Original title: Spring certified China Education Management Center - Spring Data MongoDB tutorial 6 (content source: Spring China Education Management Center)
JSON schema type
The following table shows the supported JSON schema types:

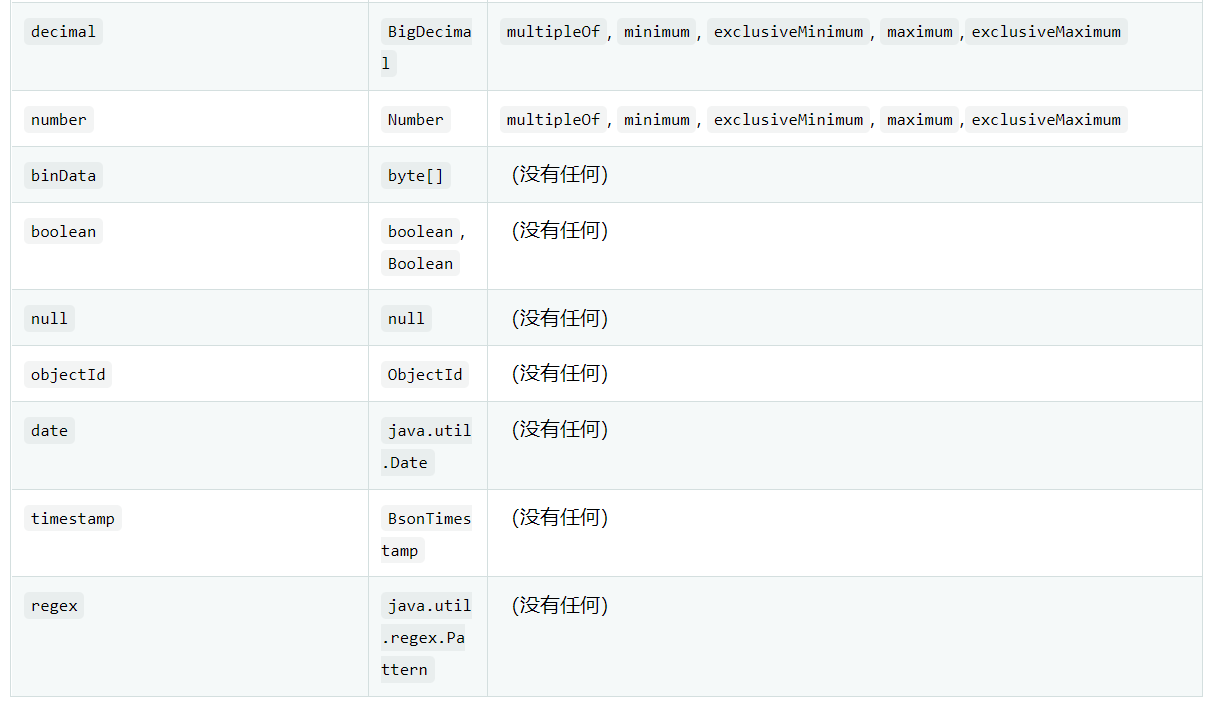
Untyped is a generic type inherited by all typed schema types. It provides all schema properties for untyped typed schema types.
For more information, see $jsonSchema.
11.6.8. Fluent template API
MongoOperations this interface is one of the core components when it comes to more low-level interaction with MongoDB. It provides a wide range of methods, ranging from collection creation, index creation and CRUD operation to higher-level functions (such as map reduce and aggregation) You can find multiple overloads for each method. Most of them cover the optional or nullable parts of the API.
Fluent MongoOperations provides a narrower interface for common methods and provides a more readable and fluent API. Entry points (insert(...), find(...), update(...), and others) Follow a natural naming pattern based on the operation to run. Starting from the entry point, the API is designed to provide only context dependent methods that cause the termination method of the actual MongoOperations counterpart to be called - all the method in the following example:
List<SWCharacter> all = ops.find(SWCharacter.class)
.inCollection("star-wars")
.all();If you define the collection @ Document with the class name SWCharacter or use the class name as the collection name, it is good to skip this step.
