Hello, I'm brother Manon Feige. Thank you for reading this article. Welcome to one click three times.
😁 1. Take a stroll around the community. There are benefits and surprises every week. Manon Feige community, leap plan
💪🏻 2. Python basic column, you can catch all the basic knowledge. Python from introduction to mastery
❤️ 3. Ceph has everything from principle to actual combat. Ceph actual combat
❤️ 4. Introduction to Java high concurrency programming, punch in and learn java high concurrency. Introduction to Java high concurrency programming
Key points of this article: This article mainly studies regular expressions and the use of re module.
Pay attention to the official account below, and many welfare prostitution. Add me VX to study in the group. I'm not alone on the way to study

Why did you write this article?
In the previous two articles, we introduced the basic syntax of regular expressions and some simple usage scenarios. If you haven't seen it yet, come and see it quickly,
Learn regular expressions well and match anything difficult to match with [advanced introduction to python crawler] (07)
Check the mobile phone number with regular expression. The email is a fraud [advanced introduction to python crawler] (08)
Why not learn what you can learn in a few minutes?
This paper further enlarges the application of regular expression and uses it to crawl the data of ancient poetry and prose websites. In this article, please hide xpath temporarily.
In order to facilitate better learning and communication, I have established a learning and communication group here.

Analysis of ancient poetry website
Figure 1 below shows the home page data of the poetry column of the ancient poetry website. The address of this column is: https://so.gushiwen.cn/shiwens/
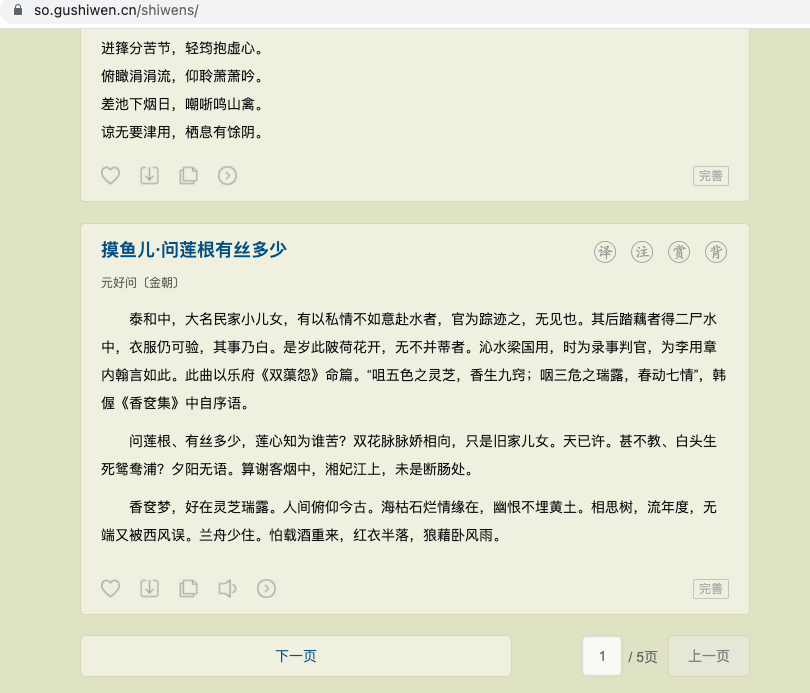
The address on the second page is: https://so.gushiwen.cn/shiwens/default.aspx?page=2&tstr=&astr=&cstr=&xstr= . And so on. The address on page n is page=n. Others remain unchanged.
1. Get the total number of pages with regular expression

