Hello, I'm brother Manon Feige. Thank you for reading this article. Welcome to one click three times.
😁 1. Take a stroll around the community. There are benefits and surprises every week. Manon Feige community, leap plan
💪🏻 2. Python basic column, you can catch all the basic knowledge. Python from introduction to mastery
❤️ 3. Ceph has everything from principle to actual combat. Ceph actual combat
❤️ 4. Introduction to Java high concurrency programming, punch in and learn java high concurrency. Introduction to Java high concurrency programming
It's full of dry goods. It's recommended to collect it. You need to use it often. If you have any questions and needs, you are welcome to leave a message ~.
Why did you write this article? [complete code required] click here ]
I watched the number of fans of other bloggers rise, and the community of other bloggers prosper. To be honest, I'm really anxious, too anxious. What should I do?
There are too many posts. What if you don't have time to review them one by one? What if you don't have time to refine excellent posts? What if the community posts are chaotic? Can you only go to the management background one by one?
After thinking hard, I think we should use the program to automatically help us deal with these problems, use the program to automatically help us refine good articles, remove meaningless irrigation posts, and sort out the grouping of posts. This starts the following article.
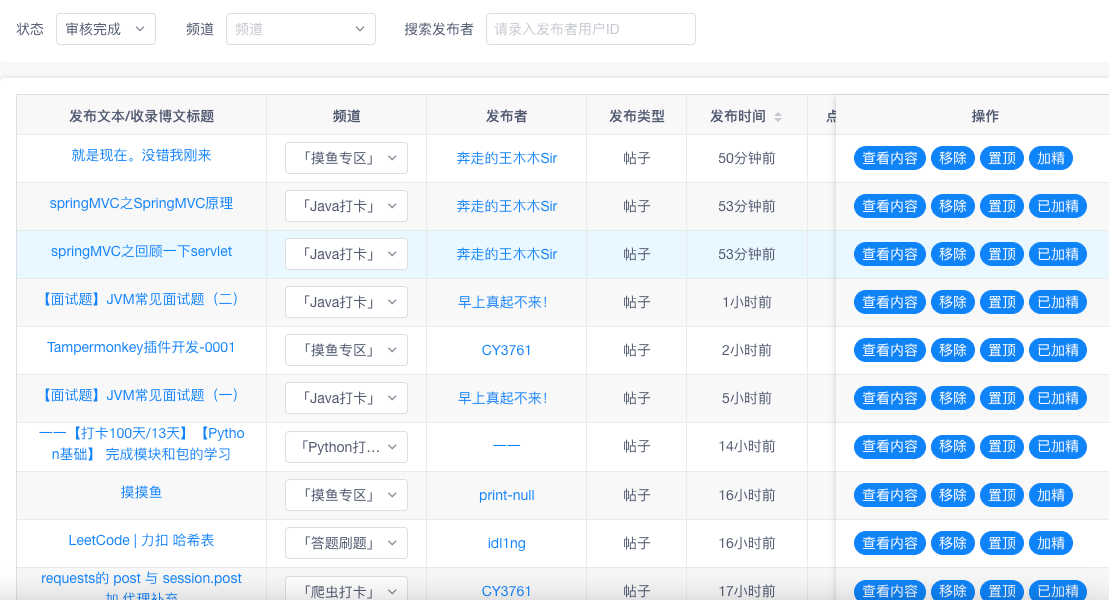
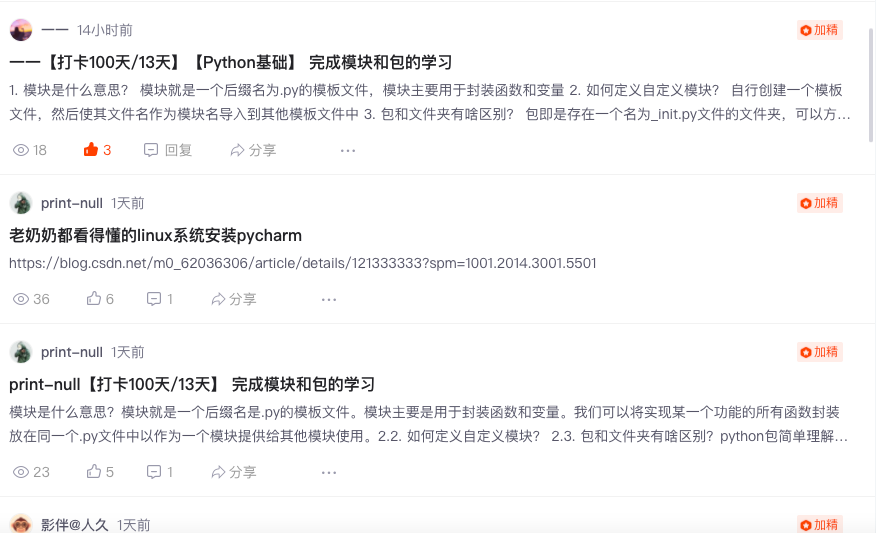
Let's see the effect first
The function of this gadget is to perform tasks regularly every day, which will meet certain preset requirements, refine excellent articles and remove unqualified irrigation articles. This can greatly reduce the cost of manual audit and let the administrator focus on more meaningful things.
