0. Introduce project objectives
- The project is based on the data set crawling task required for small language transfer learning in Southeast Asia, and the goal is to align the bilingual titles and abstracts of small language literature journals.
- The first step is to study the Thai data set. The target literature and journal websites are: http://cuir.car.chula.ac.th/simple-search?query=


- The goal is to crawl these information. For each paper record, those framed are to crawl (Thai title, English title, Thai abstract, English abstract and degree type), and generate a tsv file. The column name includes serial number, Thai title, English title, Thai abstract, English abstract and degree type
1. Website analysis
1.1 finding the uri law of documents
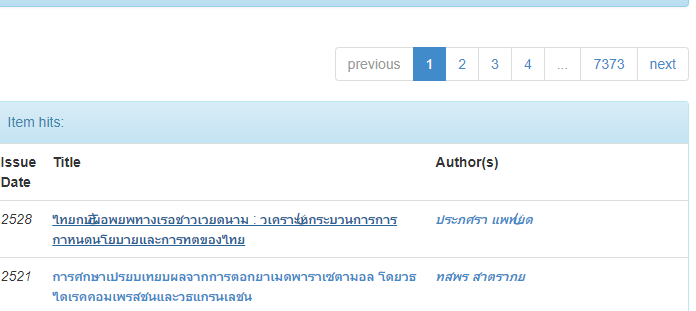
- This is a collection of all the documents. We first select one randomly and find that the address bar is very complex
# ps: [] indicates the difference between connections
# First document
http://cuir.car.chula.ac.th/handle/123456789/
72181?
src=%2Fsimple-search%3Fquery%3D%26filter_field_1%3Dtype%26filter_type_1%3Dequals%
26filter_value_1%3DThesis%26sort_by%3Ddc.date.issued_dt%26order%3Ddesc%26rpp
%3D10%26etal%3D0%26start%3D0%26brw_total%3D64845%26brw_pos%
3D0&query=
# Second document
http://cuir.car.chula.ac.th/handle/123456789/
71235?
src=%2Fsimple-search%3Fquery%3D%26filter_field_1%3Dtype%26filter_type_1%3Dequals%
26filter_value_1%3DThesis%26sort_by%3Ddc.date.issued_dt%26order%3Ddesc%26rpp%
3D10%26etal%3D0%26start%3D0%26brw_total%3D64845%26brw_pos%
3D1&query=
# Third document
http://cuir.car.chula.ac.th/handle/123456789/
71233?
src=%2Fsimple-search%3Fquery%3D%26filter_field_1%3Dtype%26filter_type_1%3Dequals%
26filter_value_1%3DThesis%26sort_by%3Ddc.date.issued_dt%26order%3Ddesc%
26rpp%3D10%26etal%3D0%26start%3D0%26brw_total%3D64845%26brw_pos%
3D2&query=
# Last document
http://cuir.car.chula.ac.th/handle/123456789/
27447?src=%2Fsimple-search%3Fquery%3D%26filter_field_1%3Dtype%26filter_type_1%3Dequals%
26filter_value_1%3DThesis%26sort_by%3Ddc.date.issued_dt%26order%3Ddesc%
26rpp%3D10%26etal%3D0%26start%3D64840%26brw_total%3D64845%26brw_pos%
3D64844&query=
# However, after several comparisons, we found that the differences of each document lie in these two places:
http://cuir.car.chula.ac.th/handle/123456789/[72181]?
src=%2Fsimple-search%3Fquery%3D%26brw_total%3D73726%
26brw_pos%3D[0]&query=
# And other places are the same. Is this the law? Let's not rush to a conclusion,
# Because this page has a return to list, I suspect it is a display page rather than the physical path where the paper is really stored.
