Hello ~ I'm Cha Cha, long time no see ~ the fun of Python is that it can achieve many things that can't be done manually in the Internet age~ Although I don't often play games, I'm very excited about my damn patriotism when EDG won the championship!
On November 6, Beijing time, in the S11 finals of the League of heroes, EDG E-sports Club of the Chinese LPL division beat DK of the Korean LCK division by 3:2 to win the global finals of the League of heroes in 2021.
This competition has also attracted the attention of the whole network:
Microblog hot search ranked first, showing 81.94 million viewers;
bilibili platform, attracting 350 million people, full screen barrage;
Tencent video has been seen by 6 million people;
The heat of Betta and tiger tooth platform is also high;
After the competition, CCTV news also sent a microblog to congratulate EDG team on winning the championship;
We can not only feel the whole process of the game through live broadcast and news, but also feel the enthusiasm of fans by analyzing hot spots through Python.

1. Brief description
It doesn't matter if you haven't seen the live broadcast. There's a replay! The whole video has been sorted out for everyone, from the opening ceremony, to five games, and then to the moment of winning the championship, a total of 7 videos.
In each video, there are bullet screens released by fans. What we need to do today is to get the bullet screen data in each video and see what the fans say in a restless mood?
I have to say that the change speed of the website of station B is really fast. I remember it was easy to find last year. But I haven't found it today.
But it doesn't matter. We just take the previous barrage data website interface and use it.
API: https://api.bilibili.com/x/v1/dm/list.so?oid=XXX
This oid is actually a string of numbers. Each video has a unique oid.
2. oid data search
This section takes you step by step to find this oid. To find an oid, you must first find something called cid.
Click F12, open the developer tool first, and complete the operations in 1-5 according to the prompts in the figure.
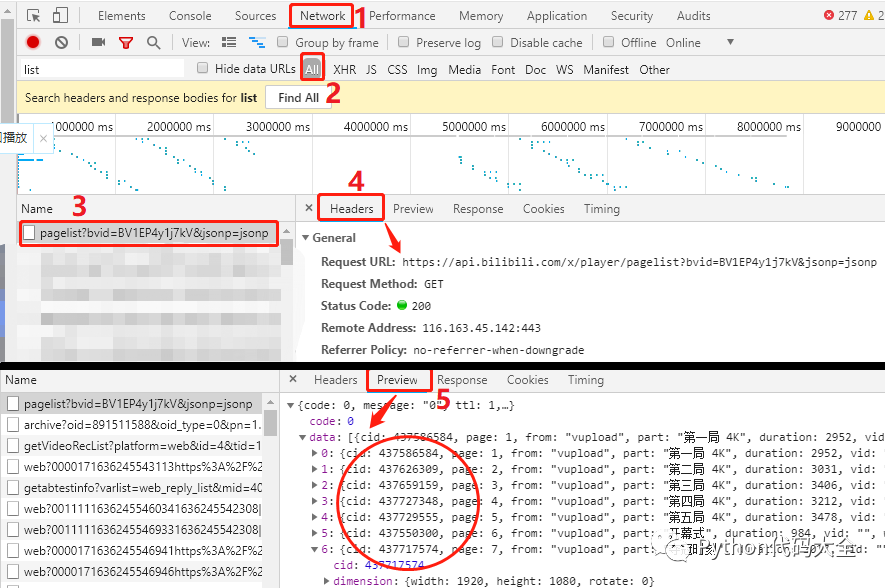
Place 3: there are many requests on this page, but you need to find the request starting with pagelist.
Place 4: under the corresponding Header, there is a Request URL, and the cid we want is in this URL.
Place 5: under the corresponding Preview, the Request URL is the result of the response to us. The cid data we want is circled in the figure.
2. cid data acquisition
We have found the Request URL above. Now we just need to make a request and get the cid data inside.
import requestsimport jsonurl = 'https://api.bilibili.com/x/player/pagelist?bvid=BV1EP4y1j7kV&jsonp=jsonp'res = requests.get(url).textjson_dict = json.loads(res)#pprint(json_dict) for i in json_dict["data"]: oid = i["cid"] print(oid)
In fact, the number string corresponding to cid here is the number string after oid.
3. Splicing url
We have not only the barrage api interface, but also the cid data. Then we can splice them to get the final url.
url = 'https://api.bilibili.com/x/player/pagelist?bvid=BV1EP4y1j7kV&jsonp=jsonp'res = requests.get(url).textjson_dict = json.loads(res)#pprint(json_dict) for i in json_dict["data"]: oid = i["cid"] api = "https://api.bilibili.com/x/v1/dm/list.so?oid=" url = api + str(oid) print(url)
There are 7 websites, corresponding to the barrage data in 7 videos.