Sometimes, in MongoDB, sets hold different types, such as SWCharacters in the collection of entity Jedi. To use different types for Query and return value mapping, you can use as (class <? > TargetType) different mapping results, as shown in the following example:
List<Jedi> all = ops.find(SWCharacter.class)
.as(Jedi.class)
.matching(query(where("jedi").is(true)))
.all();Query fields are mapped according to SWCharacter type.
The resulting document is mapped to Jedi
You can directly apply the projection to the result document as (class <? >) by providing the target type.
Using projection allows MongoTemplate to optimize the result mapping by limiting the actual response to the fields required to project the target type. This applies as long as Query itself does not contain any field restrictions and the target type is a closed interface or DTO projection.
You can retrieve a single entity and retrieve multiple entities as a switch between List or Stream through the termination method: first(), one(), all(), or stream().
When writing a geospatial query using near(NearQuery), the number of termination methods will be changed to include only the methods that are valid for geoNear to run commands in MongoDB (get GeoResults from the entity as GeoResult), as shown in the following example:
GeoResults<Jedi> results = mongoOps.query(SWCharacter.class) .as(Jedi.class) .near(alderaan) // NearQuery.near(-73.9667, 40.78).maxDis... .all();
11.6.9. Type safety query of kotlin
Kotlin supports domain specific language creation through its language syntax and extension system. Spring Data MongoDB comes with a kotlin extension for Criteria to use kotlin attribute references to build type safe queries. Queries using this extension usually benefit from improved readability. Most keyword Criteria have matching kotlin extensions, such as inValues and regex.
Consider the following example of interpreting type safe queries:
import org.springframework.data.mongodb.core.query.*
mongoOperations.find<Book>(
Query(Book::title isEqualTo "Moby-Dick")
)
mongoOperations.find<Book>(
Query(titlePredicate = Book::title exists true)
)
mongoOperations.find<Book>(
Query(
Criteria().andOperator(
Book::price gt 5,
Book::price lt 10
))
)
// Binary operators
mongoOperations.find<BinaryMessage>(
Query(BinaryMessage::payload bits { allClear(0b101) })
)
// Nested Properties (i.e. refer to "book.author")
mongoOperations.find<Book>(
Query(Book::author / Author::name regex "^H")
)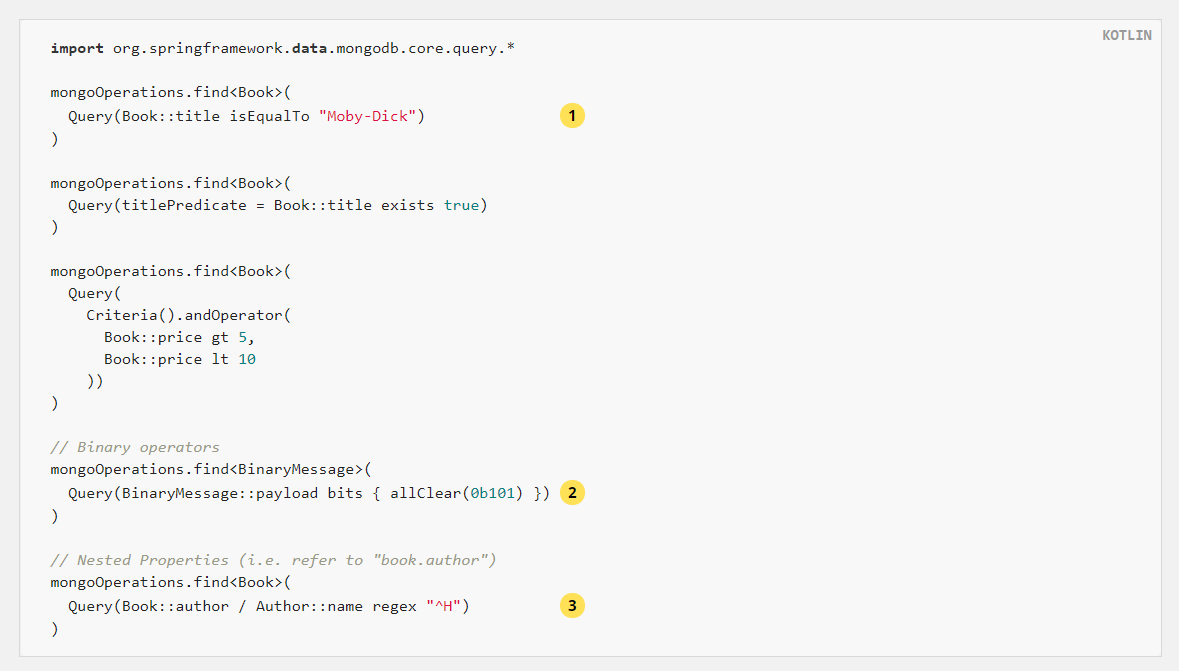
isEqualTo() is a receiver type infix extension function kproperty < T >, which returns Criteria
For bitwise operators to pass a lambda parameter, you can invoke it in it. Criteria.BitwiseCriteriaOperators.
