HashMap Source Analysis
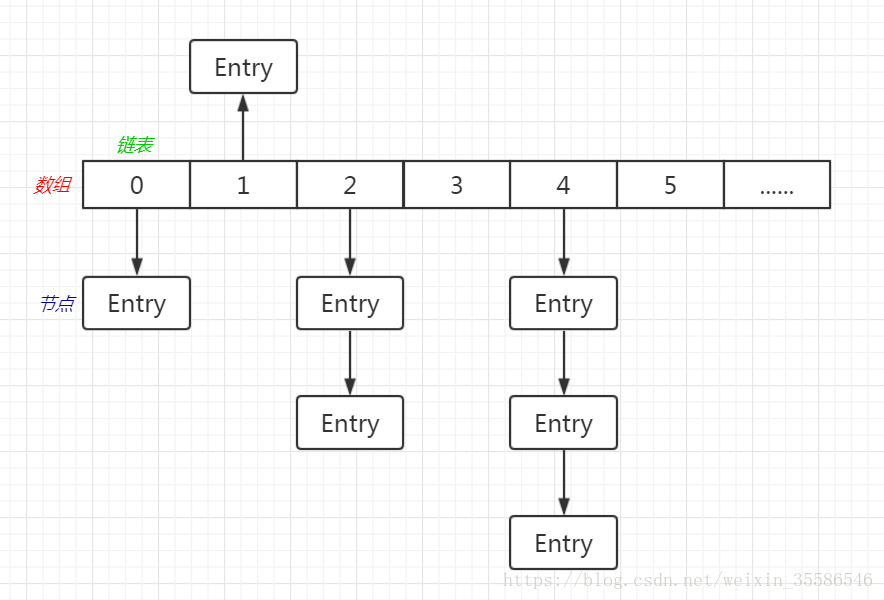
HashMap is a common key-value collection implementation class in Java that implements the Map interface.
data structure
Core:
- The whole is an array;
- Each position of the array is a chain list (or a red-black tree);
- The Value in each node of the list is the Object we store;
JDK 1.7