How do you use it?
First, download the source code and click https://docs.qq.com/doc/DUFJ0REhIRHFJdHlL

Install dependent Libraries
After downloading the source code, install the following dependency Libraries
pip install lxml pip install requests pip install urllib3
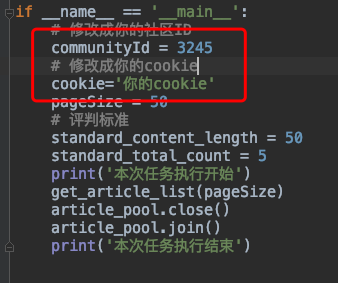
Modify community ID and cookie
if __name__ == '__main__':
# Change to your community ID
communityId = 3245
# Change to your cookie
cookie='Yours cookie'
pageSize = 50
# Evaluation criteria
standard_content_length = 50
standard_total_count = 5
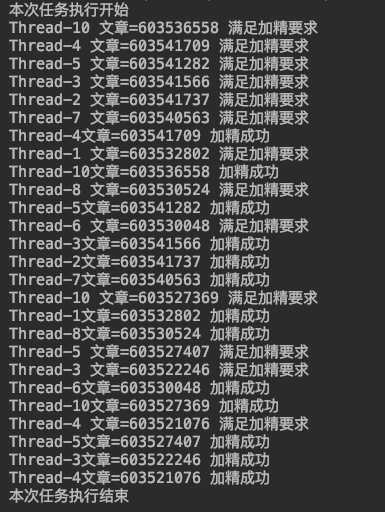
print('The execution of this task begins')
get_article_list(pageSize)
article_pool.close()
article_pool.join()
print('End of this task')
Code description, here:
communityId: refers to your current community ID,
Cookie: the cookie you are currently requesting,
pageSize: the number of entries per page indicates the amount of data queried at a time. The default is 50 entries. If the amount of data is large, it can be increased.
standard_content_length: indicates the length of the article content. By default, the article content must be at least 50 characters
standard_total_count: indicates the total number of praise points and comments. By default, it is no less than 5.
How?
How to realize it? In essence, the interface of CSDN related functions is automatically called through the program instead of manual call. The following is an example of code Nong Feige community.
Step 1: find relevant interfaces
First, from Manon Feige community home page Click the manage community button to enter the community management background, and then click the content tab page - content management. F12 to see the relevant interfaces called. The relevant interfaces are shown in Figure 1 below.
