Deploying k8s clusters in kubedm mode
Official documents:
<https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/>
Remember to turn off the firewall and selinux. The number of cpu cores should be at least 2
Official documents for kubedm deploying k8s highly available clusters:
<https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/>
Install docker – all three machines operate
The premise of doing this is that you have downloaded docker on all three machines, and it doesn't matter if you have the latest version
Get image
Ali warehouse Download
I use two methods to cluster here. The first is to directly pull the image and change the tag
The second method is that I first pull all the images and change the labels. The script I write directly uploads the images into the docker. I will summarize this method later
The first method:
[root@k8s-master ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.19.1 [root@k8s-master ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.19.1 [root@k8s-master ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.19.1 [root@k8s-master ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.19.1 [root@k8s-master ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.5 [root@k8s-master ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.3-0 [root@k8s-master ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 docker pull quay-mirror.qiniu.com/coreos/flannel:v0.12.0-amd64 --Download the configuration file of the network plug-in
The second method: write a script to directly pull the whole process without pulling one by one
vim pull.sh
#!/bin/bash docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.19.1 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.19.1 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.19.1 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.19.1 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.5 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.3-0 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2 docker pull quay-mirror.qiniu.com/coreos/flannel:v0.12.0-amd64
Change tag
After downloading, all images downloaded by aliyun need to be labeled as k8s.gcr.io/kube-controller-manager:v1.17.0
The first method:
[root@k8s-master ~]# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.19.1 k8s.gcr.io/kube-controller-manager:v1.19.1 [root@k8s-master ~]# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.19.1 k8s.gcr.io/kube-proxy:v1.19.1 [root@k8s-master ~]# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.19.1 k8s.gcr.io/kube-apiserver:v1.19.1 [root@k8s-master ~]# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.19.1 k8s.gcr.io/kube-scheduler:v1.19.1 [root@k8s-master ~]# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.5 k8s.gcr.io/coredns:1.7.0 [root@k8s-master ~]# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.3-0 k8s.gcr.io/etcd:3.4.13-0 [root@k8s-master ~]# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.2 The version number does not change
The second method is to write a script and change the script directly
vim tag.sh
#!/bin/bash docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.19.1 k8s.gcr.io/kube-controller-manager:v1.19.1 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.19.1 k8s.gcr.io/kube-proxy:v1.19.1 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.19.1 k8s.gcr.io/kube-apiserver:v1.19.1 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.19.1 k8s.gcr.io/kube-scheduler:v1.19.1 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.5 k8s.gcr.io/coredns:1.7.0 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.3-0 k8s.gcr.io/etcd:3.4.13-0 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.2 The version number does not change
All machines must have mirrors
Complete installation process
Prepare three machines for time synchronization
192.168.246.166 kub-k8s-master 192.168.246.167 kub-k8s-node1 192.168.246.169 kub-k8s-node2 Make local resolution and modify the host name. Mutual analysis # vim /etc/hosts
All machine system configurations
1.Turn off the firewall: # systemctl stop firewalld # systemctl disable firewalld 2.Disable SELinux: # setenforce 0 3.Edit file/etc/selinux/config,take SELINUX Change to disabled,As follows: # sed -i 's/SELINUX=permissive/SELINUX=disabled/' /etc/sysconfig/selinux SELINUX=disabled
Shut down system Swap: new regulations after 1.5
# swapoff -a
modify/etc/fstab File, comment out SWAP Auto mount, using free -m confirm swap Has been closed.