data structure
- Array+Chain List
Core Attributes

Core approach
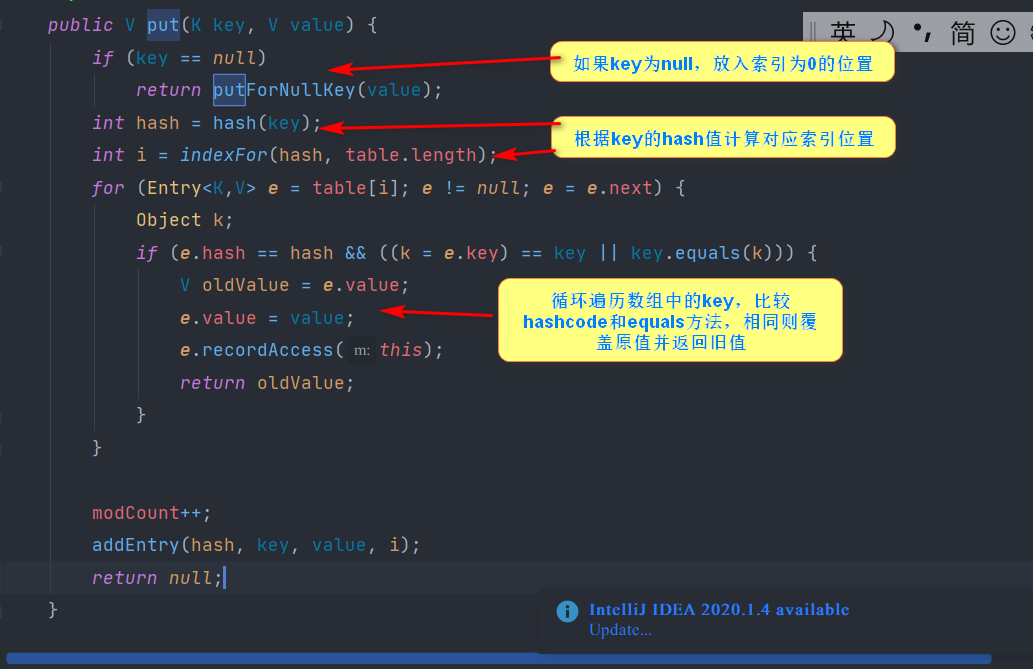
put method
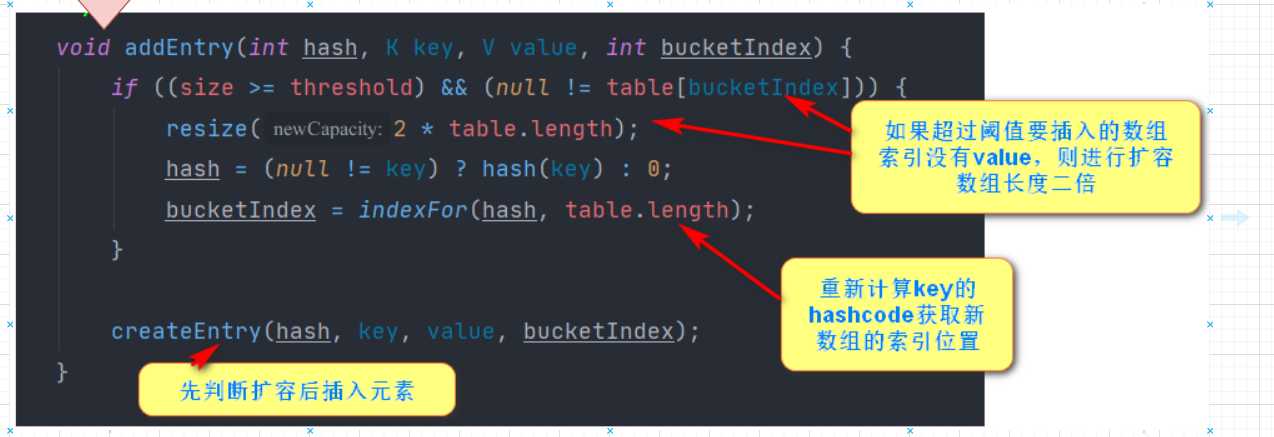
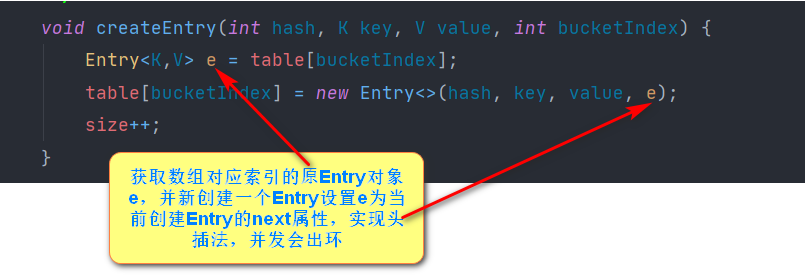
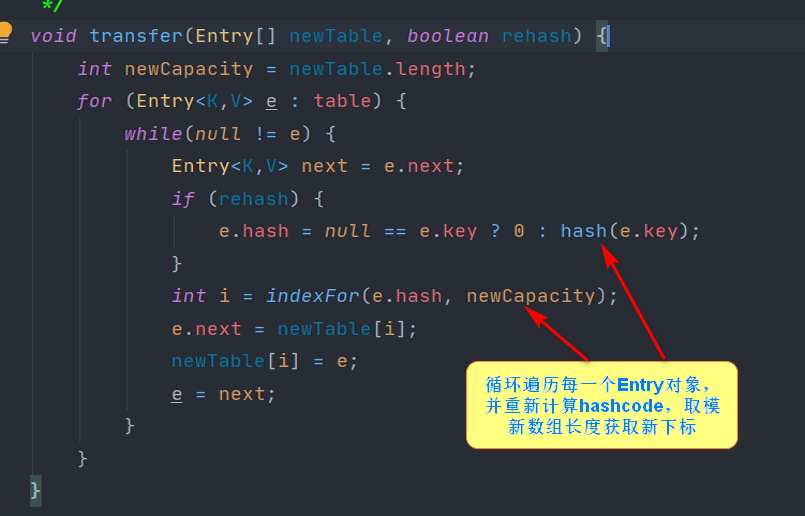
Core Expansion Mechanisms
JDK 1.8
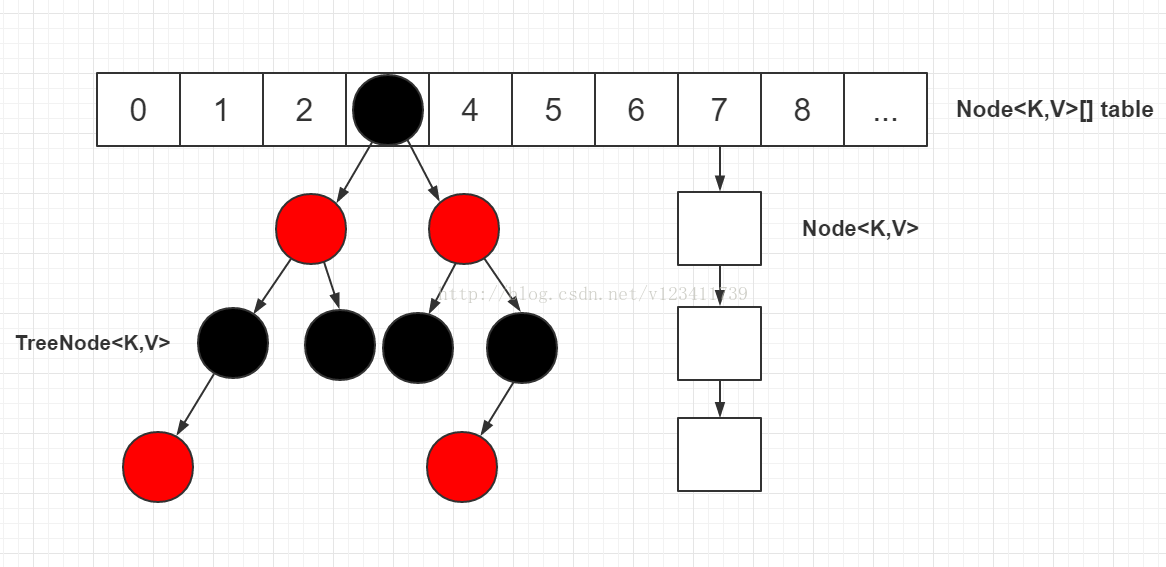
data structure
- Array+Chain List+Red-Black Tree
