- 🎉 Fan welfare book: Java multithreading and big data processing practice
- 🎉 give the thumbs-up 👍 Collection ⭐ Leaving a message. 📝 You can participate in the lucky draw to send books
- 🎉 At 20:00 p.m. next Tuesday (November 17), a fan will be selected in the [praise area and comment area] to send the book of Peking University Press~ 🙉
- 🎉 Please see the final introduction for details~ ✨

Experiment 1
1.1 title
Master the serialization output method of Item and Pipeline data in the scene;
Scrapy+Xpath+MySQL database storage technology route crawling Dangdang website book data
Candidate sites: http://www.dangdang.com/
1.2 ideas
1.2.1 setting.py
-
Open request header

-
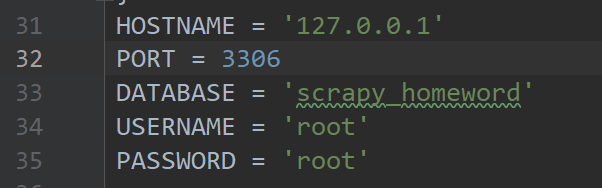
Connection database information
-
ROBOTSTXT_OBEY is set to False

-
Open pipelines

1.2.2 item.py
Write the field of item.py
class DangdangItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()
date = scrapy.Field()
price = scrapy.Field()
detail = scrapy.Field()
1.2.3 db_Spider.py
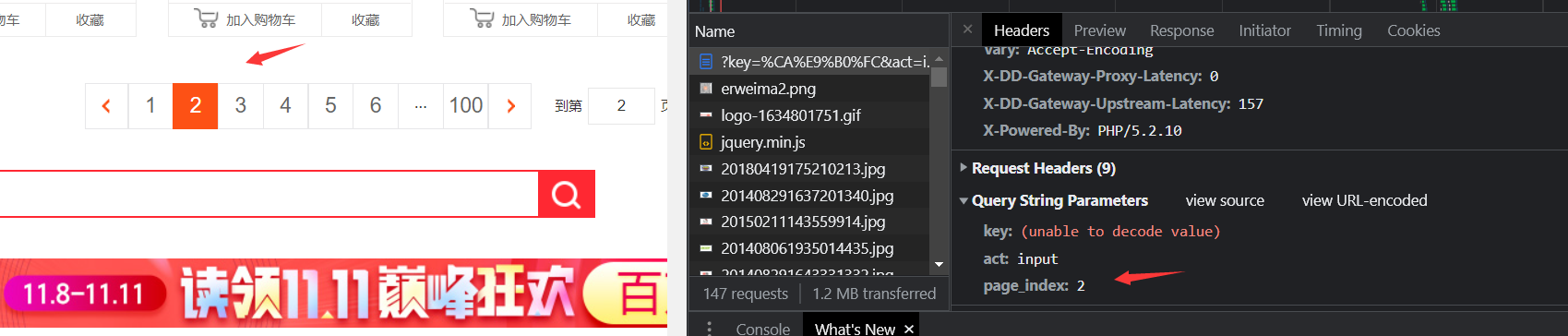
- Look at the page and see the page
Page 2
Page 3
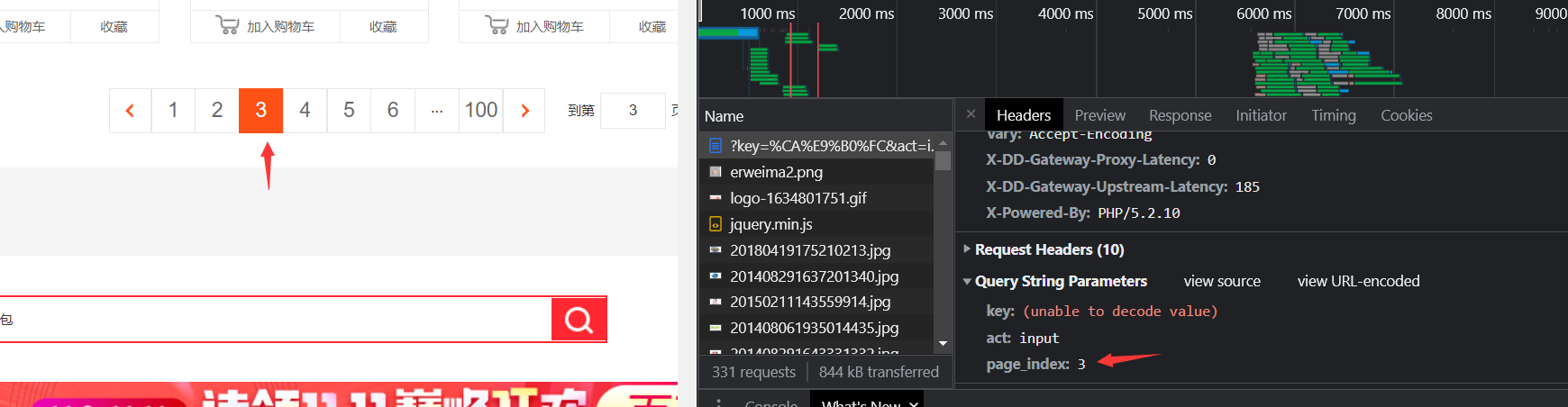