The matching regular expression is R '< div class = "pageright" >. *< span .*?> (.*?)</span>'
- First, the r modified string is a native string, which is first matched to the < div class = "pageright" > tag, and then passed through. *? Match the < a > tag < span > tag, etc. Here. Can match any character (except newline character), and the * sign can match 0 or any number of characters.? Sign indicates that only 1 or 0 can be matched. Add here? No. is to use non greedy mode.
- <span .*?> By matching the < span > tag to the total number of pages. Specify. * in the label?
- (. *?) plus () can specify different groups. Here we only need to get the number of pages, so we add a group separately.
Therefore, the final code is:
def get_total_pages():
resp = requests.get(first_url)
# Get total pages
ret = re.findall(r'<div class="pagesright">.*?<span .*?>(.*?)</span>', resp.text, re.DOTALL)
result = re.search('\d+', ret[0])
for page_num in range(int(result.group())):
url = 'https://so.gushiwen.cn/shiwens/default.aspx?page=' + str(page_num)
parse_page(url)
The re.DOTALL parameter is passed in the findall method so that the. Sign can match the newline \ n.
The previous ret result is / 5 pages. To get the number 5 again, you need to do a matching search, which is to find it through re.search('\d+', ret[0]).
2. Extract the title of the poem
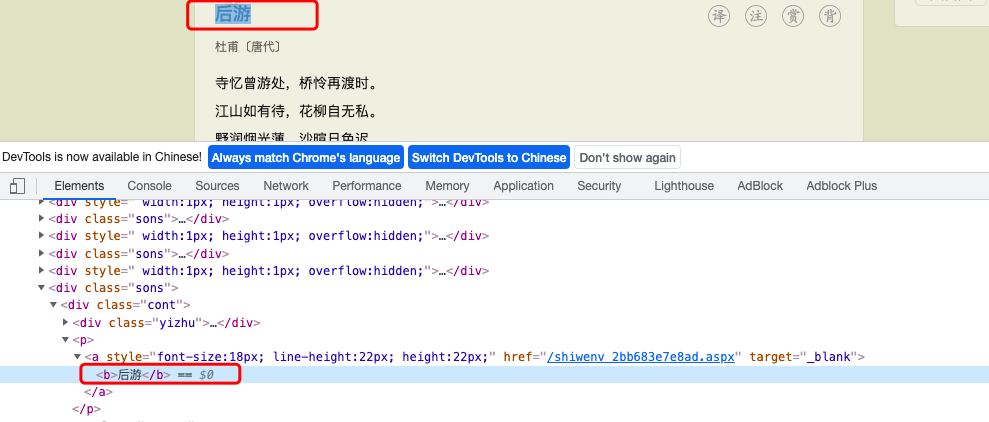
As shown in Figure 2 above, the HTML source code of the poem title is shown. It can be seen that the poem title has a < b > tag, and the regular expression matching the poem title is < div class = "CONT" >. *< b>(.*?)</b>
First, match the < div class = "CONT" > tag, and then match < b > (. *?) < / b > here, the non greedy mode is used for matching.
3. Extract the author and Dynasty
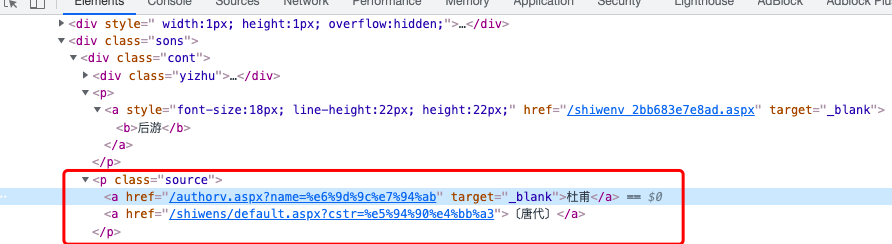
As shown in Figure 3 above, the HTML source code of the author of the poem and the dynasty is shown. It can be seen that both the author and the dynasty are in the two a tags under the < p class = "source" > < / P > tag.
3.1 extraction of authors
The regular expression extracted by the author is < p class = "source" >. *< a .*?> (. *?) < / a > first match to the < p class = "source" > tag. Then match the contents of the first < a > tag.
3.2 extraction of dynasties
The regular expression for extracting dynasties is < p class = "source" >. *< a .*?>< a .*?> (. *?) < / a > different from the extraction author, there is one more < a. *? >, This is because the dynasty is in the second < a > label.
5. Extract the content of the poem

As shown in Figure 4 above, the HTML source code of the poem content is shown. It can be seen that the poems are in the < div class = "contson" > tag, so you only need to match the content in this tag. Its regular expression is < div class = "contson". *? > (.*?)</div>.
However, the matched data contains < br > tags. Therefore, we need to replace this tag through the sub method. re.sub(r'<.*?>+', "", content).
Sorting code
So far, we have extracted all the data we want. Next, we need to process the data. The final data format we expect is:
poems=[
{
"title": 'Fisherman pride·The bottom of the flower suddenly smells and knocks two oars',
"author":'Zhang San',
'dynasty':'the tang dynasty',
'content':'xxxxxx'
}
{
"title": 'Goose goose goose',
"author":'Li Si',
'dynasty':'the tang dynasty',
'content':'xxxxxx'
}
]
Previously, we obtained a list of all titles; List of all authors; List of dynastys of all dynasties; List contents of all verses.
So how do we combine these lists into the form above?
Here, you need to use the zip function. This function can combine multiple lists into a new list, in which the elements of the list are tuples. For example:
a=['name','age'] b=['Zhang San',18] c=zip(a,b)
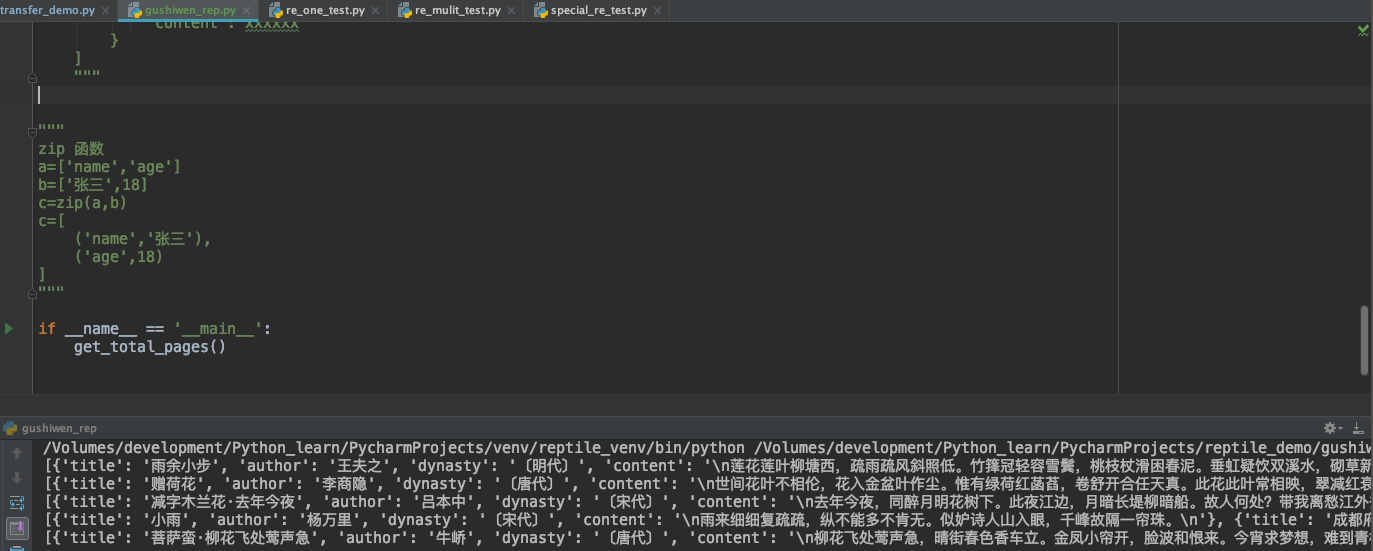
After calling the zip method, you get a zip object, which can be converted into a list object. The final results are shown in Figure 5 below

