[source code analysis] PyTorch distributed (13) -- back propagation of distributed dataparallel
0x00 summary
We have analyzed the forward propagation of Reduer above. This paper then looks at how to carry out back propagation.
Other articles in this series are as follows:
Automatic differentiation of deep learning tools (1)
Automatic differentiation of deep learning tools (2)
[Source code analysis] automatic differentiation of deep learning tools (3) -- example interpretation
[Source code analysis] how PyTorch implements forward propagation (1) -- basic class (I)
[Source code analysis] how PyTorch implements forward propagation (2) -- basic classes (Part 2)
[Source code analysis] how PyTorch implements forward propagation (3) -- specific implementation
[Source code analysis] how pytoch implements backward propagation (1) -- call engine
[Source code analysis] how pytoch implements backward propagation (2) -- engine static structure
[Source code analysis] how pytoch implements backward propagation (3) -- engine dynamic logic
[Source code analysis] how PyTorch implements backward propagation (4) -- specific algorithm
[Source code analysis] PyTorch distributed (1) -- history and overview
[Source code analysis] PyTorch distributed (2) -- dataparallel (Part 1)
[Source code analysis] PyTorch distributed (3) -- dataparallel (Part 2)
[Source code analysis] PyTorch distributed (4) -- basic concept of distributed application
[Source code analysis] PyTorch distributed (5) -- overview of distributeddataparallel & how to use
[Source code analysis] PyTorch distributed (6) -- distributeddataparallel -- initialization & store
[Source code analysis] PyTorch distributed (7) -- process group of distributeddataparallel
[Source code analysis] PyTorch distributed (8) -- distributed dataparallel
[Source code analysis] PyTorch distributed (9) -- initialization of distributeddataparallel
[Source code analysis] PyTorch distributed (12) -- distributeddataparallel forward propagation
0x01 review
1.1 previous review
We have given the logic of forward propagation. After the forward propagation, we get the following results:
- The parameters to calculate the gradient have been divided into barrels.
- The barrel has been rebuilt.
- Forward propagation has been completed.
- Backtrack from the specified output, traverse the autograd calculation diagram to find all unused parameters, and mark them as ready.
In this way, DDP has the basis for gradient merging. It knows which parameters can be merged directly (ready state) without the operation of the autograd engine, and which parameters can be merged together (bucket Division). The subsequent initiative lies with the PyTorch autograd engine, which performs cross process gradient specification while doing reverse calculation.
1.2 overall logic
We give an overall strategy of backward propagation as follows:
Backward Pass:
- backward() is called directly on loss, which is the work of autograd and cannot be controlled by DDP. DDP uses Hook to achieve its purpose.
- DDP registers an autograd hooks during construction.
- Autograd engine for gradient calculation.
- When a gradient is ready, its corresponding DDP hook on the gradient accumulator will be triggered.
- In autograd_ All reduce in hook. Suppose the parameter index is param_index, param is used_ Index gets the parameter marked as ready. If the gradients in a bucket are ready, the bucket is ready.
- When the gradients in a bucket are ready, the Reducer will start asynchronous allreduce on the bucket to calculate the average gradient of all processes.
- If all buckets are ready, wait for all all reduce to complete. When all buckets are ready, the Reducer will block and wait for all allreduce operations to complete. When this is done, write the average gradient to the fields of all param.grad parameters.
- The gradient of all processes will be reduce d. After updating, everyone's model weight is the same. Therefore, after the backward propagation is completed, the grad fields on the corresponding same parameters across different DDP processes should be equal.
- After the gradient is merged, it is transmitted back to the autograd engine.
- There is no need to broadcast parameters after each iteration like DP. However, Buffers still need to be broadcast by the rank 0 process to other processes in each iteration.
Next, let's look at how to carry out backward communication.
0x02 start with Hook
The following is a quick essay from a Kwai Fu (see reference 1, which should also be analyzed later). The top half of the figure is the processing method of the native autograd engine, and the following is the processing method of Horovod and torch DDP. It can be seen that the gradient merging starts in the backward propagation process.
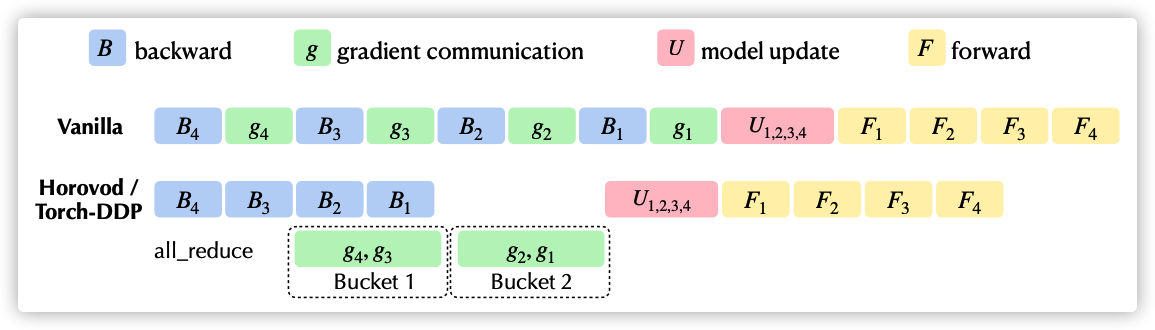
Specifically, in addition to bucket splitting, Reducer also registers autograd hooks during construction, one Hook for each parameter. When the gradient is ready, these hooks will be triggered during backward transfer for gradient specification. If all gradients in a bucket are ready, the bucket is ready. When the gradients in a bucket are ready, the Reducer will start asynchronous allreduce on the bucket to calculate the average gradient of all processes. Therefore, we start with Hook, the entry point of back propagation.
2.1 how to register a hook
Let's first look at how to register a hook, which involves AutogradMeta and Node.
2.1.1 AutogradMeta
AutoGradMeta: records the autograd history information of variables. The main member variables are.
- grad_ : Storing the gradient of the current Variable instance is also a Variable.
- grad_fn: it is a Node instance, only non leaf nodes. Through grad_fn() method. In fact, PyTorch is accessed through grad_ Whether FN is empty determines whether a Variable is a leaf variable.
- grad_accumulator_ : It is also an instance of Node. Only leaf nodes have.
- Grad through Variable_ Accessed by calculator().
- The leaf node is responsible for accumulating the gradient, grad_accumulator_ Is the gradient accumulation processing function.
- The corresponding gradient is saved in grad_ Variables.
- output_nr_: It's a number. output_nr_ Indicates the number of outputs of the Node. For example, 0 indicates that this Variable is the first output of the Node.
- Let's summarize:
- For non leaf nodes, grad_fn is a calculation gradient operation, and the gradient will not accumulate in grad_ Instead, it is passed to the next station of back propagation of the calculation diagram. grad_fn is a Node.
- For a leaf Node, PyTorch virtualizes a special calculation operation to output the leaf Node. At the same time, this virtual calculation operation is also used as the grad of the leaf Node_ accumulator_ To accumulate its gradient, and the gradient will accumulate in grad_ Therefore, the output of the leaf Node_ nr_ Must be 0. grad_accumulator_ It is also a Node, AccumulateGrad.
