Original title: Spring certified China Education Management Center - Spring Data Redis framework tutorial II
10.11.Redis stream
Redis Streams models the log data structure in an abstract way. Typically, a log is an additional data structure that is used at random from the beginning or by streaming new messages.
Learn more about Redis Streams in the Redis reference documentation.
Redis Streams can be roughly divided into two functional areas:
- Append record
- Records of consumption
Although this pattern is similar to Pub/Sub, the main difference lies in the persistence of messages and their consumption mode.
Although Pub/Sub relies on the broadcast of transient messages (that is, if you don't listen, you will miss a message), Redis Stream uses a persistent, attachment only data type that retains messages until the stream is trimmed. Another difference in consumption is that Pub/Sub registers server-side subscriptions. Redis pushes the incoming messages to the client, and Redis Streams needs active polling.
stay The org.springframework.data.redis.connection and org.springframework.data.redis.stream packages provide core functions for Redis data flow.
10.11.1. Additional
To send records, you can use low-level RedisConnection or high-level StreamOperations like other operations. Both entities provide the add (xadd) method, which accepts records and target flows as parameters. Although RedisConnection requires original data (byte array), StreamOperations allows any object to be passed in as a record, as shown in the following example:
// append message through connection
RedisConnection con = ...
byte[] stream = ...
ByteRecord record = StreamRecords.rawBytes(...).withStreamKey(stream);
con.xAdd(record);
// append message through RedisTemplate
RedisTemplate template = ...
StringRecord record = StreamRecords.string(...).withStreamKey("my-stream");
template.streamOps().add(record);Stream records carry a Map, key tuple, as their payload. Attaching a record to a stream returns a RecordId that can be used for further reference.
10.11.2. Consumption
In terms of consumption, a person can consume one or more streams. Redis Streams provides read commands that allow streams to be consumed from any location (random access) inside the known stream content and outside the stream end to consume new stream records.
At the bottom layer, RedisConnection provides xRead and xReadGroup methods, which map the Redis commands read and read in the consumer group respectively. Note that multiple flows can be used as parameters.
Subscription commands in Redis may be blocked. That is, calling the xRead connection will cause the current thread to block when it starts waiting for a message. The thread is released only when the read command times out or a message is received.
To use streaming messages, you can poll for messages in your application code or use one of two types of asynchronous reception through the message listener container, either imperative or reactive. The container notifies the application code every time a new record arrives.
Synchronous reception
Although stream consumption is usually associated with asynchronous processing, it is also possible to consume messages synchronously. Overloading the StreamOperations.read(...) method provides this functionality. During synchronous reception, the calling thread may block until the message is available. This property StreamReadOptions.block specifies how long the recipient should wait before giving up waiting for a message.
// Read message through RedisTemplate
RedisTemplate template = ...
List<MapRecord<K, HK, HV>> messages = template.streamOps().read(StreamReadOptions.empty().count(2),
StreamOffset.latest("my-stream"));
List<MapRecord<K, HK, HV>> messages = template.streamOps().read(Consumer.from("my-group", "my-consumer"),
StreamReadOptions.empty().count(2),
StreamOffset.create("my-stream", ReadOffset.lastConsumed()))Receive asynchronously through the message listener container
Due to its blocking nature, low-level polling is not attractive because it requires connection and thread management for each consumer. To alleviate this problem, Spring Data provides a message listener, which can do all the heavy work. If you are familiar with EJB and JMS, you should find these concepts familiar because it is designed to be as close as possible to the support in the Spring Framework and its message driven POJO (MDP).
Spring Data comes with two implementations tailored to the programming model used:
- The StreamMessageListenerContainer acts as a message listener container for the imperative programming model. It is used to use the records in Redis Stream and drive the StreamListener to inject instances into it.
- StreamReceiver provides a reactive variant of the message listener. It is used to use the message from Redis Stream as a potential infinite stream through Flux
The StreamMessageListenerContainer is responsible for receiving and dispatching messages to all threads in the listener for processing. The message listener container / receiver is the intermediary between the MDP and the message provider. It is responsible for registering and receiving messages, obtaining and releasing resources, exception conversion, etc. This allows you, as an application developer, to write (possibly complex) business logic related to receiving messages (and responding to them), and delegate the template Redis infrastructure issues to the framework.