- We look down and find an attribute called uri
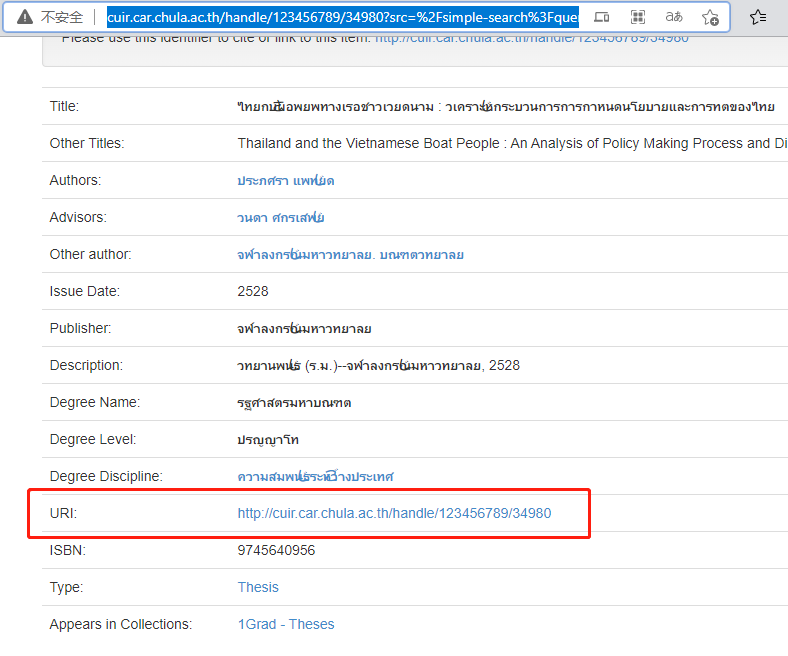
- After clicking, you enter the same page, and the address bar has been changed
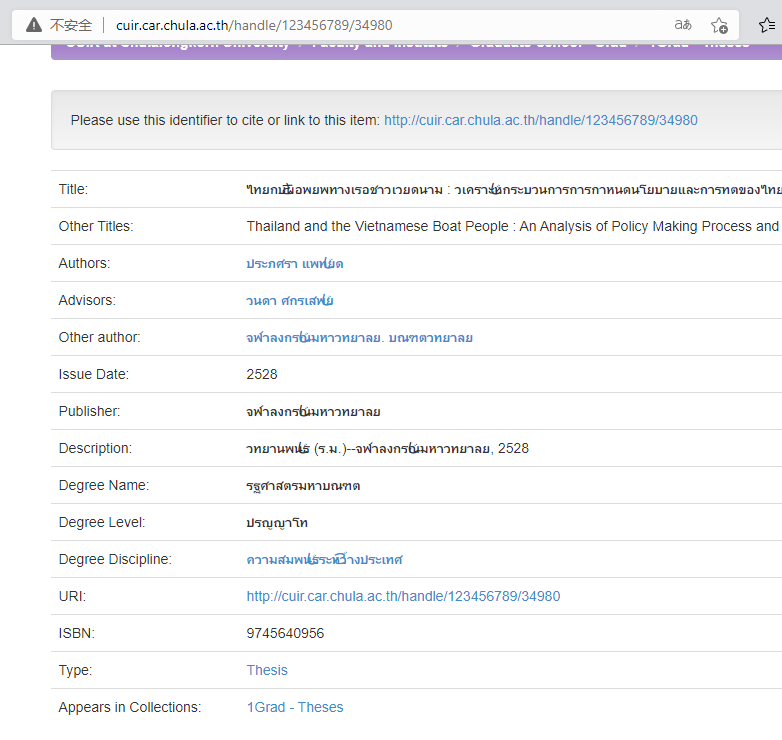
- The rule of this address bar is no easier to find than the one just now?