It is defined as follows:
struct TORCH_API AutogradMeta : public c10::AutogradMetaInterface {
std::string name_;
Variable grad_;
std::shared_ptr<Node> grad_fn_;
std::weak_ptr<Node> grad_accumulator_;
// This field is used to store all the forward AD gradients
// associated with this AutogradMeta (and the Tensor it corresponds to)
std::shared_ptr<ForwardGrad> fw_grad_;
std::vector<std::shared_ptr<FunctionPreHook>> hooks_;
std::shared_ptr<hooks_list> cpp_hooks_list_;
// Only meaningful on leaf variables (must be false otherwise)
bool requires_grad_;
// Only meaningful on non-leaf variables (must be false otherwise)
bool retains_grad_;
bool is_view_;
// The "output number" of this variable; e.g., if this variable
// was the second output of a function, then output_nr == 1.
// We use this to make sure we can setup the backwards trace
// correctly when this variable is passed to another function.
uint32_t output_nr_;
mutable std::mutex mutex_;
};
2.1.2 Node
In the calculation diagram, a calculation operation is represented by a Node, and different Node subclasses implement different operations.
Grad of AutogradMeta_ fn_ And grad_accumulator_ All nodes.
The main member variable targeted here is post_hooks_, This is the hook that will be executed after running the gradient calculation.
add_post_hook will post_hooks_ Add a hook to the.
struct TORCH_API Node : std::enable_shared_from_this<Node> {
public:
std::vector<std::unique_ptr<FunctionPreHook>> pre_hooks_;
std::vector<std::unique_ptr<FunctionPostHook>> post_hooks_;
uintptr_t add_post_hook(std::unique_ptr<FunctionPostHook>&& post_hook) {
post_hooks_.push_back(std::move(post_hook));
// Use the raw pointer as the unique key to identify this hook. This key
// can then be used in del_post_hook(key) to remove this hook.
return reinterpret_cast<std::uintptr_t>(post_hooks_.back().get());
}
}
2.1.3 AccumulateGrad
AccumulateGrad is a derived class of Node.
2.2 constructor
Let's review the Reducer constructor, which will:
- Each tensor gets the grad of its Variable::AutogradMeta_ accumulator_, That is, the gradient accumulator used to accumulate leaf variables.
- An autograd is configured for each gradient accumulator_ hook, which is hung on the autograd graph and is responsible for gradient synchronization during backward.
- Set gradAccToVariableMap_ Saved grad_ The corresponding relationship between calculator & Index (the corresponding relationship between function pointer and parameter tensor), so it is convenient to search for unused parameters in the autograd graph in the future.
- These gradient accumulators are stored in grad_accumulators_ in
The specific codes are as follows:
Reducer::Reducer(
std::vector<std::vector<at::Tensor>> replicas, // tensor
std::vector<std::vector<size_t>> bucket_indices, // Bucket information
......) {
for (size_t replica_index = 0; replica_index < replica_count; // Traverse replica
replica_index++) {
for (size_t variable_index = 0; variable_index < variable_count; // Ergodic tensor
variable_index++) {
auto& variable = replicas_[replica_index][variable_index]; //Get the specific tensor
const auto index = VariableIndex(replica_index, variable_index); //Each tensor has an index
// Get the grad of Variable::AutogradMeta_ accumulator_, That is, the gradient accumulator used to accumulate leaf variables
auto grad_accumulator = torch::autograd::impl::grad_accumulator(variable);
hooks_.emplace_back(
// Add a hook to the accumulator, which is hung on the autograd graph and is responsible for gradient synchronization during backward.
// grad_ After the calculator is executed, autograd_hook will run
grad_accumulator->add_post_hook(
torch::make_unique<torch::autograd::utils::LambdaPostHook>(
[=](const torch::autograd::variable_list& outputs,
const torch::autograd::variable_list& ) {
#ifndef _WIN32
this->rpc_context_.set(
ThreadLocalDistAutogradContext::getContextPtr());
#endif
this->autograd_hook(index); // Put the reducer's autograd_ Add the hook function
return outputs;
})),
grad_accumulator);
// gradAccToVariableMap_ Saved grad_ The corresponding relationship between calculator & Index (the corresponding relationship between function pointer and parameter tensor), so it is convenient to search for unused parameters in the autograd graph in the future
if (find_unused_parameters_) {
gradAccToVariableMap_[grad_accumulator.get()] = index;
}
grad_accumulators_[replica_index][variable_index] =
std::move(grad_accumulator);
}
}
}
}
2.2.1 grad_accumulator
Here, grad_ The calculator code is as follows. As you can see, it is the autograd to obtain the tensor_ meta->grad_accumulator_, Then return, for leaf nodes, grad_accumulator_ It's AccumulateGrad.
std::shared_ptr<Node> grad_accumulator(const Variable& self) {
auto autograd_meta = get_autograd_meta(self); // Get autograd_meta
if (!autograd_meta) {
return nullptr;
}
if (autograd_meta->grad_fn_) {
throw std::logic_error(
"grad_accumulator() should be only called on leaf Variables");
}
if (!autograd_meta->requires_grad_) {
return nullptr;
}
std::lock_guard<std::mutex> lock(autograd_meta->mutex_);
// Get autograd_ meta->grad_ accumulator_
auto result = autograd_meta->grad_accumulator_.lock();
if (result)
return result;
c10::raw::intrusive_ptr::incref(self.unsafeGetTensorImpl());
auto intrusive_from_this = c10::intrusive_ptr<at::TensorImpl>::reclaim(self.unsafeGetTensorImpl());
result = std::make_shared<AccumulateGrad>(Variable(std::move(intrusive_from_this)));
autograd_meta->grad_accumulator_ = result; // Get autograd_ meta->grad_ accumulator_
return result;
}
2.2.2 diagram
A tensor is variable1, and the VariableIndex corresponding to the tensor is index1. The specific configuration is as follows. AccumulateGrad will call post after calculating the gradient using apply_ Hooks in hook s.
+-----------------------------------------+
| Reducer |
| |
| |
| +------------------------------------+ | +------------------+ +----------------+
| | grad_accumulators_ | | | variable1 | | AccumulateGrad |
| | | | | | | |
| | | | | | | |
| | [replica_index][variable_index]+------> | autograd_meta_+---> | post_hooks |
| | | | | | | + |
| | | | | | | | |
| +------------------------------------+ | +------------------+ +----------------+
| | |
| +-------------------------------+ | |
| | gradAccToVariableMap_ | | v
| | | |
| | | | +-----------------------+
| | [variable1 : index1] | | | autograd_hook(index1)|
| | | | +-----------------------+
| +-------------------------------+ |
| |
+-----------------------------------------+
+---------------------------------------+
index1 +--> |VariableIndex |
| |
| replica_index of Variable1 |
| |
| variable_index of Variable1 |
| |
+---------------------------------------+
2.3 Hook function
When the gradient is ready, the engine will call back the hook function, which is the following autograd_hook method, which is to set whether the variable is ready according to relevant conditions. The logic is as follows:
-
If it is a dynamic graph & find the unused tensor or the first iteration of a static graph, set local_used_maps_ The corresponding position of the variable is set to 1.
- local_used_maps_ Record the CPU tensor used locally.
- The dynamic graph may be inconsistent every iteration, and the bucket and variable may be different every time, so local_used_maps_ It needs to be updated every iteration.
- The static graph is the same every iteration, as long as it is set in the callback at the first iteration.
-
If it is the first iteration of the static graph, numgradhooks triggeredmap_ The corresponding place of this variable becomes 1
-
If the unused variable is not marked, the unused variable is traversed. The unused variable is marked as ready and mark is called_ variable_ ready.