Both containers allow runtime configuration changes so that you can add or remove subscriptions while the application is running without restarting. In addition, the container uses the lazy subscription method, and RedisConnection is used only when needed. If all listeners are unsubscribed, it automatically performs cleanup and frees the thread.
Critical StreamMessageListenerContainer
In a manner similar to message driven beans (MDBs) in the EJB world, flow driven POJOs (SDPs) act as receivers for flow messages. One limitation of SDP is that it must be implemented org.springframework.data.redis.stream.StreamListener interface. Also note that when your POJO receives messages on multiple threads, it is important to ensure that your implementation is thread safe.
class ExampleStreamListener implements StreamListener<String, MapRecord<String, String, String>> {
@Override
public void onMessage(MapRecord<String, String, String> message) {
System.out.println("MessageId: " + message.getId());
System.out.println("Stream: " + message.getStream());
System.out.println("Body: " + message.getValue());
}
}StreamListener represents a functional interface, so you can rewrite the implementation in their Lambda form:
message -> {
System.out.println("MessageId: " + message.getId());
System.out.println("Stream: " + message.getStream());
System.out.println("Body: " + message.getValue());
};Once you implement your StreamListener, you can create a message listener container and register a subscription:
RedisConnectionFactory connectionFactory = ...
StreamListener<String, MapRecord<String, String, String>> streamListener = ...
StreamMessageListenerContainerOptions<String, MapRecord<String, String, String>> containerOptions = StreamMessageListenerContainerOptions
.builder().pollTimeout(Duration.ofMillis(100)).build();
StreamMessageListenerContainer<String, MapRecord<String, String, String>> container = StreamMessageListenerContainer.create(connectionFactory,
containerOptions);
Subscription subscription = container.receive(StreamOffset.fromStart("my-stream"), streamListener);See the Javadoc for the various message listener containers for a complete description of the functionality supported by each implementation.
Reactive StreamReceiver
Reactive consumption of streaming data sources usually occurs through a series of Flux events or messages. The reactive receiver implementation provides the StreamReceiver and its overloaded receive(...) message. And The StreamMessageListenerContainer uses fewer infrastructure resources, such as threads, than the thread resources provided by the driver. The receiving stream is a requirement driven publisher StreamMessage:
Flux<MapRecord<String, String, String>> messages = ...
return messages.doOnNext(it -> {
System.out.println("MessageId: " + message.getId());
System.out.println("Stream: " + message.getStream());
System.out.println("Body: " + message.getValue());
});Now we need to create a StreamReceiver and register a subscription to consume stream messages:
ReactiveRedisConnectionFactory connectionFactory = ...
StreamReceiverOptions<String, MapRecord<String, String, String>> options = StreamReceiverOptions.builder().pollTimeout(Duration.ofMillis(100))
.build();
StreamReceiver<String, MapRecord<String, String, String>> receiver = StreamReceiver.create(connectionFactory, options);
Flux<MapRecord<String, String, String>> messages = receiver.receive(StreamOffset.fromStart("my-stream"));See the Javadoc for the various message listener containers for a complete description of the functionality supported by each implementation.
Demand driven consumption uses back pressure signals to activate and deactivate polling. StreamReceiver if the demand is met, the subscription will pause polling until the subscriber sends a further demand signal. Depending on the ReadOffset policy, this may cause messages to be skipped.
Knowledge policy
When you read a message through a, the Consumer Group, the server remembers that the given message has been delivered and adds it to the pending item list (PEL). List of messages sent but not yet confirmed. The message must be acknowledged StreamOperations.acknowledge can be deleted from the list of pending entries, as shown in the following fragment.
StreamMessageListenerContainer<String, MapRecord<String, String, String>> container = ...
container.receive(Consumer.from("my-group", "my-consumer"),
StreamOffset.create("my-stream", ReadOffset.lastConsumed()),
msg -> {
// ...
redisTemplate.opsForStream().acknowledge("my-group", msg);
});Read from my group as my consumer. The received message is not acknowledged.
Post processing confirmation message.
To automatically acknowledge messages when received, use receiveAutoAck instead of receive
ReadOffset policy
The stream read operation accepts the read offset specification to consume the message from a given offset. ReadOffset indicates the read offset specification. Redis supports three offset variants, depending on whether you use streams independently or in a consumer group:
- ReadOffset.latest() – read the latest news.
