Tensor
detach()
This is used when you want to freeze some parameters in the network model and do not participate in training. And it will return a new tensor.
y = x.detach()
In this case, y and X share the same memory, that is, one will change and the other will change. At this point, X can still take its derivative normally. So x = x.detach() is often used.
torch.cat and torch stack
torch.cat will not add new dimensions. Are the original dimensions or several dimensions
torch.stack will add a new dimension, making the tensor of N dimension become n+1 dimension
x1_torch = torch.zeros(3,1) y1_torch = torch.ones(3,1) xy_1 = torch.cat([x1_torch, y1_torch], dim = 1) xy_2 = torch.stack([x1_torch, y1_torch], dim=1)
xy_ Shape of 1 = (3,2)
xy_1 = tensor(
[[0., 1.],
[0., 1.],
[0., 1.]])
xy_ Shape of 2 = (3,2,1)
xy_2 = tensor(
[ [[0.],[1.]],
[[0.],[1.]],
[[0.], [1.]] ])
Matrix operation
x = torch.Tensor([[1,2],[3,4]])
Matrix multiplication follows the matrix algorithm:
y1 = x @ x.T y2 = x.matmul(x.T)
y1=y2=tensor(
[[ 5., 11.],
[11., 25.]])
Multiplication between elements:
y3 = x * x.T y4 = x.mul(x.T)
y3 = y4 = tensor(
[[ 1., 4.],
[ 9., 16.]])
Data exchange with numpy:
Tensor --> numpy
x_numpy = x_torch.numpy()
numpy --> Tensor
x_torch = torch.from_numpy(x_numpy)
However, it should be noted that the two share the underlying storage, so changing one will affect the other. If you want to break the relationship, you can add copy() after numpy data.
data processing
Datasets & DataLoaders
These two classes are the key to pytorch's data processing
- torch.utils.data.DataLoader is mainly used for training iterators, which is relatively simple to use
-
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
- torch.utils.data.Dataset is the key class of its own dataset. The most important thing is that the inherited class must be overloaded__ init__,__ len__,__ getitem__ These three functions. Common templates are as follows:
-
class Dataset_name(Dataset): def __init__(self, flag='train'): assert flag in ['train', 'test', 'valid'] self.flag = flag self.__load_data__() def __getitem__(self, index): pass def __len__(self): pass def __load_data__(self, csv_paths: list): pass print( "train_X.shape:{}\ntrain_Y.shape:{}\nvalid_X.shape:{}\nvalid_Y.shape:{}\n" .format(self.train_X.shape, self.train_Y.shape, self.valid_X.shape, self.valid_Y.shape))
`
Torchvision.transform
Before training, the data basically needs data enhancement, various clipping and other data transformation, so this module is essential.
torchvision.transforms.Compose
This is a class whose main function is to aggregate all data processing into one operation
- Input parameter: the element it receives is torchvision A list of methods in transform
-
T = transforms.Compose([transforms.CenterCrop(10), transforms.ToTensor()])
- Usage: just pass in the picture directly to the instance of this class. The format of the picture needs to be PIL or Tensor. If it is opencv, you need to put the ToTensor() method first. The source code of its call definition is:
-
def __call__(self, img): for t in self.transforms: img = t(img) return img - This class cannot be used to transfer the code of the moving end. If the moving end is transferred, it needs to be replaced with the following, and the output must only be Tensor type.
transforms = torch.nn.Sequential( transforms.CenterCrop(10), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)), ) scripted_transforms = torch.jit.script(transforms)
torchvision.transforms.ToTensor
Because the reading of pictures is generally divided into opencv and PIL, but they need to be converted to tensor or mutual conversion. The storage method in opencv is (h,w,c), but it is generally stored in tensor as (c,h,w), and PIL is also a special format; But all this can be done with one button of ToTensor.
#img_cv.shape = (448, 800, 3) #img_pil.size = (800, 448) cv2tensor = torchvision.transforms.ToTensor()(img_cv) #cv2tensor.shape : torch.Size([3, 448, 800]) pil2tensor = torchvision.transforms.ToTensor()(img_pil) #pil2tensor.shape : torch.Size([3, 448, 800])
build model
Building models include:
- Build a model, which in turn includes:
- Define a separate network layer, i.e__ init__ Function;
- Put them together to determine the execution order of each layer, that is, the forward function.