Click any one to view:
4. Extract and save the barrage data
With a complete url, all we have to do is extract the data inside. Here, we still use regular expressions directly. Let's take one of the videos as an example to explain it to you.
final_url = "https://api.bilibili.com/x/v1/dm/list.so?oid=437729555"final_res = requests.get(final_url)final_res.encoding = chardet.detect(final_res.content)['encoding']final_res = final_res.textpattern = re.compile('<d.*?>(.*?)</d>')data = pattern.findall(final_res)
with open("bullet chat.txt", mode="w", encoding="utf-8") as f: for i in data: f.write(i) f.write("\n")This is only one page of data, with a total of 7200 data.
Extract the barrage program code completely, and the extracted Barrage is stored in "barrage. txt".
import osimport requestsimport jsonimport reimport chardet
# Get ciddef get_ cid(): url = ' https://api.bilibili.com/x/player/pagelist?bvid=BV1EP4y1j7kV&jsonp=jsonp ' res = requests.get(url).text json_ dict = json.loads(res) cid_ list = [] for i in json_ dict["data"]: cid_ list.append(i["cid"]) return cid_ list
# Splice urldef concat_url(cid): api = "https://api.bilibili.com/x/v1/dm/list.so?oid=" url = api + str(cid) return url
# Regular extract data def get_ data(url): final_ res = requests.get(url) final_ res.encoding = chardet.detect(final_res.content)['encoding'] final_ res = final_ res.text pattern = re.compile('<d.*?>(.*?)</d>') data = pattern.findall(final_res) return data
# Save data def save_ to_ File (data): with open ("barrage data. TXT", mode = "a", encoding = "UTF-8") as F: for I in data: f.write (I) f.write ("\ n")
cid_list = get_cid()for cid in cid_list: url = concat_url(cid) data = get_data(url) save_to_file(data)Turn the extracted barrage data into a complete code of word cloud picture
# 1 import related libraries import pandas as pdimport jiebfrom wordcloud import wordcloudimport matplotlib.pyplot as pltfrom imageio import imread
import warningswarnings.filterwarnings("ignore")
# Note: dynamically add the word set for i in ["EDG", "eternal God", "yyds", "Niubi", "send a congratulatory message]: jieba.add_word(i)
# 2 read the text file and use the lcut() method for word segmentation with open("barrage data. TXT", encoding = "UTF-8") as F: TXT = f.read() TXT = TXT. Split() TXT = [i.upper() for I in txt] data_ cut = [jieba.lcut(x) for x in txt]
# 3 read the stop word with open ("stoplist. TXT", encoding = "UTF-8") as F: stop = f.read() stop = stop. Split() stop = [""] + stop
# 4 remove the final word s after the stop word_ data_ cut = pd.Series(data_cut)all_ words_ after = s_ data_ cut.apply(lambda x:[i for i in x if i not in stop])
# 5 word frequency statistics_ words = []for i in all_ words_ after: all_ words.extend(i)word_ count = pd.Series(all_words).value_ counts()
# 6 Drawing of word cloud map# 1) Read background picture back_picture = imread("EDG.jpg")
# 2) Set the word cloud parameter WC = wordcloud (font_path = "simhei. TTF", background_color = "white", max_words = 1000, mask = back_picture, max_font_size = 200, random_state = 42) wc2 = wc.fit_ words(word_count)
# 3) Draw word cloud picture plt.figure(figsize=(16,8))plt.imshow(wc2)plt.axis("off")plt.show()wc.to_file("ciyun.png") 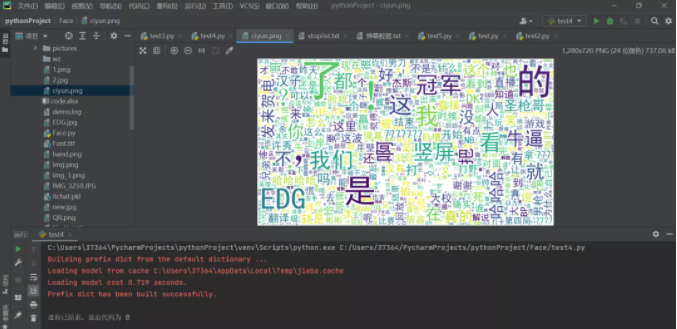
In the past, many people would say that games are not good things and lose heart, but EDG and IG are using facts to prove that no matter what we are doing, we will play a good role. Just like learning Python, some people may think it is a programming language? What's great, but with the increasing development of artificial intelligence, Python plays an important role, so students, don't underestimate him for anything, just study hard!