generated
class MyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
picurl=scrapy.Field()
Pipeline treatment
The pipeline mainly starts and closes the database, and simply checks the data and stores it in the database
import pymysql
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
class MyPipeline:
def open_spider(self, spider):
self.client = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='sa123456',
database='db1',
charset='utf8'
)
self.cursor = self.client.cursor()
def close_spider(self, spider):
self.cursor.close()
self.client.close()
def process_item(self, item, spider):
title = item['title']
picurl = item['picurl']
print('preservation%s'%title)
sql = f"select * from pictable where title='{title}' and picurl='{picurl}'"
print(sql)
rows = self.cursor.execute(sql)
if rows == 0:
sql2 = f"insert into pictable(title,picurl) values ('{title}','{picurl}')"
self.cursor.execute(sql2)
print('A new piece of data has been added')
self.client.commit()
else:
print(f'Data({title},{picurl})Already exists')
raise DropItem
return item
Basic settings
Make the following settings in the setting file, and pay attention to the opening of the pipeline and the adjustment of UA
# Distributed configuration SCHEDULER = "scrapy_redis.scheduler.Scheduler" # dispatch DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # duplicate removal SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # Priority of tasks SCHEDULER_PERSIST = True # SCHEDULER_FLUSH_ON_START = True # You have a password redis://user:password@IP:port/db REDIS_URL = 'redis:/Yours redis'
Main crawler
The parse function is the default handler that handles links similar to each page
The imgdownload function handles the links behind the displayed images on each page
The downloader handles the downloading of image files
import scrapy
import logging
from scrapy.selector import Selector
from scrapy_redis.spiders import RedisSpider
from my.items import MyItem
class StaSpider(RedisSpider):
name = 'sta'
# allowed_domains = ['*']
baseurl = 'http://pic.netbian.com'
# start_urls = ['https://pic.netbian.com/4kmeinv/']
def parse(self, response):
print('Start a reptile')
logging.warning('Start a reptile')
# print(response.text)
selector=Selector(text=response.text)
pics=selector.xpath('//*[@id="main"]/div[3]/ul/li/a/@href').extract()
nextselector=selector.xpath('//*[@ id="main"]/div[4]/a[text() = "next] / @ href ')
print(pics)
print(nextselector)
if nextselector:
nextpage=nextselector.extract_first()
print(nextpage)
else:
nextpage=None
if nextpage:
print('Go to the next page',self.baseurl+nextpage)