To construct nested properties, use the / character (overloaded operator div).
11.6.10. Other Query options
MongoDB provides a variety of Query methods to apply meta information (such as comments or batch size) to queries. There are several methods to use these options directly using the API.
Query query = query(where("firstname").is("luke"))
.comment("find luke")
.batchSize(100) Comments are propagated to the MongoDB profile log.
The number of documents to return in each response batch.
At the repository level, the @ Meta annotation provides a way to add Query options declaratively.
@Meta(comment = "find luke", batchSize = 100, flags = { SLAVE_OK })
List<Person> findByFirstname(String firstname);11.7. Query by example
11.7.1. Introduction
This chapter introduces Query by Example and explains how to use it.
Example query (QBE) is a user-friendly query technology with a simple interface. It allows you to create queries dynamically and does not require you to write queries containing field names. In fact, Query by Example does not require you to write queries in a store specific query language at all.
11.7.2. Usage
The Query by Example API consists of three parts:
- Probe: a practical example of a domain object with populated fields.
- ExampleMatcher: ExampleMatcher contains detailed information about how to match specific fields. It can be reused in multiple examples.
- Example: AnExample consists of a probe and an ExampleMatcher. It is used to create a query.
Query by Example is very suitable for the following use cases:
- Query your data store using a set of static or dynamic constraints.
- Refactor domain objects frequently without worrying about breaking existing queries.
- Work independently of the underlying data store API.
Query by Example also has several limitations:
- Nested or grouped attribute constraints are not supported, such as firstname =? 0 or (firstname =? 1 and LastName =? 2)
- Only start / include / end / regular expression matching of strings and exact matching of other attribute types are supported.
Before you start using Query by Example, you need to have a domain object. First, create an interface for your repository, as shown in the following example:
Example 91. Example Person object
public class Person {
@Id
private String id;
private String firstname;
private String lastname;
private Address address;
// ... getters and setters omitted
}The previous Example shows a simple domain object. You can use it to create an Example. By default, null ignores fields with values and matches strings with store specific default values.
The inclusion of properties in the Query by Example standard is based on nullability. Properties that use the original type (int, double,...) are always included unless the property path is ignored. You can use the of factory method or use ExampleMatcher. Example is immutable. The following listing shows a simple example:
Example 92. Simple example
Person person = new Person();
person.setFirstname("Dave");
Example<Person> example = Example.of(person); Create a new instance of the domain object.
Set the properties to query.
Create Example
You can run sample queries using the repository. To do this, let your repository interface extend QueryByExampleExecutor < T >. The following listing shows excerpts from the QueryByExampleExecutor interface:
Example 93. QueryByExampleExecutor
public interface QueryByExampleExecutor<T> {
<S extends T> S findOne(Example<S> example);
<S extends T> Iterable<S> findAll(Example<S> example);
// ... more functionality omitted.
