Chapter 1 Introduction to SQL
1.1. What is sql
- SQL: Structure Query Language. (Structured Query Language), operate the database through SQL (operation database, operation table, operation data)
- SQL was determined as the American Standard of relational database language by American National Bureau of standards (ANSI), and later adopted as the international standard of relational database language by international standards organization (ISO)
- All database manufacturers (MySql,oracle,sql server) support the ISO SQL standard.
- Each database manufacturer has made its own expansion on the basis of the standard. Each database has its own specific syntax
1.2 classification of sql
- Data Definition Language (DDL) such as operation database and operation table
- Data Manipulation Language(DML), such as adding, deleting and modifying records in a table
- Data Query Language(DQL data query language), such as query operations on data in tables
- Data Control Language(DCL), such as setting of user permissions
1.3 syntax specification and requirements of MySQL
(1) The sql syntax of mysql is not case sensitive
MySQL's keywords and function names are not case sensitive, but whether the data values are case sensitive is related to the character set and proofreading rules.
ci (case insensitive), cs (case sensitive), _bin (binary, that is, the comparison is based on the value of character encoding, independent of language, case sensitive)
(2) When naming: try to use 26 English letters in case, numbers 0-9, underline, and do not use other symbols user_id
(3) It is recommended not to use mysql keywords as table names and field names. If you use them carelessly, please use ` (floating sign) in the SQL statement
(4) Do not include spaces between database, table name, field name and other object names
(5) In the same mysql software, the database cannot have the same name, the table cannot have the same name in the same database, and the field cannot have the same name in the same table
(6) Punctuation:
- Must be paired
- Half angle input mode must be in English
- String and date types can use single quotation marks'
- The column alias can use double quotation marks' ', and do not use double quotation marks to alias the table name. Alias can be omitted
- If the alias of the column does not contain spaces, double quotes can be omitted. If there are spaces, double quotes cannot be omitted.
(7) How to add comments in SQL scripts
- Single line note: # note content
- Single line comment: – space comment content, where – the following space must have
- Multiline comment: / comment content/
#The following two sentences are the same, case insensitive
show databases;
SHOW DATABASES;
#Create table
#create table student info(...); #The table name is incorrect because there are spaces in the table name
create table student_info(...);
#Where name uses ` ` floating sign, because name is the same as predefined identifiers such as system keyword or system function name.
CREATE TABLE t_stu(
id INT,
`name` VARCHAR(20)
);
select id as "number", `name` as "full name" from t_stu; #When aliasing, as can be omitted
select id as number, `name` as full name from t_stu; #You can omit "" if there are no spaces in the field alias
select id as Number, `name` as full name from t_stu; #Error, cannot omit '' if there are spaces in the field aliasChapter 2 - DDL operation database
2.1. Create database (Master)
- grammar
create database Database name [character set character set][collate Proofreading rules] notes: []Means optional
Charset: a set of symbols and codes.
- practice
Create a day01 database (default character set)
create database day01;
Create a day01_2, specify the character set as GBK (understand)
create database day01_2 character set gbk;
2.2. View all databases
- View all databases
grammar
show databases;
- View the definition structure of the database [understand]
grammar
show create database Database name;
View the definition of day01 database
show create database day01;
2.3. Delete database
grammar
drop database Database name;
Delete day01_2 Database
drop database day01_2;
2.4. Modify database [understand]
grammar
alter database Database name character set character set;
Modify the character set (gbk) of day01 database
alter database day01 character set gbk;
be careful:
- It's utf8, not utf-8
- Not modify database name
2.5 other operations
Switch databases and select which database
use Database name; //Note: be sure to specify the database before creating the table use database name
Exercise: using day01
use day01;
View databases in use
select database();
Chapter III - DDL operation table
3.1. Create table
grammar
create table Table name( Column name type [constraint], Column name type [constraint] ... );- type
value type
Integer series: xxxInt
- int(M) must be used with unsigned zerofill to make sense
Floating point series: float,double (or real)
double(M,D): indicates that the maximum length is M digits, including D digits after the decimal point
For example: double(5,2)Data range represented[-999.99,999.99],If it exceeds this range, an error will be reported.