-
If it is a static graph & after the second iteration, if numgradhooks triggeredmappperitration_ If the corresponding decrement is 0, set the variable to ready and call mark_variable_ready.
-
Otherwise, it is a dynamic graph. The dynamic graph must set variable to ready every time and call mark_variable_ready.
// The function `autograd_hook` is called after the gradient for a
// model parameter has been accumulated into its gradient tensor.
// This function is only to be called from the autograd thread.
void Reducer::autograd_hook(VariableIndex index) {
std::lock_guard<std::mutex> lock(this->mutex_);
// Carry over thread local state from main thread. This allows for
// thread-local flags such as profiler enabled to be configure correctly.
at::ThreadLocalStateGuard g(thread_local_state_);
// Ignore if we don't expect to be called.
// This may be the case if the user wants to accumulate gradients
// for number of iterations before reducing them.
if (!expect_autograd_hooks_) {
return;
}
// Note [Skip allreducing local_used_maps_dev]
// ~~~~~~~~~~~~~~~~~~~~~~~~~~
// If find_unused_parameters_ is set to false, there is no need to allreduce
// local_used_maps_dev_, because all parameters will be reduced anyway.
// Therefore, we can avoid allocating memory for local_used_maps and
// local_used_maps_dev_ if find_unused_parameters_ is false.
// See Note [Skip allreducing local_used_maps_dev]
// Dynamic Graph & Find Unused tensor or first iteration of static graph
if (dynamic_graph_find_unused() || static_graph_first_iteration()) {
// Since it gets here, this param has been used for this iteration. We want
// to mark it in local_used_maps_. During no_sync session, the same var can
// be set multiple times, which is OK as does not affect correctness. As
// long as it is used once during no_sync session, it is marked as used.
// In no_ In the session of sync, as long as the parameter is used once, it will be marked as used
// local_used_maps_ Record the CPU tensor used locally
// The dynamic graph may be inconsistent every iteration, and the bucket and variable may be different every time, so local_used_maps_ Need to be updated every iteration
// The static graph is the same every iteration, as long as it is set in the callback at the first iteration
local_used_maps_[index.replica_index][index.variable_index] = 1;
}
if (static_graph_first_iteration()) { // First iteration of static graph
numGradHooksTriggeredMap_[index] += 1;// Only the first iteration of the static graph will increase by 1
return;
}
// If `find_unused_parameters_` is true there may be model parameters that
// went unused when computing the model output, they won't be part of the
// autograd graph, and won't receive gradients. These parameters are
// discovered in the `prepare_for_backward` function and their indexes stored
// in the `unused_parameters_` vector.
if (!has_marked_unused_parameters_) {
has_marked_unused_parameters_ = true;
for (const auto& unused_index : unused_parameters_) { // Traverse unused variable s
mark_variable_ready(unused_index); //Of course, unused ones are marked as ready
}
}
// If it is static graph, after 1st iteration, check a avariable
// is ready for communication based on numGradHooksTriggeredMap_.
if (static_graph_after_first_iteration()) {// After the second iteration, it is practical
// Why start with the second iteration? Because in the first iteration, the gradient is not ready when you enter here (that is, it has not been processed by Reducer, and it can be processed only after it has been processed by Reducer)
// When static graph, numgradhooks triggeredmappperitration_= numGradHooksTriggeredMap_;
if (--numGradHooksTriggeredMapPerIteration_[index] == 0) {
// Finally mark variable for which this function was originally called.
mark_variable_ready(index); // Changing from 1 to 0 is ready, so set variable to ready
}
} else {
// Finally mark variable for which this function was originally called.
mark_variable_ready(index);// The dynamic graph should set variable to ready every time
}
}
0x03 ready
If the variable is found to be ready in the hook of a parameter during the back propagation process, mark will be called_ variable_ Ready (index), let's continue to see how to deal with it.
The approximate sequence is: Processing ready variables, processing ready buckets, processing usage, and copying from DDP back to the corresponding gradient in autograd.
3.1 variable ready
3.1.1 setting ready
mark_variable_ready is to mark a variable as ready. The logic is as follows.
-
If the bucket needs to be rebuilt, insert the index into the list to be rebuilt.
- Rebuilding the bucket occurs in the following situations: 1) rebuilding the bucket for the first time. 2) When the static graph is true or finding unused parameters is false. 3) This reverse process requires allreduce to be run.
- Here, we only need to dump the tensor and its parameter index into the reconstruction parameters and reconstruction parameter index based on gradient arrival order, and then in finalize_ At the end of backward (), the bucket will be rebuilt based on the rebuild parameters and rebuild parameter index, and then broadcast and initialize the bucket. In addition, we only need to dump a copy of the tensor and parameter index.
-
Find the copy index corresponding to this variable and find the position of this variable in the copy.
-
This variable is used, recorded, and inserted into peritrationreadyparams_.
-
Whenever a variable is marked as ready, it is necessary to set and call finalize.
-
Check whether the gradients in the bucket are ready. If there is no pending, the bucket is ready
-
The number of pending copies of this model is reduced by 1 because another tensor is ready.
-
If the number of pending copies in this bucket is 0, the number of pending copies in this bucket will be reduced by 1.
- Because if the pending of this model copy is 0, the number of pending model copies corresponding to the bucket should be reduced by one.
- If the bucket pending is 0, mark is used_ bucket_ Ready sets the bucket ready.
-
If all buckets are ready:
- Call all_reduce_local_used_map.
- Call Engine::get_default_engine().queue_callback registers a callback. This callback will be called after engine completes all backward. The subsequent variable will be used to specify the variable, which calls finalize_. backward.
void Reducer::mark_variable_ready(VariableIndex index) {
// Rebuild bucket only if 1) it is the first time to rebuild bucket 2)
// static_graph_ is true or find_unused_parameters_ is false,
// 3) this backward pass needs to run allreduce.
// Here, we just dump tensors and their parameter indices into
// rebuilt_params_ and rebuilt_param_indices_ based on gradient arriving
// order, and then at the end of finalize_backward(), buckets will be
// rebuilt based on rebuilt_params_ and rebuilt_param_indices_, and then
// will be broadcasted and initialized. Also we only need to dump tensors
// and parameter indices of one replica.
if (should_rebuild_buckets()) {
push_rebuilt_params(index); // If you need to rebuild, insert the index into the list to be rebuilt
}
const auto replica_index = index.replica_index; // Replica index found
const auto variable_index = index.variable_index; // Find where in the replica
if (replica_index == 0) {
checkAndRaiseMarkedTwiceError(variable_index);
perIterationReadyParams_.insert(variable_index); // This variable is used and recorded
}
backward_stats_[replica_index][variable_index] =
current_time_in_nanos() - cpu_timer_.backward_compute_start_time;
// Any time we mark a variable ready (be it in line due to unused parameters,
// or via an autograd hook), we require a call to the finalize function. If
// this doesn't happen before the next iteration (or call to
// `prepare_for_backwards`), we know something is wrong.
require_finalize_ = true; // Whenever a variable is marked ready, you call finalize
const auto& bucket_index = variable_locators_[variable_index]; // Find the index information of variable
auto& bucket = buckets_[bucket_index.bucket_index]; // Find the bucket in which the variable is located
auto& replica = bucket.replicas[replica_index]; // Copy found
set_divide_factor();
if (bucket.expect_sparse_gradient) {
mark_variable_ready_sparse(index); // sparse variable
} else {
mark_variable_ready_dense(index); // dense variable
}
// TODO(@pietern): Make this work for both CPU/CUDA tensors.
