background
Everyone has learned how to write code in a standard and concise way, but they rarely learn how to submit code in a standard and concise way. Now we basically use git as a tool for source code management. Git provides great flexibility. We submit / merge codes according to various workflow s. This flexibility is not well controlled and will also bring many problems
The most common problem is the messy git log history. It's really an old lady's foot binding. It's smelly and long. I don't like this log very much
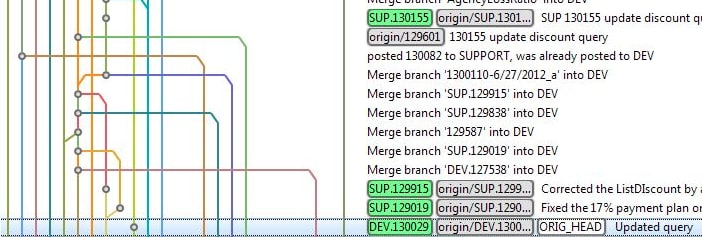
The root cause of this problem is random code submission.
The code has been submitted. Is there any way to save it? Three brocade bags can be solved perfectly
Make good use of git commit --amend
The help document for this command is described as follows:
--amend amend previous commit
In other words, it can help us modify the last submission
You can modify both the message we submitted and the file we submitted, and finally replace the last commit ID
We may miss a file when submitting. When we submit again, we may have multiple useless commit IDs. If everyone does this, the git log will slowly become chaotic and unable to track the complete function
Suppose we have such a log information
* 98a75af (HEAD -> feature/JIRA123-amend-test) feat: [JIRA123] add feature 1.2 * 119f86e feat: [JIRA123] add feature 1.1 * 5dd0ad3 feat: [JIRA123] add feature 1 * c69f53d (origin/main, origin/feature/JIRA123-amend-test, origin/HEAD, main) Initial commit
Suppose we want to modify the last log message, we can use the following command:
git commit --amend -m "feat: [JIRA123] add feature 1.2 and 1.3"
Let's look at the log information again. We can find that we replaced the old commit ID 98a75af with the new commit ID 5e354d1, modified the message, and did not add nodes
