I Connection pool
1. Introduction
Mybatis uses its own connection pool technology, which can be found in mybatis config XML
As shown in the figure:
2. Classification of mybaits connection pool
UNPOOLED does not use the data source of the connection pool
POOLED uses the data source of the connection pool
JNDI database connection pool implemented using JNDI
3.UNPOOLED analysis
UNPOOLED does not use the data source of the connection pool. When the type attribute of dateSource is configured as UNPOOLED, MyBatis will first instantiate an UnpooledDataSourceFactory factory instance, and then use The getDataSource() method returns an UnpooledDataSource instance object reference, which is assumed to be a dataSource.
Using getConnection() of UnPooledDataSource, a new Connection instance object will be generated every time it is called. The getConnection() method of UnPooledDataSource is implemented as follows:
public class UnpooledDataSource implements DataSource {
private ClassLoader driverClassLoader;
private Properties driverProperties;
private static Map<String, Driver> registeredDrivers = new ConcurrentHashMap();
private String driver;
private String url;
private String username;
private String password;
private Boolean autoCommit;
private Integer defaultTransactionIsolationLevel;
public UnpooledDataSource() {
}
public UnpooledDataSource(String driver, String url, String username, String password){
this.driver = driver;
this.url = url;
this.username = username;
this.password = password;
}
public Connection getConnection() throws SQLException {
return this.doGetConnection(this.username, this.password);
}
private Connection doGetConnection(String username, String password) throws SQLException {
Properties props = new Properties();
if(this.driverProperties != null) {
props.putAll(this.driverProperties);
}
if(username != null) {
props.setProperty("user", username);
}
if(password != null) {
props.setProperty("password", password);
}
return this.doGetConnection(props);
}
private Connection doGetConnection(Properties properties) throws SQLException {
this.initializeDriver();
Connection connection = DriverManager.getConnection(this.url, properties);
this.configureConnection(connection);
return connection;
}
}As shown in the above code, UnpooledDataSource will do the following:
- Initialize driver: judge whether the driver driver has been loaded into memory. If it has not been loaded, the driver class will be loaded dynamically, and a driver object will be instantiated to use drivermanager The registerdriver () method registers it in memory for subsequent use.
- Create Connection object: use drivermanager The getconnection () method creates a Connection.
- Configure Connection object: set whether to automatically submit autoCommit and isolation level isolationLevel.
- Return Connection object
As can be seen from the above code, every time we call the getConnection() method, we will use drivermanager getConnection() returns a new Java sql. Connection instance, so there is no connection pool.
4.POOLED analysis
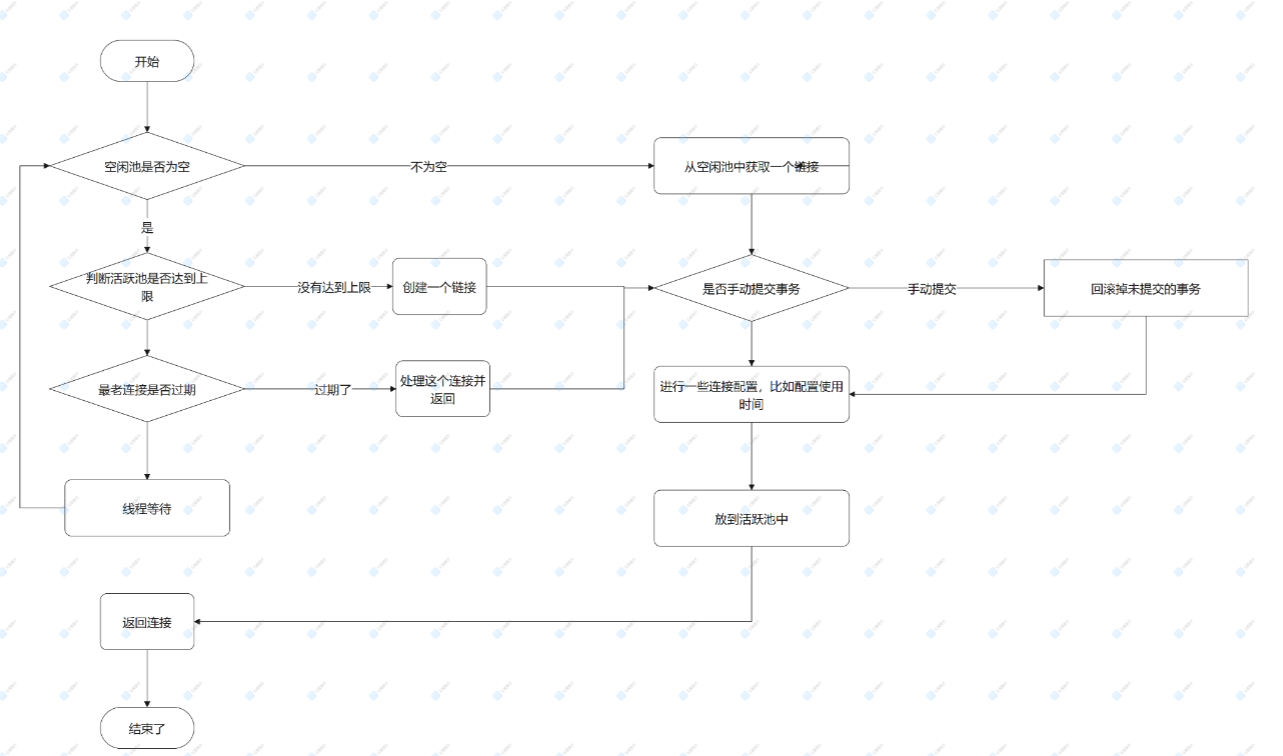
PooledDataSource: Java sql. The connection object is wrapped into a PooledConnection object and maintained in a container of PoolState type. MyBatis divides pooledconnections in the connection pool into two states: idle state (idle) and active state (active). PooledConnection objects in these two states are stored in the idleConnections and active connections List collections in the PoolState container respectively:
idleConnections:
The PooledConnection object in idle state is placed in this collection, indicating the PooledConnection collection that is currently idle and not used. When calling the getConnection() method of PooledDataSource, the PooledConnection object in this collection will take precedence. When you run out of a Java sql. When a connection object is, MyBatis wraps it into a PooledConnection object and puts it in this collection.