Part I: http://cuir.car.chula.ac.th/handle/123456789/72181
Part II: http://cuir.car.chula.ac.th/handle/123456789/71235
Part III: http://cuir.car.chula.ac.th/handle/123456789/71233
Part IV: http://cuir.car.chula.ac.th/handle/123456789/73078
Part V: http://cuir.car.chula.ac.th/handle/123456789/69502
Part VI: http://cuir.car.chula.ac.th/handle/123456789/71254
Part 20: http://cuir.car.chula.ac.th/handle/123456789/77274
Part 60: http://cuir.car.chula.ac.th/handle/123456789/75905
Last article: http://cuir.car.chula.ac.th/handle/123456789/27447
testing:
http://cuir.car.chula.ac.th/handle/123456789/55
http://cuir.car.chula.ac.th/handle/123456789/77960
# Literature exists from 55 to 77960
- By shortening the scope through dichotomy, we found that only 55-77960 documents were available [as of December 10, 2021]
- But this rule is already very useful. Just give a loop.
1.2 search for laws
- We open f12 view elements for this page
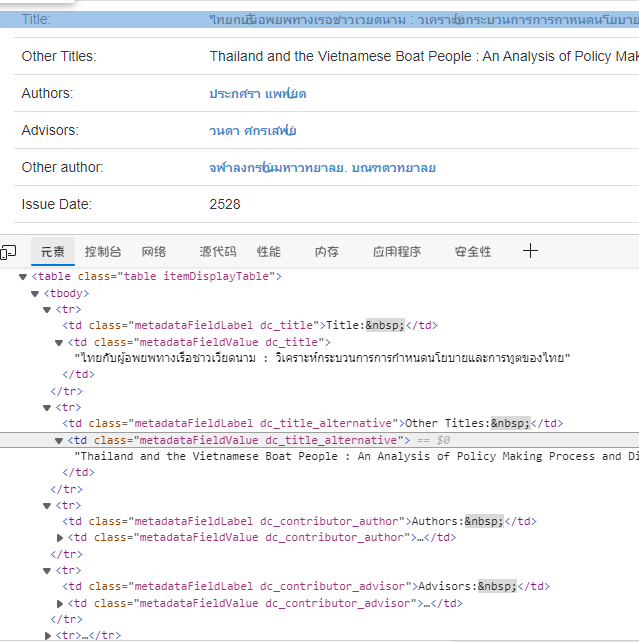
- It is not difficult to find that this website is easy to crawl, and the content is displayed in td. Use the find method of beatifulsoup: soup find(class_=“metadataFieldValue dc_title”). String to locate the string. Learn about the use of beatifulsoup by yourself. I will provide comments for the following code.
- The theory holds, start writing code
2. Crawling operation
2.1 multi thread access and crawling
- Note that there are 7w + URIs in total. What we need is to access them again and again. The efficiency is too low. We should make full use of the advantages of cpu multi-core to realize multithreading. Of course, we should not divide too many threads. If too many threads can not be carried by the cpu, the efficiency will be reduced, because we still need to queue to obtain cpu time slices. We use three threads that are a little more secure.
- The code is provided directly below. Follow the code comments from top to bottom.
# First, import all the packages we need
import requests
import sys
import io
import threading
from bs4 import BeautifulSoup
# This sentence can be copied and pasted directly. It is to deal with the problem of garbled code when reading and writing text in python io stream. Unify utf8 [utf8 has Thai collection], otherwise it will be affected by gbk
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
# Create three thread classes to make three function calls. This is the usage of threading module. You can learn it by yourself and come back
# Note that this is a class instead of a method. You can just copy it. The key point is a run method in class,
# The run method needs to call our execution function. For example, what I call here is the function processDocument that I want to perform the crawling function later
class thread1(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Start thread:" + self.name)
# 5526023 indicates the range we want to crawl, and 1 indicates that this is the first thread. See the following function parameters for details
processDocument(55,26023,1)
print ("Exit thread:" + self.name)
class thread2(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Start thread:" + self.name)
processDocument(26023,51991,2)
print ("Exit thread:" + self.name)
class thread3(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Start thread:" + self.name)
processDocument(51991,77961,3)
print ("Exit thread:" + self.name)
# For crawling functions, I only annotate one. The latter two are duplicate functions that can be reused directly. However, pay attention to the different num formal parameters, thread_no indicates the sequence number of the current thread
# num1 and num2 refer to the range of serial numbers we want to crawl. After analyzing the website, we get the valid serial number of the document is 55-77960,