* 5e354d1 (HEAD -> feature/JIRA123-amend-test) feat: [JIRA123] add feature 1.2 and 1.3 * 119f86e feat: [JIRA123] add feature 1.1 * 5dd0ad3 feat: [JIRA123] add feature 1 * c69f53d (origin/main, origin/feature/JIRA123-amend-test, origin/HEAD, main) Initial commit
Now the file in our repo is as follows:
. ├── README.md └── feat1.txt 0 directories, 2 files
Suppose that when we submit feature 1.3, we forget a configuration file config.yaml, do not want to modify the log, and do not want to add a new commit ID, then the following command is very easy to use
echo "feature 1.3 config info" > config.yaml git add . git commit --amend --no-edit
Git commit -- amend -- no edit is the soul. Take a look at the current repo file:
. ├── README.md ├── config.yaml └── feat1.txt 0 directories, 3 files
Take another look at git log
* 247572e (HEAD -> feature/JIRA123-amend-test) feat: [JIRA123] add feature 1.2 and 1.3 * 119f86e feat: [JIRA123] add feature 1.1 * 5dd0ad3 feat: [JIRA123] add feature 1 * c69f53d (origin/main, origin/feature/JIRA123-amend-test, origin/HEAD, main) Initial commit
Knowing this technique will ensure that every submission contains valid information. A diagram describes the process as follows:
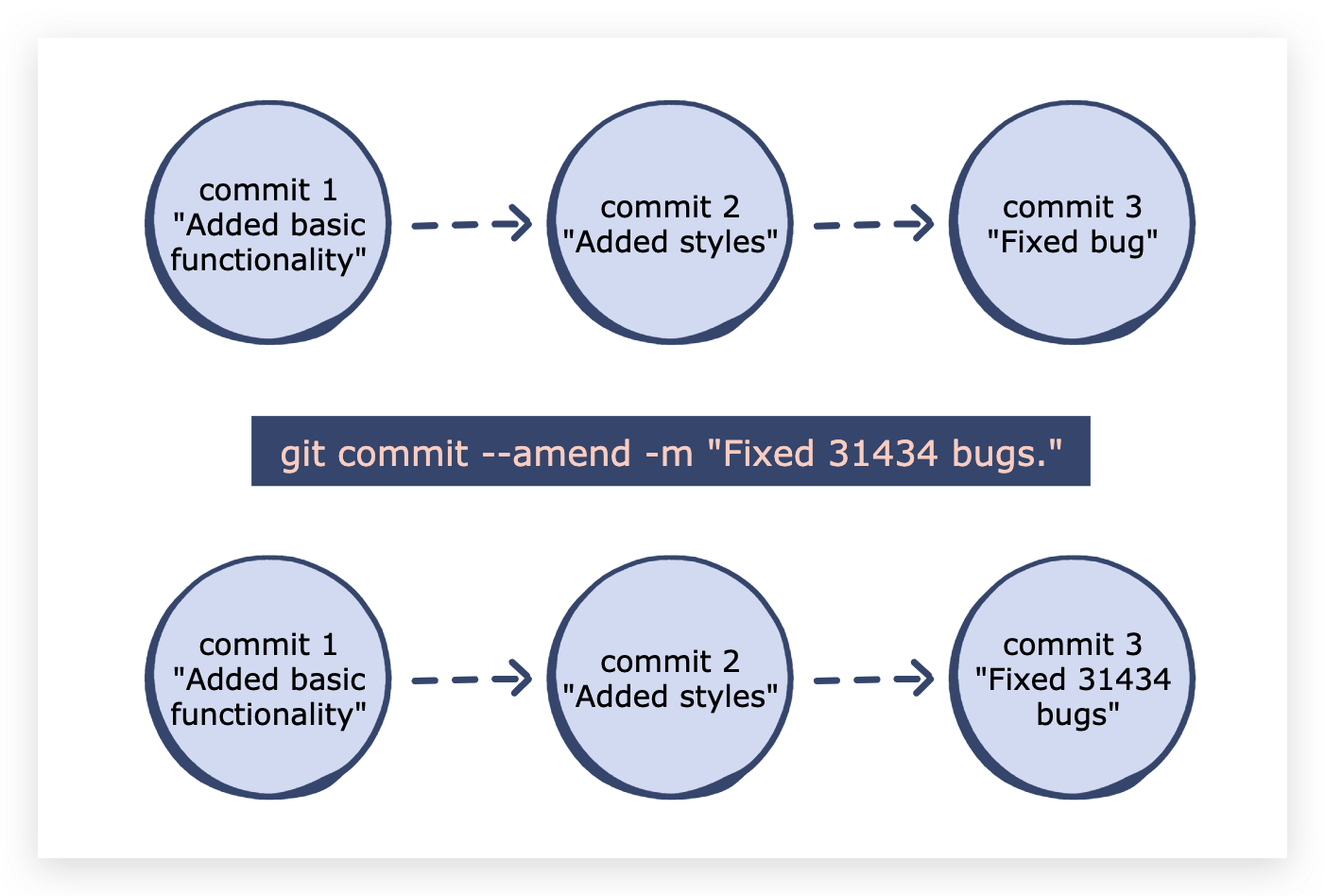
With the buff bonus of -- no edit, it's more powerful
Make good use of git rebase -i
You can see that the above logs are developing feature1. We should continue to merge the log commit node before merging the feature branch to the main branch. This is used
git rebase -i HEAD~n
Where n represents the last few submissions. We have three submissions for feature 1 above, so you can use:
git rebase -i HEAD~3
After running, a vim editor will be displayed as follows:
1 pick 5dd0ad3 feat: [JIRA123] add feature 1 2 pick 119f86e feat: [JIRA123] add feature 1.1 3 pick 247572e feat: [JIRA123] add feature 1.2 and 1.3 4 5 # Rebase c69f53d..247572e onto c69f53d (3 commands) 6 # 7 # Commands: 8 # p, pick <commit> = use commit 9 # r, reword <commit> = use commit, but edit the commit message 10 # e, edit <commit> = use commit, but stop for amending 11 # s, squash <commit> = use commit, but meld into previous commit 12 # f, fixup <commit> = like "squash", but discard this commit's log message 13 # x, exec <command> = run command (the rest of the line) using shell 14 # d, drop <commit> = remove commit 15 # l, label <label> = label current HEAD with a name 16 # t, reset <label> = reset HEAD to a label 17 # m, merge [-C <commit> | -c <commit>] <label> [# <oneline>] 18 # . create a merge commit using the original merge commit's 19 # . message (or the oneline, if no original merge commit was 20 # . specified). Use -c <commit> to reword the commit message. 21 # 22 # These lines can be re-ordered; they are executed from top to bottom. 23 # 24 # If you remove a line here THAT COMMIT WILL BE LOST. 25 # 26 # However, if you remove everything, the rebase will be aborted. 27 # 28 # 29 # Note that empty commits are commented out
The most common ways to merge commit IDs are squash and fixup. The former contains commit message, while the latter does not. Here, use fixup, and then: wq exit
1 pick 5dd0ad3 feat: [JIRA123] add feature 1 2 fixup 119f86e feat: [JIRA123] add feature 1.1 3 fixup 247572e feat: [JIRA123] add feature 1.2 and 1.3
Let's take another look at the log, which is very clear
* 41cd711 (HEAD -> feature/JIRA123-amend-test) feat: [JIRA123] add feature 1 * c69f53d (origin/main, origin/feature/JIRA123-amend-test, origin/HEAD, main) Initial commit
Make good use of rebase