- ReadOffset.from(...) – read after a specific message ID.
- ReadOffset.lastConsumed() – read after the last consumed message ID (consumer group only).
In the consumption context based on message container, we need to read the offset in advance (or increase) when consuming messages. Advance depends on the request ReadOffset and consumption pattern (with / without consumer groups). The following matrix explains how the container advances ReadOffset:
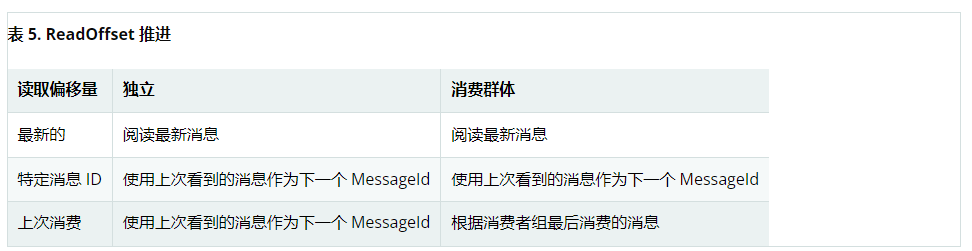
Reading from a specific message ID and the last consumed message can be considered a secure operation to ensure that all messages attached to the stream are consumed. Reading with the latest message can skip messages added to the stream when the polling operation is in the dead time state. Polling introduces a dead time in which messages can arrive between polling commands. Stream consumption is not a linear continuous read, but is split into repeated XREAD calls.
serialize
Any record sent to the stream needs to be serialized into its binary format. Due to the proximity between the stream and the hash data structure, the stream key, field name and value are used in RedisTemplate
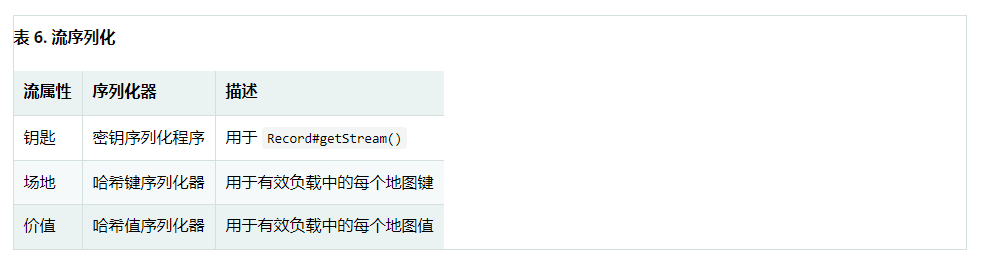
Be sure to check RedisSerializers in use and note that if you decide not to use any serializers, you need to ensure that these values are already binary.
Object mapping
Simple value
StreamOperations allows you to attach simple values ObjectRecord directly to the stream without putting these values into the Map structure. The value is then assigned to the payload field and can be extracted when the value is read back.
ObjectRecord<String, String> record = StreamRecords.newRecord()
.in("my-stream")
.ofObject("my-value");
redisTemplate()
.opsForStream()
.add(record);
List<ObjectRecord<String, String>> records = redisTemplate()
.opsForStream()
.read(String.class, StreamOffset.fromStart("my-stream"));XADD my-stream * "_class" "java.lang.String" "_raw" "my-value"
ObjectRecords goes through exactly the same serialization process as all other records, so you can also use the typeless read operation that returns a to get the Record MapRecord.
Complex value
There are three ways to add complex values to a flow:
- Use, for example, to convert to a simple value. A string JSON representation.
- Use the appropriate RedisSerializer
- Map uses a to convert values to HashMapper values suitable for serialization.
The first variant is the most direct variant, but ignores the field value function provided by the flow structure, and the values in the flow can still be read by other consumers. The second option has the same benefits as the first option, but can lead to very specific consumer restrictions because all consumers must implement exactly the same serialization mechanism. The HashMapper method uses a slightly more complex steam hash structure, but flattens the source. As long as the appropriate serializer combination is selected, other consumers can still read records.
HashMappers converts the payload into a Map with a specific type of A. Make sure to use a hash key and hash value serializer that can (de -) serialize hashes.