Core Attributes

Core approach
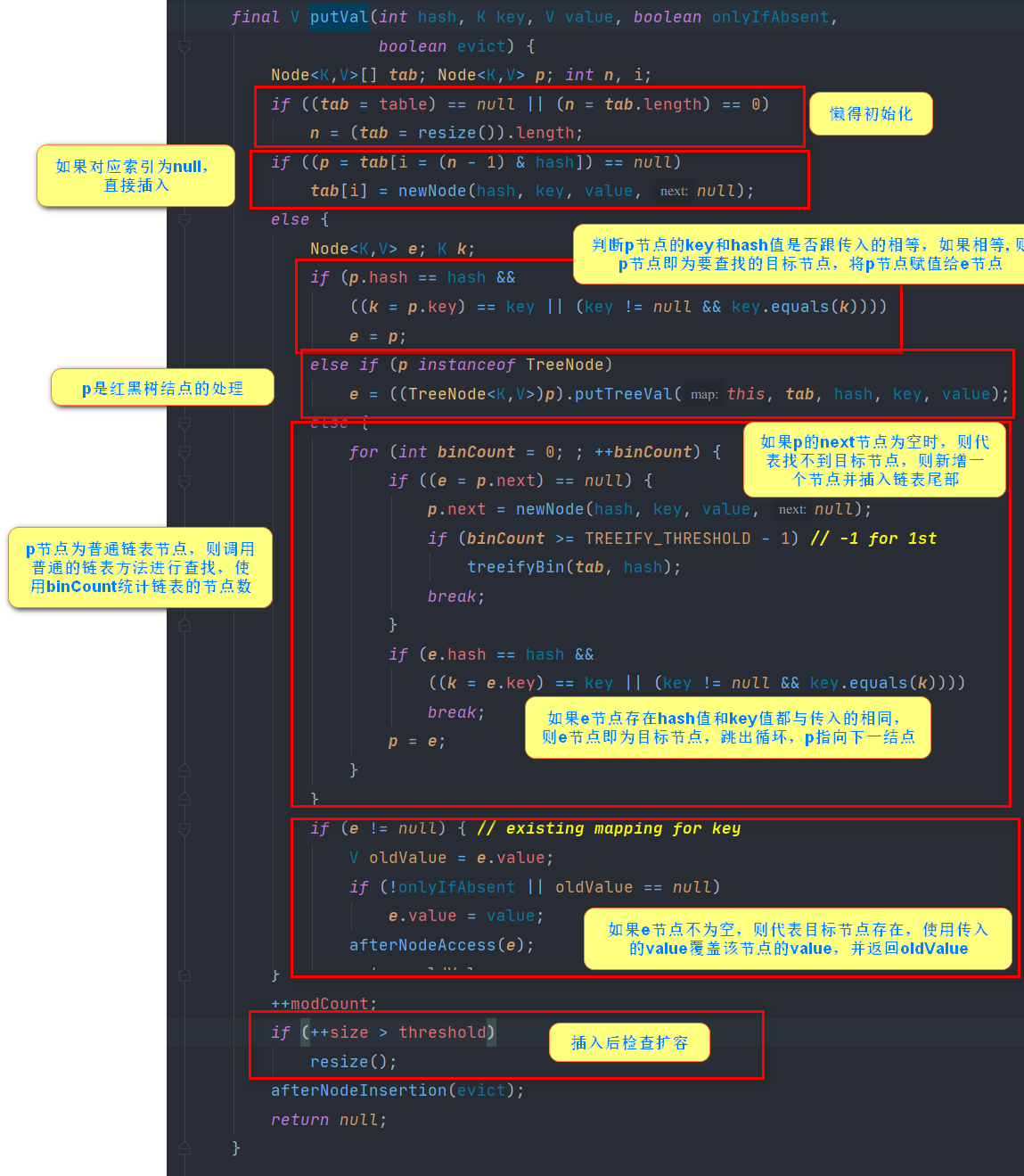
put method
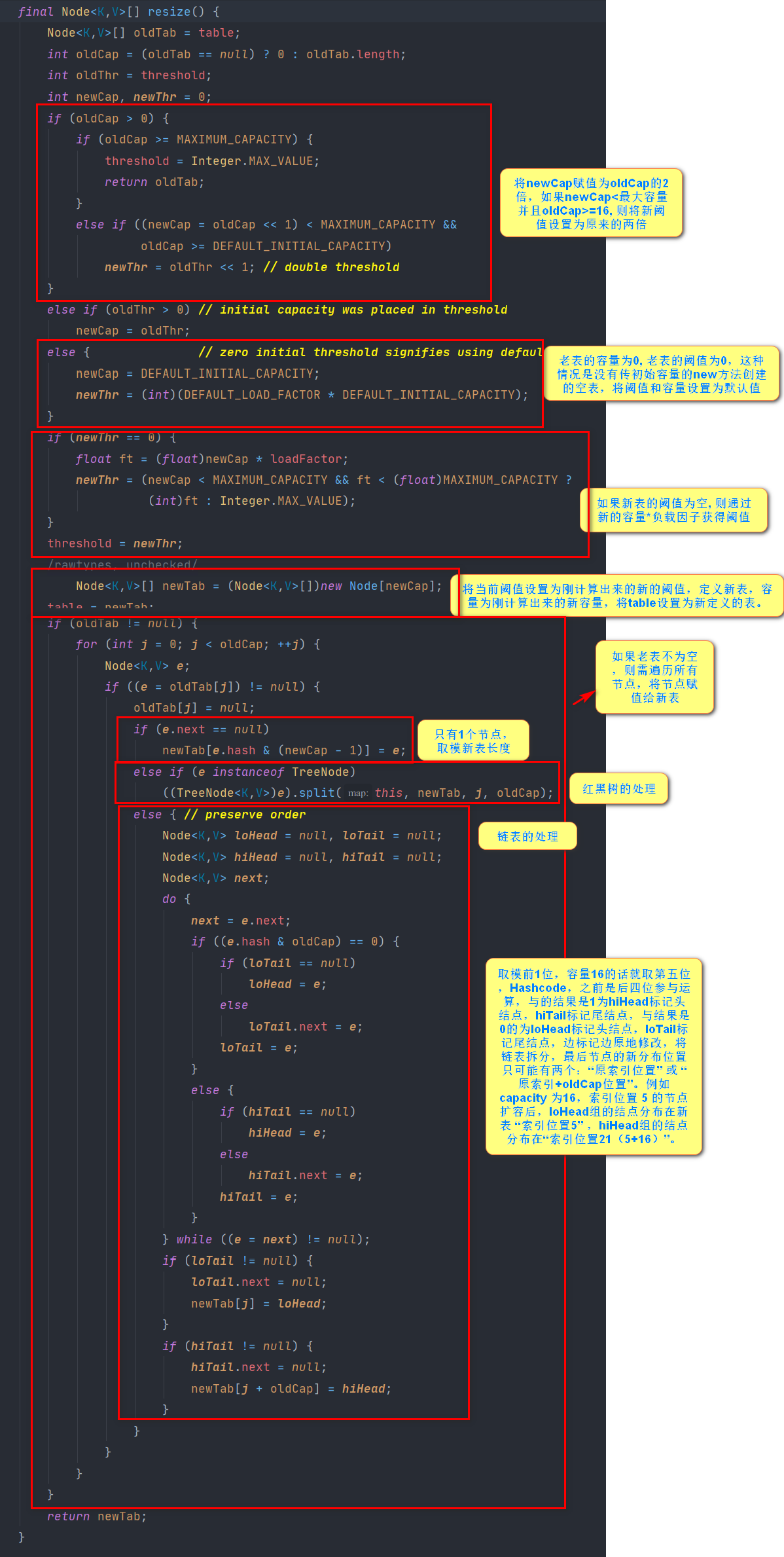
Core Expansion
Differences between JDK1.7 and JDK1.8
-
The most important point is that the underlying structure is different, 1.7 is array + Chain table, 1.8 is array + Chain Table + red-black tree structure.