2.Comment out swap Partition:
[root@localhost /]# sed -i 's/.*swap.*/#&/' /etc/fstab
# free -m
total used free shared buff/cache available
Mem: 3935 144 3415 8 375 3518
Swap: 0 0 0
Deploying Kubernetes using kubedm:
Install kubedm and kubelet on all nodes:
Configuration source
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
All nodes:
View historical versions:# yum list kubectl --showduplicates | sort -r View the image used by the version: # kubeadm config images list --kubernetes-version=v1.19.1
1. Installation
[root@k8s-master ~]# yum install -y kubelet-1.19.1-0.x86_64 kubeadm-1.19.1-0.x86_64 kubectl-1.19.1-0.x86_64 ipvsadm
2. Load ipvs related kernel modules
If you restart, you need to reload (you can write it in / etc/rc.local and load it automatically after startup)
# modprobe ip_vs # modprobe ip_vs_rr # modprobe ip_vs_wrr # modprobe ip_vs_sh # modprobe nf_conntrack_ipv4 3.Edit file add boot # vim /etc/rc.local # chmod +x /etc/rc.local
Script mode
#!/bin/bash modprobe ip_vs modprobe ip_vs_rr modprobe ip_vs_wrr modprobe ip_vs_sh modprobe nf_conntrack_ipv4
4. Configuration:
Configure forwarding related parameters, otherwise errors may occur
cat <<EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 vm.swappiness=0 EOF
5. Make the configuration effective
sysctl --system