- Weight initialization.
torch.nn
PyTorch puts all classes related to the construction of deep learning model in torch NN in this sub module.
According to the function classification of the class, the common parts are as follows:
- Model operation layer:
- Convolution layer: torch nn. Conv2d
- Pool layer: torch nn. MaxPool2d
- Linear layer: torch nn. Linear
- wait
- Container class, such as torch nn. Module
- The tool function class Utilities is rarely used and can be supplemented in the future.
And in torch NN also has a sub module torch nn. Functional, basically torch NN, such as torch nn. The corresponding function of relu is torch nn. functional. Relu has the same function and different operation efficiency, but there are also great differences:
- Call torch in different ways nn. XXX is a class, which must be instantiated before use, and torch nn. Functional is a function. All parameters must be passed in before use. If it is a convolution layer, the weight needs to be passed in.
inputs = torch.rand(64, 3, 244, 244) conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1) out = conv(inputs) weight = torch.rand(64,3,3,3) bias = torch.rand(64) out = nn.functional.conv2d(inputs, weight, bias, padding=1)
- nn.Xxx inherits from NN Module, which can work well with NN Sequential is used in combination with NN functional. XXX cannot communicate with NN Sequential is used in combination.
- nn.Xxx is NN functional. Class encapsulation of XXX, and NN XXX all inherited from a common ancestor NN Module. This leads to NN XXX has NN functional. In addition to the XXX function, NN is attached internally Module related properties and methods, such as train(), eval(),load_state_dict, state_dict et al. So try to choose torch NN to build the model.
Because of the above differences, PyTorch officially recommends:
NN is adopted for those with learning parameters (e.g., conv2d, linear, batch_norm) XXX mode;
nn.functional.xxx or nn.Xxx is used for those without learning parameters (e.g., maxpool, loss function, activation function), etc. according to personal choice. This method is required if some layer parameters are to be shared.
But for dropout, I strongly recommend using NN XXX mode, because generally, dropout is performed only in the training stage, but not in the eval stage. Use NN Define dropout in XXX mode, and call model After eval(), all dropout layer s in the model are closed, but NN function. Define dropout in dropout mode, and call model Dropout cannot be closed after eval().
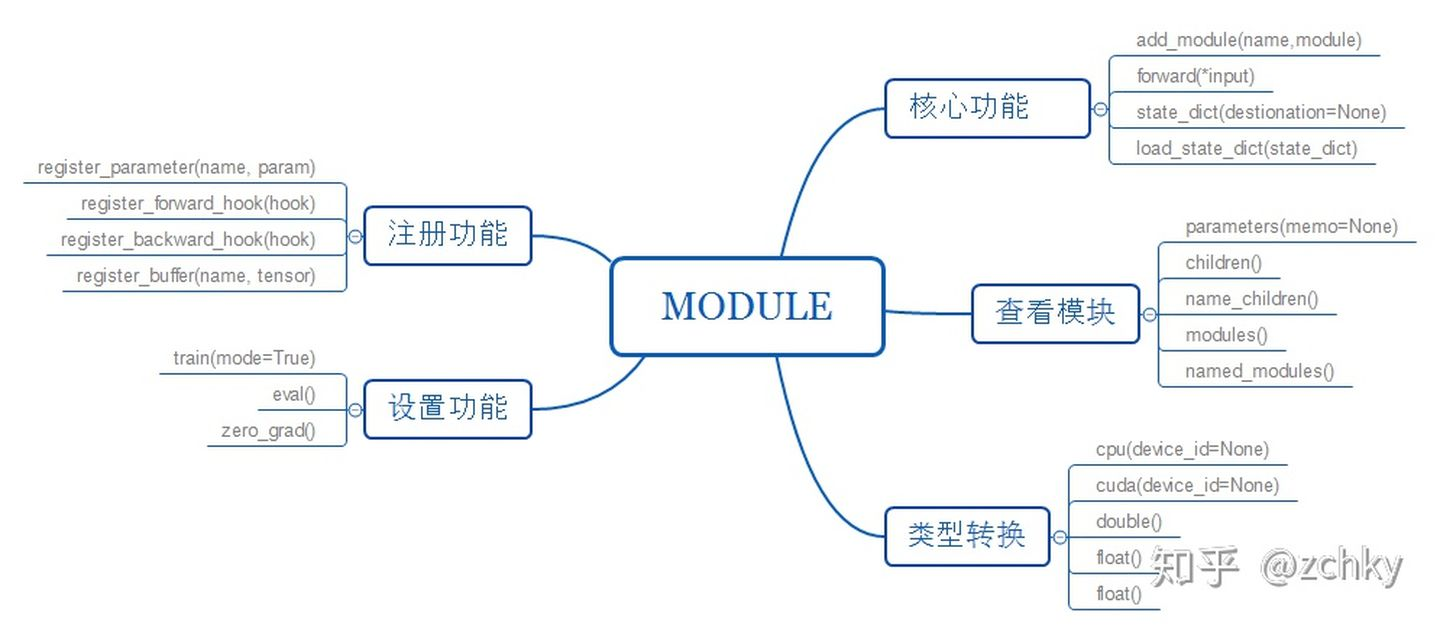
nn.Module
All custom neural networks should inherit torch nn. Module. Define a separate network layer and implement it in init function. Splice the defined network layers together and implement it in forward function. Inherited NN Moudle's model class has two important functions: parameters stores the weight of the model; modules stores the structure of the model.