-
When the hash table is empty in jdk1.7, an array is initialized by calling inflateTable(); 1.8 calls resize() extension directly;
-
The difference between put methods for inserting key-value pairs is that in 1.8 nodes are inserted at the end of the chain table, while in 1.7 headers are used.
-
The hash function in jdk1.7 directly uses the hashCode value of the key to calculate the hash value, while in 1.8 it uses the hashCode of the key exclusively or the hashCode of the upper key to shift 16 bits unsigned to the right, avoiding the conflict caused by calculating the hash only from the low bit data. The result of calculation is determined by the combination of the high and low bits, making the distribution of elements more even.
-
When expanding capacity, 1.8 keeps the original list in order, while 1.7 reverses the order of the list, so 1.8 avoids the concurrent dead-loop problem. Moreover, 1.8 detects the need for expansion after element insertion, and 1.7 detects the need for expansion before element insertion.
-
jdk1.8 is to spread the chain table by hash&cap= 0 and hash&cap = 1 when expanding capacity, without changing the hash value. It expands to only two locations in the new table. One is the original index location (loHead->loTail), the other is the new index location (hiHead->hiTail) where the original index + the length of the old array, and 1.7 is to recalculate the index for each element by updating hashSeed.
-
Expansion strategy: 1.7 is the direct expansion twice as long as it is no less than the threshold value; The 1.8 expansion strategy will be more optimized. When the array capacity does not reach 64, it will be expanded by 2 times. After 64, if the number of elements in the bucket is not less than 7, the chain table will be converted to a red-black tree. However, if the number of elements in the red-black tree is less than 6, it will be restored to a chain table. When the number of elements in the red-black tree is not less than 32, it will be expanded again.
ConcurrHashMap
JDK 1.7
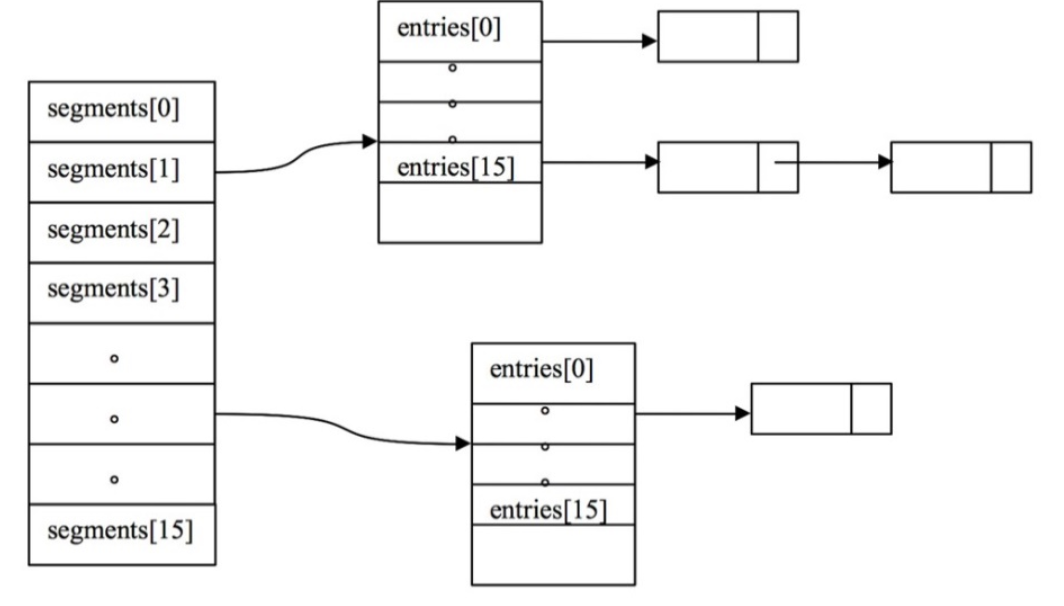
data structure
ConcurrentHashMap initializes by requiring concurrencyLevel to be initialized as the length of the segmented array, the concurrency degree, which represents the maximum number of threads that can operate ConcurrentHashMap simultaneously. By default, 16. Each segmented fragment contains an array of key-value pairs HashEntry, where the key-value pairs are actually stored. This is the data structure of ConcurrentHashMap.