**activeConnections: **
The PooledConnection object in the active state is placed in the ArrayList named activeConnections, which indicates the PooledConnection collection currently in use. When calling the getConnection() method of PooledDataSource, the PooledConnection object will be taken from the idleConnections collection first. If not, it depends on whether the collection is full. If not, PooledDataSource creates a PooledConnection, adds it to this collection, and returns
Now let's take a look at what the popConnection() method does:
- First, check whether there is a PooledConnection object in the idle state. If so, directly return an available PooledConnection object; Otherwise, proceed to step 2.
- Check whether the PooledConnection pool active connections in active status is full; If it is not full, create a new PooledConnection object, put it into the activeConnections pool, and then return the PooledConnection object; Otherwise, proceed to the third step;
- Check whether the PooledConnection object that first enters the activeConnections pool has expired: if it has expired, remove this object from the activeConnections pool, create a new PooledConnection object, add it to activeConnections, and then return this object; Otherwise, proceed to step 4.
- Thread waiting, loop 2 steps
/*
* Pass a user name and password to return the available PooledConnection from the connection pool
*/
private PooledConnection popConnection(String username, String password) throws SQLException
{
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null)
{
synchronized (state)
{
if (state.idleConnections.size() > 0)
{
// There are free connections in the connection pool. Take out the first one
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled())
{
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
}
else
{
// If there are no free connections in the connection pool, the number of currently used connections is less than the maximum limit,
if (state.activeConnections.size() < poolMaximumActiveConnections)
{
// Create a new connection object
conn = new PooledConnection(dataSource.getConnection(), this);
@SuppressWarnings("unused")
//used in logging, if enabled
Connection realConn = conn.getRealConnection();
if (log.isDebugEnabled())
{
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
}
else
{
// Cannot create new connection when the active connection pool is full and cannot be created, the PooledConnection object that first enters the connection pool is taken out
// Calculate its verification time. If the verification time is greater than the maximum verification time specified by the connection pool, it is considered to have expired. Use the realConnection inside the PoolConnection to regenerate a PooledConnection
//
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime)
{
// Can claim overdue connection
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit())
{
oldestActiveConnection.getRealConnection().rollback();
}
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
oldestActiveConnection.invalidate();
if (log.isDebugEnabled())
{
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
}
else
{
//If it cannot be released, it must wait
// Must wait
try
{
if (!countedWait)
{
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled())
{
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
}
catch (InterruptedException e)
{
break;
}
}
}
}
//If the PooledConnection is obtained successfully, its information is updated
if (conn != null)
{
if (conn.isValid())
{
if (!conn.getRealConnection().getAutoCommit())
{
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
}
else
{
if (log.isDebugEnabled())
{
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + 3))
{
if (log.isDebugEnabled())
{
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
if (conn == null)
{
if (log.isDebugEnabled())
{
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}When we finish using the connection object in our program, if we don't use the database connection pool, we usually call connection Close () method to close the connection and release resources
All the resources held by the Connection object that has called the close() method will be released, and the Connection object can no longer be used. So, if we use a Connection pool, what should we do when we run out of Connection objects and need to put them in the Connection pool?