Complete source code
# -*- utf-8 -*-
"""
@url: https://blog.csdn.net/u014534808
@Author: Mainong Feige
@File: gushiwen_rep.py
@Time: 2021/12/7 07:40
@Desc: Crawling ancient poetry websites with regular expressions
Address of ancient poetry website:
https://www.gushiwen.cn/
"""
import re
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
}
first_url = 'https://so.gushiwen.cn/shiwens/default.aspx'
def get_total_pages():
resp = requests.get(first_url)
# Get total pages
ret = re.findall(r'<div class="pagesright">.*?<span .*?>(.*?)</span>', resp.text, re.DOTALL)
result = re.search('\d+', ret[0])
for page_num in range(int(result.group())):
url = 'https://so.gushiwen.cn/shiwens/default.aspx?page=' + str(page_num)
parse_page(url)
# Parse page
def parse_page(url):
resp = requests.get(url)
text = resp.text
# Extract the title (. *) for grouping, and only extract the content in the < b > tag. By default. Cannot match \ n. Adding re.DOTALL indicates that. Can match all greedy patterns
# titles = re.findall(r'<div class="cont">.*<b>(.*)</b>', text,re.DOTALL)
# Non greedy model
titles = re.findall(r'<div class="cont">.*?<b>(.*?)</b>', text, re.DOTALL)
# Extract author
authors = re.findall(r'<p class="source">.*?<a .*?>(.*?)</a>', text, re.DOTALL)
# Extraction Dynasty
dynastys = re.findall(r'<p class="source">.*?<a .*?><a .*?>(.*?)</a>', text, re.DOTALL)
# Extract verse
content_tags = re.findall(r'<div class="contson" .*?>(.*?)</div>', text, re.DOTALL)
contents = []
for content in content_tags:
content = re.sub(r'<.*?>+', "", content)
contents.append(content)
poems = []
for value in zip(titles, authors, dynastys, contents):
# Unpack
title, author, dynasty, content = value
poems.append(
{
"title": title,
"author": author,
'dynasty': dynasty,
'content': content
}
)
print(poems)
"""
poems=[
{
"title": 'Fisherman pride·The bottom of the flower suddenly smells and knocks two oars',
"author":'Zhang San',
'dynasty':'the tang dynasty',
'content':'xxxxxx'
}
{
"title": 'Fisherman pride·The bottom of the flower suddenly smells and knocks two oars',
"author":'Zhang San',
'dynasty':'the tang dynasty',
'content':'xxxxxx'
}
]
"""
"""
zip function
a=['name','age']
b=['Zhang San',18]
c=zip(a,b)
c=[
('name','Zhang San'),
('age',18)
]
"""
if __name__ == '__main__':
get_total_pages()
The final operation result is:
summary
This paper takes the ancient poetry website as an example to demonstrate how to crawl website data through regular expressions.
Exclusive benefits for fans
Soft test materials: Practical soft test materials
Interview questions: 5G Java high frequency interview questions
Learning materials: 50G various learning materials
Withdrawal secret script: reply to [withdrawal]
Concurrent programming: reply to [concurrent programming]
👇🏻 The verification code can be obtained by searching the official account below.👇🏻