// When using CPU tensors we don't need to do this.
// // Record event so that we can wait for all of them.
// auto& event = replica.events[bucket_index.intra_bucket_index];
// event.record();
// Check if this was the final gradient for this bucket.
// Check whether the gradients in the bucket are ready. If there is no pending, the bucket is ready
if (--replica.pending == 0) { // Subtract the pending number of copies of this model because another tensor is ready
// Kick off reduction if all replicas for this bucket are ready.
if (--bucket.pending == 0) {// If the pending of this model copy is 0, the number of pending model copies corresponding to the bucket should be reduced by one
mark_bucket_ready(bucket_index.bucket_index); // Then set the bucket ready
}
}
// Run finalizer function and kick off reduction for local_used_maps once the
// final bucket was marked ready.
if (next_bucket_ == buckets_.size()) { // If all barrels are ready
if (dynamic_graph_find_unused()) {
all_reduce_local_used_map(); // Specify the used variable s
}
// The autograd engine uses the default stream when running callbacks, so we
// pass in the current CUDA stream in case it is not the default.
const c10::Stream currentStream = get_current_stream();
// Finalize will be registered here_ Backward to engine
torch::autograd::Engine::get_default_engine().queue_callback([=] {
std::lock_guard<std::mutex> lock(this->mutex_);
// Run callback with the current stream
c10::OptionalStreamGuard currentStreamGuard{currentStream};
if (should_collect_runtime_stats()) {
record_backward_compute_end_time();
}
// Check that all buckets were completed and had their work kicked off.
TORCH_INTERNAL_ASSERT(next_bucket_ == buckets_.size());
this->finalize_backward();
});
}
}
The logic is as follows:
- Reduer will register autograd_hook to AccumulateGrad post_hooks.
- During the back propagation process, the Autograd Engine calls autograd if it finds a parameter ready_ hook.
- autograd_ Continue processing in hook.
- Will register a finalize_backward to engine.
Engine AccumulateGrad Reducer + + + | | | | | 1 | | | <-----------------------v | | | | | | | v 2 | post_hooks +--------> autograd_hook | + | | | | 3 | v | +------------------+---------------------------+ | | mark_variable_ready | | | | | | | | | All variable in replica are ready? | | | + | | | | YES | | | v | | | All replica in bucket are ready? | | | + | | | | YES | | | v | | | mark_bucket_ready | | | | | | | | | | | | + | | | | | | | | | | | v | | | All buckets are ready? | | | + | | | | YES | | | v | | queue_back 4 | all_reduce_local_used_map | | <----------------------------+ queue_callback(finalize_backward) | | | | | | | v +----------------------------------------------+
3.1.2 register callback
In the above code, torch:: autograd:: Engine:: get is used_ default_ engine().queue_ Callback to register a callback function. Let's analyze it.
There is a definition in engine, which is to go to final_callbacks_ Insert callback:
void Engine::queue_callback(std::function<void()> callback) {
std::lock_guard<std::mutex> lock(current_graph_task->final_callbacks_lock_);
current_graph_task->final_callbacks_.emplace_back(std::move(callback));
}
For final_callbacks_ Processing, in Exec_ post_ In processing, callback will be called when the engine completes backward.
void GraphTask::exec_post_processing() {
if (!not_ready_.empty()) {
throw std::runtime_error("could not compute gradients for some functions");
}
// set the thread_local current_graph_task_ as more callbacks can be installed
// by existing final callbacks.
GraphTaskGuard guard(shared_from_this());
// Lock mutex during each iteration for accessing final_callbacks.size()
// Unlocking is necessary, because the callback can register
// more callbacks (or they can be registered from other threads
// while it's waiting.
std::unique_lock<std::mutex> cb_lock(final_callbacks_lock_);
// WARNING: Don't use a range-for loop here because more callbacks may be
// added in between callback calls, so iterators may become invalidated.
// NOLINTNEXTLINE(modernize-loop-convert)
for (size_t i = 0; i < final_callbacks_.size(); ++i) {
cb_lock.unlock();
final_callbacks_[i](); // callback called
cb_lock.lock();
}
// Syncs leaf streams with default streams (if necessary)
// See note "Streaming backwards"
for (const auto& leaf_stream : leaf_streams) {
const auto guard = c10::impl::VirtualGuardImpl{c10::DeviceType::CUDA};
const auto default_stream = guard.getDefaultStream(leaf_stream.device());
if (leaf_stream != default_stream) {
auto event = c10::Event{c10::DeviceType::CUDA};
event.record(leaf_stream);
default_stream.wait(event);
}
}
}
Therefore, the logic is expanded as follows:
- Reduer will register autograd_hook to AccumulateGrad post_hooks.
- During the back propagation process, the Autograd Engine calls autograd if it finds a parameter ready_ hook.
- autograd_ Continue processing in hook.
- Will register a finalize_backward to engine.
- In graphtask:: Exec_ post_ Finalize will be called in processing_ backward.
Engine AccumulateGrad Reducer
+ + +
| | |
| | 1 |
| | <-----------------------+
| |
| |
| |
| v
| 2
| post_hooks +--------> autograd_hook
| +
| |
| | 3
| v
| +------------------+---------------------------+
| | mark_variable_ready |
| | |
| | |
| | All variable in replica are ready? |
| | + |
| | | YES |
| | v |
| | All replica in bucket are ready? |
| | + |
| | | YES |
| | v |
| | mark_bucket_ready |
| | |
| | |
| | |
| | + |
| | | |
| | | |
| | v |
| | All buckets are ready? |
| | + |
| | | YES |
| | v |
| queue_back 4 | all_reduce_local_used_map |
| <----------------------------+ queue_callback(finalize_backward) |
| | |
| | |
| +-------------------+--------------------------+
v |
|
GraphTask::exec_post_processing |
+ |
| |
| 5 v
+---------------------------------> finalize_backward
| +
| |
| |
v v
3.1.3 mark_variable_ready_sparse
mark_ variable_ ready_ The spark function is used to handle variables of spark type, which is actually copying gradients to Reducer.
void Reducer::mark_variable_ready_sparse(VariableIndex index) {
const auto replica_index = index.replica_index;
const auto variable_index = index.variable_index;
const auto& bucket_index = variable_locators_[variable_index];
auto& bucket = buckets_[bucket_index.bucket_index]; // Which bucket
auto& replica = bucket.replicas[replica_index]; // Which copy of the bucket
auto& variable = replica.variables[bucket_index.intra_bucket_index]; // Which variable in the copy
runGradCallbackForVariable(variable, [&](auto& grad) {
TORCH_CHECK(grad.defined(), "Expected sparse gradient to be defined.");
TORCH_CHECK(
grad.options().layout() == c10::kSparse,
"Expected variable to have sparse gradient.");
// Sparse tensors cannot be grouped together with other sparse tensors
// in a single reduction operation like we can for dense tensors.
// Therefore, the `offsets` and `lengths` vectors in the bucket replica
// struct are empty, and there is no pre-existing accumulation tensor.
