👻 I believe many friends have learned the requests library from entering the pit to meeting through the repeated bombing of my two ten thousand word blog posts, and can independently develop their own small crawler projects—— The reptile road is endless~ 👻
💦 The first article on reptiles entering the pit; A ten thousand word blog post takes you into the pit, the reptile is a no return road [ten thousand word picture and text]💦
💦 The second part is the detailed explanation of crawler library requests. 20000 word blog post teaches you python crawler requests library [detailed explanation]💦
😬 But crawlers, crawlers, focus on crawling to the data we want, so how do we extract the information we need in the page? In order to let my friends learn more about the page parsing library described in this article, I first wrote an HTML ten thousand word detailed explanation step by step. I hope my friends will read it seriously, understand, understand and knock more, and you will feel the intention of our blogger in the future—— HTML 20000 word king's notes summary[ ❤️ Stay up late to tidy up & suggestions collection ❤️] (Part I) and HTML 20000 word king's notes summary[ ❤️ Stay up late to tidy up & suggestions collection ❤️] (Part II)😬
😜 Crawl to the data we want - professionally speaking, page parsing! For the nodes of the web page, it can define id,class and other attributes. In addition, there is a hierarchical relationship between the nodes. In the web page, you can use XPath or CSS selector to locate one or more nodes. Then, during page parsing, use XPath or CSS selector to extract a node, and then Call the corresponding method to get its body content or properties, so we can extract the information we want! 😜
🚔 Jump straight to the end 🚔 ——>Receive exclusive fan benefits 💖

our great Python has encapsulated many parsing libraries for us to realize the above operations, among which lxml,Beautiful Soup,pyquery, etc. are more powerful & & used. This blog leads our friends into the world of XPath (one of our most commonly used / practical parsing libraries in the future)!
| Learn the parsing library well and let me take the web data!!! |

💎 1.XPath (path expression)
🎉 (1) Introduction:
Xpath is a language for finding information in XML documents, but it can also be used for searching HTML documents. (compared with beautiful soup, Xpath is more efficient in extracting data)
| XPath is very powerful. It provides very simple path selection expressions and more than 100 built-in functions for string, value, time matching, node and sequence processing! So it is also the first choice for many crawler engineers when parsing pages!!! |
🎅 (2) Installation:
in python, many libraries provide XPath functions, but the most popular one is lxml, which is the most efficient. (just pip install lxml directly)
| It should be noted that: |
| 1. The method of importing etree in Python 3.7 is from lxml import html; |
| 2. The method of importing etree in Python 3.6 is from lxml import etree; |
🎃 (3) Common rules:
| expression | describe |
|---|---|
| nodename | Select all children of this node |
| / | Select direct child node from current node |
| // | Select a descendant node from the current pin |
| . | Select current contact |
| ... | Selects the parent node of the current pin |
| @ | Select Properties |
🎈 (2) Instance introduction:
(we define a text string to simulate the page data crawled)
from lxml import etree
text = '''
<div class="navli "><span class="nav_tit"><a href="javascript:;">Current politics</a><i class="group"></i></span></div>
<div class="navli "><span class="nav_tit"><a href="https://News. CCTV. COM / "> News < / a > < / span > < / div >
<div class="navli "><span class="nav_tit"><a href="https://v. CCTV. COM / "> Video < / a > < / span > < / div >
<div class="navli "><span class="nav_tit"><a href="https://Jingji. CCTV. COM / "> economy < / a > < / span > < / div >
<div class="navli "><span class="nav_tit"><a href="https://Opinion. CCTV. COM / "> comments < / a > < / span > < / div >
<div class="navli "><span class="nav_tit"><a href="https://Sports. CCTV. COM / "> Sports</a></span>
'''
html = etree.HTML(text) # Call the HTML class for initialization, so that an XPath parsing object is successfully constructed.
result = etree.tostring(html)
print(result.decode('utf-8'))
note that the last div node in the HTML text above is not closed, but the etree module can automatically complete the HTML text. In order to observe the automatically completed HTML text, call the tostring() method. Note that the result is of type bytes, so you need the decode() method to convert it to str type!
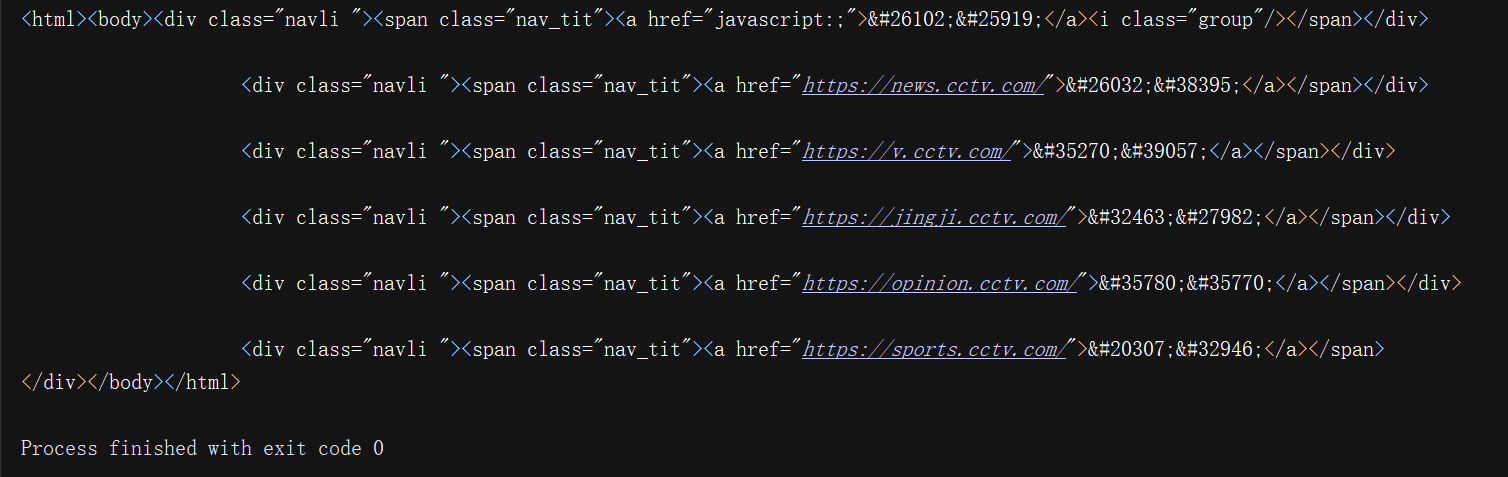
from the above results, we can see that after processing, the div node label is completed, and the body and HTML nodes are automatically added!

