1. RDD persistence operation
Acts on the behavior of the operator
RDD does not store data. If an RDD needs to be reused, it needs to be executed again from the beginning to obtain data
RDD objects can be reused, but data cannot be reused
By default, it is saved in memory. There is a parameter in persist (default memory)
Put it in memory: save an RDD temporarily, mapRDD.cache()
On disk: mapRDD.persist(StorageLevel.DISK_ONLY)
2. checkPoint operation checkPoint - used in conjunction with cache
Checkpointing is actually by writing RDD intermediate results to disk
//checkPoint() needs to drop the disk, and the path of checkPoint needs to be specified
//The files saved in the checkpoint path will not be deleted after the job is executed
//General save path in distributed storage system (hdfs)
sc.setCheckpointDir("sparkproject/data")
wordRDD.checkpoint()

3. cache, persist, checkpoint differences
cache: temporarily store the results in memory for data reuse (data may be unsafe and memory overflow). New dependencies will be added to the blood relationship. If there is a problem, you can re read the data
persist: temporarily store data in disk files for data reuse (disk dropped, slow disk IO, low performance, data security)
If the job is completed, the temporarily saved data file will be lost
checkpoint: save data in disk files for long time for data reuse (involving disk IO, low performance and data security)
The blood relationship is cut off, a new blood relationship is re established, and the job is executed again. In order to improve efficiency, it is generally necessary to use checkpoint in combination with cache, which is equivalent to changing the data source
4. RDD partition
Spark currently supports Hash partitions, Range partitions, and user-defined partitions. The Hash partition is the current default partition, and the partition directly determines the RDD
The number of partitions in RDD and which partition each data in RDD enters after shuffling determine the number of Reduce
Only RDDS of key value type have a partition. The value of RDD partitions of non key value type is None
The partition ID range of each RDD is 0 ~ (numPartitions - 1), which determines which partition this value belongs to
object Demo07partition {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo06cache").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val listRDD= sc.makeRDD(List(
("nba", "xxxxxxx"),
("cba", "xxxxxxx"),
("wnba", "xxxxxxx"),
("nba", "xxxxxxx")
),3)
listRDD.partitionBy(new MyPartition)
.saveAsTextFile("sparkproject/data/res")
}
/**
* Custom partition
* (1)Inherit Partitioner class