// Directly assign the sparse tensor to the `contents` field.
replica.contents = grad; //direct copy
// See Note [DDP Communication Hook]
if (comm_hook_ == nullptr) {
replica.contents.div_(divFactor_);
}
// The grad is modified in place and needs to be written back.
return true;
});
}
3.1.4 mark_variable_ready_dense
mark_variable_ready_dense handles dense tensors, which is actually copying gradients to Reducer.
Let's first look at a member variable: gradient_as_bucket_view_, Its:
-
If false, after allreduce the bucket, you need to copy the bucket back to grads.
-
When set to True, the gradient will be a view pointing to different offsets of "allreduce". This reduces peak memory usage, where the saved memory size will be equal to the total size of the gradient. In addition, it avoids the overhead of replication between the gradient and the "all reduce" communication bucket. detach cannot be called on a gradient when the gradient is a view_ ().
mark_ variable_ ready_ The deny logic is:
- Find the bucket and copy to which the variable belongs according to the index, and then get the tensor variable in the copy, and then get the offset and size of the variable. Finally, the bucket corresponding to the tensor is obtained_ view.
- The tensor is processed using runGradCallbackForVariable. runGradCallbackForVariable actually uses DistAutogradContext to process callback, and finally returns DistAutogradContext.
- The internal execution logic of callback is:
- When gradient_as_bucket_view_ When it is false, or even gradient_as_bucket_view_ When true, in rare cases, the user can set grad to None after each iteration.
- In these cases, grad and bucket_view points to different storage, so you need to copy grad to bucket_view.
- If gradient_as_bucket_view_ Set to true to point grad to the bucket_view.
- If grad has been set to bucket in the previous iteration_ View, you do not need to copy.
void Reducer::mark_variable_ready_dense(VariableIndex index) {
const auto replica_index = index.replica_index;
const auto variable_index = index.variable_index;
const auto& bucket_index = variable_locators_[variable_index];
auto& bucket = buckets_[bucket_index.bucket_index]; // Which bucket
auto& replica = bucket.replicas[replica_index]; // Which copy of the bucket
auto& variable = replica.variables[bucket_index.intra_bucket_index]; // Get the variable in the copy
const auto offset = replica.offsets[bucket_index.intra_bucket_index]; // offset of variable
const auto length = replica.lengths[bucket_index.intra_bucket_index]; // size of variable
auto& bucket_view = replica.bucket_views_in[bucket_index.intra_bucket_index]; //Insert view
// Copy contents of gradient tensor to bucket tensor.
// If the gradient is not set, we assume it wasn't computed
// as part of the current backwards pass, and zero the part
// of the bucket it would otherwise hold.
runGradCallbackForVariable(variable, [&](auto& grad) {
// Get the gradient grad corresponding to the tensor
if (grad.defined()) {
this->check_grad_layout(grad, bucket_view);
// When gradient_as_bucket_view_ is false, or even when
// gradient_as_bucket_view_ is true, in rare cases users may set grad to
// be None after every iteration. In these cases, grad and bucket_view are
// pointing to different storages and thus need to copy grads to
// bucket_view. If gradient_as_bucket_view_ is set as true, let grad point
// to bucket_view. If grad has already been set as views of buckets in
// previous iterations, no copy is needed.
if (!grad.is_alias_of(bucket_view)) {
this->copy_grad_to_bucket(grad, bucket_view); // Copy the gradient into contents
if (gradient_as_bucket_view_) {
// Let grad point to bucket_view buffer.
grad = bucket_view; // To save memory, grad points to the bucket_view
// The grad is modified and need to be written back.
return true;
}
} else {
// If grad and bucket view point to the same storage, no need to copy
if (comm_hook_ == nullptr) {
bucket_view.div_(divFactor_);
}
}
} else {
bucket_view.zero_(); // Set to 0
}
// The grad is not modified and doesn't need to be written back.
return false;
});
}
copy_grad_to_bucket is used to copy gradients to contents
void Reducer::copy_grad_to_bucket(
const at::Tensor& grad,
at::Tensor& bucket_view) {
// See Note [DDP Communication Hook]
if (comm_hook_ == nullptr) {
auto wrapped = at::native::wrapped_scalar_tensor(double(1.) / divFactor_);
// Divides while copying into the bucket view.
at::mul_out(bucket_view, grad, wrapped);
} else {
bucket_view.copy_(grad); // Through bucket_view copies the gradient to the contents of the bucket copy
}
}
3.2 barrels ready
In the previous code, check whether the gradients in the bucket are all ready. If there is no pending, the bucket is also ready. At this time, call mark_bucket_ready.
mark_ bucket_ The ready bucket will be traversed and the ready bucket will be specified.
// Called when the bucket at the specified index is ready to be reduced.
void Reducer::mark_bucket_ready(size_t bucket_index) {
TORCH_INTERNAL_ASSERT(bucket_index >= next_bucket_);
// Buckets are reduced in sequence. Ignore this bucket if
// it's not its turn to be reduced.
if (bucket_index > next_bucket_) {
return;
}
// Keep going, until we either:
// - have kicked off reduction for all buckets, or
// - found a bucket that's not yet ready for reduction.
//
// Traverse the bucket until the following two conditions are encountered:
// -A protocol for all barrels has been launched
// -It was found that a bucket was not ready
for (; next_bucket_ < buckets_.size() && buckets_[next_bucket_].pending == 0;
next_bucket_++) {
num_buckets_ready_++; // increase
if (num_buckets_ready_ == 1 && should_collect_runtime_stats()) {
record_backward_comm_start_time();
}
auto& bucket = buckets_[next_bucket_];
all_reduce_bucket(bucket); // For the ready bucket, perform the protocol
}
}
3.2.1 all_reduce_bucket
all_reduce_bucket synchronizes the contents.
- Traverse the copy of the bucket and insert the copy tensor into tensors.
- If comm is not registered_ Hook, directly allreduce these tensors.
- Registered comm_hook, then use hook for allreduce. Note that this comm_hook is only the bottom hook for communication. If you want to perform gradient clipping before reduce, you still need to hang hook in autograph.
void Reducer::all_reduce_bucket(Bucket& bucket) {
std::vector<at::Tensor> tensors;
tensors.reserve(bucket.replicas.size());
for (const auto& replica : bucket.replicas) {
// TODO(@pietern): Ensure proper synchronization with the CUDA events
// that recorded copies into this contents tensor. If these copies are
// executed on non-default streams, the current stream for the device
// that holds the contents tensor must wait on these events.
//
// As long as autograd uses the default stream for every device,
// these operations are implicitly sequenced, and we don't need to
// do any extra synchronization here.
//
// CUDA default stream s are all arranged in order
tensors.push_back(replica.contents);
}
// See Note [DDP Communication Hook]
if (comm_hook_ == nullptr) {
// If comm is not registered_ Hook, direct allreduce
bucket.work = process_group_->allreduce(tensors);
} else {
// Registered comm_hook then use hook for allreduce
// It should be noted that this comm_hook is only the bottom hook for communication. If you want to perform gradient clipping before reduce, you still need to hang hook in autograph
GradBucket grad_bucket(
next_bucket_,
tensors[0], // As you can see from the notes below, a bucket has only one replica
// Since currently we do not support single-process multiple-device
// mode, we can assume only one replica in the bucket.
bucket.replicas[0].offsets,
bucket.replicas[0].lengths,
bucket.replicas[0].sizes_vec);
bucket.future_work = comm_hook_->runHook(grad_bucket);
}
}
The logical expansion is as follows:
- Reduer will register autograd_hook to AccumulateGrad post_hooks.