The above feature1 has been completely developed, and the main branch has been updated by others. Before returning the feature merge to the main branch, in case of code conflict, you need to merge the contents of the main branch into the feature. If you use the merge command, there will be multiple merge nodes, and inflection points will appear in the log history, which is not linear, So here we can use the rebase command on the feature branch
git pull origin main --rebase
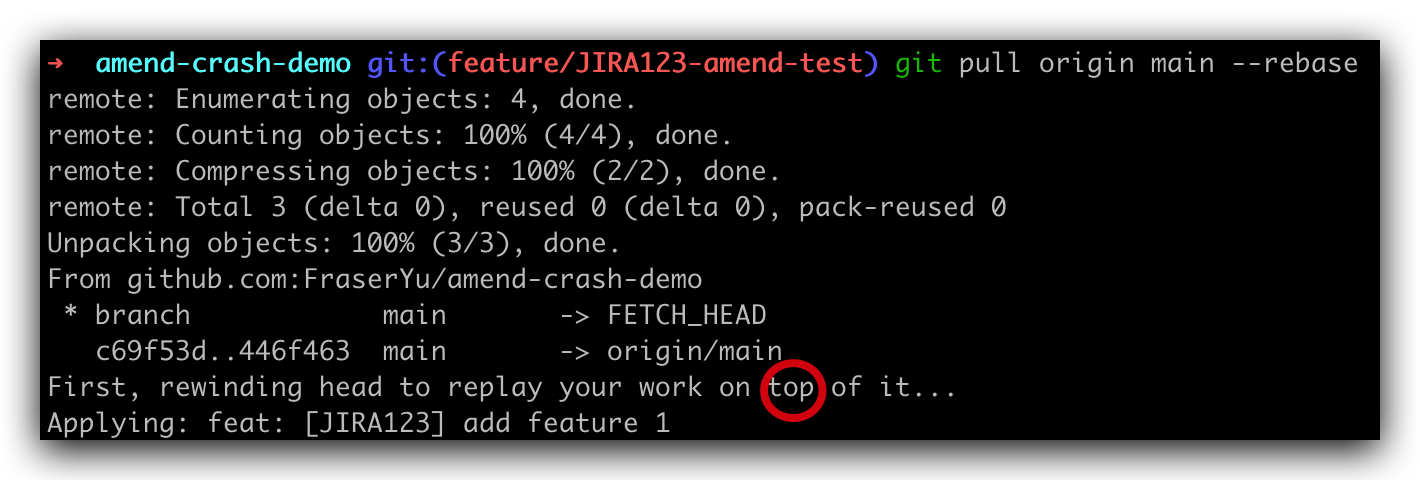
The back of the pull command is to automatically do merge for us, but here in the form of rebase, let's take a look at the log
* d40daa6 (HEAD -> feature/JIRA123-amend-test) feat: [JIRA123] add feature 1 * 446f463 (origin/main, origin/HEAD) Create main.properties * c69f53d (origin/feature/JIRA123-amend-test, main) Initial commit
Our feature1 function remains linear at the submission node of on top of main. Next, you can push the code, and then raise PR to merge your feature into the main branch
Briefly describe the difference between merge and rebase as follows:

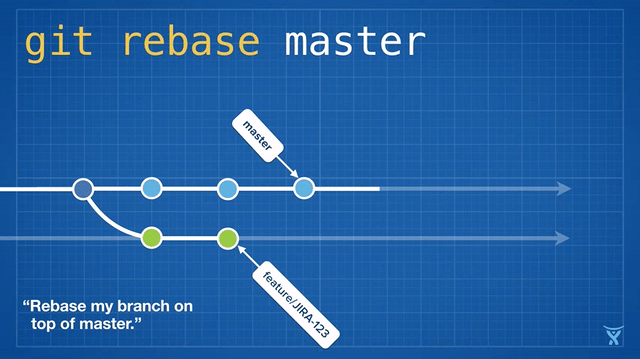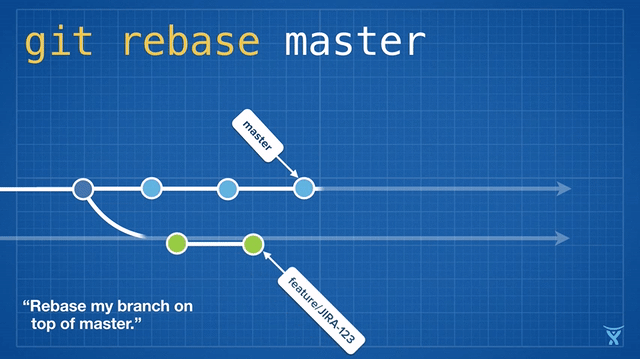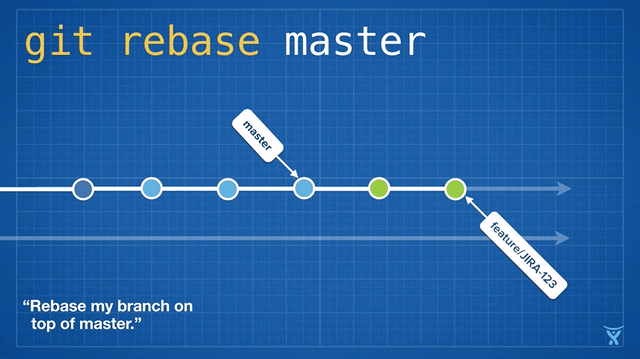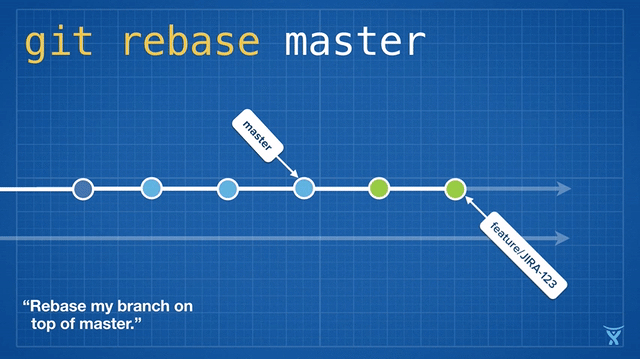
I use git pull origin main --rebase here, omitting the process of switching main, pulling the latest content and then cutting back. The principle behind it is shown in the figure above
Using rebase is to follow a golden rule, which has been mentioned before, so it is no longer repeated
summary
With these three brochures, I believe everyone's git log is extremely clear. If you don't know it, you can use it. If members of your group don't know it, you can promote it. This repo looks healthier
Next, we will introduce a brocade bag in which multi branch switching does not affect each other
Original | Japanese arch one soldier