So it's easy to find this page_index is the paging parameter
- Get node information
def parse(self, response):
lis = response.xpath('//*[@id="component_59"]')
titles = lis.xpath(".//p[1]/a/@title").extract()
authors = lis.xpath(".//p[5]/span[1]/a[1]/text()").extract()
publishers = lis.xpath('.//p[5]/span[3]/a/text()').extract()
dates = lis.xpath(".//p[5]/span[2]/text()").extract()
prices = lis.xpath('.//p[3]/span[1]/text()').extract()
details = lis.xpath('.//p[2]/text()').extract()
for title,author,publisher,date,price,detail in zip(titles,authors,publishers,dates,prices,details):
item = DangdangItem(
title=title,
author=author,
publisher=publisher,
date=date,
price=price,
detail=detail,
)
self.total += 1
print(self.total,item)
yield item
self.page_index += 1
yield scrapy.Request(self.next_url % (self.keyword, self.page_index),
callback=self.next_parse)
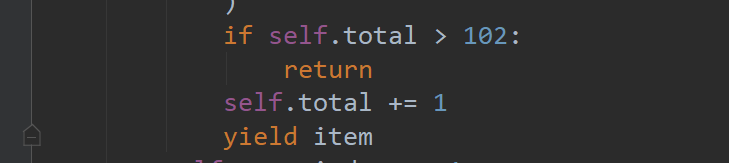
- Specify the number of crawls
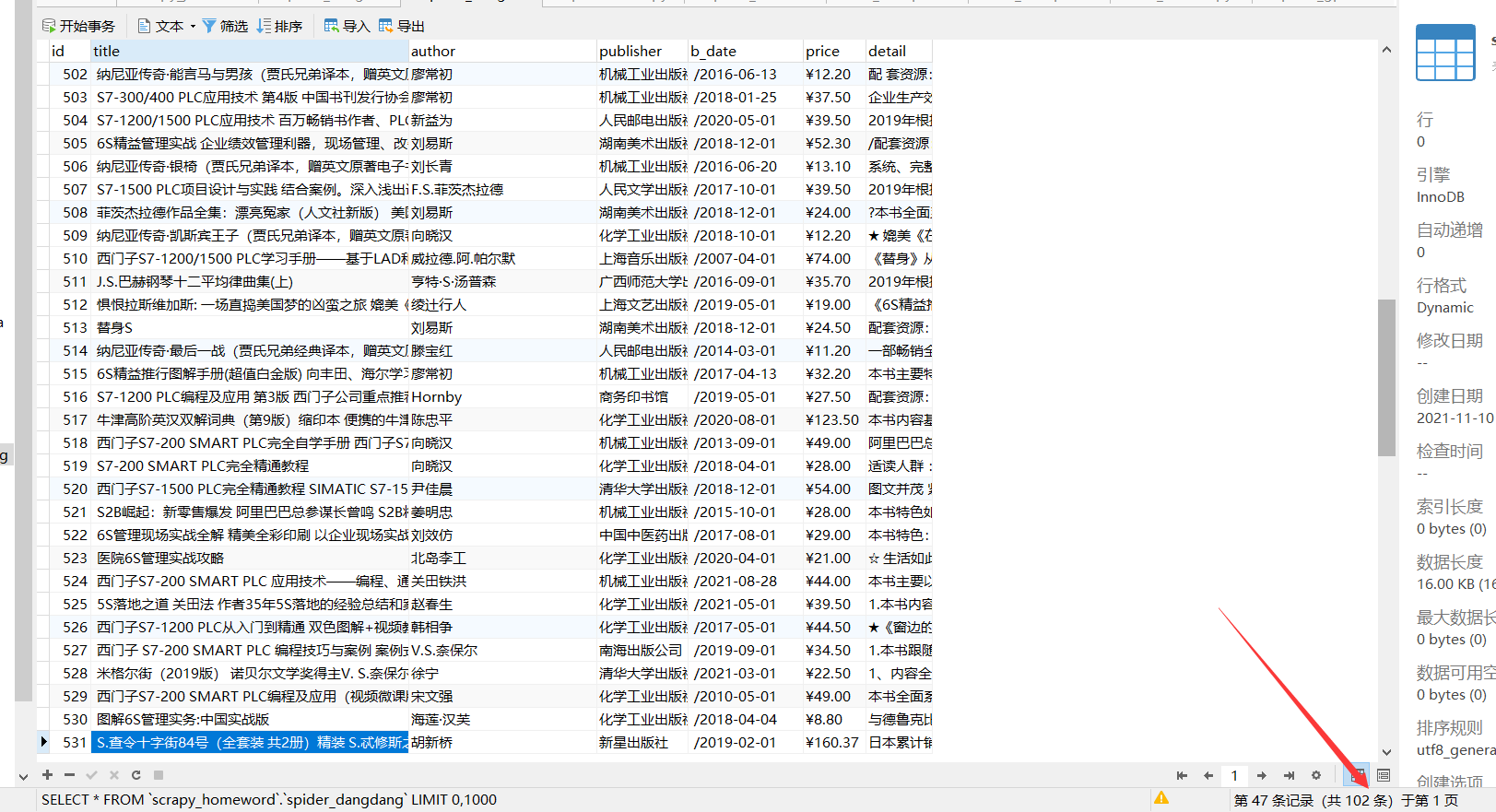
Climb 102
1.2.4 pipelines.py
- Database connection
def __init__(self):
# Get the host name, port number and collection name in setting
host = settings['HOSTNAME']
port = settings['PORT']
dbname = settings['DATABASE']
username = settings['USERNAME']
password = settings['PASSWORD']
self.conn = pymysql.connect(host=host, port=port, user=username, password=password, database=dbname,
charset='utf8')
self.cursor = self.conn.cursor()
- insert data
def process_item(self, item, spider):
data = dict(item)
sql = "INSERT INTO spider_dangdang(title,author,publisher,b_date,price,detail)" \
" VALUES (%s,%s, %s, %s,%s, %s)"
try:
self.conn.commit()
self.cursor.execute(sql, [data["title"],
data["author"],
data["publisher"],
data["date"],
data["price"],
data["detail"],
])
print("Insert successful")
except Exception as err:
print("Insert failed", err)
return item
The result shows that there are 102 pieces of data in total. I set this id to increase automatically. Because there is data insertion in the previous test, the id does not start from 1
Experiment 2
2.1 title
Requirements: master the serialization output method of Item and Pipeline data in the scene; Crawl the foreign exchange website data using the technology route of "scratch framework + Xpath+MySQL database storage".