}11.7.3. Example matcher
Examples are not limited to default settings. You can use ExampleMatcher to specify your own default values for string matching, null handling, and property specific settings, as shown in the following example:
Example 94. Example matcher with custom matching
Person person = new Person();
person.setFirstname("Dave");
ExampleMatcher matcher = ExampleMatcher.matching()
.withIgnorePaths("lastname")
.withIncludeNullValues()
.withStringMatcher(StringMatcher.ENDING);
Example<Person> example = Example.of(person, matcher); Create a new instance of the domain object.
Set properties.
Create an ExampleMatcher to expect all values to match. It can be used at this stage even without further configuration.
Construct a new ExampleMatcher that ignores the lastname attribute path.
Construct a newExampleMatcher to ignore the lastname property path and contain null values.
Construct a newExampleMatcher to ignore the lastname attribute path, contain null values, and perform suffix string matching.
Create a new Example based on the domain object and configure the ExampleMatcher.
By default, ExampleMatcher expects all values set on the probe to match. If you want to get results that match any implicitly defined predicates, use ExampleMatcher.matchingAny().
You can specify behavior for a single attribute, such as first name and last name, or for nested attributes, address.city. You can adjust it using the match option and case sensitivity, as shown in the following example:
Example 95. Configure matcher options
ExampleMatcher matcher = ExampleMatcher.matching()
.withMatcher("firstname", endsWith())
.withMatcher("lastname", startsWith().ignoreCase());
}Another way to configure matcher options is to use lambdas (introduced in Java 8). This method creates a callback that requires the implementer to modify the matcher. You do not need to return to the matcher because the configuration options are saved in the matcher instance. The following example shows a matcher using lambda:
Example 96. Configuring matcher options using lambda
ExampleMatcher matcher = ExampleMatcher.matching()
.withMatcher("firstname", match -> match.endsWith())
.withMatcher("firstname", match -> match.startsWith());
}Example a query created using the configured merge view. The default matching settings can be set at the ExampleMatcher level, while individual settings can be applied to specific attribute paths. The setting ExampleMatcher on the set is inherited by the property path setting unless they are explicitly defined. The settings on the property patch have higher priority than the default settings. The following table describes the range of various ExampleMatcher settings:
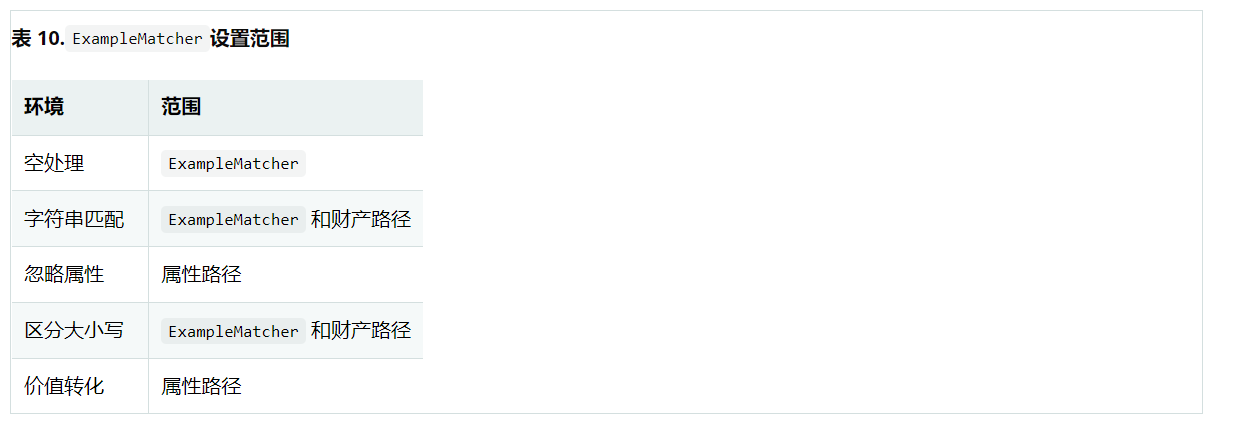
11.7.4. Operation example
The following example shows how to query by example when using the repository (Person is an object in this case):
Example 97. Query by example using repository
public interface PersonRepository extends QueryByExampleExecutor<Person> {
}
public class PersonService {
@Autowired PersonRepository personRepository;
public List<Person> findPeople(Person probe) {
return personRepository.findAll(Example.of(probe));
}
}An Example contains untyped ExampleSpec usage library types and their collection names. Typed ExampleSpec instances use their types as collection names for result types and Repository instances.
