This paper is based on the realization of the function of counting the total salary of employees in each department. If it has not been realized, please refer to: Realize the function of counting the total salary of employees in each department
Optimization project:
1. Use serialization
2. Implement partition partition
3.Map uses Combiner
Use serialization
This case is in Realize the function of counting the total salary of employees in each department Based on.
Serialization and deserialization:
Serialization refers to the process of converting Java objects into binary strings to facilitate network transmission;
Deserialization is the process of converting binary strings into Java objects.

MapReduce programming model and programming ideas:

And Realize the function of counting the total salary of employees in each department In contrast, this case needs to create one more employee class. The Employee class code is as follows:
code
Employee.java
package com.wang.employee;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @author CreazyHacking
* @version 1.0
* @date 12/4/2021 10:12 PM
*/
public class Employee implements Writable {
//Field names empno, ename, job, Mgr, hiredate, Sal, comm, deptno
//Data type: Int, Char, Char, Int, Date, Int, Int, Int
//Data: 7654, MARTIN, SALESMAN, 7698, 1981/9/28, 1250, 1400, 30
//Variables defined above
private int empno; //Employee number
private String ename; //full name
private String job; //department
private int mgr; //manager
private String hiredate; //time
private int sal; //wages
private int comm;//bonus
//Serialization method: a technique for converting java objects into data streams (binary strings / bytes) that can be transmitted across machines
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(this.empno);
dataOutput.writeUTF(this.ename);
dataOutput.writeUTF(this.job);
dataOutput.writeInt(this.mgr);
dataOutput.writeUTF(this.hiredate);
dataOutput.writeInt(this.sal);
dataOutput.writeInt(this.comm);
}
//Deserialization method: a technology that converts a data stream (binary string) that can be transmitted across machines into java objects
public void readFields(DataInput dataInput) throws IOException {
this.empno = dataInput.readInt();
this.ename = dataInput.readUTF();
this.job = dataInput.readUTF();
this.mgr = dataInput.readInt();
this.hiredate = dataInput.readUTF();
this.sal = dataInput.readInt();
this.comm = dataInput.readInt();
}
//Other classes operate variables through the set/get method: source -- > generator getters and setters
public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
}
SalaryTotalMapper.java
package com.wang.employee;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author CreazyHacking
* @version 1.0
* @date 12/4/2021 8:36 PM
*/
public class SalaryTotalMapper extends Mapper<LongWritable, Text, IntWritable, Employee> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//Data: 7499, Allen, salesman, 7698, 1981 / 2 / 201600300,30
String date = value.toString();
String[] words = date.split(",");
//Create employee object
Employee employee = new Employee();
//Set employee properties
employee.setEmpno(Integer.parseInt(words[0]));//Employee number
employee.setEname(words[1]); //full name