yield scrapy.Request(self.baseurl+nextpage,callback=self.parse)
for i in pics:
print('Enter picture page',self.baseurl+i)
yield scrapy.Request(self.baseurl+i,callback=self.imgdownload)
def imgdownload(self,response):
logging.warning('Start a page')
# print(response.text)
selector=Selector(text=response.text)
pics=selector.xpath('//*[@id="img"]/img/@src').extract_first()
print(pics)
title=selector.xpath('//*[@id="main"]/div[2]/div[1]/div[1]/h1/text()').extract_first()
print(title)
picurl=self.baseurl+pics
item=MyItem()
item['title']=title
item['picurl']=picurl
yield item
print('Enter the download page',picurl)
yield scrapy.Request(picurl,callback=self.downloader,meta={'title':title})
def downloader(self,response):
print('Enter the download page')
title=response.meta.get('title')
with open('pics/'+title+'.jpg','wb') as f:
f.write(response.body)
Operation method
Direct operation
For the first time, start and run the command line under the project directory
scrapy crawl xxx
xxx is the name of the main crawler, and then push your starting URL in the redis library

After the interruption, the command can be directly re executed on the command line to continue the transmission at the breakpoint, which is also the result of the distribution
Scrapd deployment
Configure the scene.cfg file

Then start scrapd at a terminal
scrapyd
The other terminal is deployed first
scrapyd-deploy mypro -p my
Restart
curl http://localhost:6800/schedule.json -d project=my -d spider=sta
sta is my spider name, which can be adjusted according to my own crawler name
my is the project name
mypro is the name of the configuration
When running, you can see the running in the web interface
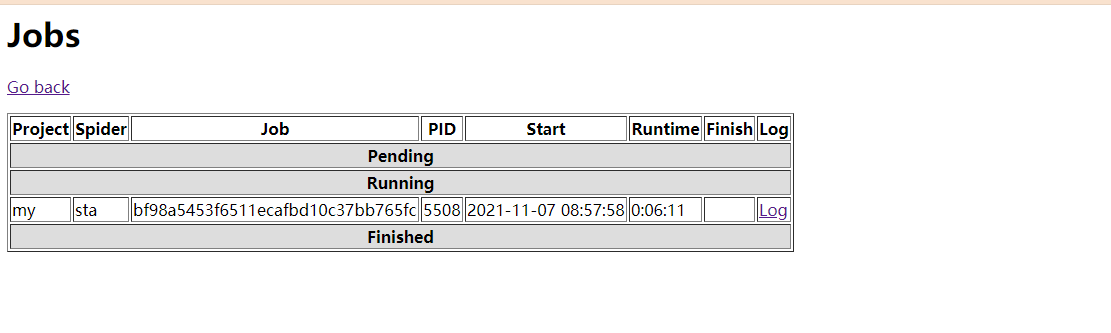
Push a new URL in redis
You can see that the logs show that it is running
But there was a mistake. My request was turned off by the opposite server

This is definitely not the reason for scrapd. We'll debug it later
Stop project
curl http://localhost:6800/cancel.json -d project=my -d job=bf98a5453f6511ecafbd10c37bb765fc
Adjust settings
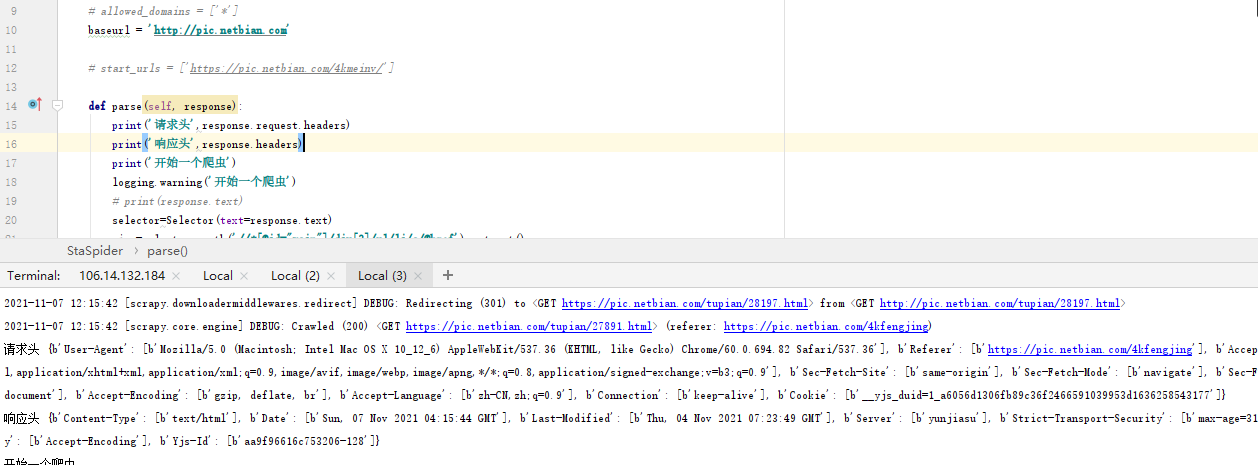
I found that I was redirected once when I visited the web page in the browser. The ip should not be closed, but there is redirection
Charles, it's obvious from the data
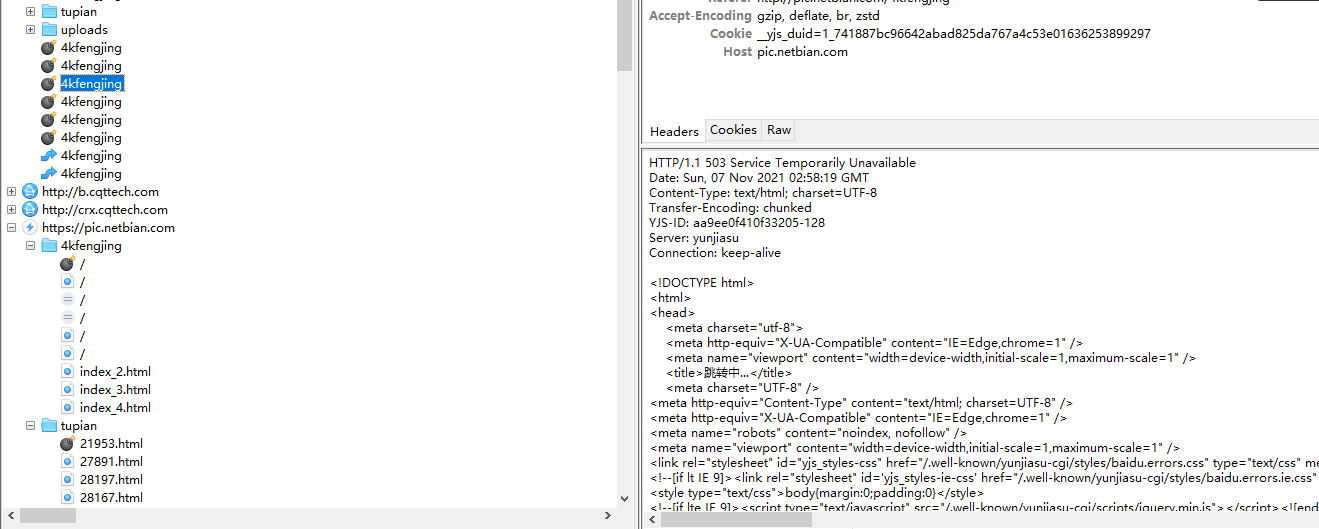
Modify headers
A random UA middleware is made here, but it is useless. If redirection, consider setting a long link in the headers
Modify in settings
DEFAULT_REQUEST_HEADERS = {
'referer':'https://pic.netbian.com/4kfengjing',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-dest': 'document',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'connection':'keep-alive',