Maybe the first thought that comes to mind is: I should call con When using the close() method, instead of calling the close() method, replace it with the code that puts the Connection object into the Connection pool container!
How to implement the Connection object calls the close() method, but it is actually added to the Connection pool
This is to use the proxy mode to create a proxy object for the real Connection object. All methods of the proxy object are implemented by calling the methods of the corresponding real Connection object. When the proxy object executes the close() method, it needs special processing. Instead of calling the close() method of the real Connection object, the Connection object is added to the Connection pool.
The PoolState of the PooledDataSource of MyBatis internally maintains an object of type PooledConnection, which is a Java. Java connection to a real database sql. Wrapper for the connection instance object.
PooledConnection object holds a real database connection Java sql. Connection instance object and a Java sql. Proxy for connection:
class PooledConnection implements InvocationHandler {
private static final String CLOSE = "close";
private static final Class<?>[] IFACES = new Class[]{Connection.class};
private int hashCode = 0;
private PooledDataSource dataSource;
private Connection realConnection;
private Connection proxyConnection;
private long checkoutTimestamp;
private long createdTimestamp;
private long lastUsedTimestamp;
private int connectionTypeCode;
private boolean valid;
public PooledConnection(Connection connection, PooledDataSource dataSource) {
this.hashCode = connection.hashCode();
this.realConnection = connection;
this.dataSource = dataSource;
this.createdTimestamp = System.currentTimeMillis();
this.lastUsedTimestamp = System.currentTimeMillis();
this.valid = true;
this.proxyConnection = (Connection)Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
//When closing, the connection will be recycled, not the real close
if("close".hashCode() == methodName.hashCode() && "close".equals(methodName)) {
this.dataSource.pushConnection(this);
return null;
} else {
try {
if(!Object.class.equals(method.getDeclaringClass())) {
this.checkConnection();
}
return method.invoke(this.realConnection, args);
} catch (Throwable var6) {
throw ExceptionUtil.unwrapThrowable(var6);
}
}
}
}Process diagram:
II Transaction and isolation level
1. Submission method of transaction
In jdbc, the transaction submission method is set through the setAutoCommit() interface. The transaction submission method in jdbc is encapsulated in mybatis. Its submission method is as follows
// Set to auto submit sqlSession = MybatisUtils.openSession(true); //If the default parameter is not written, it is submitted manually //Manual submission sqlSession.commit();
2. Transaction rollback
When executing one or more sql statements, if an exception occurs in the middle, it needs to be rolled back. The rollback method in mybatis
sqlSession.rollback();
//Test the rollback of transactions after an error is reported
@Test
public void TestRollBack(){
try {
//Insert user
User user = new User();
user.setNickname("Zhang San");
userMapper.insertUser(user);
//Analog midway error reporting
int a = 10/0;
//Simulate inserting the corresponding user address
Address address = new Address();
address.setAddress("Fangda Science Park");
address.setUserId(user.getId());
addressMapper.insertAddress(address);
} catch (Exception e) {
e.printStackTrace();
session.rollback();//Error rollback
}
}3. Isolation level of transactions
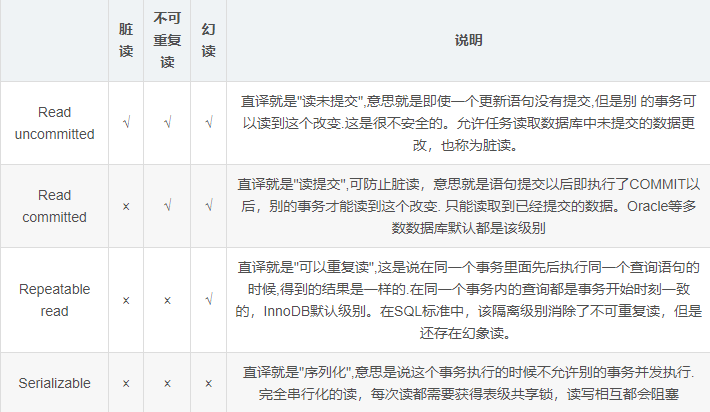
1. Dirty reading, non repeatable reading, unreal reading
Dirty read: read uncommitted data. This is easy to understand. If uncommitted data is read, if the data is rolled back, dirty data (data that should not exist) is read
Non repeatable reading: the data read twice is inconsistent. During A transaction, data A is read for the first time. During the execution of the transaction, the data is modified. When the data needs to be read again, the data has changed, and some errors will occur
Unreal reading: there is no data at the beginning, but it will be read later. This is generally designed to insert operation. It is empty at the beginning of reading, but during the process of transaction, the entry is inserted, and the data will be read again, which will also lead to some errors
Summarize in the simplest words:
Dirty read: read uncommitted
Non repeatable reading: inconsistent reading (modification)