*/
class MyPartition extends Partitioner {
//Number of partitions
override def numPartitions: Int = 3
//Returns the partition index of the data according to the data key value (0, 1, 2...)
override def getPartition(key: Any): Int = {
key match {
case "nba" => 0
case "wnba" => 1
case _ => 2
}
}
}
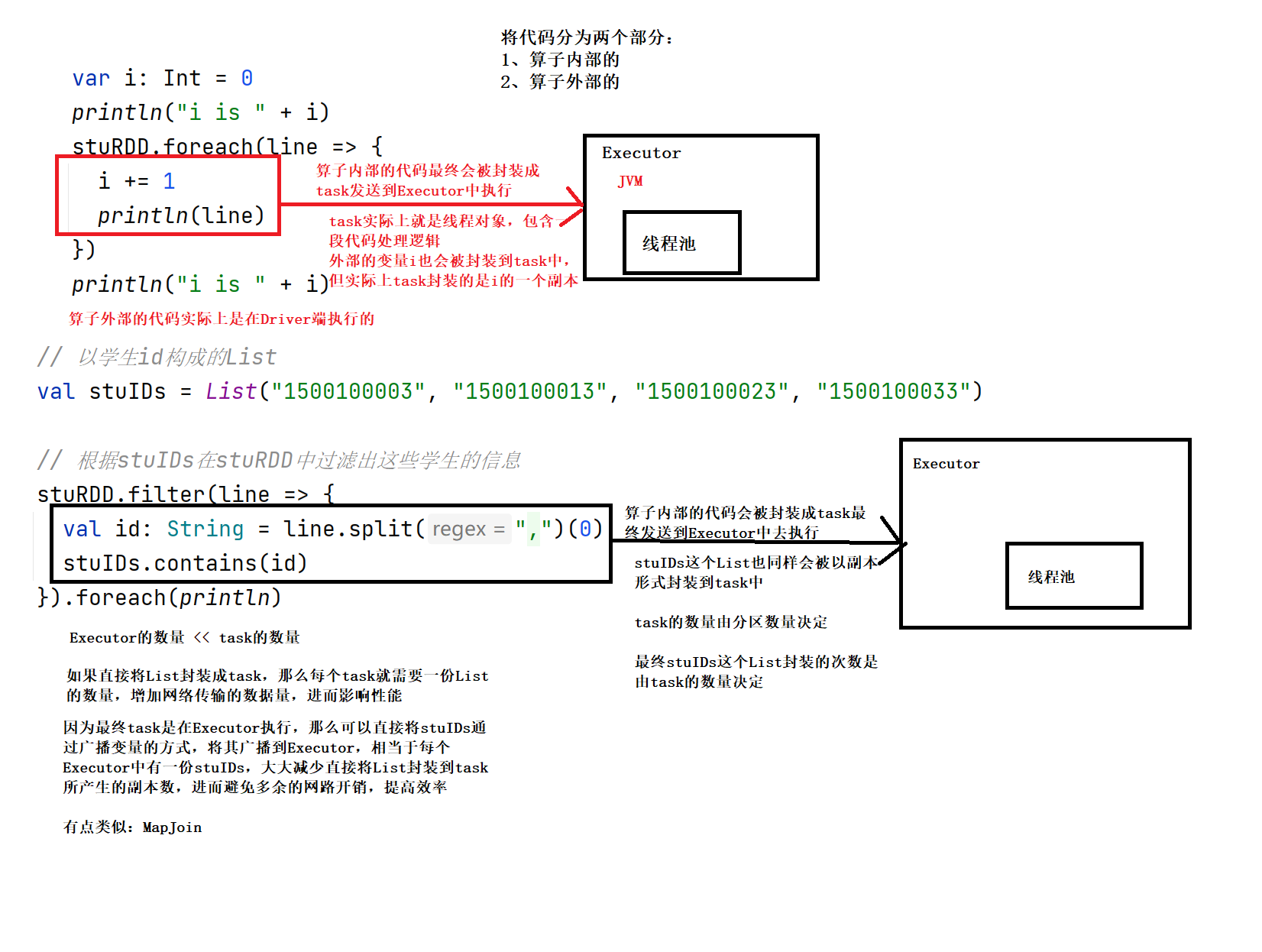
5. Accumulator (similar to global variable)
Distributed shared write only variables
(1) Principle
The accumulator is used to aggregate the variable information on the Executor side to the Driver side. For variables defined in the Driver program, each task on the Executor side will get a new copy of this variable. After each task updates the values of these copies, it will be returned to the Driver side for merge
(2) System accumulator
- Spark provides an accumulator for simple data aggregation by default
Default accumulator
doubleAccumulator() collectionAccumulator longAccumulator
//Add less: the accumulator is called in the transformation operator. If there is no action operator, it will not execute. //Not implemented //Add: the accumulator is called in the transformation operator. If there is no action operator, it will not execute. //Multiple execution. Generally, the accumulator is placed in the action operator for operation
object Demo08ass {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Demo06cache").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val listRDD = sc.makeRDD(List(1, 2, 3, 4))
/**
* Get system accumulator
* Default accumulator
*/
//sc.doubleAccumulator()
//sc.collectionAccumulator
val sumAcc = sc.longAccumulator("sum")
listRDD.foreach(num => {
sumAcc.add(num)}
)
//Gets the value of the accumulator
println(sumAcc.value)
}
}
6. Broadcast variable
Distributed shared read-only variable
Broadcast variables are used to efficiently distribute large objects. Sends a large read-only value to all work nodes for use by one or more Spark operations
The closure data in the task is placed in the memory of the Executor to achieve the purpose of sharing

object Demo12brostcast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("Demo12brostcast")
conf.setMaster("local")
val sc = new SparkContext(conf)
val stuRDD = sc.textFile("sparkproject/data/students.txt")
val stuList: List[String] = List("1500100025","1500100035","1500100045","1500100055")
//Make list a broadcast variable
val listRDD: Broadcast[List[String]] = sc.broadcast(stuList)
stuRDD.filter(stu=>{
val id: String = stu.split(",")(0)
//Gets the value of the broadcast variable
val list: List[String] = listRDD.value
list.contains(id)
})
.foreach(println)
}
}