}
This is called in the default middleware. The location is
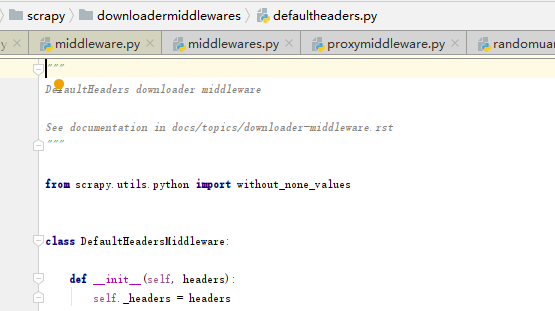
The default sorting values of the request header and the middleware of the user agent can be found in the defaultsettings file

If you set the random UA through the customized middleware and put it in front of the headers setting, what may be the problem
At present, there is no coverage here
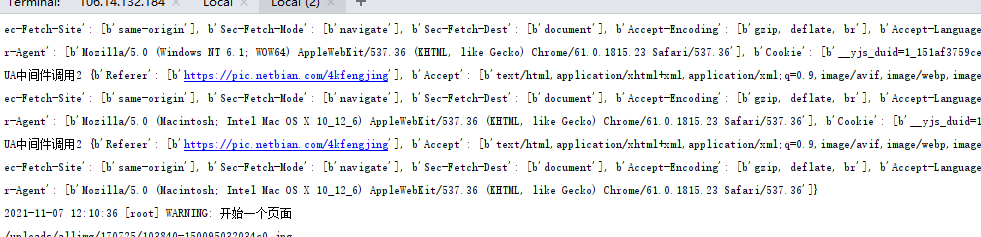
Random UA code reference
Here is to take the default UA middleware code, write a random UA class, and then set the UA in the request processing function
from collections import defaultdict, deque
import logging
import pprint
from scrapy import signals
from scrapy.exceptions import NotConfigured
from scrapy.utils.misc import create_instance, load_object
from scrapy.utils.defer import process_parallel, process_chain, process_chain_both
logger = logging.getLogger(__name__)
import random
class MyUA:
first_num = random.randint(55, 62)
third_num = random.randint(0, 3200)
fourth_num = random.randint(0, 140)
os_type = [
'(Windows NT 6.1; WOW64)', '(Windows NT 10.0; WOW64)', '(X11;Linux x86_64)','(Macintosh; Intel Mac OS X 10_12_6)'
]
chrome_version = 'Chrome/{}.0.{}.{}'.format(first_num, third_num,
fourth_num)
@classmethod
def get_ua(cls):
return ' '.join(['Mozilla/5.0', random.choice(cls.os_type),
'AppleWebKit/537.36','(KHTML, like Gecko)', cls.chrome_version,
'Safari/537.36'])
class RandomUAMiddleware(object):
"""This middleware allows spiders to override the user_agent"""
# def __init__(self, user_agent='Scrapy'):
# self.user_agent = MyUA.get_ua()
#Do not process UA in settings
# @classmethod
# def from_crawler(cls, crawler):
# o = cls(crawler.settings['USER_AGENT'])
# crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
# return o
#
# def spider_opened(self, spider):
# self.user_agent = self.user_agent
def process_request(self, request, spider):
request.headers[b'User-Agent']= MyUA.get_ua()
# print('UA middleware call 2',request.headers)
proxy server
If it is a proxy server proxies, you can purchase the available ip at the relevant website and process it with middleware. As shown below, the request after the proxy ip is used
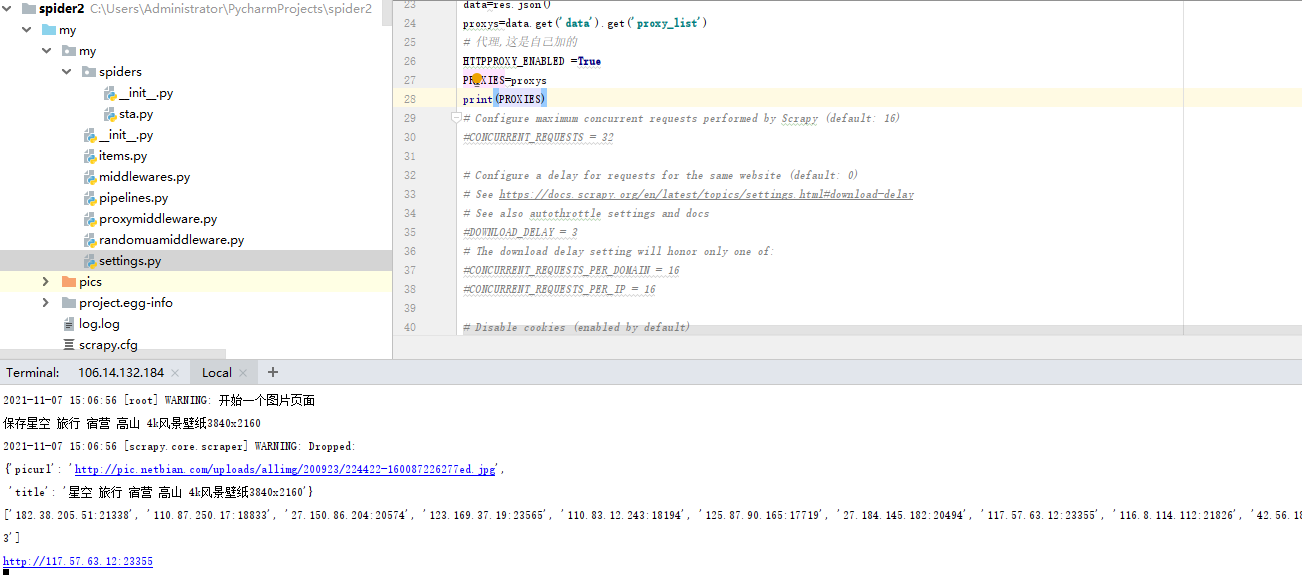
The use of IP has a time limit. It is recommended to add a program to dynamically re extract IP from the IP website
Code reference:
There are two items in the setting: PROXIES and HTTPPROXY_ENABLED. The former is a list and the latter is a Boolean value