ObjectRecord<String, User> record = StreamRecords.newRecord()
.in("user-logon")
.ofObject(new User("night", "angel"));
redisTemplate()
.opsForStream()
.add(record);
List<ObjectRecord<String, User>> records = redisTemplate()
.opsForStream()
.read(User.class, StreamOffset.fromStart("user-logon"));XADD user login * "_class" "com.example.User" "firstname" "night" "lastname" "angel"
StreamOperations uses ObjectHashMapper by default. You can use HashMapper to provide a stream operations that suits your requirements when retrieving.
redisTemplate()
.opsForStream(new Jackson2HashMapper(true))
.add(record); XADD user login * "firstname" "night" "@class" "com.example.User" "lastname" "angel"

AStreamMessageListenerContainer may not know anything used on the @ TypeAlias domain type, because those need to use MappingContext. Ensure that RedisMappingContext uses initialEntitySet
@Bean
RedisMappingContext redisMappingContext() {
RedisMappingContext ctx = new RedisMappingContext();
ctx.setInitialEntitySet(Collections.singleton(Person.class));
return ctx;
}
@Bean
RedisConverter redisConverter(RedisMappingContext mappingContext) {
return new MappingRedisConverter(mappingContext);
}
@Bean
ObjectHashMapper hashMapper(RedisConverter converter) {
return new ObjectHashMapper(converter);
}
@Bean
StreamMessageListenerContainer streamMessageListenerContainer(RedisConnectionFactory connectionFactory, ObjectHashMapper hashMapper) {
StreamMessageListenerContainerOptions<String, ObjectRecord<String, Object>> options = StreamMessageListenerContainerOptions.builder()
.objectMapper(hashMapper)
.build();
return StreamMessageListenerContainer.create(connectionFactory, options);
}
10.12.Redis transaction
Redis supports transactions through multi, exec and discard commands. These operations are available on RedisTemplate. However, RedisTemplate cannot guarantee that all operations in a transaction can be run in the same connection.
Spring Data Redis provides a SessionCallback interface for use when multiple connection s need to be performed on the same, for example, when Redis transactions are used. The following example uses this multi method:
//execute a transaction
List<Object> txResults = redisTemplate.execute(new SessionCallback<List<Object>>() {
public List<Object> execute(RedisOperations operations) throws DataAccessException {
operations.multi();
operations.opsForSet().add("key", "value1");
// This will contain the results of all operations in the transaction
return operations.exec();
}
});
System.out.println("Number of items added to set: " + txResults.get(0));RedisTemplate uses its value, hash key, and hash value serializer exec to deserialize all results before returning. There is also an exec method that allows you to pass custom serializers for transaction results.
Since version 1.1, exec has made important changes to the RedisConnection and RedisTemplate methods. Previously, these methods returned the results of the transaction directly from the connector. This means that the data type is usually different from the data type returned from the method RedisConnection. For example, zAdd returns a boolean indicating whether an element has been added to the sort set. Most connectors return this value as long, and Spring Data Redis performs the conversion. Another common difference is that most connectors are OK, such as set. These replies are usually discarded by Spring Data Redis. Before 1.1, exec. Was not. In addition, the results did not deserialize RedisTemplate, so they usually contain the original byte array. If this change destroys your application, set convertPipelineAndTxResults is false. You RedisConnectionFactory to disable this behavior.
10.12.1. @ transaction support
By default, RedisTemplate does not participate in managed Spring transactions. If you want RedisTemplate to use Redis transaction TransactionTemplate when using @ Transactional or, you need to explicitly enable transaction support for each RedisTemplate by setting it setEnableTransactionSupport(true). Enable the transaction and support binding RedisConnection to ThreadLocal. If the transaction is completed and there are no errors, the redis transaction will use commit EXEC, otherwise use rollback DISCARD. Redis transactions are batch oriented. Commands issued during an ongoing transaction are queued and applied only when the transaction is committed.
Spring Data Redis distinguishes between read-only and write commands in ongoing transactions. Read only commands, such as KEYS, are piped to a new (non thread bound) RedisConnection to allow reading. The write command is submitted by RedisTemplate, queued and applied at the time of submission.