6. If net.bridge.bridge-nf-call-iptables reports an error, load br_netfilter module
# modprobe br_netfilter # sysctl -p /etc/sysctl.d/k8s.conf
7. Check whether the loading is successful
# lsmod | grep ip_vs ip_vs_sh 12688 0 ip_vs_wrr 12697 0 ip_vs_rr 12600 0 ip_vs 141092 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr nf_conntrack 133387 2 ip_vs,nf_conntrack_ipv4 libcrc32c 12644 3 xfs,ip_vs,nf_conntrack
Configure startup kubelet (all nodes)
1. Configure kubelet to use pause image
Get cgroups of docker
[root@k8s-master ~]# DOCKER_CGROUPS=`docker info |grep 'Cgroup' | awk 'NR==1{print $3}'`
[root@k8s-master ~]# echo $DOCKER_CGROUPS
cgroupfs
Configure cgroups for kubelet
cat >/etc/sysconfig/kubelet<<EOF KUBELET_EXTRA_ARGS="--cgroup-driver=cgroupfs --pod-infra-container-image=k8s.gcr.io/pause:3.2" EOF
Check it out
# cat /etc/sysconfig/kubelet #The correct one is on the same line
start-up
# systemctl daemon-reload # systemctl enable kubelet && systemctl restart kubelet Use here # systemctl status kubelet, you will find an error message;
Configure master node
Run the initialization process as follows:
Before initialization, remember to turn off the firewall and selinux, and the number of cpu cores should be at least 2
kubeadm init --kubernetes-version=v1.19.1 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.246.166 --ignore-preflight-errors=Swap
