I. Introduction
Problem: Existing CNN s require fixed-size input pictures, which can be achieved by clipping or distorting the original image. These two methods may have different problems: (i) The clipped area may not contain the whole object; (ii) The distortion operation results in unnecessary geometric distortion of the target. If the target sizes vary, the pre-defined sizes may not be appropriate.
Cause: CNN is mainly composed of convolution layer and full connection layer, where convolution layer output size is a variable of input size, while full connection layer produces fixed size output and also requires fixed size weights and inputs, so the restriction of CNN network on full connection layer requires fixed length input.
Solution: SPP, Spytial Pyramid Pooling, spatial pyramid pooling;
2. Principles
Function: remove the fixed-size constraint of the network: A method for pooling feature map s of any size produces a fixed-length output to the full connection layer, avoiding clipping or distortion, independent of the convolution layer for feature extraction;
Feature Map: The output of the original photo after it has been convoluted is feature maps. Feature maps contain two aspects of information: (i) response intensity to certain features; (ii) corresponding spatial location.
The practice of SPP is to add an SPP layer after the convolution layer, and the SPP layer pulls the feature map to a feature vector of a fixed length. Then enter the feature vectors into the fully-connected layers. The process differences between SPP and R-CNN are as follows:

SPP has two advantages in doing this: 1. Solving the problem of proposal regions (convolution area) size, i.e. generating fixed length output for different input sizes; 2. Feature maps can be pooled at different scales because of the flexibility of input size. The results of feature maps can be shared to save computing time when representing each proposal region. 3. Use multilevel spatial bins instead of single-sized pooled windows to be robust to deformation. SPP is represented as follows:
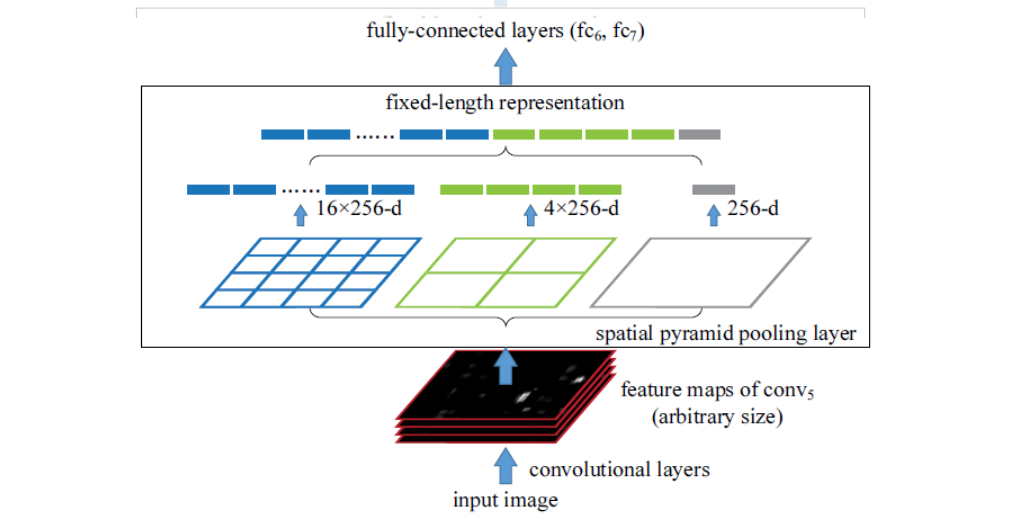
The convolution layer is followed by a SPP layer, which forms a fixed-length feature vector, and then the full connection layer is input.
For example, an original image of any size generates feature maps after a convolution layer. Assuming that the last convolution layer is conv5 and 256 filters are used, the resulting feature maps are (W, H, 256) in size. Each feature map has (W, H) a total of 256 feature maps. Assuming there is a proposal region corresponding to the size of (w, h, 256) on the feature maps, input to the spatial pyramid pooling layer, SPP layer divides the feature maps into 4*4, 2*2, 1*1 bin levels, and after max pooling changes each feature map into 16, 4, 1 feature level featurevector s, since there are 256 layers of feature maps, So combine the feature vector s of each layer into vectors of 16*256-d, 4*256-d, and 1*256-d levels. Finally, these vectors are combined and reused as the output of the SPPlayer.
These steps can be summarized as follows:
1. As shown in the figure above, when we enter a picture, we divide a picture by using scales of different sizes. In the diagram above, three scales of different sizes (4*4,2*2,1*1) are used to divide an input picture, resulting in a total of 16+4+1=21 blocks. We are going to extract a feature from each of these 21 blocks, which happens to be the 21-dimensional feature vector that we are extracting.