Unreal reading: data is created out of nothing (insertion operation)
2. Isolation level of transactions
The isolation level of transactions is the solution to the above problems:
√: possible ×: Will not appear
3. Set isolation level in mybatis
//Read commit, resolve dirty read (read only committed data) session = sqlSessionFactory.openSession(TransactionIsolationLevel.READ_COMMITTED); //Repeatable reading, solve non repeatable reading (lock the data) session = sqlSessionFactory.openSession(TransactionIsolationLevel.REPEATABLE_READ); //Serialization, solve phantom reading, fully serialized reading, low efficiency session = sqlSessionFactory.openSession(TransactionIsolationLevel.SERIALIZABLE);
package org.apache.ibatis.session;
public enum TransactionIsolationLevel {
NONE(0),
READ_COMMITTED(2),
READ_UNCOMMITTED(1),
REPEATABLE_READ(4),
SERIALIZABLE(8);
private final int level;
private TransactionIsolationLevel(int level) {
this.level = level;
}
public int getLevel() {
return this.level;
}
}III Delayed loading strategy
When the associated query is used, it will only be loaded when the data is needed, so lazy loading is required
1. Global configuration
<settings> <setting name="lazyLoadingEnabled" value="true"/> <setting name="aggressiveLazyLoading" value="false"/> </settings>
After the attribute is turned on, we will trigger lazy loading when we get any attribute of the variable. After the attribute is turned off, we will trigger lazy loading only when we trigger the associated attribute
2. Local configuration
On the associated field, you can also specify the loading method by setting fetchType. For an associated attribute, the fetchType priority specified is higher than the global configuration
<resultMap id="lazyLoadTestMap" type="Address" autoMapping="true">
<result column="user_id" property="userId"></result>
<association property="user" column="user_id" javaType="User" fetchType="lazy" select="com.tl.mybatis03.mapper.UserMapper.findById">
</association>
</resultMap>
<select id="lazyLoadTest" parameterType="int" resultMap="lazyLoadTestMap">
select * from address where id = #{id}
</select>IV Development using annotations
1.mybatis common notes
@Insert: add
@Update: implement update
@Delete: implements deletion
@Select: implement query
@Result: implement result set encapsulation
@Results: can be used with @ Result to encapsulate multiple Result sets
@ResultMap: implements encapsulation defined by referencing @ Results
@One: implement one-to-one result set encapsulation
@Many: implement one to many result set encapsulation 2 Implement basic CRUD
public interface IAddressDao {
@Insert("insert into t_address (addr, phone, postcode, user_id) VALUES (#{addr},#{phone},#{postcode},#{userId})")
int insert(Address address);
@Delete("delete from t_address where id = #{id}")
int delete(int id);
@Update("update t_address set addr = #{addr} where id = #{id}")
int update(Address address);
@Select("select * from t_address where id = #{id}")
Address selectById(int id);
}3. Use Result for mapping
How can we map the result set through the @ Results annotation
@Select("select * from t_address where id = #{id}")
@Results(id = "addressRes", value = {
//id = true indicates that this field is the primary key
@Result(id = true, column = "id", property = "id"),
@Result(column = "addr", property = "addr"),
@Result(column = "phone", property = "mobile"),
})
Address selectById(int id);4. Associated query with annotation
1 to 1
@Select("select * from t_address where id = #{id}")
@Results(id = "addressRes", value = {
//id = true indicates that this field is the primary key
@Result(id = true, column = "id", property = "id"),
@Result(column = "addr", property = "addr"),
@Result(column = "phone", property = "mobile"),
@Result(column = "user_id", property = "user",
one = @One(select = "com.tledu.erp.mapper.IUserMapper.selectById", fetchType = FetchType.EAGER))
})
Address selectById(int id);2 1 to many
@Select("select * from t_user where id = #{id}")
@Results(id = "addressRes", value = {
//id = true indicates that this field is the primary key
@Result(id = true, column = "id", property = "id"),
@Result(column = "id", property = "addressList",
many = @Many(select = "com.tledu.erp.mapper.IAddressMapper.listByUserId", fetchType = FetchType.EAGER))
})
User selectById(int id);V cache
1. Introduction
Like most persistence frameworks, Mybatis also provides a caching strategy to reduce the number of queries in the database and improve performance.