explain
Note: apiserver-advertise-address=192.168.246.166 ---master of ip Address. --kubernetes-version=v1.19.1 --More specific version for modification Be careful to check swap Is the partition closed
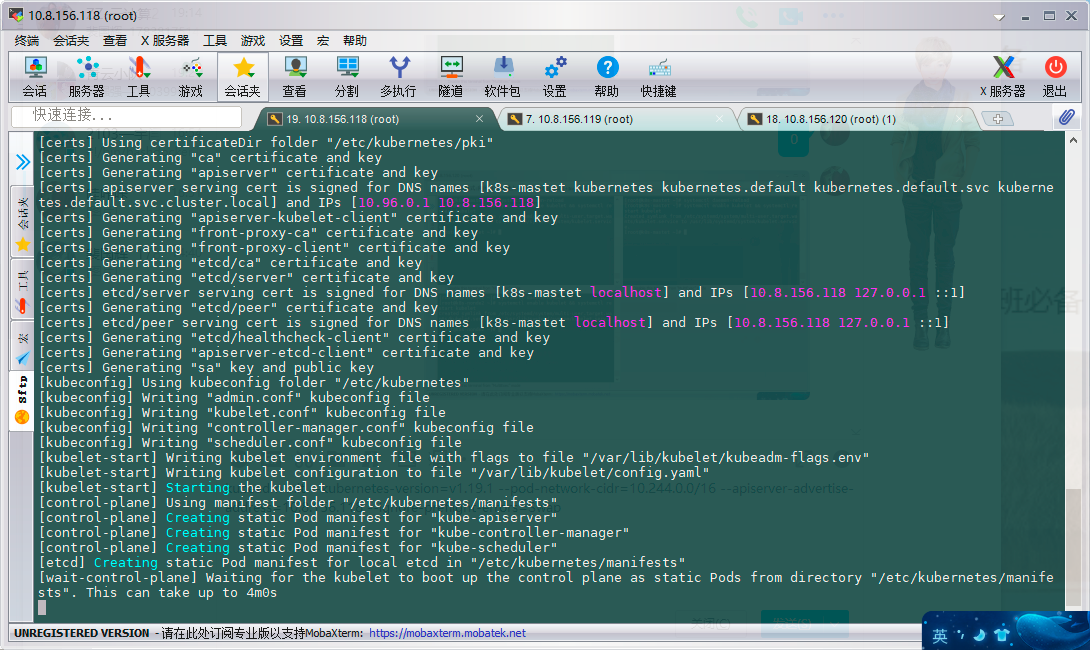 If an error is reported, there will be a version prompt, that is, there is an updated version
If an error is reported, there will be a version prompt, that is, there is an updated version
The contents of the completed initialization output are recorded above. According to the output, we can basically see the key steps required to manually initialize and install a Kubernetes cluster.
There are the following key contents:
[kubelet] generate kubelet Profile for/var/lib/kubelet/config.yaml" [certificates]Generate relevant certificates [kubeconfig]Generate related kubeconfig file [bootstraptoken]generate token Write it down and use it later kubeadm join It is used when adding nodes to the cluster
Configure to use kubectl
The following operations are performed on the master node
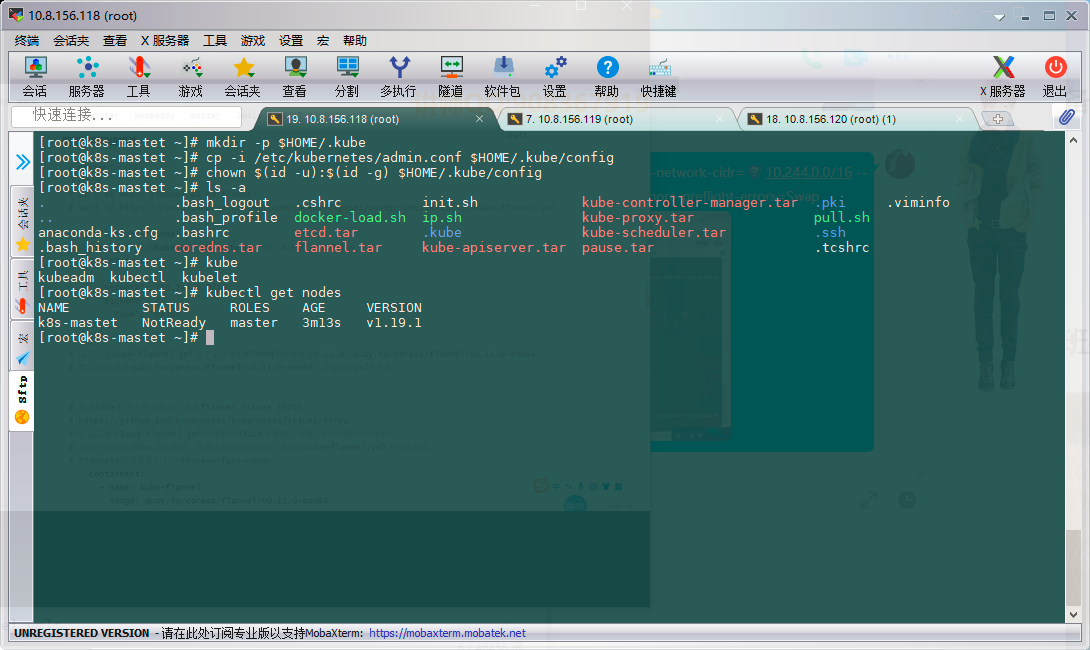
[root@kub-k8s-master ~]# rm -rf $HOME/.kube [root@kub-k8s-master ~]# mkdir -p $HOME/.kube [root@kub-k8s-master ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@kub-k8s-master ~]# chown $(id -u):$(id -g) $HOME/.kube/config
View node