# Then we divide this batch of documents into three threads, namely 5526023 | 2602351991 | 5199177961.
# Because the range function is left closed and right open, we need to add a 77961
def processDocument(num1,num2,thread_no):
for serial_num in range(num1,num2):
# These two variables can be added by yourself, and then you can print out and view the results by yourself
fail_count = 0
success_count = 0
document_URL = 'http://cuir.car.chula.ac.th/handle/123456789/'+str(serial_num)
try:
# try except must be used here, otherwise it will be terminated due to some exceptions caused by too many crawling connections.
response = requests.get(document_URL, timeout=2)
# Obtain the status code. When the status code is 200, the access is successful
status = response.status_code
# If the access is successful, the file is written
if status == 200:
# print(document_URL)
success_count += 1
# After opening the file with, append the character encoding='utf-8 'in a mode
# As a result, we can see multiple files
with open("uri"+str(thread_no)+".txt","a") as file:
file.write(document_URL+"\n")
except:
fail_count += 1
print(success_count)
# Create thread objects. thread1, thread2 and thread3 are the class names just defined
thread_1 = thread1(1, "Thread-1", 1)
thread_2 = thread2(2, "Thread-2", 2)
thread_3 = thread3(3, "Thread-3", 3)
# Start the thread and automatically call the run function
thread_1.start()
thread_2.start()
thread_3.start()
- After crawling, it is almost as long as this. Of course, what we need is not these URIs, but the corresponding contents of URIs. Here is just a brief view of the results, so crawling can be stopped in a while.
2.2 html processing
- We use the beatifulsoup module. Please learn by yourself. After pip downloads the module, it can be imported and used directly.
def processDocument(num1,num2,thread_no):
for serial_num in range(num1,num2):
# These two variables can be added by yourself, and then you can print out and view the results by yourself
fail_count = 0
success_count = 0
document_URL = 'http://cuir.car.chula.ac.th/handle/123456789/'+str(serial_num)
try:
# try except must be used here, otherwise it will be terminated due to some exceptions caused by too many crawling connections.
response = requests.get(document_URL, timeout=2)
# Obtain the status code. When the status code is 200, the access is successful
status = response.status_code
# If the access is successful, the file is written
if status == 200:
# print(document_URL)
success_count += 1
# If it is successful, we will not write and view it. We will directly pass the html document of the successful website
# It's OK to write txt here, but our final goal is txt file
# response.text is the html code corresponding to the uri website, which can be printed and viewed by yourself
processSoup('Dataset 1.tsv',response.text)
except:
fail_count += 1
print(success_count)
# With a uri, we can automatically access it continuously, and then Download html to accurately locate and obtain the element content
# We define a function to handle html
# filename is the file where we want to store the results, html_text is the html text we got
def processSoup(filename,html_text):
# The creation of the soup object requires an html text and a parser. We can use the lxml provided by default
soup = BeautifulSoup(html_text,'lxml')
# The way to get content in the following fields is similar. Check the soup Find() function. We only use the two fields of find function here,
# soup.find('tag name ', class_ =' class name ') so that I can uniquely locate the content I want,
# But what we need is the string in the middle of the label, not including the label, so we still need to do it String operation. As for the content in which category, you can go to the web page f12 to view the elements.