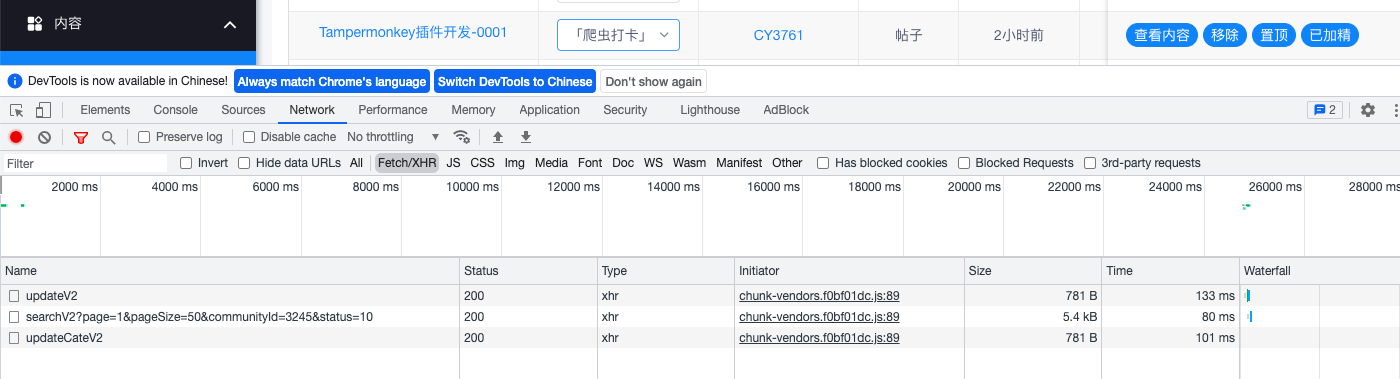
Figure 1 shows several important interfaces involved in content management, including:
- The updateV2 interface is used for topping and polishing operations
- The searchV2 interface is used to query the content list
- The updateCateV2 interface is used to move articles to different channels.
Step 2: call related interfaces
After determining the relevant interfaces to be called, the next step is to call each interface. First, let's look at the direct call interface. Here, take the simplest content list query interface as an example, because it is an interface for Get requests. You can enter and access it directly in the browser. https://bizapi.csdn.net/community-cloud/v1/admin/api/content/searchV2?page=1&pageSize=50&communityId=3245&status=10 , the access results are shown in Figure 2 below.
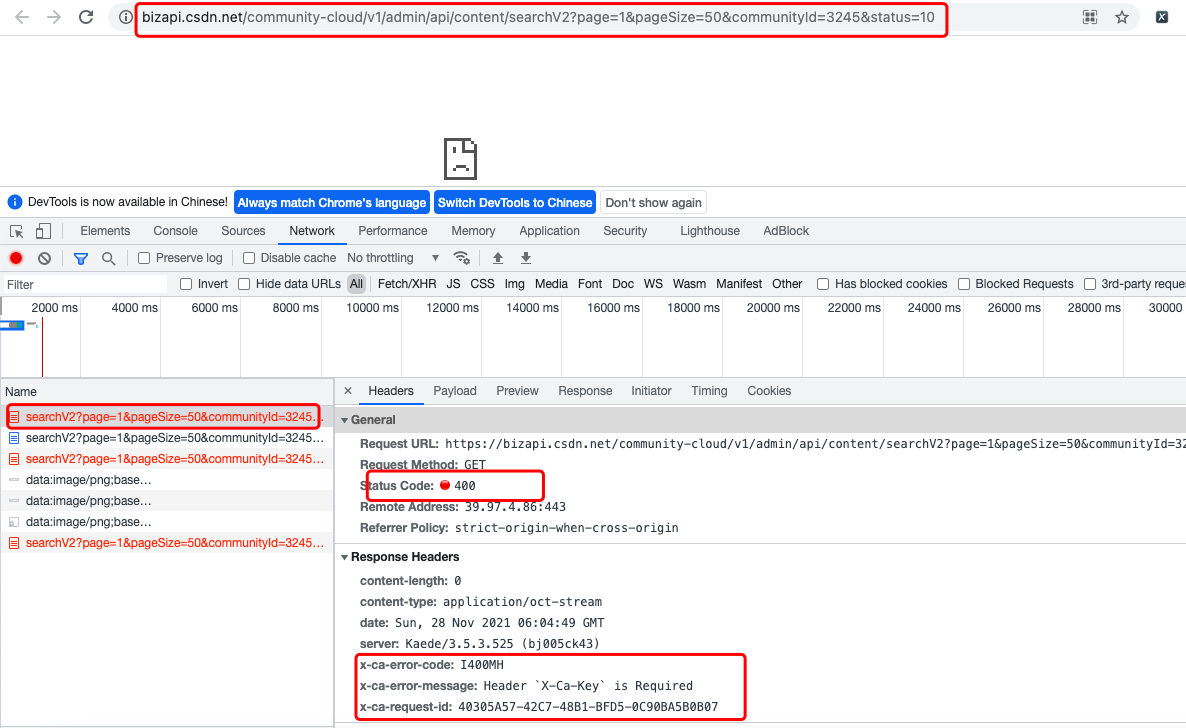
Unfortunately, a 400 error was reported when accessing the interface directly on the browser. F12 looked at it and found that the x-ca-key attribute was missing in the request header.