employee.setJob(words[2]); //position
try {
employee.setMgr(Integer.parseInt(words[3])); //Boss number
} catch (NumberFormatException e) {
employee.setMgr(-1); //There may be no boss number
}
employee.setHiredate(words[4]); //Entry date
employee.setSal(Integer.parseInt(words[5])); //a monthly salary
try {
employee.setComm(Integer.parseInt(words[6])); //bonus
} catch (NumberFormatException e) {
employee.setComm(0); //There may be no bonus
}
employee.setDeptno(Integer.parseInt(words[7])); //Department number
//Take out the department number words[7], convert String to Int, Int to IntWritable object, and assign k2
// IntWritable k2 = new IntWritable(employee.getDeptno()); // Department number
//Output k2, v2=employee object
context.write(new IntWritable(employee.getDeptno()), employee);
}
}
SalaryTotalReducer.java
package com.wang.employee;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author CreazyHacking
* @version 1.0
* @date 12/4/2021 8:36 PM
*/
public class SalaryTotalReducer extends Reducer<IntWritable,Employee,IntWritable,IntWritable> {
@Override
protected void reduce(IntWritable k3, Iterable<Employee> v3, Context context) throws IOException, InterruptedException {
//Take out the data of each employee in v3 for salary summation
IntWritable k4 = k3;
int toal = 0;
for (Employee v : v3){
toal += v.getSal();
}
context.write(k4, new IntWritable(toal));
}
}
SalaryTotalMain.java
package com.wang.employee;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author CreazyHacking
* @version 1.0
* @date 12/4/2021 8:35 PM
*/
@SuppressWarnings("all")
public class SalaryTotalMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1. Create a job and task entry (specify the main class)
Job job = Job.getInstance();
job.setJarByClass(SalaryTotalMain.class);
//2. Specify the mapper of the job and the type of output < K2 V2 >
job.setMapperClass(SalaryTotalMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Employee.class);
//3. Specify the reducer and output type of the job < K4 V4 >
job.setReducerClass(SalaryTotalReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputKeyClass(IntWritable.class);
//4. Specify the input and output paths of the job
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//5. Execute job
job.waitForCompletion(true);
}
}
Packaging project
Submit it to Hadoop to run and view the running results. It will not be viewable Realize the function of counting the total salary of employees in each department Packaging implementation process in
Note: if the code path changes, you need to change pro.xml
as
Replace with
<mainClass>com.wang.employee.SalaryTotalMain</mainClass>
result
Execute command
hadoop jar ~/soft/SalTotal-yh-1.0-SNAPSHOT.jar /EMP.csv /output_yh hdfs dfs -ls /output_yh hdfs dfs -cat /output_yh/part-r-00000

Implement partition partition
This case is an optimization of the use of serialization: the number of output files can be specified to store the results in partitions.
MapReduce has only one Reduce output file by default, such as part-r-00000.
Partition Partitioner can output multiple Reduce files with different output files, such as part-r-00000, part-r-00001, part-r-00002.
MapReduce programming model and programming ideas:
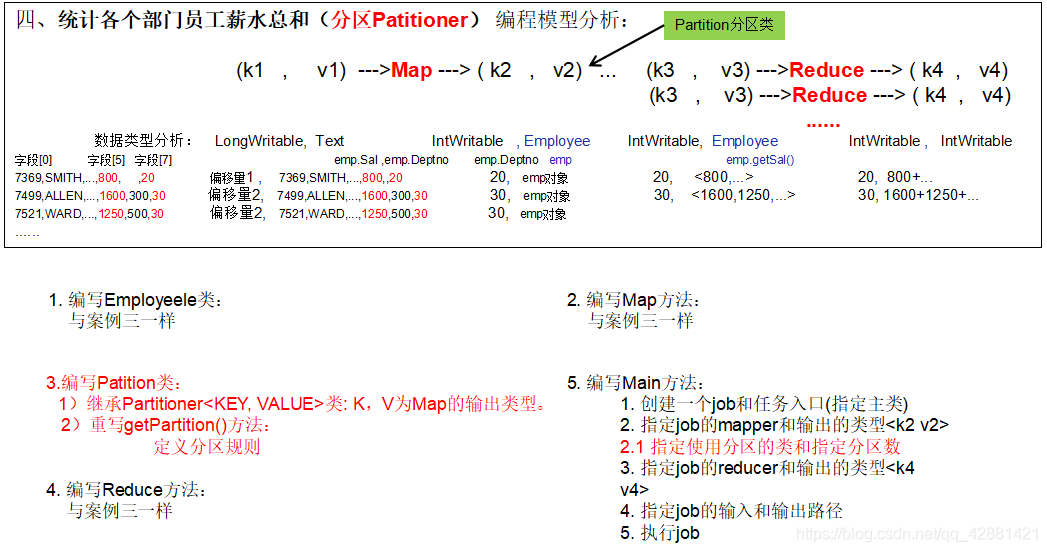
Compared with partition serialization, this case has one more partition class. The code of the partition class is as follows:
Patition.java
package com.myPatition;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
// map-outputs:k2,v2-->IntWritable, Employee
public class SalaryTotalPartitioner extends Partitioner<IntWritable, Employee>{
@Override
public int getPartition(IntWritable k2, Employee v2, int numPatition) {
//How to partition: each department is placed in a partition
if(v2.getDeptno() == 10) {
//Put it in zone 1
return 1%numPatition;// 1%3=1
}else if(v2.getDeptno() == 20){
//Put it in zone 2
return 2%numPatition;// 2%3=2
}else {
//Put it in zone 3
return 3%numPatition;// 3%3=0
}
}
}
Employee.java
package com.wang.patitioner;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @author CreazyHacking
* @version 1.0
* @date 12/4/2021 10:12 PM
*/
public class Employee implements Writable {
//Field names empno, ename, job, Mgr, hiredate, Sal, comm, deptno
//Data type: Int, Char, Char, Int, Date, Int, Int, Int
//Data: 7654, MARTIN, SALESMAN, 7698, 1981/9/28, 1250, 1400, 30
//Variables defined above
private int empno; //Employee number
private String ename; //full name
private String job; //position
private int mgr; //manager
private String hiredate; //time
private int sal; //wages
private int comm;//bonus
private int deptno; //Department number
public Employee() {
}
//Serialization method: a technique for converting java objects into data streams (binary strings / bytes) that can be transmitted across machines
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(this.empno);
dataOutput.writeUTF(this.ename);
dataOutput.writeUTF(this.job);
dataOutput.writeInt(this.mgr);
dataOutput.writeUTF(this.hiredate);
dataOutput.writeInt(this.sal);
dataOutput.writeInt(this.comm);
}
//Deserialization method: a technology that converts a data stream (binary string) that can be transmitted across machines into java objects
public void readFields(DataInput dataInput) throws IOException {
this.empno = dataInput.readInt();
this.ename = dataInput.readUTF();
this.job = dataInput.readUTF();
this.mgr = dataInput.readInt();
this.hiredate = dataInput.readUTF();
this.sal = dataInput.readInt();
this.comm = dataInput.readInt();
}
//Other classes operate variables through the set/get method: source -- > generator getters and setters
public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
public int getDeptno() {
return deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
}
SalaryTotalMapper.java
package com.wang.patitioner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author CreazyHacking
* @version 1.0
* @date 12/4/2021 8:36 PM
*/
public class SalaryTotalMapper extends Mapper<LongWritable, Text, IntWritable, Employee> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//Data: 7499, Allen, salesman, 7698, 1981 / 2 / 201600300,30
String date = value.toString();
String[] words = date.split(",");
//Create employee object
Employee employee = new Employee();
//Set employee properties
employee.setEmpno(Integer.parseInt(words[0]));//Employee number
employee.setEname(words[1]); //full name
employee.setJob(words[2]); //position
try {