Core Attributes
//Default initial capacity static final int DEFAULT_INITIAL_CAPACITY = 16; //Default Load Factor static final float DEFAULT_LOAD_FACTOR = 0.75f; //Default concurrency, which is the default length of the egment array static final int DEFAULT_CONCURRENCY_LEVEL = 16; //Maximum capacity, ConcurrentMap maximum capacity static final int MAXIMUM_CAPACITY = 1 << 30; //The length of the table array in each segment must be 2^n, with a minimum of 2 static final int MIN_SEGMENT_TABLE_CAPACITY = 2; //Maximum number of segment s allowed to limit concurrencyLevel boundaries, must be 2^n static final int MAX_SEGMENTS = 1 << 16; // slightly conservative //Number of retries to call the size and contains methods without locking to avoid unlimited retries due to continuous table modifications static final int RETRIES_BEFORE_LOCK = 2; //Compute the mask value for the segment location final int segmentMask; //The number of bits hash participates in when calculating the segment ed position final int segmentShift; //The segmentMask and segmentShift functions primarily to calculate which Segment fragment is located based on the hash value of the key. //Segment array final Segment<K,V>[] segments;
Introduction to Segment
[Segmented Lock] Inherited from ReentrantLock, a thread must acquire a synchronization lock in order to access the Segment fragment
static final class Segment<K,V> extends ReentrantLock implements Serializable {
//The maximum number of attempts to acquire a lock, the number of spins
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
//HashEntry array, that is, key-value pair array, volatile modifier, thread visibility
transient volatile HashEntry<K, V>[] table;
//Number of elements
transient int count;
//Number of operations in a segment that change elements, such as put/remove
transient int modCount;
//When the table size exceeds the threshold, the table is expanded to capacity *loadFactor
transient int threshold;
//Load factor
final float loadFactor;
Segment(float lf, int threshold, HashEntry<K, V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
}
Core approach
put method
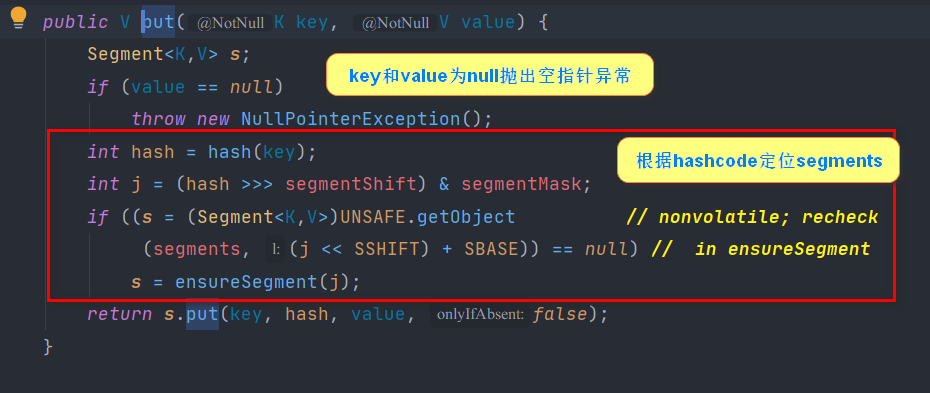
- Calculate hash value of key
- Location j in Segment array found from hash value
- Insert new values into slots
Segment initialization only initializes data at position 0. The rest of the segments use the reinitialization strategy by delaying load, which calls the ensureSegment method
private Segment<K,V> ensureSegment(int k) {
//Get the current segments array
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
//Initialize Segment[k] according to segment[0] HashEntry array length and load factor
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// Initialize segment[k] using the array length and load factor at the current segment[0], which is why segment[0] was previously initialized.
// Why use Current because segment[0] may have been expanded long ago.
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
//Check again if the slot is initialized by another thread.
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
//unsafe guarantees memory visibility
// With a while loop, CAS internally, exit after the current thread has successfully set a value or another thread has successfully set a value
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))//cas operation, atomicity
break;
}
}
}
return seg;
}

get method
The get method is unlocked, Entry is decorated with volatile, and all read variables are up-to-date.

size method
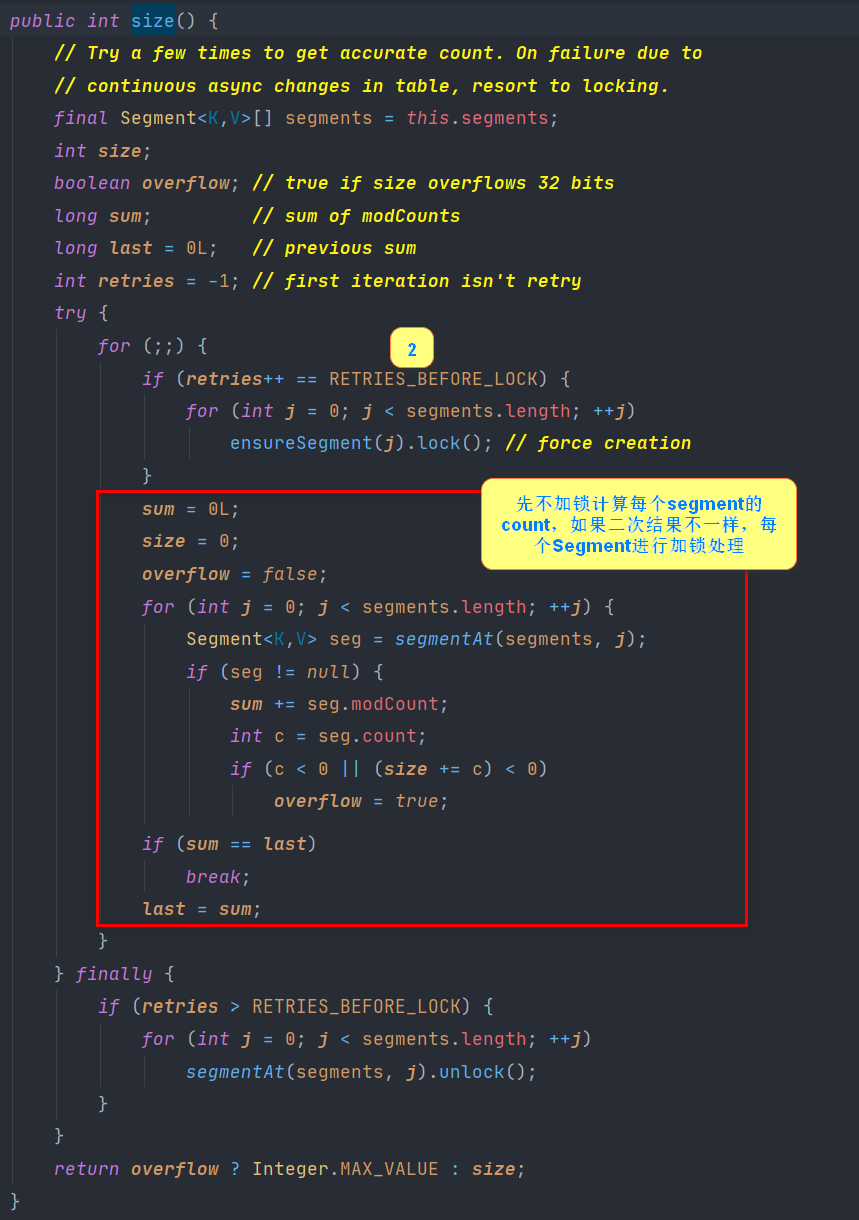
Expansion Core
private void rehash(HashEntry<K,V> node) {
// Record old table array
HashEntry<K,V>[] oldTable = table;
// Record old capacity
int oldCapacity = oldTable.length;
// Get the capacity of the new array, twice as large as before
int newCapacity = oldCapacity << 1;
// Calculate a new threshold
threshold = (int)(newCapacity * loadFactor);
// Create a new capacity HashEntry array
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
// Used to calculate Subscripts
int sizeMask = newCapacity - 1;
// Traverse the old table for element transfer
for (int i = 0; i < oldCapacity ; i++) {
// Get the list elements in each array
HashEntry<K,V> e = oldTable[i];
// Nothing has been transferred for nothing
if (e != null) {
// Get the next node of the header node
HashEntry<K,V> next = e.next;
// Calculate Subscript
int idx = e.hash & sizeMask;
// If next == null, it means that there is only one chain table element
if (next == null)