Further analysis, what is x-ca-key
Go back to the content management page we opened earlier to see what their x-ca-key attribute is, as shown in Figure 3 and Figure 4 below.
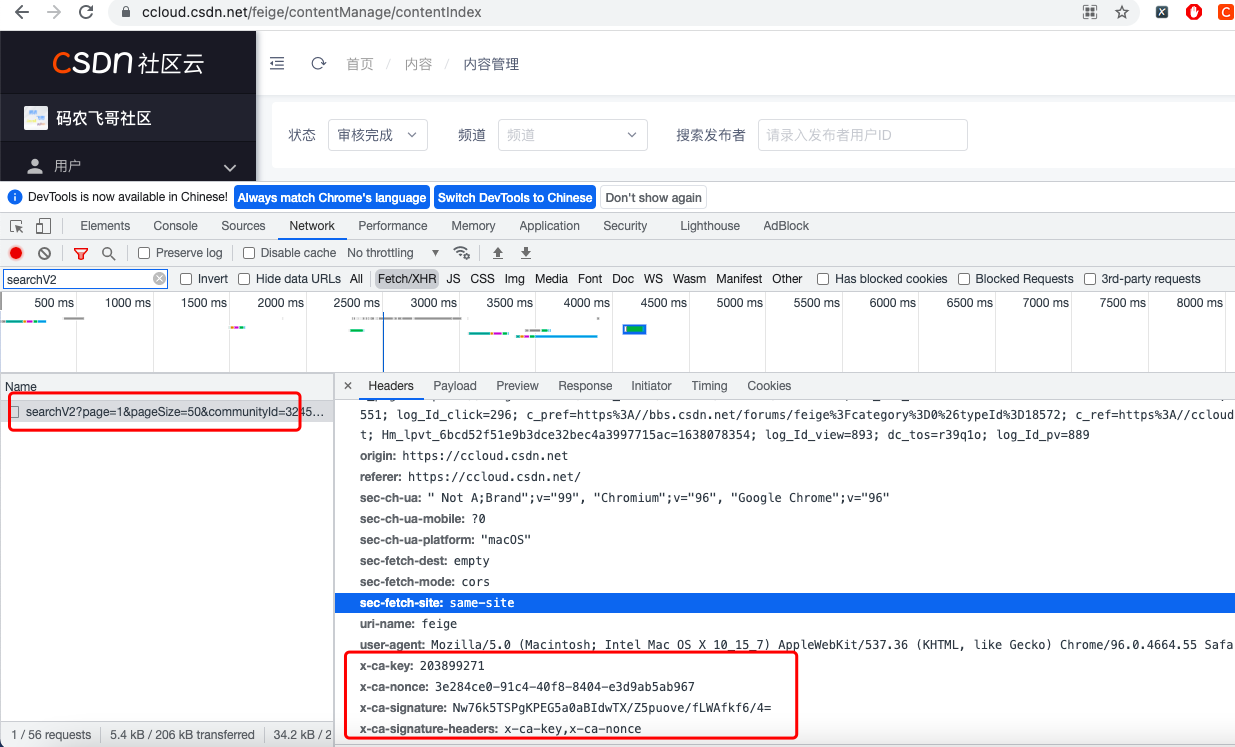
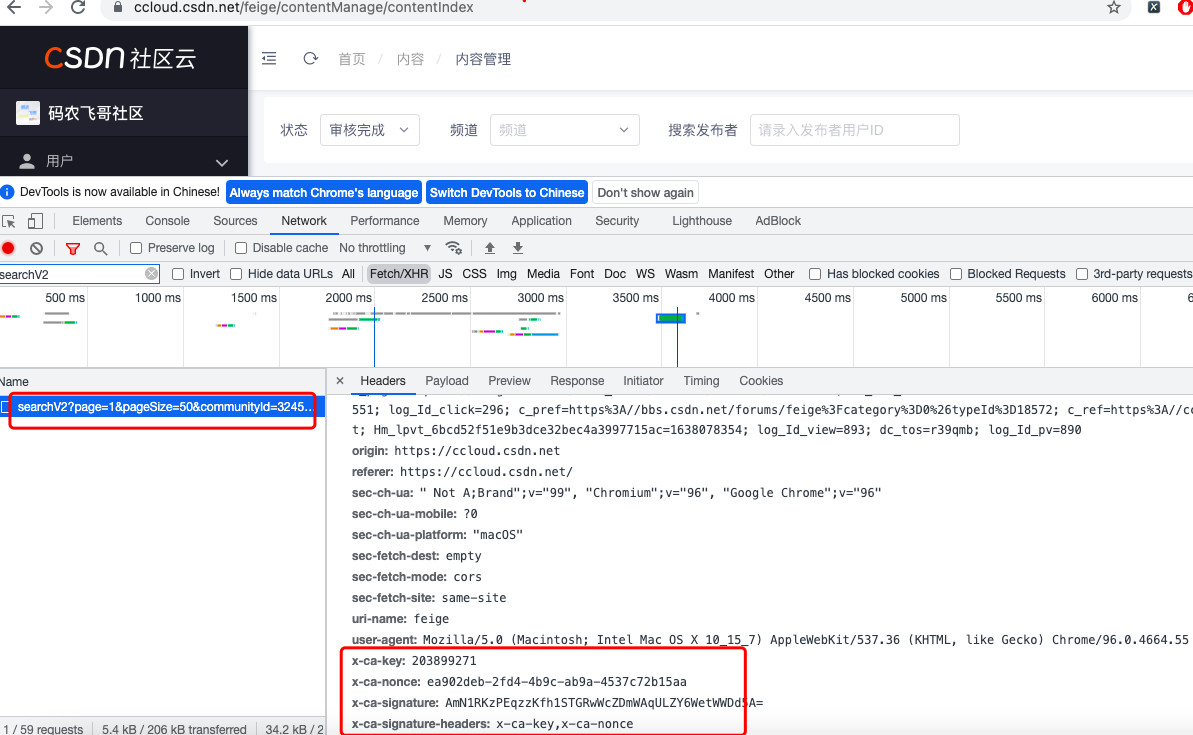
From figures 3 and 4, it is not difficult to see that the four parameters x-ca-key, x-ca-nonce, x-ca-signature and x-ca-signature headers are passed into the request header every time the interface is requested. Through simple analysis, it is not difficult to find that x-ca-key and x-ca-signature headers are two fixed values. However, x-ca-signature and x-ca-signature headers are different every time the interface is requested, which is a little difficult Top.
How do you know the generation mechanism of x-ca-signature and x-ca-signature headers?