The cache in Mybatis is divided into level 1 cache and level 2 cache
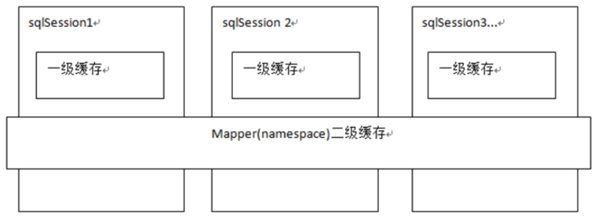
2. L1 cache
The L1 cache is a SqlSession level cache. It exists as long as SqlSession does not have flush or close.
Test:
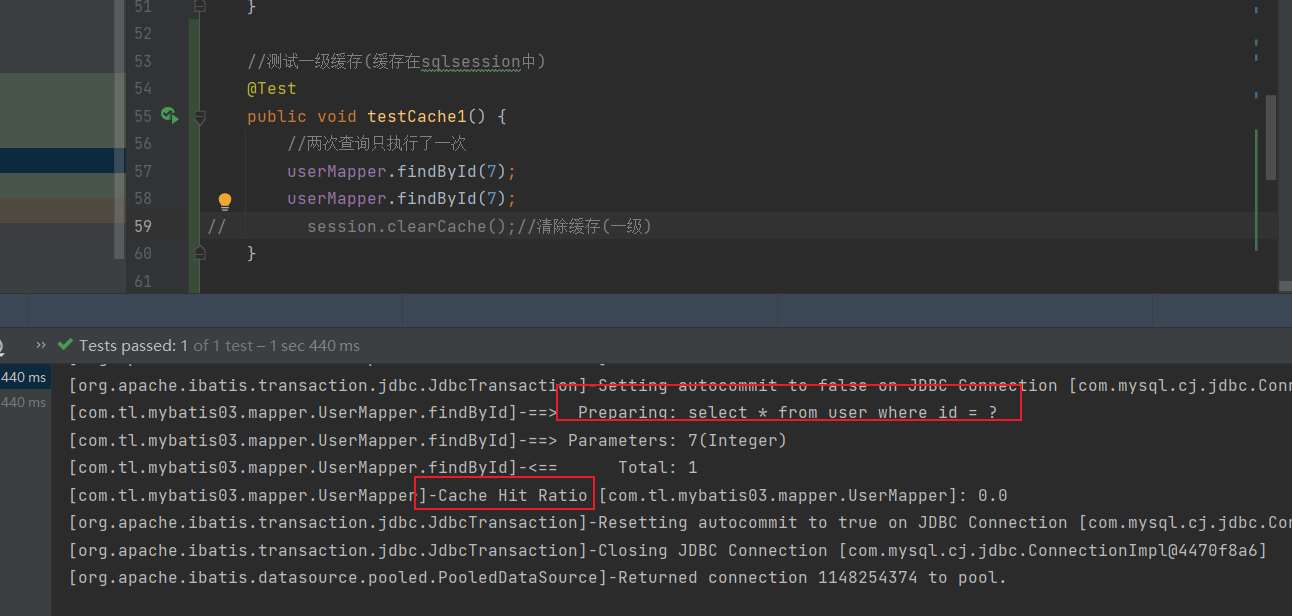
How to clear L1 cache:
session.clearCache();
3. L2 cache
The L2 cache is saved in mapper and can be shared in multiple sqlsessions. It needs to be configured
to configure
Enable L2 cache
<setting name="cacheEnabled" value="true"/>
Configure mapper to support caching
<mapper namespace="com.tledu.erp.mapper.IAddressMapper"> <!-- Enable cache support--> <cache /> </mapper>
useCache = "true" needs to be specified in the query statement
<select id="selectOne" resultMap="addressResultMap" useCache="true">
select *
from t_address
where id = #{id}
</select>Note: when using L2 cache, the cached classes must implement Java io. Serializable interface, which can use serialization to save objects.