Candidate website: China Merchants Bank Network: http://fx.cmbchina.com/hq/
2.2 ideas
2.2.1 setting.py
It is similar to setting.py in 1.2.1, but there is no more display
2.2.2 item.py
Write item.py
class CmbspiderItem(scrapy.Item):
currency = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
time = scrapy.Field()
2.2.3 db_Spider.py
- Data analysis
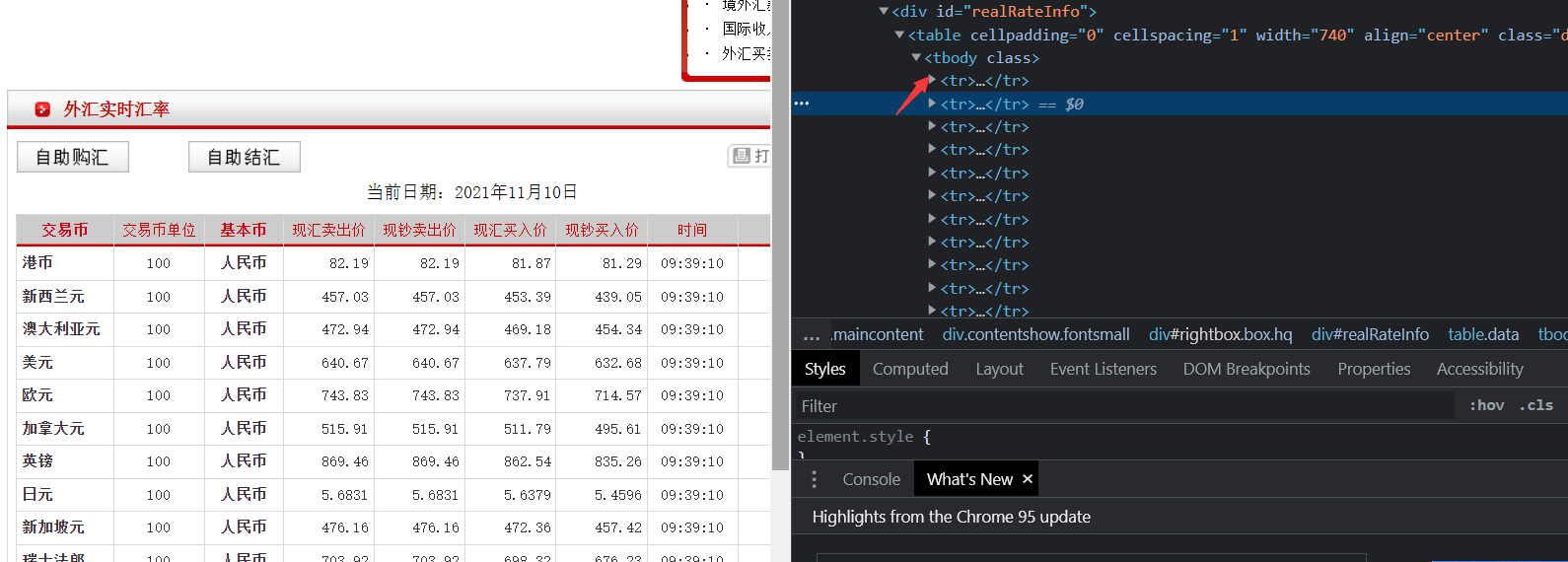
lis = response.xpath('//*[@id="realRateInfo"]/table')
currencys = lis.xpath(".//tr/td[1]/text()").extract()
tsps = lis.xpath(".//tr/td[4]/text()").extract()
csps = lis.xpath(".//tr/td[5]/text()").extract()
tbps = lis.xpath(".//tr/td[6]/text()").extract()
cbps = lis.xpath(".//tr/td[7]/text()").extract()
times = lis.xpath(".//tr/td[8]/text()").extract()
Note: there is a pit here, because there should be a tbody behind the table!
But if we add it, we can't climb down! So delete this tbody, and then change all the following elements from \\
- data processing
Remove spaces before and after data and some '\ r\n'
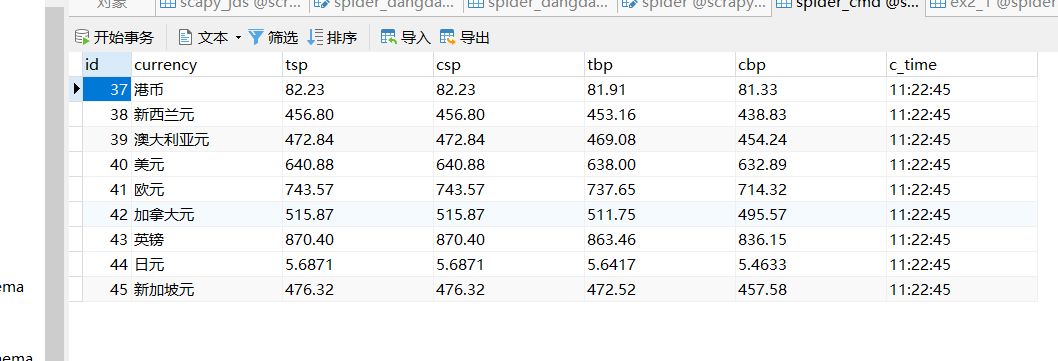
for currency, tsp, csp, tbp, cbp, time in zip(currencys, tsps, csps, tbps, cbps, times):
count+=1
currency = currency.replace(' ', '')
tsp = tsp.replace(' ', '')
csp = csp.replace(' ', '')
tbp = tbp.replace(' ', '')
cbp = cbp.replace(' ', '')
time = time.replace(' ', '')
currency = currency.replace('\r\n', '')
tsp = tsp.replace('\r\n', '')
csp = csp.replace('\r\n', '')
tbp = tbp.replace('\r\n', '')
cbp = cbp.replace('\r\n', '')
time = time.replace('\r\n', '')
if count ==1 :
continue
item = CmbspiderItem(
currency=currency, tsp=tsp, csp=csp, tbp=tbp, cbp=cbp, time=time
)
yield item
2.2.4 pipelines.py
It is similar to the operation of 1.2.4 and will not be described too much
Experiment 3
3.1 title
Proficient in Selenium searching HTML elements, crawling Ajax web page data, waiting for HTML elements, etc;
Use Selenium framework + MySQL database storage technology route to crawl the stock data information of "Shanghai and Shenzhen A shares", "Shanghai A shares" and "Shenzhen A shares".