// Move the current element directly onto the new array
newTable[idx] = e;
else {
// If more than one needs to be transferred
// First assign the header node to lastRun and the subscript in the new array
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// Traverse through each element to find the element with the same subscript, whichever is the last group
for (HashEntry<K,V> last = next; last != null; last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// Transfer elements that find the same subscript to
newTable[lastIdx] = lastRun;
// Then put the elements before lastRun into the new ones
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
// Head Interpolation
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// New elements need to be added to the list of chains when expansion is complete
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
// Update the current segment ed table to an expanded element
table = newTable;
}
Like HashMap 1.8, there are only two locations (the original index location or the original index location + the old array length), except that the advantage of using lastRun node optimization eliminates the need for lastRun nodes and back nodes to re-enter the HashEntry object into a new array without having to re-export it to pass the last Run node reference to the past. If the lastRun node is the last node, then this optimization is redundant, but this is rarely the case.
JDK 1.8
On JDK1.7, ConcurrentHashMap was also implemented through segmented locks, and the number of segments constrained concurrency. In JDK1.8, this kind of structure design has been abandoned, but implemented directly with Node array + chain list + red-black tree structure, while concurrent control is operated with Synchronized and CAS.
Core Attributes
// node array maximum capacity: 2^30=1073741824 private static final int MAXIMUM_CAPACITY = 1 << 30; // Default initial value, must be 2 acts private static final int DEFAULT_CAPACITY = 16; //Array may have a maximum value and needs to be associated with the toArray() related method static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; //Concurrency level, legacy, compatible with previous versions private static final int DEFAULT_CONCURRENCY_LEVEL = 16; // Load factor private static final float LOAD_FACTOR = 0.75f; // Chain list to red-black tree threshold, > 8 chain list to red-black tree static final int TREEIFY_THRESHOLD = 8; //Tree chain table threshold, less than or equal to 6 (when tranfer, lc, hc=0 counters ++ record the number of original bin and new binTreeNode respectively, <=UNTREEIFY_THRESHOLD untreeify(lo)) static final int UNTREEIFY_THRESHOLD = 6; static final int MIN_TREEIFY_CAPACITY = 64; private static final int MIN_TRANSFER_STRIDE = 16; private static int RESIZE_STAMP_BITS = 16; // 2^15-1, maximum number of threads for help resize private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; // 32-16=16, offset of size recorded in sizeCtl private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; // hash value of forwarding nodes static final int MOVED = -1; // hash value of tree root node static final int TREEBIN = -2; // hash value of ReservationNode static final int RESERVED = -3; // Number of processors available static final int NCPU = Runtime.getRuntime().availableProcessors(); //Array to hold node s transient volatile Node<K,V>[] table; /*A control identifier used to control the initialization and expansion of a table. Different values have different meanings *When negative: -1 means initializing, -N means N-1 thread is expanding *When 0: the table representing the time has not been initialized *When positive: indicates the size of the initialization or next expansion */ private transient volatile int sizeCtl;
data structure
- Array+Chain List+Red-Black Tree
Core approach
put method
1. Call initTable() to initialize if it is not initialized
2. Insert CAS directly without hash conflict
3. If expansion is in progress, expand first
4. If there is a hash conflict, thread security is ensured by locking: the chain table traverses directly to the end insert: the red-black tree rotates insert
5. If the number of linked lists is greater than the threshold of 8, the structure of the black-red tree will be converted first, break will enter the cycle again
6. If the addition succeeds, call the addCount() method to count the size and check for extensions
Simply put, the whole put process solves three problems: initialization -> expansion -> data migration.