4. Summary
- When using L2 cache, you should pay attention to configuring mybatis config Enable L2 cache in XML
- Then use the catch tag in the mapper mapping file to mark on, and add useCache = "true" to the statement to be replaced
- It is used in the mapper's mapping file to represent that the current mapper has L2 cache enabled
- Add useCache = true to the query that needs L2 cache, which means that the current query needs cache
- And the corresponding entity class encapsulating data needs to implement the Serializable interface
- The data to be cached implements the Serialization interface, which means that the data is serializable
- The L2 cache cannot take effect until sqlsession is closed
- When adding, deleting, and modifying, you must execute commit() to persist to the database and clear the L2 cache
- session.clearCache() cannot clear the L2 cache. If you need to clear the L2 cache, you can use sqlsessionfactory getConfiguration(). Getcache ("cache id") clear();
- However, when we execute commit() or close() to close the session in the query statement, the L2 cache will not be emptied
Vi paging
1, Why pagination
When there is a lot of data, the interface that returns a large amount of data in a single request will be very slow.
For queries with a large amount of data, we will use paging queries
2, How to design paging
How many per page
What page is it currently on
Total number of data
Data list
Design paged entity classes based on these properties
@Data
public class PageInfo<T> {
/**
* How many per page
*/
private int pageSize;
/**
* What page is it currently on
*/
private int currentPage;
/**
* Total number of data
*/
private int total;
/**
* Data list
*/
private List<T> list;
// Get offset
public int getOffset() {
return (this.currentPage - 1) * this.pageSize;
}
}3, Realize paging function
Method of creating paging query
/**
* Paging query
*
* @param user query criteria
* @param offset Starting position
* @param pageSize Capacity per page
* @return User list
*/
List<User> page(@Param("user") User user, @Param("offset") int offset, @Param("pageSize") int pageSize);
/**
* Total statistics
*
* @param user query criteria
* @return total
*/
int count(@Param("user") User user);
<select id="page" resultType="User">
select *
from t_user
<where>
<if test="user.nickname != null and user.nickname != ''">
and nickname like concat('%',#{user.nickname},'%')
</if>
<if test="user.username != null and user.username != ''">
and username = #{user.username}
</if>
</where>
limit #{offset},#{pageSize};
</select>
<select id="count" resultType="int">
select count(*)
from t_user
<where>
<if test="user.nickname != null and user.nickname != ''">
and nickname like concat('%',#{user.nickname},'%')
</if>
<if test="user.username != null and user.username != ''">
and username = #{user.username}
</if>
</where>
</select>test
@Test
public void page(){
PageInfo<User> pageInfo = new PageInfo<User>();
pageInfo.setCurrentPage(1);
pageInfo.setPageSize(10);
User user = new User();
user.setNickname("Shang Yun");
// Add filter criteria to filter according to nickname or username
List<User> list = userMapper.page(user,pageInfo.getOffset(),pageInfo.getPageSize());
pageInfo.setList(list);
pageInfo.setTotal(userMapper.count(user));
System.out.println(pageInfo);
}4, Paging plug-in
https://pagehelper.github.io/
1. Introduce dependency
<dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper</artifactId> <version>5.2.0</version> </dependency>
2. Configure interceptor
Add a plug-in in the configuration file of mybatis
<!-- plugins The position in the configuration file must meet the requirements, otherwise an error will be reported, in the following order: properties?, settings?, typeAliases?, typeHandlers?, objectFactory?,objectWrapperFactory?, plugins?, environments?, databaseIdProvider?, mappers? --> <plugins> <!-- com.github.pagehelper by PageHelper Package name of class --> <plugin interceptor="com.github.pagehelper.PageInterceptor"> <!-- Use the following method to configure parameters. All parameters will be described later --> <property name="param1" value="value1"/> </plugin> </plugins>
3. Configure plug-ins
4. Use plug-ins
@Test
public void testList() throws IOException {
SqlSession session = MybatisUtils.openSession();
User condition = new User();
// For the paging tool provided in the plug-in, execute PageHelper before querying Startpage (the current number of pages and the capacity of each page) will cause lazy loading failure when using the tool
// With this operation, the plug-in will splice the limit limit in the sql statement and count the total number
PageHelper.startPage(1,5);
List<User> users = session.getMapper(IUserMapper.class).list(condition);
// Get the results through pageInfo Of() to obtain pageInfo
com.github.pagehelper.PageInfo<User> list = com.github.pagehelper.PageInfo.of(users);
System.out.println(users);
}