# ps: why class_? Instead of class =? Because class is the keyword of python, soup changes a keyword to represent the class of html in order to distinguish.
title = soup.find('td',class_='metadataFieldValue dc_title').string
other_title = soup.find('td',class_='metadataFieldValue dc_title_alternative').string
abstract = soup.find('td',class_='metadataFieldValue dc_description_abstract').string
other_abstract = soup.find('td',class_='metadataFieldValue dc_description_abstractalternative').string
degree_discipline = soup.find('td',class_='metadataFieldValue dc_degree_discipline').a.string
# Generally speaking, the title of a web page is the Thai title, other_title is the English title, but in the process of crawling, we found that the English title comes first, and the other_title is the Thai title, so we need to add a filtering method
thai_title = title
en_title = other_title
thai_abstract = abstract
en_abstract = other_abstract
# Filter method to ensure that the title is the Thai title and other_title is the English title
for i in range(10):
# Provide a random number
index = random.randint(1,20)
# Simply exclude stop words. If our random characters are stop words, we provide random numbers again
if(thai_title[index] == ',' or thai_title[index] == ' ' or thai_title[index] == '.' or thai_title[index] == '(' or thai_title[index] == ')' or thai_title[index] == '?' or thai_title[index] == '!'):
continue
else:
# If the character we randomly find is not a stop word, judge whether it is English. Note that the case should also be considered. The ascii of lowercase English is 97-122 and the uppercase is 65-80. Some other ascii in the middle can be ignored
if(ord(title[1])>=65 and ord(title[1])<=122):
# If the character is in English, the title is a special case, that is, the title is an English title,
# other_title is the Thai title. Let's make a simple conversion
thai_title = other_title
en_title = title
thai_abstract = other_abstract
en_abstract = abstract
break
# Write the crawled fields to the file
with open(filename,'a',encoding='utf-8') as file:
file.write(thai_title+",")
file.write(en_title+",")
file.write(thai_abstract+",")
file.write(en_abstract+",")
file.write(degree_discipline+"\n")
return
2.3 tsv conversion
- Because our target is a tsv file, that is, the separator is the tab key. We chose to use python's own csv package for rewriting
# Here you need to add a parameter newline = '', otherwise there will be strange line breaks
with open(filename,'a',encoding='utf-8',newline='') as file:
tsv_w = csv.writer(file,delimiter='\t')
#tsv_w.writerow(['thai_title','en_title','thai_abstract','en_abstract','degree_discipline'])
tsv_w.writerow([thai_title,en_title,thai_abstract,en_abstract,degree_discipline])
#file.write(thai_title+",")
#file.write(en_title+",")
#file.write(thai_abstract+",")
#file.write(en_abstract+",")
#file.write(degree_discipline+"\n")
3. Complete code
# First, import all the packages we need
import requests
import sys
import io
import threading
from bs4 import BeautifulSoup
# This sentence can be copied and pasted directly. It is to deal with the problem of garbled code when reading and writing text in python io stream. Unify utf8 [utf8 has Thai collection], otherwise it will be affected by gbk
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
# Create three thread classes to make three function calls. This is the usage of threading module. You can learn it by yourself and come back
# Note that this is a class instead of a method. You can just copy it. The key point is a run method in class,
# The run method needs to call our execution function. For example, what I call here is the function processDocument that I want to perform the crawling function later
class thread1(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Start thread:" + self.name)
# 5526023 indicates the range we want to crawl, and 1 indicates that this is the first thread. See the following function parameters for details
processDocument(55,26023,1)
print ("Exit thread:" + self.name)
class thread2(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Start thread:" + self.name)
processDocument(26023,51991,2)
print ("Exit thread:" + self.name)
class thread3(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Start thread:" + self.name)
processDocument(51991,77961,3)
print ("Exit thread:" + self.name)
# For crawling functions, I only annotate one. The latter two are duplicate functions that can be reused directly. However, pay attention to the different num formal parameters, thread_no indicates the sequence number of the current thread
# num1 and num2 refer to the range of serial numbers we want to crawl. After analyzing the website, we get the valid serial number of the document is 55-77960,
# Then we divide this batch of documents into three threads, namely 5526023 | 2602351991 | 5199177961.
# Because the range function is left closed and right open, we need to add a 77961
def processDocument(num1,num2,thread_no):
for serial_num in range(num1,num2):
# These two variables can be added by yourself, and then you can print out and view the results by yourself
fail_count = 0
success_count = 0
document_URL = 'http://cuir.car.chula.ac.th/handle/123456789/'+str(serial_num)
try:
# try except must be used here, otherwise it will be terminated due to some exceptions caused by too many crawling connections.