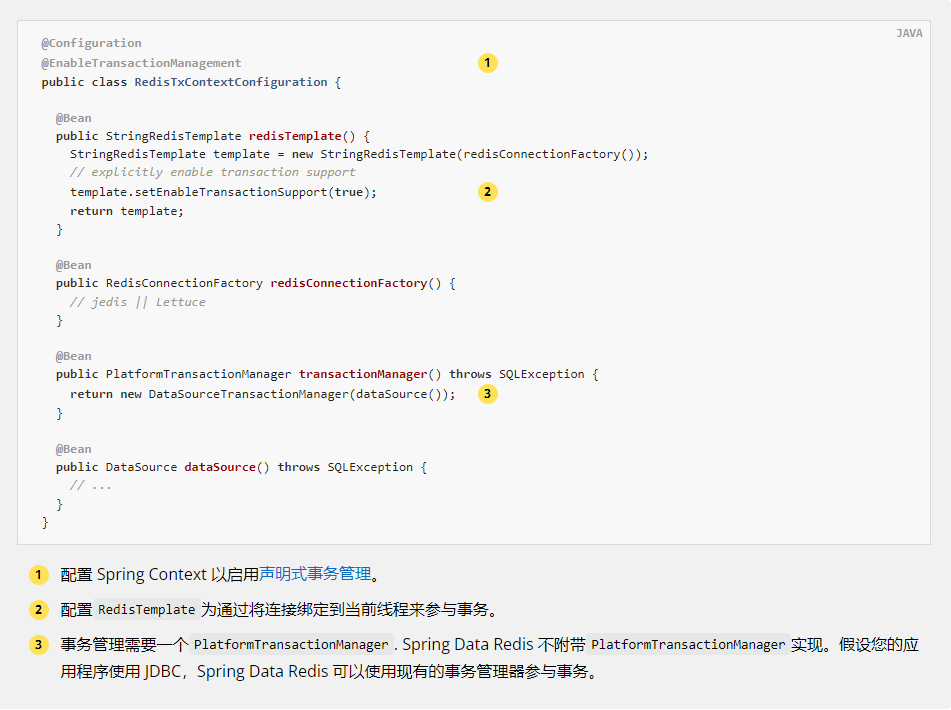
The following example shows how to configure transaction management:
Example 3. Configuration with transaction management enabled
@Configuration
@EnableTransactionManagement
public class RedisTxContextConfiguration {
@Bean
public StringRedisTemplate redisTemplate() {
StringRedisTemplate template = new StringRedisTemplate(redisConnectionFactory());
// explicitly enable transaction support
template.setEnableTransactionSupport(true);
return template;
}
@Bean
public RedisConnectionFactory redisConnectionFactory() {
// jedis || Lettuce
}
@Bean
public PlatformTransactionManager transactionManager() throws SQLException {
return new DataSourceTransactionManager(dataSource());
}
@Bean
public DataSource dataSource() throws SQLException {
// ...
}
}Configure Spring Context to enable declarative transaction management.
RedisTemplate is configured to participate in transactions by binding the connection to the current thread.
Transaction management requires a PlatformTransactionManager. Spring Data Redis does not come with the PlatformTransactionManager implementation. Assuming that your application uses JDBC, Spring Data Redis can use the existing transaction manager to participate in transactions.
The following examples demonstrate usage limitations:
Example 4. Use restrictions
// must be performed on thread-bound connection
template.opsForValue().set("thing1", "thing2");
// read operation must be run on a free (not transaction-aware) connection
template.keys("*");
// returns null as values set within a transaction are not visible
template.opsForValue().get("thing1");10.13. Assembly line
Redis supports streaming waterlines, which involves sending multiple commands to the server without waiting for a reply, and then reading the reply in one step. When you need to send multiple commands in succession, pipelining can improve performance, such as adding many elements to the same List.
Spring Data Redis provides a variety of methods for RedisTemplate to run commands in the pipeline. If you don't care about the result of pipeline operation, you can use the standard execute method to pass the pipeline parameter of true. These executePipelined methods run the provided RedisCallback or SessionCallback in the pipeline and return results, as shown in the following example:
//pop a specified number of items from a queue
List<Object> results = stringRedisTemplate.executePipelined(
new RedisCallback<Object>() {
public Object doInRedis(RedisConnection connection) throws DataAccessException {
StringRedisConnection stringRedisConn = (StringRedisConnection)connection;
for(int i=0; i< batchSize; i++) {
stringRedisConn.rPop("myqueue");
}
return null;
}
});The previous example ejects items from a queue in a pipeline in batches. All pop-up items are included in the results List. RedisTemplate uses its value, hash key and hash value serializer to deserialize all results before returning, so the return item in the previous example is a string. There are other executePipelined methods that allow you to pass custom serializers for pipelined results.