👻 (3) Detailed explanation of various common operations
the first step of pre war preparation - customize an HTML text to simulate the page data crawled!
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story" id="66">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">999</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """
💝 The second step of pre war preparation -- Constructing XPath parsing objects!
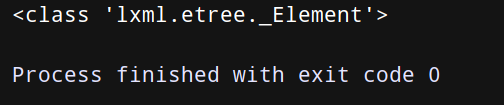
from lxml import etree #The principle is the same as that of beautiful, which is to convert html strings into tag objects that we can easily handle page = etree.HTML(html_doc) #html node returned print(type(page)) #The output is: < class' lxml. Etree. _element '>
🏄 (1) Detailed explanation of common rules:
XPath uses path expressions to select nodes in XML/HTML documents. Nodes are selected by following a path or step. (Note: all selected nodes are included in the list!)
the most useful / common path expressions are listed below:
🎅 ① nodename means to select the tag according to the tag name. Note that only sub tags will be selected! For example, if it is the son of a son, it cannot be selected.

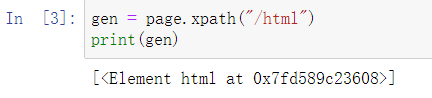
🍏 ② / indicates that level-1 filter is selected from the root node (cannot skip)
🍒 ③ / / indicates that nodes in the document are selected from the current node that matches the selection, regardless of their location. Note: all qualified nodes

🍓 ④ . indicates that the current label is selected
🍌 ⑤ Two. Indicates that the parent node of the current label is selected

🍠 ⑥ @ indicates to get the attribute value of the tag

🎍 The above common rules test code (I suggest you knock more, practice more and think more!):
# 1. When selecting a tag according to nodeName (tag name), only sub tags will be selected; for example, if it is the son of a son, it cannot be selected.
print(page.xpath("body"))
#2. / select level-1 filter from the root node (cannot skip)
gen = page.xpath("/html")
print(gen)
#3. Select nodes in the document from the current node that matches the selection, regardless of their location. Note: all qualified nodes
a = page.xpath("//a")
print(a)
#4. Select the current label
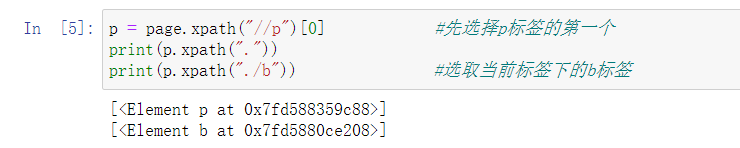
p = page.xpath("//p")[0] # first select the first one of the p Tags
print(p.xpath("."))
print(p.xpath("./b")) #Select the b tag under the current tag
#5.. select the parent node of the current tag
a = page.xpath("//a")[0]
print(a.xpath("..")) # a.xpath("parent::") can also get the parent node!
# 6. Get the attribute value of the tag
bb = page.xpath('//p[@class="story"]/@id ') # gets the id attribute value of the tag
print(bb)