When null values are included in ExampleSpec, Spring Data Mongo uses embedded document matching instead of dot symbol attribute matching. Doing so forces precise document matching of all attribute values and attribute order embedded in the document.
Spring Data MongoDB supports the following matching options:

11.7.5. No type example
By default, Example is strictly typed. This means that the mapped query has contained type matches, limiting it to probe assignable types. For Example, when you insist on using the default type key (_class), the query has restrictions such as (_class: {$in: [com. Acme. Person]}).
By using UntypedExampleMatcher, you can bypass the default behavior and skip type restrictions. Therefore, almost any domain type can be used as a probe to create a reference as long as the field names match, as shown in the following example:
Example 98. Query without type
class JustAnArbitraryClassWithMatchingFieldName {
@Field("lastname") String value;
}
JustAnArbitraryClassWithMatchingFieldNames probe = new JustAnArbitraryClassWithMatchingFieldNames();
probe.value = "stark";
Example example = Example.of(probe, UntypedExampleMatcher.matching());
Query query = new Query(new Criteria().alike(example));
List<Person> result = template.find(query, Person.class);UntypedExampleMatcher if you store different entities in a single collection or choose not to write type prompts, this may be your correct choice.
Also, remember that using @ TypeAlias requires a mapping context. To do this, configure the initialEntitySet to ensure correct alias resolution for the read operation.
11.8. Counting file
In versions prior to SpringData MongoDB 3.x, the count operation used MongoDB's internal to collect statistics. With the introduction of MongoDB transactions, this is no longer possible because statistics do not correctly reflect potential changes during transactions that require aggregation based counting methods. Therefore, in version 2.x, MongoOperations.count() will use to collect statistics if there are no ongoing transactions, and if so, aggregate variants.
Starting from Spring Data MongoDB 3.x, any count operation uses the filter condition of the aggregation based counting method of MongoDBs to determine whether there are countDocuments. If the application works well under the constraints of processing and collecting statistics, then MongoOperations.estimatedCount() provides an alternative method.
MongoDBs local countDocuments method and $match aggregation do not support $near and $nearSphere, but $geoWithin together with $center or $centerSphere do not support $minDistance (see https://jira.mongodb.org/browse/SERVER-37043).
Therefore, Query will override the given count operation and use Reactive-/MongoTemplate to bypass the problem shown below.
{ location : { $near : [-73.99171, 40.738868], $maxDistance : 1.1 } }
{ location : { $geoWithin : { $center: [ [-73.99171, 40.738868], 1.1] } } }
{ location : { $near : [-73.99171, 40.738868], $minDistance : 0.1, $maxDistance : 1.1 } }
{$and :[ { $nor :[ { location :{ $geoWithin :{ $center :[ [-73.99171, 40.738868 ], 0.01] } } } ]}, { location :{ $geoWithin :{ $center :[ [-73.99171, 40.738868 ], 1.1] } } } ] }
Use the count source to query $near.
Now rewrite the query $center with $geoWithinwith.
Query $maxDistance using $nearwith$minDistance and the calculated source.
The rewritten query now combines the $nor $geowathin standard to resolve the unsupported $minDistance
11.9. Map reduce operation
You can use map reduce to query MongoDB, which is very useful for batch processing, data aggregation and when the query language can not meet your needs.