[root@k8s-master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master NotReady master 2m41s v1.17.4
Configure and use network plug-ins
Operate on the master node
Download configuration
cd ~ && mkdir flannel && cd flannel # curl -O https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
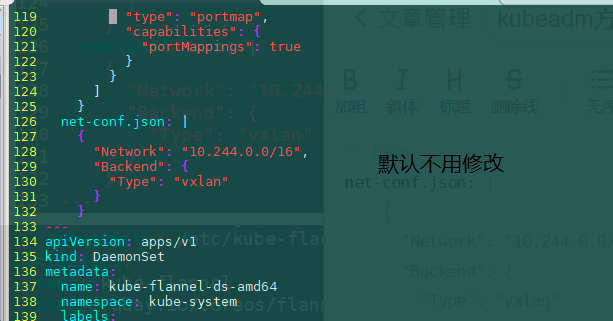
Modify the configuration file kube-flannel.yml:
The ip configuration here should be consistent with the pod network of kubedm above. It is consistent and does not need to be changed
First configuration file
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
 Modify the second place
Modify the second place
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.11.0-amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=ens33
- --iface=eth0
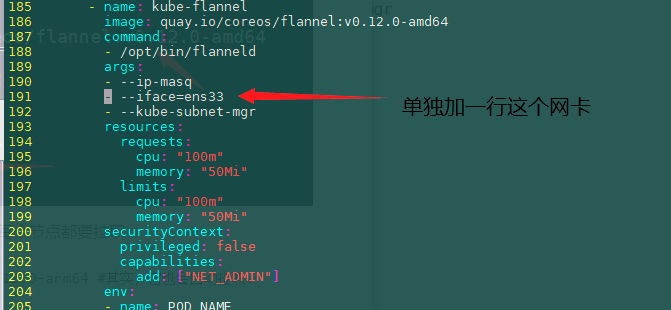 Modify the third place
Modify the third place
- key: beta.kubernetes.io/arch
operator: In
values:
- arm64
hostNetwork: true
tolerations:
- operator: Exists
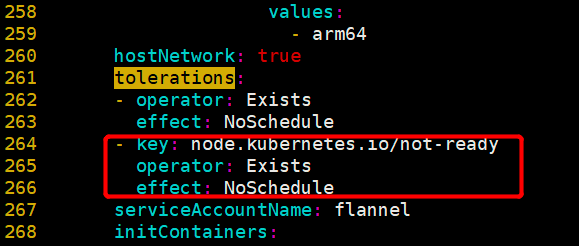
effect: NoSchedule
- key: node.kubernetes.io/not-ready #Add the following three lines --- around 261
operator: Exists
effect: NoSchedule
serviceAccountName: flannel
Start:
#Wait for a while after startup
kubectl apply -f ~/flannel/kube-flannel.yml
see:
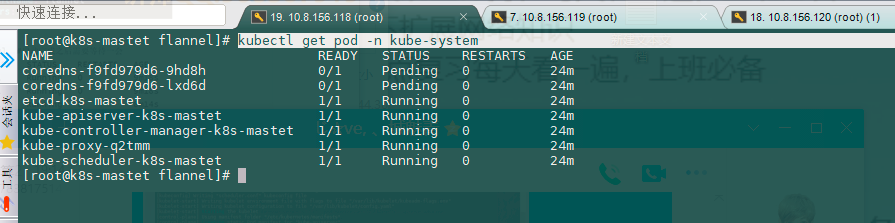
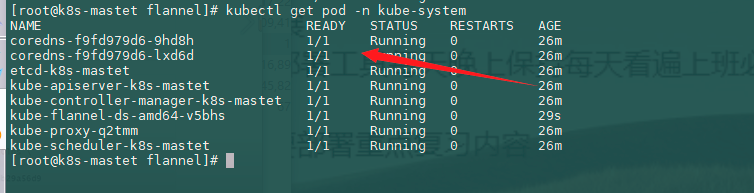