🐱 (2) Predicate explanation:
predicate:
predicate is used to find a specific node or some specific nodes or nodes containing a specified value
The predicate is embedded in square brackets.
Some path expressions with the most common / useful predicates and the results of the expressions are listed below
🐹 ① Select all p tags that have attribute class:

🐸 ② Select all p tags with the attribute class and the value of story:

🚀 ③ Select all p tags, and the text value of a tag is greater than 889:

🐻 ④ Select the first a element belonging to the p signature sub element with class story:

👑 ⑤ Select the last a element belonging to the p signature sub element with class story:

🐮 ⑥ Select the penultimate a element belonging to the p signature sub element with class story:

🐒 ⑦ Select the first two a elements that belong to the child elements of the p tag with class story:

⚽ Explain the test code with the above predicate (I suggest you knock more, practice more and think more!)
#1. Select all p tags with attribute class
j = page.xpath('//p[@class]')
print("j:",j)
#Select all p tags with the attribute class and the value of story
b = page.xpath('//p[@class="story"]')
print("b",b)
#2. Select all p tags, and the text value of a tag is greater than 889.
print(page.xpath('//p[a>889]'))
#3. Select the first a element belonging to the p signature sub element with class story.
dd = page.xpath('//p[@class="story"]/a[1] '# if you select an index in xpath, start with 1
ee = page.xpath('//p[@class="story"]/a')[0] # if you select an index from the list, start with 0
print("dd:",dd)
print("ee",ee)
# Select the last a element belonging to the p signature sub element with class story.
ss = page.xpath('//p[@class="story"]/a[last()]')
print("ss:",ss)
# Select the penultimate a element belonging to the p signature sub element with class story.
rr = page.xpath('//p[@class="story"]/a[last()-1]')
print("rr",rr)
# Select the first two a elements that belong to the child elements of the p tag with class story.
gg = page.xpath('//p[@class="story"]/a[position()<3]')
print("gg:",gg)
📌 (3) Get text:
🐫 ① Use text() to get the text under a node:

💊 ② Use string() to get all the text under a node:

🔆 Get the text test code above (I suggest you knock more, practice more and think more!):
#1. Use text() to get the text under a node
contents=page.xpath("//p/a/text() ") # get text data and put it in the list
print(contents)
#2. Use string() to get all the text under a node
con = page.xpath("string(//p) ") # only get all the text under the first label
print(con)

🏃 (4) XPath wildcard:
use: select unknown nodes. That is, XPath wildcards can be used to select unknown nodes
🔮 ① * indicates a node that matches any element:

🐾 ② @ * match any attribute node:

🌷 The above XPath wildcard test code (I suggest you knock more, practice more and think more!):
# 1. * match any element node
s = page.xpath("//p / * ") # select all child elements of the p tag
print(s)
#2. @ * match any attribute node
ss = page.xpath("//p / @ * ") # select all attribute values of the selected tag (all p tags)
print(ss)

🌻 (5) Use | operation:
Select multiple paths
you can select several paths by using the "|" operator in the path expression.
🍃 ① Select all a and b elements of the p element:

🍄 ② Select all a and b elements in the document:

🐚 Use the above | operation test code (it is recommended to knock more, practice more and think more!):
# Select all a and b elements of the p element
print(page.xpath('//p/a|//p/b'))
#Select all a and b elements in the document
print(page.xpath('//a|//b'))