- During the back propagation process, the Autograd Engine calls autograd if it finds a parameter ready_ hook.
- autograd_ Continue processing in hook.
- Call all_reduce_bucket to synchronize gradients.
- Will register a finalize_backward to engine.
- In graphtask:: Exec_ post_ Finalize will be called in processing_ backward.
+
Worker 1 | Worker 2
|
Engine AccumulateGrad Reducer | Reducer
|
+ + + | +
| | | | |
| | 1 | | |
| | <-----------------------+ | |
| | | |
| | | |
| v | |
| 2 | |
| post_hooks +--------> autograd_hook | |
| + | |
| | | |
| | 3 | |
| v | |
| +------------------+---------------------------+ | |
| | mark_variable_ready | | |
| | | | |
| | | | |
| | All variable in replica are ready? | | |
| | + | | |
| | | YES | | |
| | v | | |
| | All replica in bucket are ready? | | |
| | + + + |
| | | YES |
| | v 4 all_reduce_bucket |
| | mark_bucket_ready <--------------+---+-----> |
| | | | |
| | | | |
| | | | |
| | + | | |
| | | | | |
| | | | | |
| | v | | |
| | All buckets are ready? | | |
| | + | | |
| | | YES | | |
| | v | | |
| queue_back 5 | all_reduce_local_used_map | | |
| <------------------------+ queue_callback(finalize_backward) | | |
| | | | |
| | | | |
| +-------------------+--------------------------+ | |
v | | |
| | |
GraphTask::exec_post_processing | | |
+ | | |
| | | |
| v | |
+-----------------------------> finalize_backward | |
| 6 + | |
| | | |
| | | |
v v + v
3.2.2 PythonCommHook
Python commhook is used to realize the special needs of users. We mentioned earlier. Here are two more examples.
Python commhook example
c10::intrusive_ptr<c10::ivalue::Future> PythonCommHook::runHook(
GradBucket& bucket) {
py::gil_scoped_acquire acquire;
py::object py_fut = hook_(state_, bucket);
try {
return py_fut.cast<std::shared_ptr<torch::jit::PythonFutureWrapper>>()->fut;
} catch (const py::cast_error& e) {
auto type = py_fut.get_type();
auto errMsg = c10::str(
e.what(),
". DDP communication hook's callback must return a "
"torch.futures.Future or torch._C.Future object, but got ",
type.attr("__module__").cast<std::string>(),
".",
type.attr("__qualname__").cast<std::string>());
throw std::runtime_error(errMsg);
}
}
perhaps
c10::intrusive_ptr<c10::ivalue::Future> AllReduceCommHook::runHook(
GradBucket& bucket) {
std::vector<at::Tensor> tensors = {bucket.getTensorRef()};
auto allreduce_work = state_->allreduce(tensors);
// FIXME Access the result through the Future passed as argument, instead of
// capturing the Work.
auto div_by_process_group_size = [allreduce_work,
this](c10::ivalue::Future& /* unused */) {
auto tensor = allreduce_work->result()[0] / state_->getSize();
return c10::IValue(tensor);
};
auto fut = allreduce_work->getFuture();
return fut->then(div_by_process_group_size, fut->elementType());
}
3.2.3 GradBucket
GradBucket is a class used to copy information.
// This class passes bucket contents tensor to DDP communication hook.
class GradBucket {
public:
explicit GradBucket(
size_t index,
const at::Tensor& tensor,
const std::vector<size_t>& offsets,
const std::vector<size_t>& lengths,
const std::vector<c10::IntArrayRef>& sizes_vec)
: index_(index),
tensor_(tensor),
offsets_(offsets),
lengths_(lengths),
sizes_vec_(sizes_vec) {}
// Returns the index of the bucket, which is unique across all the buckets.
size_t getIndex() const {
return index_;
}
const at::Tensor& getTensor() const {
return tensor_;
}
// Returns a mutable tensor compared with the above method.
at::Tensor& getTensorRef() {
return tensor_;
}
// Overwrites tensors at a specific index.
void setTensor(at::Tensor& tensor) {
tensor_ = tensor;
}
// Each tensor in the list that getPerParameterTensors corresponds to a
// parameter.
std::vector<at::Tensor> getPerParameterTensors() const;
// Returns whther this bucket is the last bucket to allreduce in an iteration.
bool isTheLastBucketToAllreduce() const {
return index_ == 0;
}
private:
size_t index_;
at::Tensor tensor_;
// Per-variable info in tensors_[0].
std::vector<size_t> offsets_;
std::vector<size_t> lengths_;
std::vector<c10::IntArrayRef> sizes_vec_;
};
3.3 all_reduce_local_used_map
Note that here is the local for tensor usage_ used_ maps_ Variables, not tensor gradients.
3.3.1 definitions
Let's recall the definition.
The following two variables are used to record locally used parameters, which are marked when synchronization is not enabled (no_sync is on), in the current iteration or no_ Whether these parameters have been used locally in the sync session.
Each copy of the model corresponds to a tensor in the map, and each tensor is a one-dimensional int32 (one-dim int32) tensor of the number of parameters.
These tensors are in autograd_ Tag in the hook to indicate that the corresponding parameter has been used. These tensors will be allreduce at the end of the current iteration or the backward propagation of no_sync session to calculate the global unused parameters.
// Locally used parameter maps indicating if parameters are used locally // during the current iteration or no_sync session if no_sync is on. One // tensor for each model replica and each tensor is one-dim int32 tensor of // number of parameters. These tensors are marked in autograd_hook to indicate // the corresponding param has been used, and get allreduced in the end of // backward of current iteration or no_sync session for figuring out the // globally unused parameters. // // local_used_maps_: CPU tensors for bookkeeping locally used params // local_used_maps_dev_: dev tensors for reducing globally unused params std::vector<at::Tensor> local_used_maps_; // autograd_ It will be set in hook, corresponding to those in the paper std::vector<at::Tensor> local_used_maps_dev_; // GPU
3.3.2 synchronization
all_reduce_local_used_map uses asynchronous H2D here to avoid blocking overhead. local_used_maps_ Copy to local_used_maps_dev_, Then local_used_maps_dev_ Make regulations.
void Reducer::all_reduce_local_used_map() {
// See Note [Skip allreducing local_used_maps_dev]
// H2D from local_used_maps_ to local_used_maps_dev_
for (size_t i = 0; i < local_used_maps_.size(); i++) {
if (local_used_maps_dev_[i].is_cuda()) {
// Note [local_used_maps_ -> local_used_maps_dev copying]
// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// We do async H2D to avoid the blocking overhead. The async copy and
// allreduce respect the current stream, so will be sequenced
// correctly.
//
// Correct sequencing with respect to host operations is also
// essential. The H2D copy_ is stream ordered, while the host's
// changes to local_used_maps_ are host ordered. If a large backlog of
// cuda-stream work pushes the copy_ far into the future, and if no
// blocking calls occur between now and finalize_backward()** such
// that finalize_backward() re-zeroes local_used_maps_ on the host
// before the stream executes the copy_, copy_ will read those zeros
// instead of the values we thought we told it to read here. Copying
// local_used_maps_[i] to a pinned temporary (which the pinned caching
// allocator should supply asynchronously) avoids this nasty, rare
// race condition.
//
// ** In the hoped-for case where all params are used, DDP itself
// won't do any blocking work between now and the re-zeroing, so the
// danger is real.