Spring simplifies the creation and operation of map reduce operations by providing the method MongoOperations, thus providing integration with MongoDB's map reduce. It can convert the results of map reduce operations into POJO s and integrate with spring's Resource abstraction. This allows you to place data on your file system, classpath, HTTP server or any other spring Resource implementation JavaScript files, and then reference JavaScript resources through simple URI style syntax -- for example, classpath:reduce.js; externalizing JavaScript code in a file is usually preferable to embedding them in a file as a Java string. Note that you can still pass JavaScript code as a Java string if you like.
11.9.1. Example usage
In order to understand how to perform the map reduce operation, we use an example in mongodb - the definitive guide [1]. In this example, we create three documents with values [a,b], [b,c] and [c,d]. The values in each document are associated with the key "x", as shown in the following example (assuming that these documents are located in the set named jmr1):
{ "_id" : ObjectId("4e5ff893c0277826074ec533"), "x" : [ "a", "b" ] }
{ "_id" : ObjectId("4e5ff893c0277826074ec534"), "x" : [ "b", "c" ] }
{ "_id" : ObjectId("4e5ff893c0277826074ec535"), "x" : [ "c", "d" ] }The following map function calculates the number of occurrences of each letter in the array of each document:
function () {
for (var i = 0; i < this.x.length; i++) {
emit(this.x[i], 1);
}
}The following reduce function summarizes the occurrence of each letter in all documents:
function (key, values) {
var sum = 0;
for (var i = 0; i < values.length; i++)
sum += values[i];
return sum;
}Running the above function produces the following set:
{ "_id" : "a", "value" : 1 }
{ "_id" : "b", "value" : 2 }
{ "_id" : "c", "value" : 2 }
{ "_id" : "d", "value" : 1 }Suppose that the map and reduce functions are located in map.js and reduce.js and bundled in your jar, so they are available on the classpath. You can run the map reduce operation as follows:
MapReduceResults<ValueObject> results = mongoOperations.mapReduce("jmr1", "classpath:map.js", "classpath:reduce.js", ValueObject.class);
for (ValueObject valueObject : results) {
System.out.println(valueObject);
}The previous example produces the following output:
ValueObject [id=a, value=1.0] ValueObject [id=b, value=2.0] ValueObject [id=c, value=2.0] ValueObject [id=d, value=1.0]
The MapReduceResults class of implements iteratable and provides the raw output and timing of access, and the count statistics.TheValueObject class is listed below:
public class ValueObject {
private String id;
private float value;
public String getId() {
return id;
}
public float getValue() {
return value;
}
public void setValue(float value) {
this.value = value;
}
@Override
public String toString() {
return "ValueObject [id=" + id + ", value=" + value + "]";
}
}By default, the output type is INLINE, so you do not need to specify an output set. To specify additional map reduce options, use the overloaded method with the additional MapReduceOptions parameter. This class MapReduceOptions has a smooth API, so you can add additional options to complete it with a compact syntax. The following example outputs the set jmr1_out is set to (note that only the output set is set, assuming the default output type is REPLACE):
MapReduceResults<ValueObject> results = mongoOperations.mapReduce("jmr1", "classpath:map.js", "classpath:reduce.js",
new MapReduceOptions().outputCollection("jmr1_out"), ValueObject.class);There is also an import static org.springframework.data.mongodb.core.mapreduce.MapReduceOptions.options;) can be used to make the syntax a little more compact, as shown in the following example:
MapReduceResults<ValueObject> results = mongoOperations.mapReduce("jmr1", "classpath:map.js", "classpath:reduce.js",
options().outputCollection("jmr1_out"), ValueObject.class);You can also specify a query to reduce the dataset of input map reduce operations. The following example deletes the document containing [a,b] from the consideration of map reduce operation:
Query query = new Query(where("x").ne(new String[] { "a", "b" }));
MapReduceResults<ValueObject> results = mongoOperations.mapReduce(query, "jmr1", "classpath:map.js", "classpath:reduce.js",
options().outputCollection("jmr1_out"), ValueObject.class);Note that you can specify additional limits and sort values on the query, but you cannot skip values.