kubectl get pod -n kube-system
All node operations
Configure node nodes to join the cluster:
If an error is reported, enable ip forwarding:
# sysctl -w net.ipv4.ip_forward=1
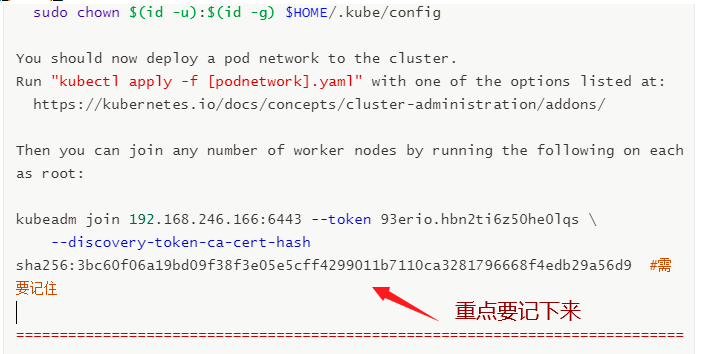
In all node operations, this command is the result returned after the master is initialized successfully
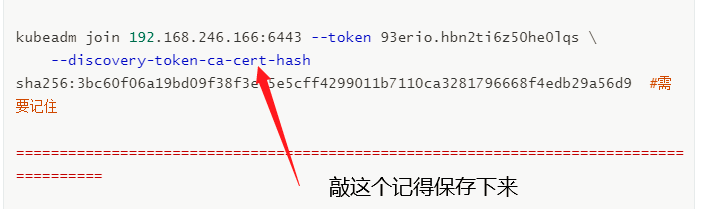
Everyone's is different. Remember to keep your own
kubeadm join 192.168.246.166:6443 --token 93erio.hbn2ti6z50he0lqs \
--discovery-token-ca-cert-hash sha256:3bc60f06a19bd09f38f3e05e5cff4299011b7110ca3281796668f4edb29a56d9
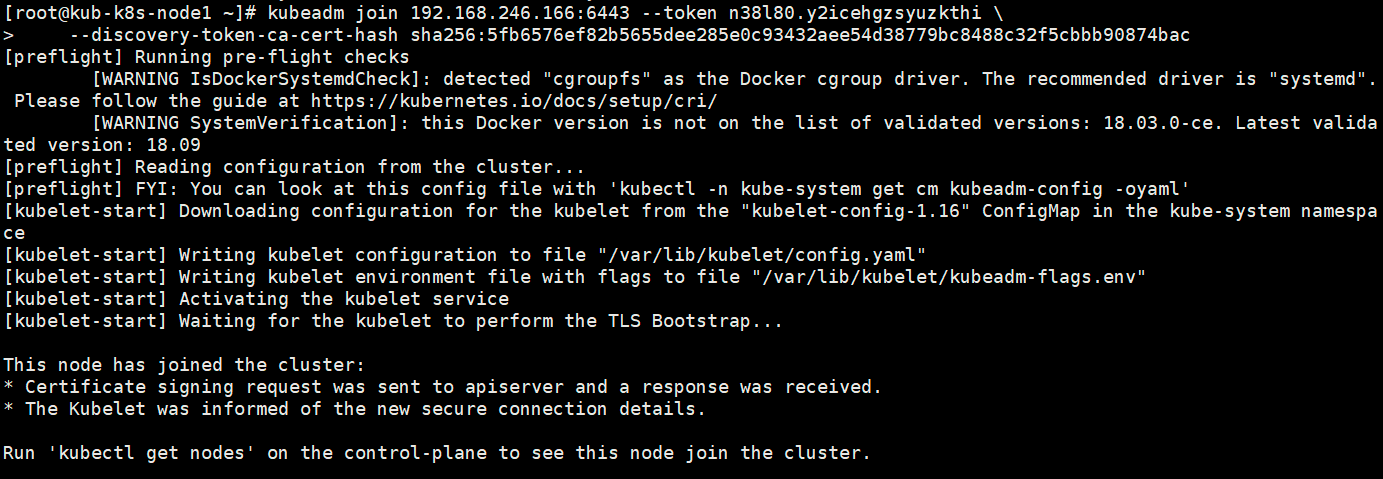
In the master operation:
1.see pods: [root@kub-k8s-master ~]# kubectl get pods -n kube-system
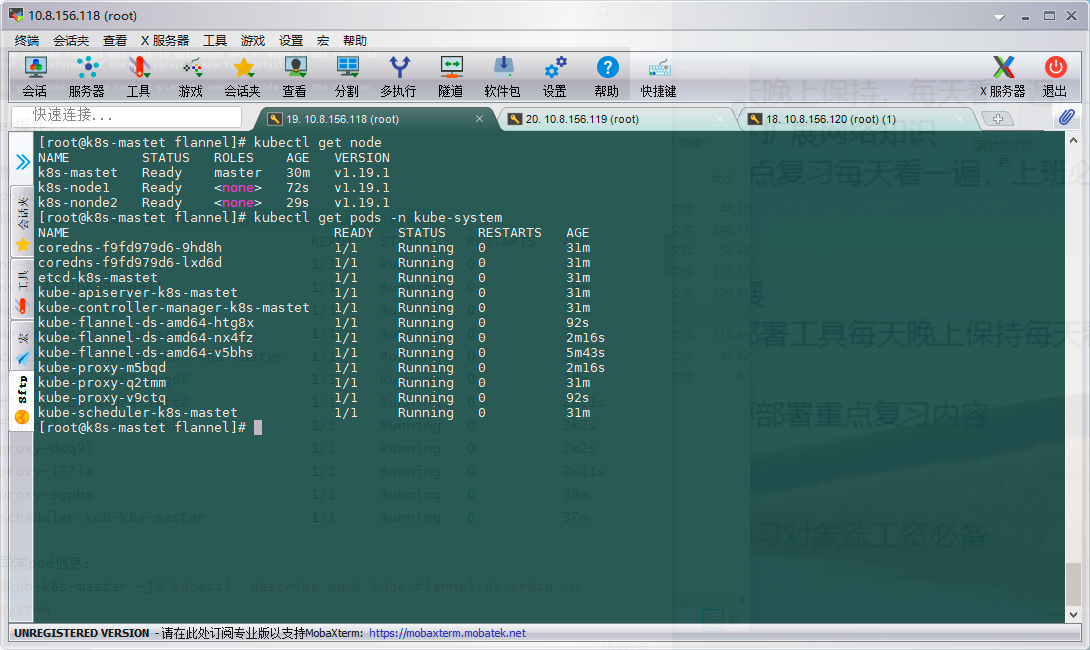
Summarize the second method
In the first method, first remove the image and then type the tag.
Write a script to upload all images to docker
vim docker.sh
#!/bin/bash docker load -i etcd.tar docker load -i flannel.tar docker load -i kube-apiserver.tar docker load -i kube-controller-manager.tar docker load -i kube-proxy.tar docker load -i kube-scheduler.tar docker load -i pause.tar docker load -i coredns.tar docker images
Then use the network plug-in for configuration. Instead of downloading the image, just write the configuration file directly.