Function diagram:
Inheritance diagram:
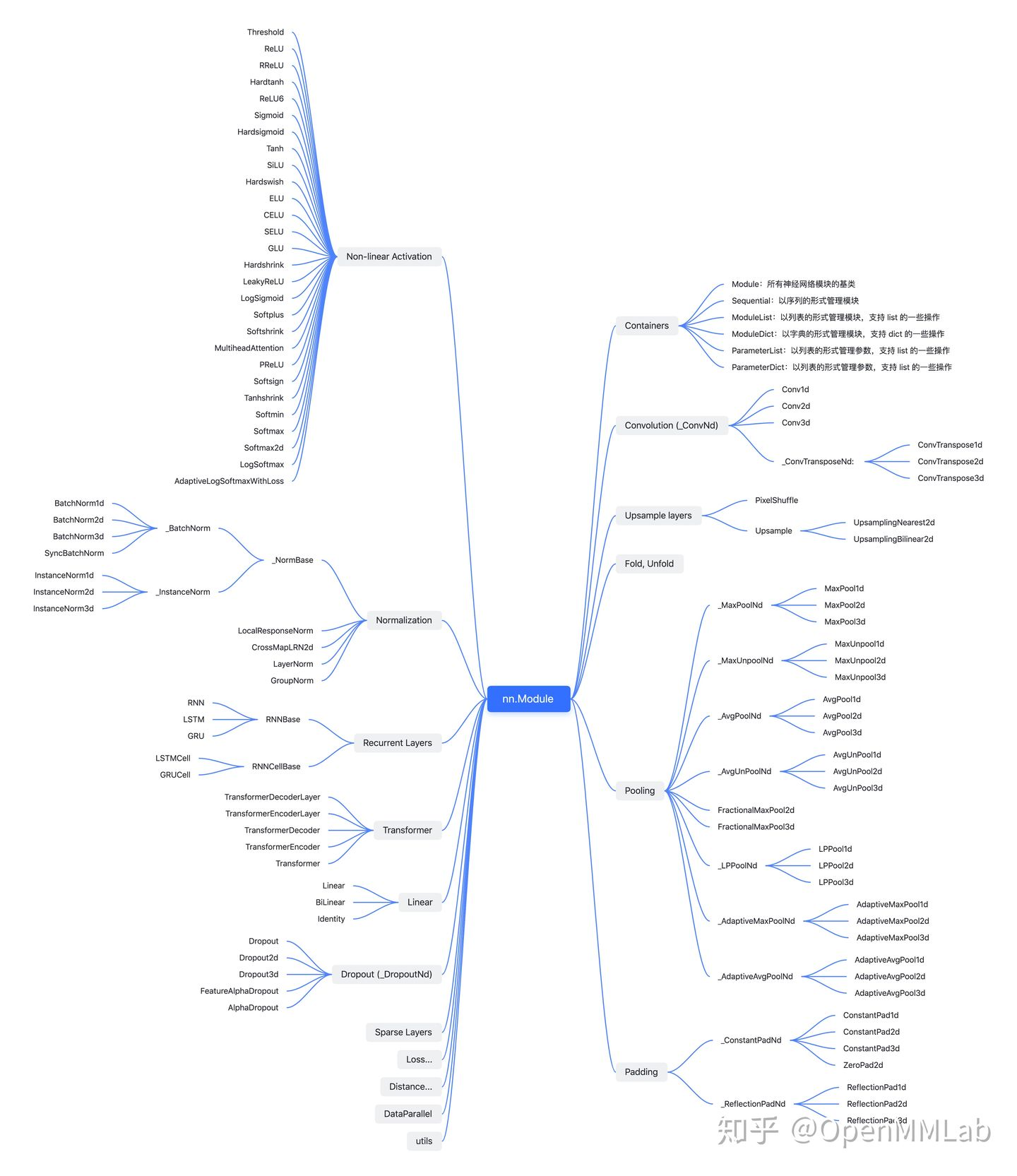
3 auxiliary tools for modeling
nn.Sequential
This is a sequence container, which can be placed outside the model to build a model alone or inside the model to become a layer of the model.