2.For the first picture, we divided a complete picture into 16 blocks, that is, the size of each block is (w/4,h/4);
3. The second picture is divided into four blocks, each of which is (w/2,h/2);
4. The third picture takes an entire picture as a block, that is, the block size is (w,h).
5. The process of maximizing the pooling of spatial pyramids is to calculate the maximum value of each of the 21 image blocks to get an output neuron. Finally, a picture of any size is converted to a 21-dimensional feature of a fixed size (of course, you can design outputs of other dimensions, increase the number of layers of the pyramid, or change the size of the mesh). The three different scales above are divided, each of which we call: the first layer of the pyramid, and the size of each picture block we call windows size. If you want one layer of the pyramid to output n*n features, then you'll pool with a size of windows size: (w/n,h/n).
3. Code implementation
Neural Network Framework Version (tensorflow==1.14;keras==2.2.4)
The original Spatial Pyramid Pooling, SPP code is implemented as follows:
from keras.engine.topology import Layer
import keras.backend as K
class SpatialPyramidPooling(Layer):
def __init__(self, pool_list, **kwargs):
self.dim_ordering = K.image_dim_ordering()
assert self.dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}'
self.pool_list = pool_list
self.num_outputs_per_channel = sum([i * i for i in pool_list])
super(SpatialPyramidPooling, self).__init__(**kwargs)
def build(self, input_shape):
if self.dim_ordering == 'th':
self.nb_channels = input_shape[1]
elif self.dim_ordering == 'tf':
self.nb_channels = input_shape[3]
def compute_output_shape(self, input_shape):
return (input_shape[0], self.nb_channels * self.num_outputs_per_channel)
def get_config(self):
config = {'pool_list': self.pool_list}
base_config = super(SpatialPyramidPooling, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def call(self, x, mask=None):
input_shape = K.shape(x)
if self.dim_ordering == 'th':
num_rows = input_shape[2]
num_cols = input_shape[3]
elif self.dim_ordering == 'tf':
num_rows = input_shape[1]
num_cols = input_shape[2]
row_length = [K.cast(num_rows, 'float32') / i for i in self.pool_list]
col_length = [K.cast(num_cols, 'float32') / i for i in self.pool_list]
outputs = []
if self.dim_ordering == 'th':
for pool_num, num_pool_regions in enumerate(self.pool_list):
for jy in range(num_pool_regions):
for ix in range(num_pool_regions):
x1 = ix * col_length[pool_num]
x2 = ix * col_length[pool_num] + col_length[pool_num]
y1 = jy * row_length[pool_num]
y2 = jy * row_length[pool_num] + row_length[pool_num]
x1 = K.cast(K.round(x1), 'int32')
x2 = K.cast(K.round(x2), 'int32')
y1 = K.cast(K.round(y1), 'int32')
y2 = K.cast(K.round(y2), 'int32')
new_shape = [input_shape[0], input_shape[1], y2 - y1, x2 - x1]
x_crop = x[:, :, y1:y2, x1:x2]
xm = K.reshape(x_crop, new_shape)
pooled_val = K.max(xm, axis=(2, 3))
outputs.append(pooled_val)
elif self.dim_ordering == 'tf':
for pool_num, num_pool_regions in enumerate(self.pool_list):
for jy in range(num_pool_regions):
for ix in range(num_pool_regions):
x1 = ix * col_length[pool_num]
x2 = ix * col_length[pool_num] + col_length[pool_num]
y1 = jy * row_length[pool_num]
y2 = jy * row_length[pool_num] + row_length[pool_num]
x1 = K.cast(K.round(x1), 'int32')
x2 = K.cast(K.round(x2), 'int32')
y1 = K.cast(K.round(y1), 'int32')
y2 = K.cast(K.round(y2), 'int32')
new_shape = [input_shape[0], y2 - y1, x2 - x1, input_shape[3]]
x_crop = x[:, y1:y2, x1:x2, :]
xm = K.reshape(x_crop, new_shape)
pooled_val = K.max(xm, axis=(1, 2))
outputs.append(pooled_val)
if self.dim_ordering == 'th':
outputs = K.concatenate(outputs)
elif self.dim_ordering == 'tf':
outputs = K.concatenate(outputs)
return outputs
How to invoke it? Reference below:
model = Sequential()
model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape=(3, None, None)))
model.add(Activation('relu'))
model.add(Convolution2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3, border_mode='same'))
model.add(Activation('relu'))
model.add(Convolution2D(64, 3, 3))
model.add(Activation('relu'))
model.add(SpatialPyramidPooling([1, 2, 4]))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd')The test code implementation can be downloaded at the following link:
keras-spp code implementation.rar-Deep learning document class resource-CSDN Download