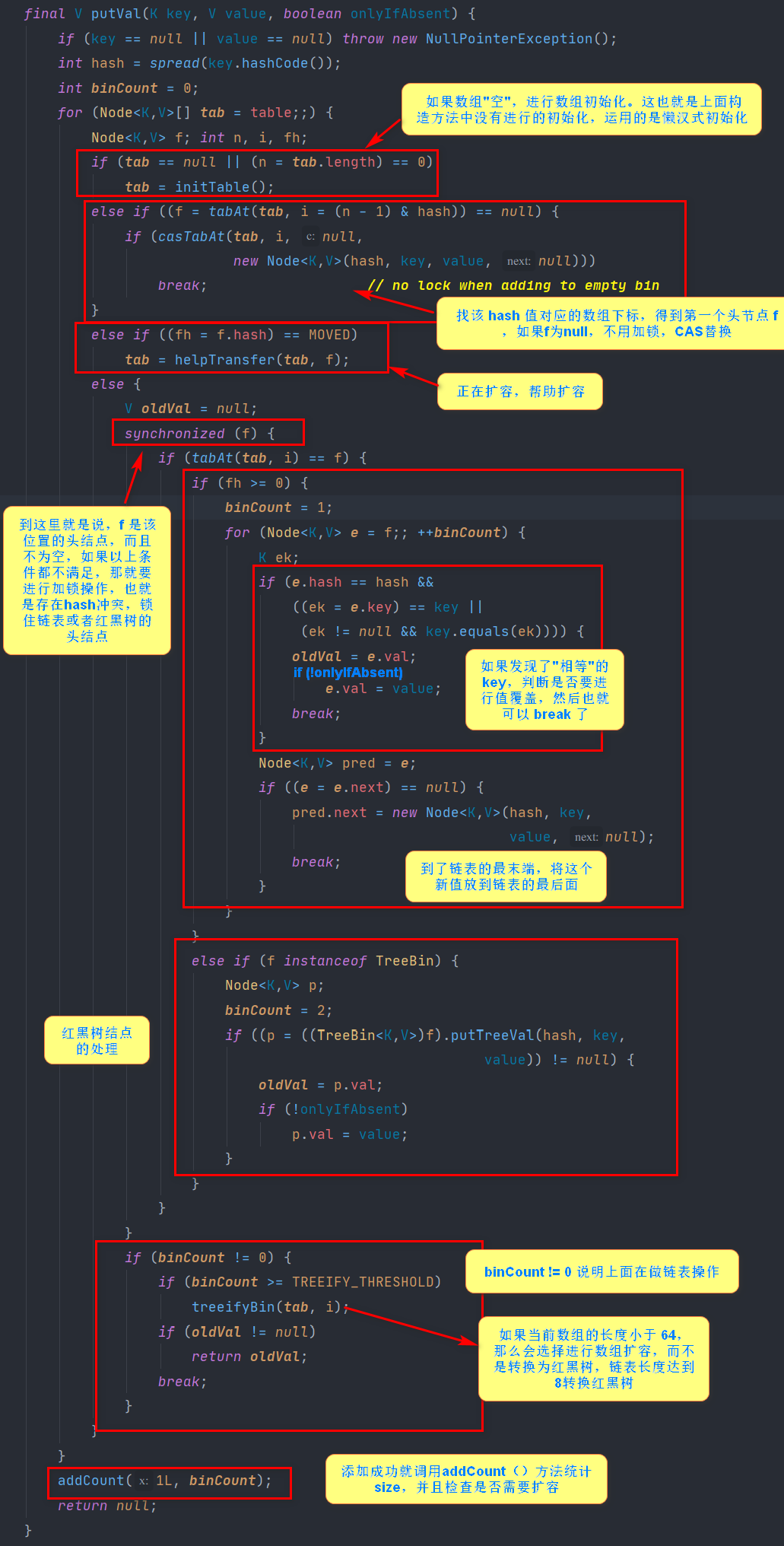
Core Expansion
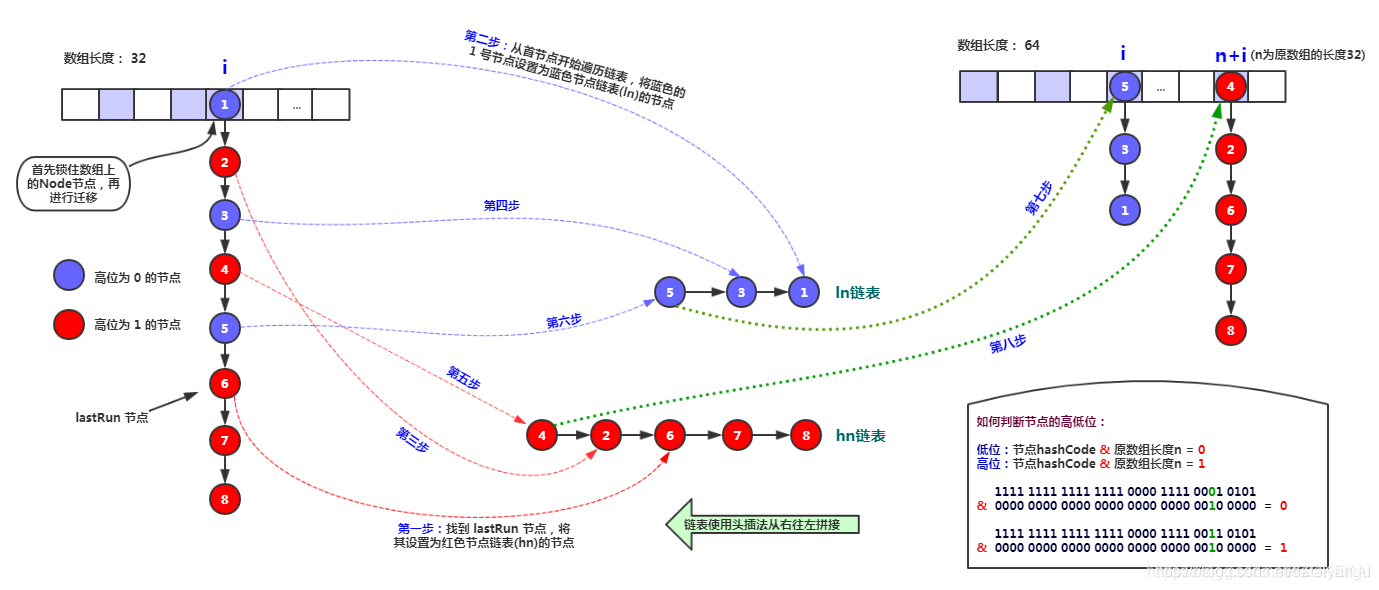
Arrays are divided into separate expansion intervals based on the number of cpu cores. Thread CAS competes for different intervals and locks the head node. Like Concurrent HashMap 1.7 expansion mechanism (lastRun), when expansion is successful, the node is marked as forwarding node with a hash value of -1, indicating that the location has been expanded.
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// stride is directly equal to n under a single core and (n >> 3) / NCPU under a multicore mode with a minimum of 16, which forces 16 when less than 16
// stride can be interpreted as a "step" where n locations need to be migrated.