# Become a single model
model1 = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Become part of the model
class LeNetSequential(nn.Module):
def __init__(self, classes):
super(LeNetSequential, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes),)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
If it is placed in the model, the model still needs init and forward functions.
The layer of the model constructed in this way has no name:
>>> model2 = nn.Sequential( ... nn.Conv2d(1,20,5), ... nn.ReLU(), ... nn.Conv2d(20,64,5), ... nn.ReLU() ... ) >>> model2 Sequential( (0): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1)) (1): ReLU() (2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1)) (3): ReLU() )
In order to distinguish different layers, we can use the OrderedDict function in collections:
>>> from collections import OrderedDict
>>> model3 = nn.Sequential(OrderedDict([
... ('conv1', nn.Conv2d(1,20,5)),
... ('relu1', nn.ReLU()),
... ('conv2', nn.Conv2d(20,64,5)),
... ('relu2', nn.ReLU())
... ]))
>>> model3
Sequential(
(conv1): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
(relu1): ReLU()
(conv2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
(relu2): ReLU()
)
torch.nn.ModuleList
The network layer is stored in a list. The list generation method can be used to quickly generate the network. The generated network layer can be indexed and has the list methods append, extend or insert. Improve the efficiency of building models.
>>> class MyModule(nn.Module):
... def __init__(self):
... super(MyModule, self).__init__()
... self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])
... self.linears.append(nn.Linear(10, 1)) # append
... def forward(self, x):
... for i, l in enumerate(self.linears):
... x = self.linears[i // 2](x) + l(x)
... return x
>>> myModeul = MyModule()
>>> myModeul
MyModule(
(linears): ModuleList(
(0): Linear(in_features=10, out_features=10, bias=True)
(1): Linear(in_features=10, out_features=10, bias=True)
(2): Linear(in_features=10, out_features=10, bias=True)
(3): Linear(in_features=10, out_features=10, bias=True)
(4): Linear(in_features=10, out_features=10, bias=True)
(5): Linear(in_features=10, out_features=10, bias=True)
(6): Linear(in_features=10, out_features=10, bias=True)
(7): Linear(in_features=10, out_features=10, bias=True)
(8): Linear(in_features=10, out_features=10, bias=True)
(9): Linear(in_features=10, out_features=10, bias=True)
(10): Linear(in_features=10, out_features=1, bias=True) # append into the layer
)
)
torch.nn.ModuleDict
This function is the same as torch nn. The behavior of sequential (ordereddict (...)) is very similar, and it has the methods of keys, values, items, pop, update and other dictionaries:
>>> class MyDictDense(nn.Module):
... def __init__(self):
... super(MyDictDense, self).__init__()
... self.params = nn.ModuleDict({
... 'linear1': nn.Linear(512, 128),
... 'linear2': nn.Linear(128, 32)
... })
... self.params.update({'linear3': nn.Linear(32, 10)}) # Add layer
... def forward(self, x, choice='linear1'):
... return torch.mm(x, self.params[choice])
>>> net = MyDictDense()
>>> print(net)
MyDictDense(
(params): ModuleDict(
(linear1): Linear(in_features=512, out_features=128, bias=True)
(linear2): Linear(in_features=128, out_features=32, bias=True)
(linear3): Linear(in_features=32, out_features=10, bias=True)
)
)
>>> print(net.params.keys())
odict_keys(['linear1', 'linear2', 'linear3'])
>>> print(net.params.items())
odict_items([('linear1', Linear(in_features=512, out_features=128, bias=True)), ('linear2', Linear(in_features=128, out_features=32, bias=True)), ('linear3', Linear(in_features=32, out_features=10, bias=True))])