//
// Defensively ensures local_used_maps_tmp is distinct from
// local_used_maps_[i]
auto local_used_maps_tmp = at::native::empty_like(
local_used_maps_[i],
optTypeMetaToScalarType(local_used_maps_[i].options().dtype_opt()),
local_used_maps_[i].options().layout_opt(),
local_used_maps_[i].options().device_opt(),
true /* pinned_memory */);
// Paranoid asserts here because in some workloads, the pinned
// allocator behaves in a way we don't understand, and may be bugged.
// See https://github.com/pytorch/pytorch/pull/54474
TORCH_INTERNAL_ASSERT(local_used_maps_tmp.is_pinned());
TORCH_INTERNAL_ASSERT(
local_used_maps_tmp.data_ptr() != local_used_maps_[i].data_ptr());
local_used_maps_tmp.copy_(local_used_maps_[i]);
local_used_maps_dev_[i].copy_(local_used_maps_tmp, true);
} else {
local_used_maps_dev_[i].copy_(local_used_maps_[i], true);
}
}
local_used_work_ = process_group_->allreduce(local_used_maps_dev_);
}
Expand as follows:
- Reduer will register autograd_hook to AccumulateGrad post_hooks.
- During the back propagation process, the Autograd Engine calls autograd if it finds a parameter ready_ hook.
- autograd_ Continue processing in hook.
- Call all_reduce_bucket to synchronize gradients.
- Call allreduce to local_used_maps_ Variables.
- Will register a finalize_backward to engine.
- In graphtask:: Exec_ post_ Finalize will be called in processing_ backward.
+
Worker 1 | Worker 2
|
Engine AccumulateGrad Reducer | Reducer
|
+ + + | +
| | | | |
| | 1 | | |
| | <-----------------------+ | |
| | | |
| | | |
| | | |
| | | |
| v | |
| 2 | |
| post_hooks +--------> autograd_hook | |
| + | |
| | | |
| | 3 | |
| v | |
| +------------------+---------------------------+ | |
| | mark_variable_ready | | |
| | | | |
| | | | |
| | All variable in replica are ready? | | |
| | + | | |
| | | YES | | |
| | v | | |
| | All replica in bucket are ready? | | |
| | + + + |
| | | YES 4 all_reduce_bucket |
| | v |
| | mark_bucket_ready <--------------+---+-----> |
| | | | |
| | | | |
| | | | |
| | + | | |
| | | | | |
| | | | | |
| | v | | |
| | All buckets are ready? | | |
| | + | | |
| | | YES + + |
| | v 5 allreduce |
| 6 queue_back | all_reduce_local_used_map <--------+---+-----> |
| <------------------------+ queue_callback(finalize_backward) | | |
| | | | |
| | | | |
| +-------------------+--------------------------+ | |
v | | |
| | |
GraphTask::exec_post_processing | | |
+ | | |
| | | |
| v | |
+-----------------------------> finalize_backward | |
| 7 + | |
| | | |
| | | |
v v + v
3.4 finalize_backward
finalize_backward has completed the closing work. The logic is:
- Traverse buckets, for each bucket:
- Wait for the synchronization tensor to complete.
- Copy back contents from future results.
- Wait for local_used_maps_dev synchronization completed.
void Reducer::finalize_backward() {
// No longer expect autograd hooks to fire after this function returns.
expect_autograd_hooks_ = false;
// No longer require call to finalize after this function returns.
require_finalize_ = false;
// Unset allreduce division factor, as it may change in next backwards pass
// when running with DDP join mode.
divFactor_ = kUnsetDivFactor;
// Wait for asynchronous reduction to complete and unflatten contents.
for (auto& bucket : buckets_) { // Traversal bucket
// See Note [DDP Communication Hook]
if (comm_hook_ == nullptr) {
bucket.work->wait(); // Wait for synchronization to complete
} else {
bucket.future_work->wait(); // Wait for synchronization to complete
auto future_result =
comm_hook_->parseHookResult(bucket.future_work->value());
for (size_t i = 0; i < future_result.size(); i++) { //
auto& replica = bucket.replicas[i];
if (bucket.expect_sparse_gradient) {
replica.contents.copy_(future_result[i]); // Copy back contents from future results
} else {
// Reinitialize only `bucket_views_out` with the future_result by
// following the same logic in `initialize_buckets`.
// Put the future_result[i] resolve to bucket_views_out
populate_bucket_views_out(replica, future_result[i]);
}
}
}
if (!bucket.expect_sparse_gradient) {
// We don't need to finalize the sparse bucket since the sparse grad and
// the bucket essentially point to the same storage. As a result, once
// the allreduce is done, the sparse grads are automatically updated.
finalize_bucket_dense(bucket); //
}
}
// See Note [Skip allreducing local_used_maps_dev]
if (dynamic_graph_find_unused() || static_graph_first_iteration()) {
// Due to the lazy wait, it is possible that reduction of the current
// iteration is still going when the one for next iteration gets kicked off.
// For such case, we want to wait explicitly to make sure the reduction does
// complete before kicking off next one. Otherwise the previous one may
// interfere, write to the device-side memory and clobber the content of
// local_unused_maps_dev_.
if (!local_used_maps_reduced_) {
local_used_work_->wait(); // Wait for local_used_maps_dev sync complete
}
}
if (dynamic_graph_find_unused()) {
// Reset unused parameter accounting.
// See Note [local_used_maps_ -> local_used_maps_dev copying]
for (auto& local_used : local_used_maps_) {
local_used.fill_(0);
}
local_used_maps_reduced_ = false;
}
if (should_collect_runtime_stats()) {
record_backward_comm_end_time();
}
}
This process uses the following functions.
4.6.1 populate_bucket_views_out
populate_bucket_views_out build output view from contents
// (see Note: "Gradient Layout Contract" in initialize_buckets).
void Reducer::populate_bucket_views_out(
Reducer::BucketReplica& replica,
at::Tensor& tensor) { // Parse tensor to bucket_views_out
replica.bucket_views_out.clear(); // empty
for (size_t i = 0; i < replica.variables.size(); i++) { // Reinitialize the bucket_views_out
const auto& v = replica.variables[i]; // Ergodic tensor
const auto offset = replica.offsets[i];
const auto length = replica.lengths[i];
if (v.is_non_overlapping_and_dense()) {
// If the param's memory is dense, match its layout, anticipating
// the autograd engine (AccumulateGrad) will also create gradients
// matching its layout.
replica.bucket_views_out.push_back( // Parse tensor to bucket_views_out
tensor.as_strided(v.sizes(), v.strides(), offset));
} else {
// Fall back to a C-style contiguous view, again anticipating
// AccumulateGrad will do the same when stashing grads for non-dense
// params.
replica.bucket_views_out.push_back( // Parse tensor to bucket_views_out
tensor.narrow(0, offset, length).view(v.sizes()));
}
}
}
4.6.1 finalize_bucket_dense
finalize_ bucket_ The function of deny is to call runGradCallbackForVariable or copy_bucket_to_grad copies the specified gradient to the engine.