Note that the value RedisCallback returned from must be null because it is discarded in order to return the result of the pipeline command.
The lattice driver supports fine-grained refresh control, allowing commands to be refreshed when they occur, buffered, or sent when the connection is closed.
LettuceConnectionFactory factory = // ...
factory.setPipeliningFlushPolicy(PipeliningFlushPolicy.buffered(3));
Buffered locally and refreshed after every third command.
Since version 1.1, exec has made important changes to the RedisConnection and RedisTemplate methods. Previously, these methods returned the results of the transaction directly from the connector. This means that the data type is usually different from the data type returned from the method RedisConnection. For example, zAdd returns a boolean indicating whether an element has been added to the sort set. Most connectors return this value as long, and Spring Data Redis performs the conversion. Another common difference is that most connectors are OK, such as set. These replies are usually discarded by Spring Data Redis. Before 1.1, exec. Was not. In addition, the results did not deserialize RedisTemplate, so they usually contain the original byte array. If this change destroys your application, set convertPipelineAndTxResults is false. You RedisConnectionFactory to disable this behavior.
10.14.Redis script
Redis 2.6 and later versions support running Lua scripts through eval and evalsha commands. Spring Data Redis provides a high-level abstraction for running scripts that handle serialization and automatically use redis script caching.
Scripts can run RedisTemplate and ReactiveRedisTemplate by calling the execute method. Both use configurable ScriptExecutor(or ReactiveScriptExecutor) to run the provided scripts. By default, the ScriptExecutor(or ReactiveScriptExecutor) is responsible for serializing the provided keys and parameters and deserializing the script results. This is done through the template's key and value serializer. There is also an additional overload that allows you to pass custom serializers for script parameters and results.
The default ScriptExecutor optimizes the performance by retrieving the SHA1 of the script and trying to run it first. If the script has not appeared in the Redis script cache, evalsha, eval will fall back to.
The following example uses the Lua script to run a common check and set scenario. This is an ideal use case for Redis script, because it needs to run a set of commands atomically, and the behavior of one command is affected by the results of another command.
@Bean
public RedisScript<Boolean> script() {
ScriptSource scriptSource = new ResourceScriptSource(new ClassPathResource("META-INF/scripts/checkandset.lua"));
return RedisScript.of(scriptSource, Boolean.class);
}public class Example {
@Autowired
RedisScript<Boolean> script;
public boolean checkAndSet(String expectedValue, String newValue) {
return redisTemplate.execute(script, singletonList("key"), asList(expectedValue, newValue));
}
}-- checkandset.lua
local current = redis.call('GET', KEYS[1])
if current == ARGV[1]
then redis.call('SET', KEYS[1], ARGV[2])
return true
end
return false
The previous code configures a RedisScript to point to the file checkandset.lua named, which should return a Boolean value. The script resultType should be a Long, Boolean, List or deserialized value type. null this may also be the case if the script returns a discard state (especially OK).
It is best for DefaultRedisScript to configure a single instance in the application context to avoid recalculating the SHA1 of the script each time the script runs.
Then run the script using the method above checkAndSet. Scripts can run internally as part of a transaction or pipeline. For more information, see Redis transaction and pipeline.
The script support provided by Spring Data Redis also allows you to use Spring Task and Scheduler abstraction to schedule Redis scripts to run regularly. For more details, see the Spring framework documentation.
10.14.1.Redis cache
Change in 2.0
Spring Redis provides spring cache abstraction through packages org.springframework.data.redis.cache implementation. To use Redis as a support implementation, add RedisCacheManager to your configuration, as shown below:
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
return RedisCacheManager.create(connectionFactory);
}RedisCacheManager can use RedisCacheManagerBuilder to set the default RedisCacheConfiguration, transaction behavior and predefined cache.
RedisCacheManager cm = RedisCacheManager.builder(connectionFactory)
.cacheDefaults(defaultCacheConfig())
.withInitialCacheConfigurations(singletonMap("predefined", defaultCacheConfig().disableCachingNullValues()))
.transactionAware()
.build();As shown in the previous example, RedisCacheManager allows configuration to be defined on a per cache basis.