The proxy IP I purchased has an extraction interface, which extracts a certain amount immediately. What I get is the IP: the form of the port. The format should be adjusted according to the form. Finally, it is submitted to the request http://ip:port Form of
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
import random
from collections import defaultdict
from scrapy import signals
from scrapy.exceptions import NotConfigured
from twisted.internet.error import ConnectionRefusedError, TimeoutError
class RandomProxyMiddleware:
def __init__(self, settings):
# 2. Initialize configuration and related variables
self.proxies = settings.getlist('PROXIES')
self.stats = defaultdict(int)
self.max_failed = 3
@classmethod
def from_crawler(cls, crawler):
# 1. Create middleware object
if not crawler.settings.getbool('HTTPPROXY_ENABLED'):
raise NotConfigured
return cls(crawler.settings)
def process_request(self, request, spider):
# 3. Assign a random IP proxy to each request object
if self.proxies and not request.meta.get('proxy') \
and request.url not in spider.start_urls:
print(self.proxies)
request.meta['proxy'] = 'http://'+random.choice(self.proxies)
print(request.meta['proxy'])
def process_response(self, request, response, spider):
# 4. If the request is successful, call process_response
cur_proxy = request.meta.get('proxy')
# Judge whether it is banned by the other party
if response.status in (401, 403):
# Give the corresponding IP failure times + 1
self.stats[cur_proxy] += 1
print('%s got wrong code %s times' % (cur_proxy, self.stats[cur_proxy]))
# When the failure times of an IP have accumulated to a certain number
if self.stats[cur_proxy] >= self.max_failed:
print('got wrong http code (%s) when use %s' \
% (response.status, cur_proxy))
# It can be considered that the IP is blocked by the other party. Delete the IP from the proxy pool
self.remove_proxy(cur_proxy)
del request.meta['proxy']
# Reschedule the request for download
return request
return response
def process_exception(self, request, exception, spider):
# 4. If the request fails, call process_exception
cur_proxy = request.meta.get('proxy')
# If the proxy is used in this request and the network request reports an error, it is considered that there is a problem with the IP
if cur_proxy and isinstance(exception, (ConnectionRefusedError, TimeoutError)):
print('error (%s) occur when use proxy %s' % (exception, cur_proxy))
self.remove_proxy(cur_proxy)
del request.meta['proxy']
return request
def remove_proxy(self, proxy):
if proxy in self.proxies:
self.proxies.remove(proxy)
print('remove %s from proxy list' % proxy)