// Divide the n tasks into multiple task packages, each with stride tasks
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// If nextTab is null, initialize it once
// As we mentioned earlier, the periphery guarantees that the parameter nextTab is null when the method is called by the first thread that initiates the migration
// nextTab will not be null when this method is called by subsequent threads participating in the migration
if (nextTab == null) {
try {
// Double capacity
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
// nextTable is a property in ConcurrentHashMap
nextTable = nextTab;
// TransfIndex is also a property of ConcurrentHashMap that controls where migration occurs
transferIndex = n;
}
int nextn = nextTab.length;
// Forwarding Node is translated as the ode being migrated
// This construct generates a Node with null key, value, and next, the key being hash as MOVED
// As we will see later, when the node at position i in the original array completes its migration, it sets position i to this Forwarding Node, which tells other threads that the location has been processed, so it is actually a flag. (fwd has a hash value of -1, fwd.nextTable=nextTab)
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// Advanced = true means that you have migrated one location and are ready to move to the next
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
/*
* The following for loop, the hardest to understand is in the front, but to understand them, you should first understand the back, and then look back
*
*/
// i is the location index, bound is the boundary, note that it is backward to forward
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// advance to true indicates that migration to the next location is possible
// Control--i, traverse the nodes in the original hash table. Simple understanding: I points to transferIndex, bound points to transferIndex-stride
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
// Assign the transferIndex value to nextIndex, where once the transferIndex is less than or equal to 0, there is a thread at all locations of the original array to process it
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
//TransfIndex calculated with CAS
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
// Looking at the code in parentheses, the nextBound is the boundary for this migration task, note that it is backward to forward
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
// All migration operations completed
nextTable = null;
// Assign a new nextTab to the table property to complete the migration
table = nextTab;
// Recalculating sizeCtl:n is the original array length, so sizeCtl will give a value of 0.75 times the length of the new array
sizeCtl = (n << 1) - (n >>> 1);
return;//Jump out of Dead Cycle
}
// As we have said before, sizeCtl is set to (rs << RESIZE_STAMP_SHIFT) + 2 before migration
// Then each thread that participates in the migration adds a sizeCtl,
// Here, the CAS operation is used to subtract sizeCtl by 1, which means that you have completed your own task and added a new thread to participate in the expansion operation
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// End of Task, Exit of Method
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// Here, description (sc - 2) == resizeStamp (n) << RESIZE_ STAMP_ SHIFT,
// That is, once all the migration tasks are completed, you will enter the if(finishing) {} branch above.
finishing = advance = true;
i = n; // recheck before commit
}
}
// f.hash == -1 indicates that the ForwardingNode node has been traversed, meaning that it has already been processed. This is the core of controlling concurrency expansion
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// This location is a ForwardingNode, indicating that the location has been migrated
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// Lock the node at this location of the array and begin processing the migration at that location of the array
synchronized (f) {
//Node Replication Work
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// Representation is a list node
if (fh >= 0) {
// Construct two linked lists: one is the original list and the other is the reverse order of the original list
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// Insert a list of chains at the nextTable i location
setTabAt(nextTab, i, ln);
// Insert a list of chains at the nextTable i + n position
setTabAt(nextTab, i + n, hn);
// Inserting Forwarding Node at table i indicates that the node has been processed and that other threads will not migrate once they see the hash value at table i as MOVED
setTabAt(tab, i, fwd);
// advance is set to true, indicating that the location has been migrated and can be executed--i action, traversing nodes
advance = true;
}
else if (f instanceof TreeBin) {
// Migration of Red and Black Trees
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// If the number of nodes <=6 is split into two, then the red-black tree is converted back to the chain table
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// Place ln in position i of the new array
setTabAt(nextTab, i, ln);
// Place hn i n the position i+n of the new array
setTabAt(nextTab, i + n, hn);
// Setting the location of the original array to fwd means that the location has been processed.
// Other threads will not migrate once they see a hash value of MOVED at that location
setTabAt(tab, i, fwd);
// advance set to true, indicating that the location has been migrated
advance = true;
}
}
}
}
}
}
The mechanism of concurrent operations is explained here. The length of the original array, n, means there are n migration tasks. The simplest is to have each thread take care of a small task at a time. Finishing a task detects if there are other unfinished tasks, and then helps with migration. Doug Lea uses a stride, which is simply understood as a step, where each thread is responsible for migrating a portion of it at a time, for example, 16 small tasks at a time. So we need a global dispatcher to schedule which thread will perform which tasks, which is what the attribute transferIndex does.
The first thread that initiates the data migration will point the transferIndex to the last position of the original array, then the stride tasks going forward belong to the first thread, then the transferIndex will point to the new location, the stride tasks going forward belong to the second thread, and so on. Of course, the second thread mentioned here does not really refer to the second thread, but it can also refer to the same thread. In fact, it divides a large migration task into task packages.
Ultimately, the transfer method does not implement all the migration tasks. Each call to this method only implements the migration of the transfer Index to the forward stride locations. The rest needs to be controlled by the periphery.
get method
The get operation is always the simplest. To summarize it briefly:
1. Calculate the hash value, locate the table index position, and return if the first node matches
2. Find the corresponding position of the array based on the hash value: (n-1) & H
3. Find the node at the location according to its nature: if the location is null, return null directly; If the node at that location happens to be what we need, return the value of that node. If the hash value of the node at this location is less than 0, it means that it is expanding or that it is a red-black tree. We will introduce the find method later. If none of the above three items are satisfied, it is a list of chains, which can be compared by traversal.
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// Determine if the header node is the one we need
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// If the hash of the header node is less than 0, the capacity is expanding or the location is a red-black tree
else if (eh < 0)
// Reference ForwardingNode.find(int h, Object k) and TreeBin.find(int h, Object k)
return (p = e.find(h, key)) != null ? p.val : null;
// Traversing a list of chains
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
The size method has the concept of a distributed accumulator, where the sum in each counter array is the size.
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a; //Number of changes
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
Welcome to my WeChat Public Number to learn more dry goods!