🌖 (4) Expansion - operation:
🌜 1. Attribute multi value matching (sometimes, the attributes of some nodes may have multiple values.)
from lxml import etree
text = '''
<div class="navli navli-first"><span class="nav_tit"><a href="javascript:;">Current politics</a><i class="group"></i></span></div>
'''
html = etree.HTML(text)
print(html.xpath('//div[@class="navli"]//a/text()'))
for example, the class attribute of div node in the above HTML text has two values navli and navli first. At this time, if you want to match and obtain the previous attribute, you can't match it. The output of the above code is [].
two solutions:
① xpath syntax writes the complete attribute value: print(html.xpath('/ / div[@class = "navli navli first] / / a/text()')), and the output is: [current politics]
② using the contains() function, you do not need to write the complete attribute value. The first parameter passes in the attribute name and the second parameter passes in the attribute value. As long as the attribute contains the passed in attribute value, you can complete the matching! For example: print(html.xpath('/ / div[contains(@class, "navli")] / / a/text()')), so the output is also: [current politics]
🌋 2. Multi attribute matching: (sometimes, a node needs to be determined according to multiple attributes. At this time, multiple attributes need to be matched at the same time. At this time, the operator and can be used to connect!)
from lxml import etree
text = '''
<div class="navli navli-first" name="second"><span class="nav_tit"><a href="javascript:;">Current politics</a><i class="group"></i></span></div>
'''
html = etree.HTML(text)
print(html.xpath('//div[contains(@class,"navli") and @name="second"]//a/text()'))
| Output as ['current affairs'] |
Some common operators:
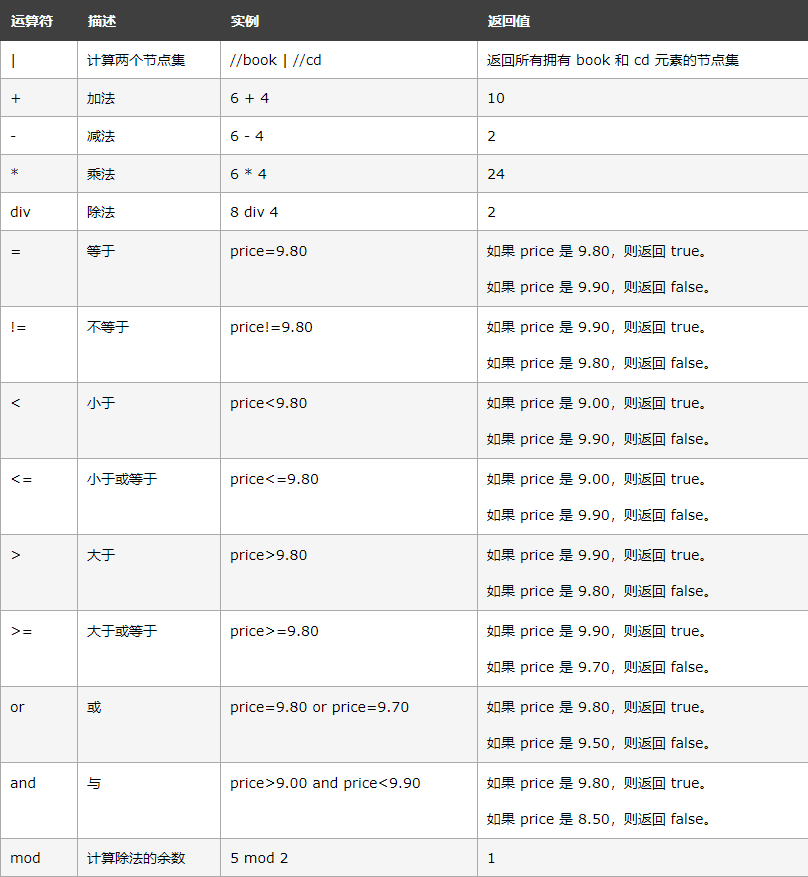 (this table is referenced from w3school)
(this table is referenced from w3school)
🌼 3. Node axis selection:
⛅ ① ancestor axis:
# Call the ancestor axis to get all ancestor nodes. It needs to be followed by two colons, followed by the selector of the node. Return result: all ancestor nodes of the first li node.
html.xpath('//li[1]/ancestor::*')
🎒 ② attribute axis:
# The attribute axis is called to get all attribute values. Return result: all attribute values of the li node.
html.xpath('//li[1]/attribute::*')
💝 ③ child axis:
# The child axis is called to obtain all direct child nodes. Return result: select the a child node whose href attribute is link.html.
html.xpath('//li[1]/child::a[@href="link1.html"]')
💝 ④ descendant axis:
# The descendant axis is called to get all descendant nodes. At the same time, restrictive conditions are added. Return result: select the span node in the descendant node under the li node.
html.xpath('//li[1]/descendant::span')
☎️ ⑤ following axis:
# The following axis is called to obtain all nodes after the current node.
html.xpath('//li[1]/following::*[2]')
🔇 ⑥ Following sibling axis:
# The following sibling axis is called to obtain all sibling nodes after the current node.
html.xpath('//li[1]/following-sibling::*')
🔓 2. Douban Top250 movie information crawling
after this practical XPath library, you will find that page parsing and extracting the data you need are very convenient and fast - this is also the feeling of the majority of crawler engineers, so XPath partners must master it firmly!
💣3.In The End!

| From now on, stick to it and make progress a little bit a day. In the near future, you will thank you for your efforts! |
the blogger will continue to update the crawler basic column and crawler actual combat column. After reading this article carefully, you can praise the collection and comment on your feelings after reading it. And you can pay attention to this blogger and read more crawler articles in the future!
If there are mistakes or inappropriate words, you can point them out in the comment area. Thank you! If you reprint this article, please contact me to explain the meaning and mark the source and the blogger's name. Thank you!
you can add a private VX number by clicking - > below (if you are the one):