employee.setMgr(Integer.parseInt(words[3])); //Boss number
} catch (NumberFormatException e) {
employee.setMgr(-1); //There may be no boss number
}
employee.setHiredate(words[4]); //Entry date
employee.setSal(Integer.parseInt(words[5])); //a monthly salary
try {
employee.setComm(Integer.parseInt(words[6])); //bonus
} catch (NumberFormatException e) {
employee.setComm(0); //There may be no bonus
}
employee.setDeptno(Integer.parseInt(words[7])); //Department number
//Take out the department number words[7], convert String to Int, Int to IntWritable object, and assign k2
IntWritable k2 = new IntWritable(employee.getDeptno()); //Department number
Employee v2 = employee; //Employee object
//Output k2, v2=employee object
context.write(k2, v2);
}
}
SalaryTotalReducer.java
package com.wang.patitioner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author CreazyHacking
* @version 1.0
* @date 12/4/2021 8:36 PM
*/
public class SalaryTotalReducer extends Reducer<IntWritable, Employee,IntWritable,Employee> {
@Override
protected void reduce(IntWritable k3, Iterable<Employee> v3, Context context) throws IOException, InterruptedException {
//Take out the data of each employee in v3 for salary summation
IntWritable k4 = k3;
for (Employee e : v3){
context.write(k4, e);
}
}
}
PartEmployeelMain.java
package com.wang.patitioner;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author CreazyHacking
* @version 1.0
* @date 12/4/2021 8:35 PM
*/
@SuppressWarnings("all")
public class PartEmployeelMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1. Create a job and task entry (specify the main class)
Job job = Job.getInstance();
job.setJarByClass(PartEmployeelMain.class);
//2. Specify the mapper of the job and the type of output < K2 V2 >
job.setMapperClass(SalaryTotalMapper.class);
job.setMapOutputKeyClass(IntWritable.class); //Department number
job.setMapOutputValueClass(Employee.class); // staff
//Specifies the partition rule for the task
job.setPartitionerClass(Patition.class);
//Specify how many partitions to create
job.setNumReduceTasks(3);
//3. Specify the reducer and output type of the job < K4 V4 >
job.setReducerClass(SalaryTotalReducer.class);
job.setOutputKeyClass(IntWritable.class);//Department number
job.setOutputKeyClass(Employee.class);// staff
//4. Specify the input and output paths of the job
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//5. Execute job
job.waitForCompletion(true);
}
}
Package upload execution
Packaging project
Submit it to Hadoop to run and view the running results. It will not be viewable Realize the function of counting the total salary of employees in each department Packaging implementation process in
Note: if the code path changes, you need to change pro.xml
as
Replace with
<mainClass>com.wang.patitioner.PartEmployeelMain</mainClass>
result
Execute command
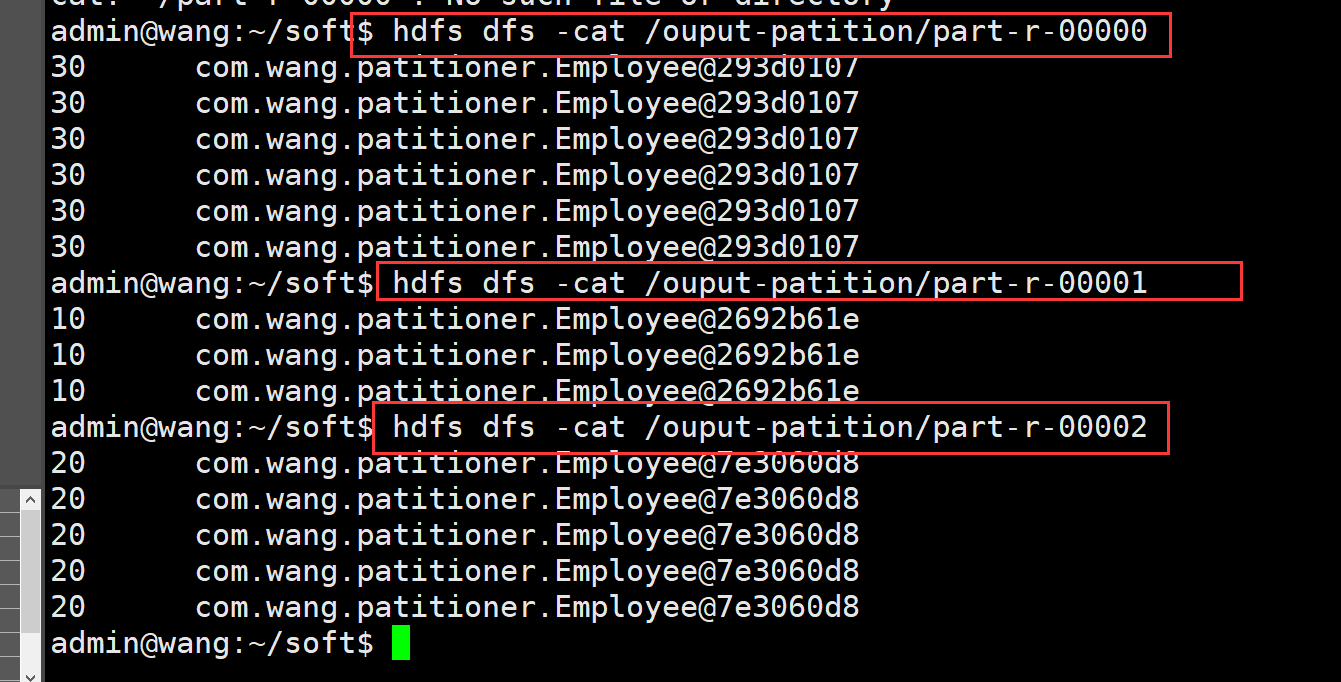
hadoop jar SalTotal-Patition-1.0-SNAPSHOT.jar /EMP.csv /ouput-patition hdfs dfs -ls /ouput-patition hdfs dfs -cat /ouput-patition/part-r-00000 hdfs dfs -cat /ouput-patition/part-r-00001 hdfs dfs -cat /ouput-patition/part-r-00002
Map uses Combiner
This case is based on the function of counting the total salary of employees in each department.