Summary of problems encountered
To view abnormal pod information:
[root@kub-k8s-master ~]# kubectl describe pods kube-flannel-ds-sr6tq -n kube-system
 In this case, delete the exception pod directly:
In this case, delete the exception pod directly:
[root@kub-k8s-master ~]# kubectl delete pod kube-flannel-ds-sr6tq -n kube-system pod "kube-flannel-ds-sr6tq" deleted 4.see pods: [root@kub-k8s-master ~]# kubectl get pods -n kube-system
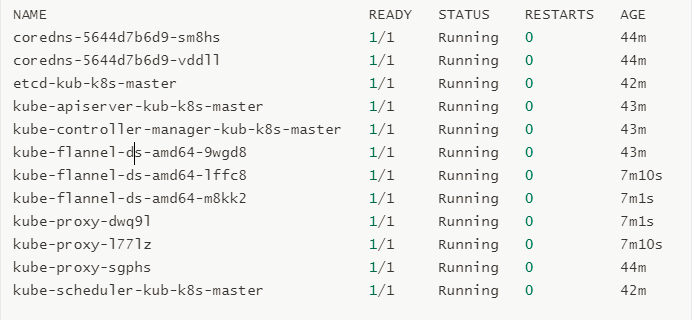 5. View nodes
5. View nodes

error
Problem 1: an error will be reported if the server time is inconsistent
View server time
Question 2: kubedm init failed. The following prompt is found, and then an error is reported
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
After checking the kubelet status, the following errors are found: the host master cannot be found and the image download fails. It is found that the pause image is downloaded from aliyuncs. In fact, I have downloaded the official pause image, re tag the pause image according to the prompted image name, and finally reset the kubedm environment to reinitialize. The error is resolved
Solution
Reset node (on node - that is, on the deleted node)
[root@kub-k8s-node1 ~]# kubeadm reset #All machine operations
Note 1: it is necessary to drive, delete and reset the master. I'm in a hole here. For the first time, I didn't drive and delete the master. The final result is that everything is normal, but coredns can't be used. It's been a whole day. Don't try
Note 2: the following files need to be deleted after reset on the master
rm -rf /var/lib/cni/ $HOME/.kube/config #All machine operations
Note: if the entire k8s cluster has been reset, follow the above steps. If there is an initialization error, you only need to reset the node
Regenerate token
kubeadm Generated token After expiration, the cluster adds nodes
adopt kubeadm After initialization, it will be provided node Joined token:
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 192.168.246.166:6443 --token n38l80.y2icehgzsyuzkthi \
--discovery-token-ca-cert-hash sha256:5fb6576ef82b5655dee285e0c93432aee54d38779bc8488c32f5cbbb90874bac
default token The validity period of is 24 hours. When it expires, the token It's not available.
resolvent:
- Regenerate a new token:
resolvent: 1. Regenerate new token: [root@node1 flannel]# kubeadm token create kiyfhw.xiacqbch8o8fa8qj [root@node1 flannel]# kubeadm token list TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS gvvqwk.hn56nlsgsv11mik6 <invalid> 2018-10-25T14:16:06+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token kiyfhw.xiacqbch8o8fa8qj 23h 2018-10-27T06:39:24+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token 2. obtain ca certificate sha256 code hash value: [root@node1 flannel]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //' 5417eb1b68bd4e7a4c82aded83abc55ec91bd601e45734d6aba85de8b1ebb057 3. Nodes join the cluster: kubeadm join 18.16.202.35:6443 --token kiyfhw.xiacqbch8o8fa8qj --discovery-token-ca-cert-hash sha256:5417eb1b68bd4e7a4c82aded83abc55ec91bd601e45734d6aba85de8b1ebb057 After a few seconds, you should notice kubectl get nodes This node in the runtime output on the primary server. The above method is cumbersome and can be achieved in one step: kubeadm token create --print-join-command The second method: token=$(kubeadm token generate) kubeadm token create $token --print-join-command --ttl=0