Candidate website: Dongfang fortune.com: http://quote.eastmoney.com/center/gridlist.html#hs_a_board
3.2 ideas
3.2.1 send request
- Introduction drive
chrome_path = r"D:\Download\Dirver\chromedriver_win32\chromedriver_win32\chromedriver.exe" # Drive path browser = webdriver.Chrome(executable_path=chrome_path)
- Save the sections to be crawled
target = ["hs_a_board", "sh_a_board", "sz_a_board"]
target_name = {"hs_a_board": "Shanghai and Shenzhen A thigh", "sh_a_board": "Shanghai A thigh", "sz_a_board": "Deep evidence A thigh"}
The plan is to crawl two pages of information from three templates.
- Send request
for k in target:
browser.get('http://quote.eastmoney.com/center/gridlist.html#%s'.format(k))
for i in range(1, 3):
print("-------------The first{}page---------".format(i))
if i <= 1:
get_data(browser, target_name[k])
browser.find_element_by_xpath('//*[@ id = "main table_paginate"] / a [2] '. Click() # page turning
time.sleep(2)
else:
get_data(browser, target_name[k])
Note: the page turning here needs time.sleep(2)
Otherwise, he will ask quickly, so that although you turn to the second page, you still crawl to the first page!!
3.2.2 get node
- When parsing web pages, you should also implicitly_wait, wait
browser.implicitly_wait(10)
items = browser.find_elements_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr')
Then the items are all the information
for item in items:
try:
info = item.text
infos = info.split(" ")
db.insertData([infos[0], part, infos[1], infos[2],
infos[4], infos[5],
infos[6], infos[7],
infos[8], infos[9],
infos[10], infos[11],
infos[12], infos[13],
])
except Exception as e:
print(e)
3.2.3 saving data
- Database class, which encapsulates initialization and insertion operations
class database():
def __init__(self):
self.HOSTNAME = '127.0.0.1'
self.PORT = '3306'
self.DATABASE = 'scrapy_homeword'
self.USERNAME = 'root'
self.PASSWORD = 'root'
# Open database connection
self.conn = pymysql.connect(host=self.HOSTNAME, user=self.USERNAME, password=self.PASSWORD,
database=self.DATABASE, charset='utf8')
