"The ancients' knowledge is weak, but their Kung Fu can only be achieved when they are young and old."
What has the final say of python crawler love? What kind of novels do you like to download? You can count on yourself. Download the crawler tutorial in super detailed novels, Download novels with python, and read novels whenever and wherever possible. Is it uncomfortable? Learning the idea of downloading novels in python is the most important. I hope it can open the door to independent thinking and guide you to analyze problems independently. If this article can bring you some help, I hope to give little brother flying rabbit one key three times to express support. Thank you, little friends.
Note: the source code has been uploaded, please click here Open source python download novel Welcome to the work, fork and star companies. There are also hidden benefits~
catalogue
1, Analyze the novel download process
6, Download the contents of each chapter
1, Analyze the novel download process
- To download a novel, we need to find a novel website for download logic analysis
- The novel website we choose here is: 4020 eBook
- Because the novel content is easy to detect violations, resulting in the closure of the website. If you can't access it when you visit, please choose another platform. The download logic of analysis is interconnected, because all laws are one
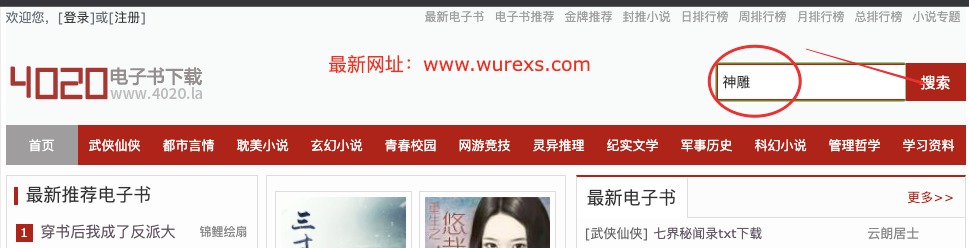
- The logic of novel download should be: select the search box, enter keywords, search novels, select the novels you want to download in the search results, and then download each chapter of the novel to the same local file
2, Analyze search links
- Because we need to find the search results page to see how many keyword novels there are
- It can be seen that www.wurexs.com/so.html?q = keyword is the search result page
- Then we can write this through python code

keywords = input('Please enter keywords:') or "Divine carving"
response = requests.get('https://www.wurexs.com/so.html?q={}'.format(keywords))3, Get a list of Novels
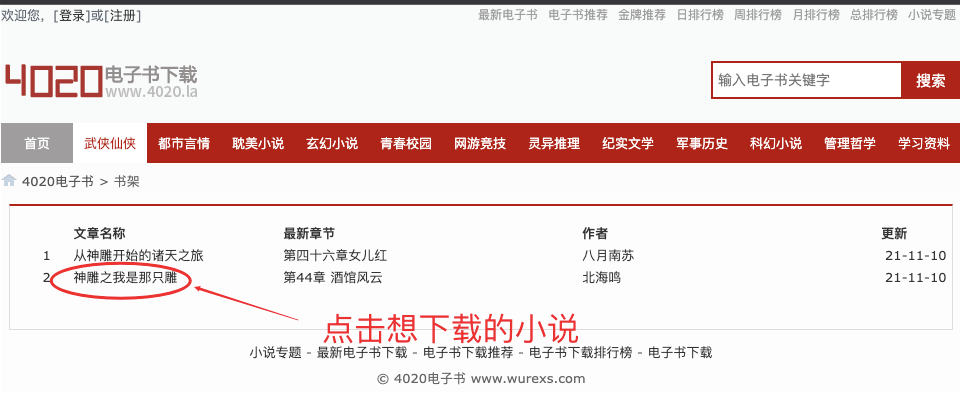
- Get the number of novels and their corresponding addresses on the search results page
- Analyze the Html document structure of the search page using beautiful soup
fictionsList = []