Debugging the generation mechanism of x-ca-signature and x-ca-signature-headers is really a painful memory. It's a little difficult. Click each js file in source - > js to find the match. By default, the js files here are compressed, as shown in Figure 5 below, which is very inconvenient to find. Here, you need to click the pretty print button to beautify the output.
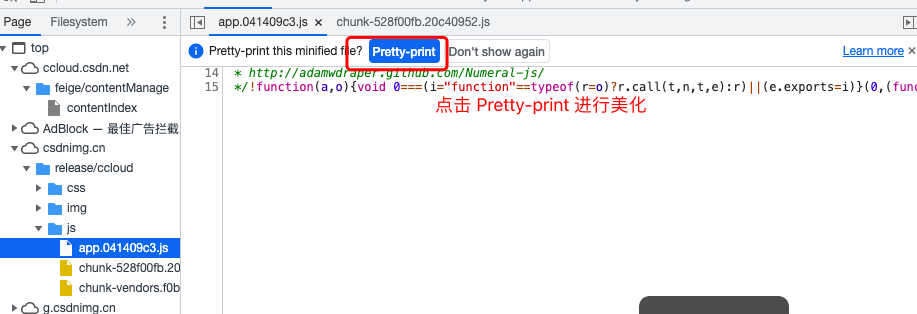
The beautified result is shown in Figure 6 below. Fortunately, the generated code of x-ca-signature is found in app.041409c3.js file through variable name matching.
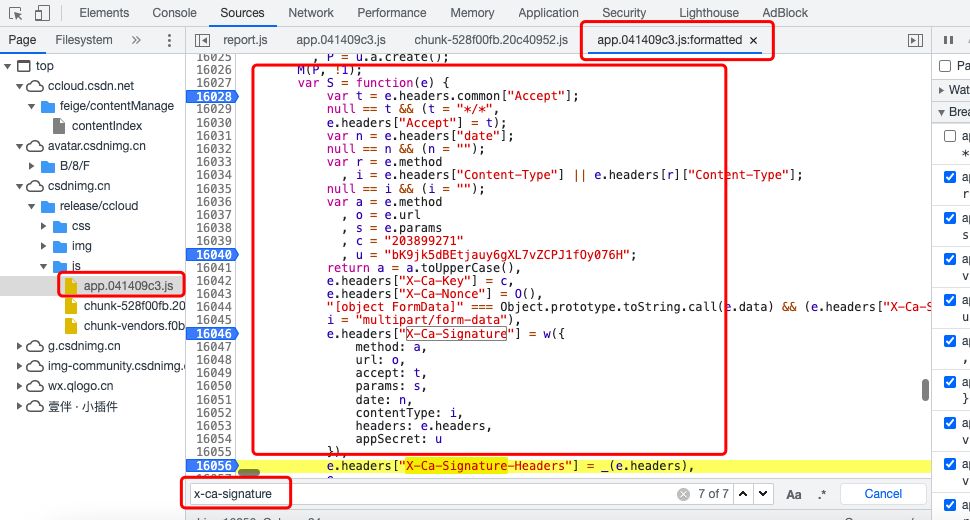
The code of x-ca-nonce is shown in Figure 7 below:

The next step is a painful js debugging. Some screenshots of debugging are shown in Figure 8 below:
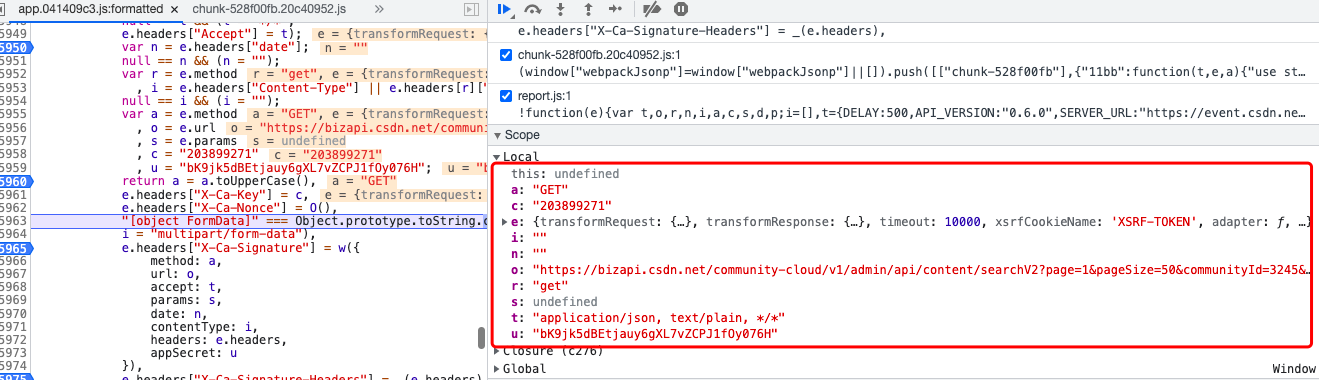
Go directly to the code:
1. The code for generating x-ca-nonce is as follows:
#x-ca-nonce
def createUuid():
text = ""
char_list = []
for c in range(97, 97 + 6):
char_list.append(chr(c))
for c in range(49, 58):
char_list.append(chr(c))
for i in "xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx":
if i == "4":
text += "4"
elif i == "-":
text += "-"
else:
text += random.choice(char_list)
return text
2. The generated x-ca-signature code is as follows:
def get_sign(uuid, url, method):
s = urlparse(url)
ekey = "bK9jk5dBEtjauy6gXL7vZCPJ1fOy076H".encode()
if method == 'get':
to_enc = f"GET\n{accept}\n\n\n\nx-ca-key:{xcakey}\nx-ca-nonce:{uuid}\n{s.path+'?'+s.query}".encode()
else:
to_enc = f"POST\n{accept}\n\n{content_type}\n\nx-ca-key:{xcakey}\nx-ca-nonce:{uuid}\n{s.path}".encode()
sign = b64encode(hmac.new(ekey, to_enc, digestmod=hashlib.sha256).digest()).decode()
return sign
It should be noted here that when generating x-ca-signature, POST requests and GET requests are different, and we need to process them differently. The two most obvious differences are the different request methods and content_type s.