# Create a cursor object using the cursor() method
self.cursor = self.conn.cursor()
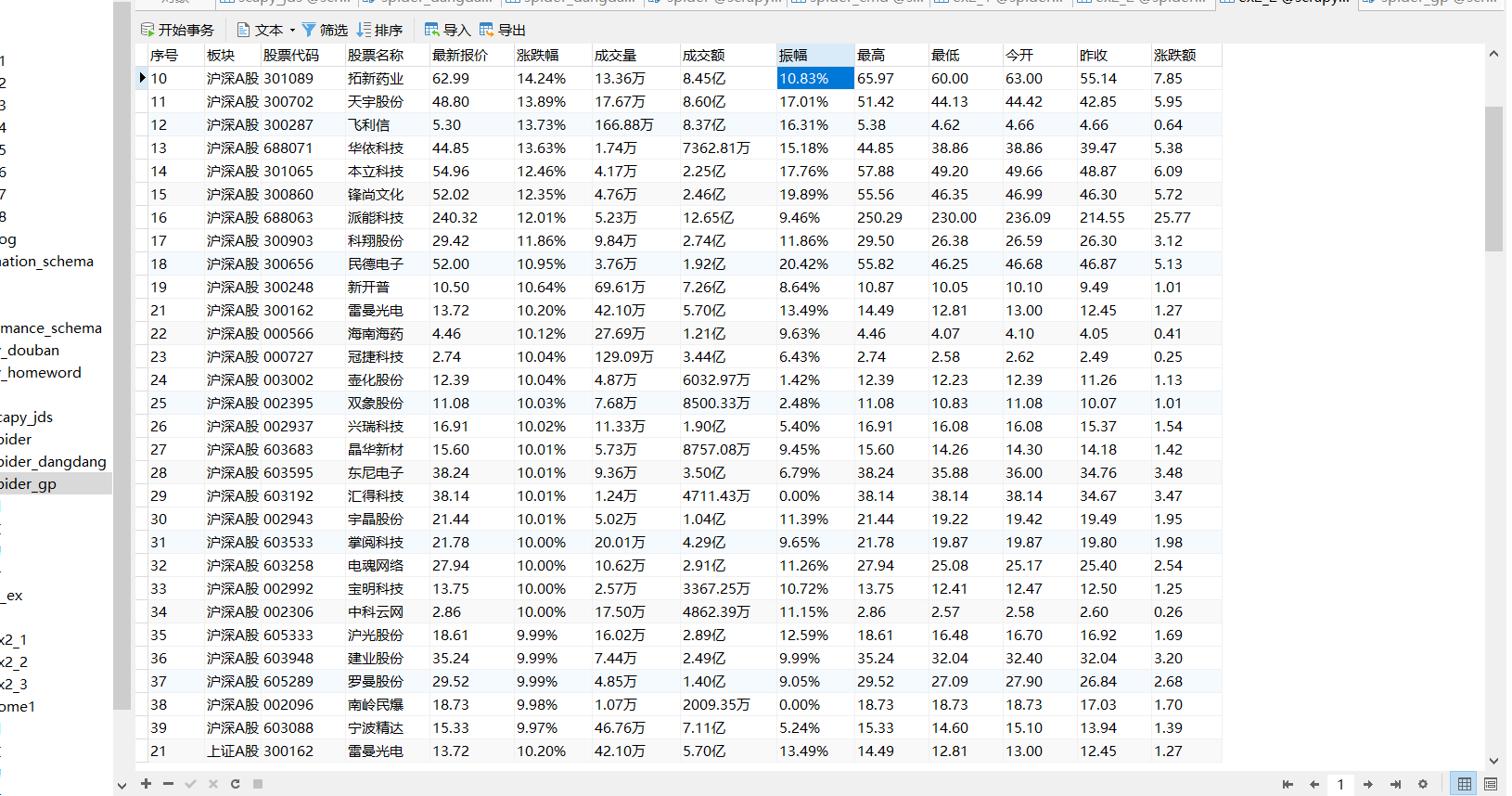
def insertData(self, lt):
sql = "INSERT INTO spider_gp(Serial number,plate,Stock code , Stock name , Latest quotation ,Fluctuation range ,Rise and fall,Turnover,Turnover , amplitude, highest , minimum , Today open , Received yesterday ) " \
"VALUES (%s,%s, %s, %s, %s, %s,%s, %s, %s, %s, %s,%s,%s,%s)"
try:
self.conn.commit()
self.cursor.execute(sql, lt)
print("Insert successful")
except Exception as err:
print("Insert failed", err)
Welfare delivery

[content introduction]
- Java multithreading and big data processing practice explains the data processing of Java multithreading and mainstream big data middleware in detail.
- This book mainly talks about Java's thread creation method and thread life cycle, which is convenient for us to manage multi-threaded thread groups and thread pools, set thread priorities, set guard threads, learn multi-threaded concurrent, synchronous and asynchronous operations, and understand Java's multi-threaded concurrent processing tools (such as semaphores and multi-threaded counters).
- Spring Boot, Spring Batch, Quartz, Kafka and other big data middleware are introduced. This provides a good reference for readers learning Java multithreading and big data processing. Multithreading and big data processing are the knowledge points that are easy to be asked in many development job interviews.
- Learning many thread knowledge points is very useful for future development work and interview preparation for front-line development positions.
- This book is not only suitable for students majoring in Computer Science in Colleges and universities, but also suitable for junior and intermediate developers engaged in software development related industries.
[comment area] and [praise area] will draw a fan to send out this book~
Of course, if you don't win the prize, you can buy it at the self owned store of Dangdang, Jingdong and Peking University Press.
You can also pay attention to me! I send one out every week~