response = requests.get('https://www.wurexs.com/so.html?q={}'.format(keywords))
offset = 0
soup = BeautifulSoup(response.content, 'lxml')
for fiction in soup.find('table', class_='grid').find_all('tr'):
offset += 1
if offset != 1:
fictionDom = fiction.find('td', class_='even')
fictionName = fictionDom.a.string
MenuUrl = fictionDom.a['href']
fictionsList.append(fictionName + "#" + MenuUrl)
print('---Search results of{}This novel...' . format(len(fictionsList)))4, Select novel serial number
- Select the serial number of the novel you want to download
- The first download is selected by default
for i in range(len(fictionsList)):
print('{} {}' .format(i, fictionsList[i].split('#')[0]))
k = input('---Please select the serial number of the novel you want to download:')
k = int(k) if k else 05, Get novel chapter address
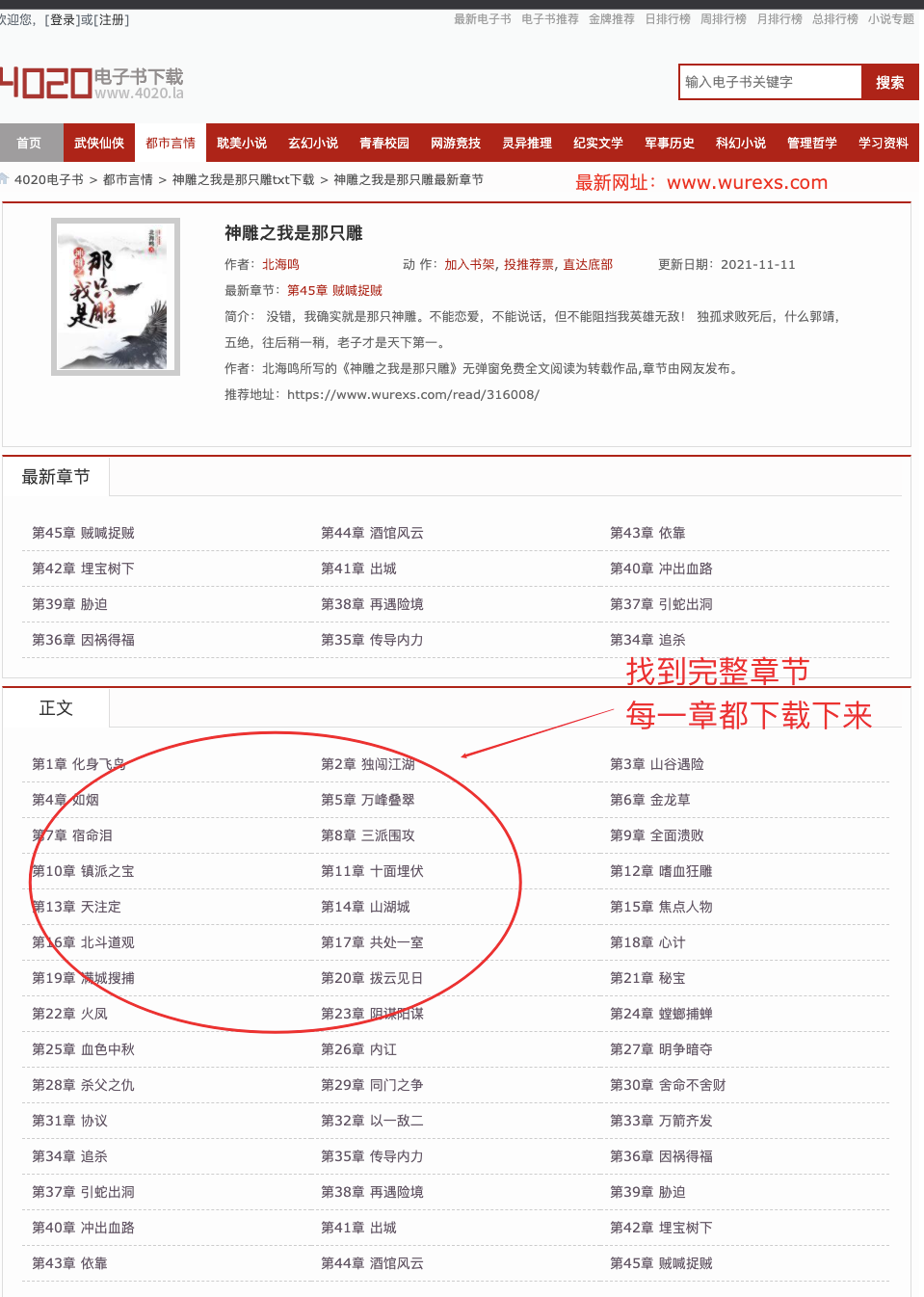
- Enter the novel details page to get the address of each chapter of the novel
- Because all chapters are below the text, we can locate the details of each chapter through the text

chapterList = []
response = self.request(self.rootUrl + MenuUrl)
soup = BeautifulSoup(response.content, 'lxml')
allChapterUrl = soup.find(text='text').find_parent("div", class_='showBox').find_all('li')
if allChapterUrl:
for chapter in allChapterUrl:
chapterName = chapter.a.string
chapterUrl = chapter.a['href']
chapterList.append(chapterName + "#" + MenuUrl + chapterUrl)
return chapterList6, Download the contents of each chapter
- After obtaining each chapter and chapter address
- We need to download the chapter details and save them in the same file
- For detailed code, please visit brother flying rabbit's open source library Open source python download novel
offset = 0
for chapter in chapterList:
offset += 1
chapterName, chapterUrl = [item for item in chapter.split('#')]
response = self.request(self.rootUrl + chapterUrl)
soup = BeautifulSoup(response.content, 'lxml')
with open('{}/{}.txt' . format(savePath, fictionName), "a", encoding="utf-8") as f:
f.write(chapterName + '\n')
for str in soup.find(id='content').strings:
if 'www.wrlwx.com' in str:
continue
if 'www.shukuai.com' in str:
continue
f.writelines(str)
f.write('\n\n')
print("{} Downloading, current{}, speed of progress{}/{}" 7, Download Preview
- After we run the code, enter the keyword to download