The behavior of RedisCachecreated with is RedisCacheConfiguration defined by RedisCacheManager. This configuration allows you to set the key expiration time, prefix and RedisSerializer to realize the conversion between binary storage format, as shown in the following example:
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(1))
.disableCachingNullValues();RedisCacheManager reads and writes binary values by default as a lockless RedisCacheWriter. Lockless caching improves throughput. Lack of entry locking may lead to overlapping non atomic commands in putIfAbsent and clean methods, because these commands need to send multiple commands to Redis. The lock counterpart prevents command overlap by setting an explicit lock key and checking the existence of this key, which can lead to additional requests and potential command waiting time.
Locking applies to the cache level, not to each cache entry.
You can choose to join the locking behavior, as shown below:
RedisCacheManager cm = RedisCacheManager.build(RedisCacheWriter.lockingRedisCacheWriter(connectionFactory)) .cacheDefaults(defaultCacheConfig()) ...
By default, any of the key cache entries is prefixed with the actual cache name followed by two colons. This behavior can be changed to static and calculated prefixes.
The following example shows how to set a static prefix:
// static key prefix
RedisCacheConfiguration.defaultCacheConfig().prefixKeysWith("( ͡° ᴥ ͡°)");
The following example shows how to set a computed prefix:
// computed key prefix
RedisCacheConfiguration.defaultCacheConfig().computePrefixWith(cacheName -> "¯\_(ツ)_/¯" + cacheName);The cache implementation uses KEYS and DEL to clear the cache by default. KEYS may cause performance problems with large key spaces. Therefore, RedisCacheWriter can use a to create the default value BatchStrategy to switch to the SCAN - based batch policy. The SCAN policy requires batch size to avoid too many Redis command round trips:
RedisCacheManager cm = RedisCacheManager.build(RedisCacheWriter.nonLockingRedisCacheWriter(connectionFactory, BatchStrategies.scan(1000))) .cacheDefaults(defaultCacheConfig()) ...
The KEYS batch strategy is fully supported by using any driver and Redis operation mode (independent, cluster). SCAN is fully supported when using the lattice driver. Jediscan only supports non cluster mode.
The following table lists the default settings for RedisCacheManager:
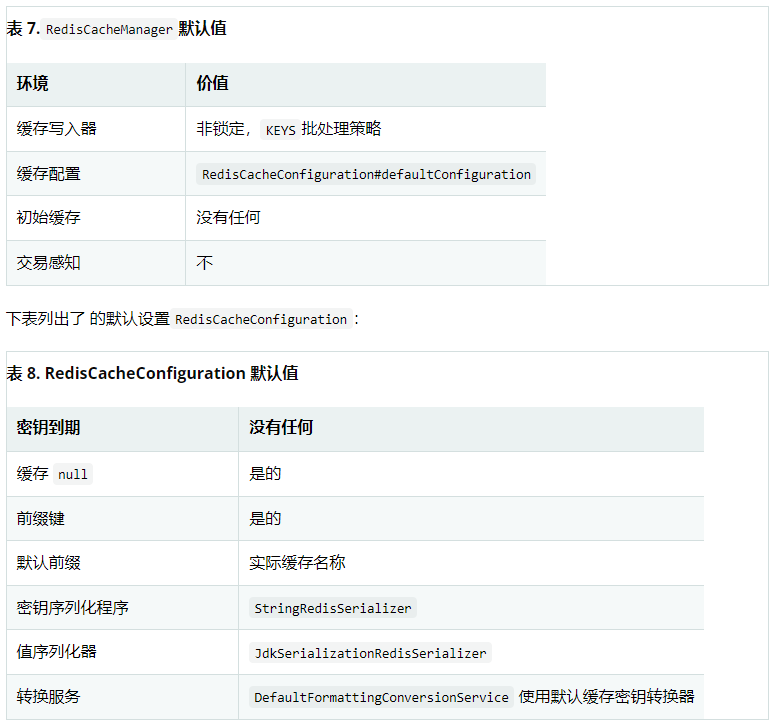
RedisCache statistics are disabled by default. use RedisCacheManagerBuilder.enableStatistics() collects local hits and misses, and returns a snapshot of the collected data through RedisCache#getStatistics().