Step 3: implement the logic we want
The most critical step is done, and the next step is to implement the logic we want. First, call the interface to get the post list, and the result is:

Special attention should be paid here: the request header must not be mistaken.
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'origin': 'https://ccloud.csdn.net',
'referer': 'https://ccloud.csdn.net/',
'sec-ch-ua': '"Google Chrome";v="96", "Chromium";v="96", ";Not A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'uri-name': 'feige',
'cookie': Change it to yours cookie
}
CSDN is very strict in checking the request header. Here, the relevant parameters of the request header are indispensable. Be sure to remember.
Here is the code for calling the searchV2 interface.
search_list_url = 'https://bizapi.csdn.net/community-cloud/v1/admin/api/content/searchV2'
def get_article_list(pageSize):
if pageSize is None:
pageSize = 50
param = {
'communityId': communityId,
'page': 1,
'pageSize': pageSize,
'status': 10
}
new_search_list_url = search_list_url + '?' + parse.urlencode(param)
get_ca_sign(new_search_list_url, headers, 'get')
resp = requests.get(new_search_list_url, headers=headers, verify=False)
# Query all articles
if resp.status_code == 200:
resp_dict = resp.json()
print(resp_dict)
Finally
This gadget is not difficult in essence. It is to call the interface of CSDN. The difficulty is that the two parameters x-ca-nonce and x-ca-signature in the request header are difficult to handle. The call logic behind these two parameters is relatively simple.
Exclusive benefits for fans
Soft test materials: Practical soft test materials
Interview questions: 5G Java high frequency interview questions
Learning materials: 50G various learning materials
Withdrawal secret script: reply to [withdrawal]
Concurrent programming: reply to [concurrent programming]
👇🏻 The verification code can be obtained by searching the official account below.👇🏻