// A bucket with one or more dense tensors needs to be unflattened.
void Reducer::finalize_bucket_dense(Bucket& bucket) {
for (size_t replica_index = 0; replica_index < bucket.replicas.size();
replica_index++) {
auto& replica = bucket.replicas[replica_index];
for (size_t intra_bucket_index = 0;
intra_bucket_index < replica.variables.size();
intra_bucket_index++) {
auto& variable = replica.variables[intra_bucket_index];
const auto offset = replica.offsets[intra_bucket_index];
const auto length = replica.lengths[intra_bucket_index];
bool global_unused = false;
// See Note [Skip allreducing local_used_maps_dev]
if (static_graph_ || find_unused_parameters_) {
// Determine if this param has been used globally or not.
//
// If the variable was used locally, it is also used globally and then
// we don't need to wait for the reduction. Otherwise we lazily wait for
// the reduction to complete, only when we see a variable that was
// unused locally. Then we end up delaying the synchronization point
// that local_used_work_->wait() implies. If we don't have any unused
// parameters at all, we can skip waiting for the work to complete
// altogether, and cause negligible performance overhead for models
// where all parameters are used. Such lazily waiting means minimizing
// performance impact for the big majority of models where all
// parameters are always used. Then we only pay the overhead cost if
// there is indeed a parameter that is locally unused, because we need
// to check if it's also globally unused.
size_t variable_index = bucket.variable_indices[intra_bucket_index];
// Note: global_unused might not be global yet. As we lazily wait for
// the reduction to complete, it becomes really global only if we get to
// the point as below where we wait for the reduction work, make D2H
// copy, and update global_unused with the real global consensus, i.e.
// local_used_maps_reduced_ is true.
global_unused =
local_used_maps_[replica_index][variable_index].item<int>() == 0;
if (global_unused && !local_used_maps_reduced_) {
// Wait for local_used_maps reduction to complete.
local_used_work_->wait();
// D2H from local_used_maps_dev_ to local_used_maps_
for (size_t i = 0; i < local_used_maps_.size(); i++) {
// Blocking copy, if local_used_maps_dev_ is cuda
local_used_maps_[i].copy_(local_used_maps_dev_[i]);
}
global_unused =
local_used_maps_[replica_index][variable_index].item<int>() == 0;
local_used_maps_reduced_ = true;
}
}
if (!gradient_as_bucket_view_) {
copy_bucket_to_grad( // Copy back to dist.context
variable, replica, intra_bucket_index, global_unused);
} else {
const auto& bucket_view_out =
replica.bucket_views_out[intra_bucket_index];
auto& bucket_view_in = replica.bucket_views_in[intra_bucket_index];
// If communication_hook is registered, bucket_view_out stores
// allreduced results in a newly allocated tensor, copy bucket_view_out
// back to bucket_view_in that referring to replica.content tensor and
// grad.
if (!bucket_view_in.is_alias_of(bucket_view_out)) {
bucket_view_in.copy_(bucket_view_out); // Copy from out back to in view
}
runGradCallbackForVariable(variable, [&](auto& grad) {
// If a parameter is globally unused, we keep its grad untouched.
if (!global_unused) {
// If grad is globally used but locally unused, let grad point to
// bucket_view_in
if (!grad.defined()) {
grad = bucket_view_in;
} else {
if (!grad.is_alias_of(bucket_view_in)) {
TORCH_CHECK(
false,
"Detected at least one parameter gradient is not the "
"expected DDP bucket view with gradient_as_bucket_view=True. "
"This may happen (for example) if multiple allreduce hooks "
"were registered onto the same parameter. If you hit this error, "
"please file an issue with a minimal repro.");
}
}
// The grad is modified and needs to be written back.
return true;
}
// The grad is not modified.
return false;
});
}
}
}
}
4.6.3 copy_bucket_to_grad
Here is the corresponding gradient copied from the bucket back to the autograd engine.
void Reducer::copy_bucket_to_grad(
at::Tensor& variable,
Reducer::BucketReplica& replica,
size_t intra_bucket_index,
bool global_unused) {
const auto& bucket_view = replica.bucket_views_out[intra_bucket_index]; // Get the output view
runGradCallbackForVariable(variable, [&](auto& grad) {
// If a parameter is globally unused, we keep its grad untouched.
if (!global_unused) {
if (!grad.defined()) {
// Creates grad according to the "Gradient Layout Contract"
// (see torch/csrc/grad/AccumulateGrad.h)
grad =
torch::autograd::utils::clone_obey_contract(bucket_view, variable);
} else {
grad.copy_(bucket_view); // Copy back from bucket
}
// The grad is modified and needs to be written back.
return true;
}
// The grad is not modified.
return false;
});
}
So far, we have expanded as follows:
- Reduer will register autograd_hook to AccumulateGrad post_hooks.
- During the back propagation process, the Autograd Engine calls autograd if it finds a parameter ready_ hook.
- autograd_ Continue processing in hook.
- Call all_reduce_bucket to synchronize gradients.
- Call allreduce to local_used_maps_ Variables.
- Will register a finalize_backward to engine.
- In graphtask:: Exec_ post_ Finalize will be called in processing_ backward.
- Call wait to synchronize with other worker s.
- Call copy_bucket_to_grad copies the gradient from the bucket back to the autograd engine.
Therefore, we know how the autograd engine interacts with DDP in the back propagation process, and how to use DDP merging gradient while doing back calculation.
+
Worker 1 | Worker 2
|
Engine AccumulateGrad Reducer | Reducer
|
+ + + | +
| | | | |
| | 1 | | |
| | <----------------------+ | |
| | | |
| | | |
| v | |
| 2 | |
| post_hooks +--------> autograd_hook | |
| + | |
| | | |
| | 3 | |
| v | |
| +------------------+---------------------------+ | |
| | mark_variable_ready | | |
| | | | |
| | | | |
| | All variable in replica are ready? | | |
| | + | | |
| | | YES | | |
| | v | | |
| | All replica in bucket are ready? | | |
| | + + + |
| | | YES 4 all_reduce_bucket |
| | v |
| | mark_bucket_ready <--------------+---+-----> |
| | | | |
| | | | |
| | | | |
| | + | | |
| | | | | |
| | | | | |
| | v | | |
| | All buckets are ready? | | |
| | + | | |
| | | YES + + |
| | v 5 allreduce |
| 6 queue_back | all_reduce_local_used_map <--------+---+-----> |
| <------------------------+ queue_callback(finalize_backward) | | |
| | | | |
| | | | |
| +-------------------+--------------------------+ | |
v | | |
| | |
GraphTask::exec_post_processing | | |
+ | | |
| | | |
| 7 v | |
+-----------------------------> finalize_backward | |
| + 8 wait | |
| | <---------------------------------> |
| <-------------------------------------+ | | |
v copy_bucket_to_grad 9 v + v
So far, the back propagation analysis is completed, and all the analysis of DDP is also completed. Next, we will analyze the distributed autograd.
0xFF reference
BAGUA: Scaling up Distributed Learning with System Relaxations
How does pytorch distributed series 2 - distributed data parallel synchronize?
https://discuss.pytorch.org/t/dataparallel-imbalanced-memory-usage/22551/20
https://pytorch.org/docs/stable/distributed.html
PyTorch source code interpretation of distributed training to understand?
Practical tutorial | PyTorch AutoGrad C + + layer implementation
PYTORCH automatic differentiation (I)
How does PyTorch accelerate data parallel training? Uncover the secrets of distributed Secrets
pytorch distributed training (II init_process_group)
https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
https://pytorch.org/docs/master/notes/ddp.html
https://pytorch.org/tutorials/intermediate/dist_tuto.html
Interpretation of PyTorch source code DP & DDP: model parallel and distributed training analysis