Using Combine means using Reduce once to merge intermediate results during Map output, which can Reduce the number of Shuffle network transmission and improve efficiency. However, it should be noted that Combiner cannot be used in some situations, for example, when calculating the average value.
MapReduce programming model and programming ideas:
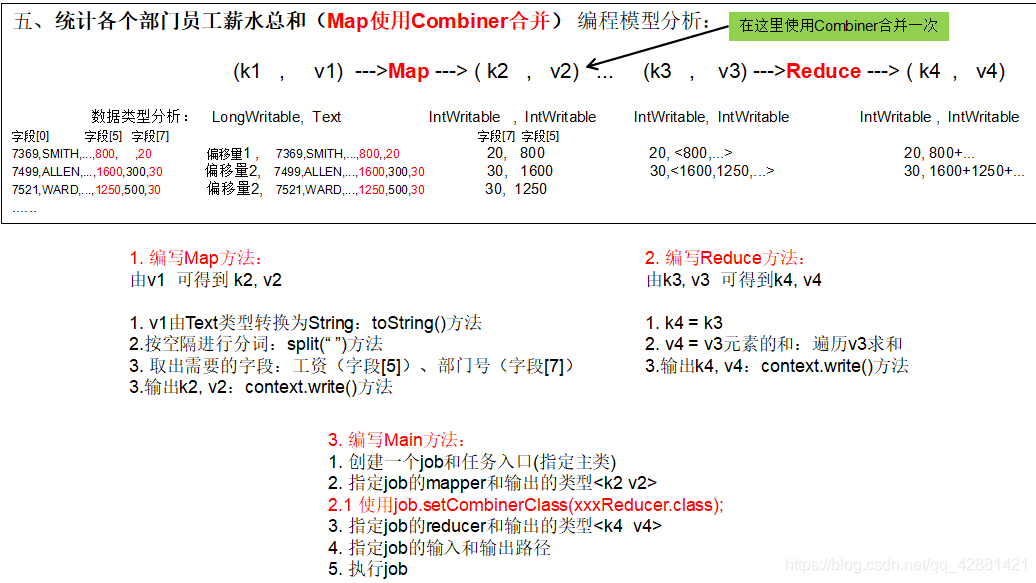
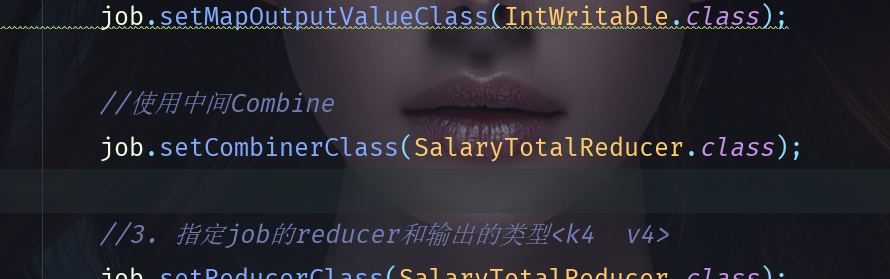
Using Combine is very simple. You only need to add it to the Main class, as shown in step 2.1 above.
job.setCombinerClass(SalaryTotalReducer.class);
Package execution
The steps are the same as above
Give the results directly