response = requests.get(document_URL, timeout=2)
# Obtain the status code. When the status code is 200, the access is successful
status = response.status_code
# If the access is successful, the file is written
if status == 200:
success_count += 1
processSoup('data set'+thread_no+'.tsv',response.text)
except:
fail_count += 1
print(success_count)
# With a uri, we can automatically access it continuously, and then Download html to accurately locate and obtain the element content
# We define a function to handle html
# filename is the file where we want to store the results, html_text is the html text we got
def processSoup(filename,html_text):
# The creation of the soup object requires an html text and a parser. We can use the lxml provided by default
soup = BeautifulSoup(html_text,'lxml')
# The way to get content in the following fields is similar. Check the soup Find() function. We only use the two fields of find function here,
# soup.find('tag name ', class_ =' class name ') so that I can uniquely locate the content I want,
# But what we need is the string in the middle of the label, not including the label, so we still need to do it String operation. As for the content in which category, you can go to the web page f12 to view the elements.
# ps: why class_? Instead of class =? Because class is the keyword of python, soup changes a keyword to represent the class of html in order to distinguish.
title = soup.find('td',class_='metadataFieldValue dc_title').string
other_title = soup.find('td',class_='metadataFieldValue dc_title_alternative').string
abstract = soup.find('td',class_='metadataFieldValue dc_description_abstract').string
other_abstract = soup.find('td',class_='metadataFieldValue dc_description_abstractalternative').string
degree_discipline = soup.find('td',class_='metadataFieldValue dc_degree_discipline').a.string
# Generally speaking, the title of a web page is the Thai title, other_title is the English title, but in the process of crawling, we found that the English title comes first, and the other_title is the Thai title, so we need to add a filtering method
thai_title = title
en_title = other_title
thai_abstract = abstract
en_abstract = other_abstract
# Filter method to ensure that the title is the Thai title and other_title is the English title
for i in range(10):
# Provide a random number
index = random.randint(1,20)
# Simply exclude stop words. If our random characters are stop words, we provide random numbers again
if(thai_title[index] == ',' or thai_title[index] == ' ' or thai_title[index] == '.' or thai_title[index] == '(' or thai_title[index] == ')' or thai_title[index] == '?' or thai_title[index] == '!'):
continue
else:
# If the character we randomly find is not a stop word, judge whether it is English. Note that the case should also be considered. The ascii of lowercase English is 97-122 and the uppercase is 65-80. Some other ascii in the middle can be ignored
if(ord(title[1])>=65 and ord(title[1])<=122):
# If the character is in English, the title is a special case, that is, the title is an English title,
# other_title is the Thai title. Let's make a simple conversion
thai_title = other_title
en_title = title
thai_abstract = other_abstract
en_abstract = abstract
break
# Write the crawled fields to the file
# Here you need to add a parameter newline = '', otherwise there will be strange line breaks
with open(filename,'a',encoding='utf-8',newline='') as file:
tsv_w = csv.writer(file,delimiter='\t')
#tsv_w.writerow(['thai_title','en_title','thai_abstract','en_abstract','degree_discipline'])
tsv_w.writerow([thai_title,en_title,thai_abstract,en_abstract,degree_discipline])
#file.write(thai_title+",")
#file.write(en_title+",")
#file.write(thai_abstract+",")
#file.write(en_abstract+",")
#file.write(degree_discipline+"\n")
return
# Create thread objects. thread1, thread2 and thread3 are the class names just defined
thread_1 = thread1(1, "Thread-1", 1)
thread_2 = thread2(2, "Thread-2", 2)
thread_3 = thread3(3, "Thread-3", 3)
# Start the thread and automatically call the run function
thread_1.start()
thread_2.start()
thread_3.start()
4. Result display

- There will be three such files in total. Direct head to tail splicing can be used as an aligned data set for migration learning