Fixed point series: decimal (the bottom layer is actually stored with strings)
- decimal(M,D): indicates that the longest is M digits, including D digits after the decimal point
Bit type: bit
- Byte range: 1-8, value range: bit(1)~bit(64), default bit(1)
Used to store binary numbers. For bit fields, using the select command directly will not see the results. You can use bit () or hex() functions to read. When inserting a bit type field, use the bit() function to convert it to a binary value and then insert it, because the binary code is "01".
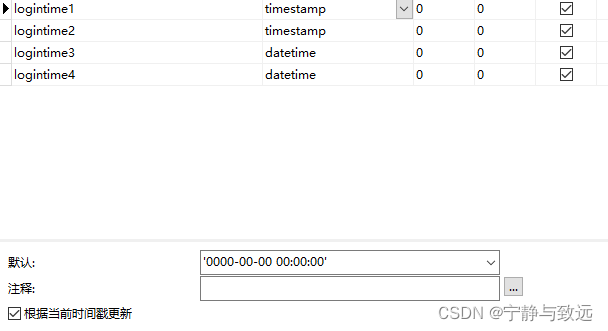
Date time type
Date time type: year, date, datetime, timestamp
Note the representation range of each date time

The difference between timestamp and datetime:
- The timestamp range is relatively small
timestamp is related to time zone
- show variables like 'time_zone';
- set time_zone = '+8:00';
- timestamp is greatly affected by MySQL version and SQL mode of the server
- If the first non empty timestamp field in the table is inserted and updated to NULL, it will be automatically set to the system time

String type
MySQL provides a variety of storage types for character data, which may vary from version to version. Common are:
char,varchar,xxtext,binary,varbinary,xxblob,enum,set wait
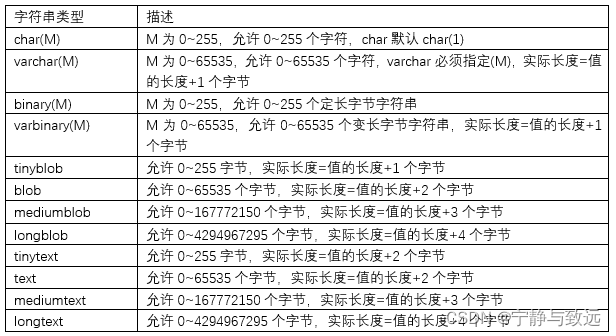
String type char,varchar(M)
- char if no width is specified, the default value is 1 character
- varchar(M), width must be specified
Binary and varbinary are similar to char and varchar, except that they contain binary strings and do not support fuzzy queries.
Generally, when saving a small number of strings, we will select char and varchar; When saving large text, you usually choose to use text or blob series. Blob and text values will cause some performance problems, especially when a large number of deletion operations are performed, they will leave a large "hole" in the data table. In order to improve performance, it is recommended to use the optimize table function to defragment such tables regularly. Synthetic indexes can be used to improve the query performance of large text fields. If fuzzy queries are needed for large text fields, MySql provides prefix indexes. However, avoid retrieving large blob or text values when not necessary.
Enum enumeration type. Its value range needs to be explicitly specified by enumeration when creating a table. For enumeration of 1 ~ 255 members, 1 byte storage is required; Two bytes are required for [255 ` 65535] members. For example, gender enum('male ',' female '). If a value other than the enumerated value is inserted, it will be treated as the first value. Only one of the enumerated values can be selected at a time.
Set collection type, which can contain 0 ~ 64 members. You can select more than one member from the collection at a time. If a set of 1-8 members is selected, it takes up 1 byte, 2 and 3 in turn.. 8 bytes. For example: hoppy set("eat", "sleep", "play games", "travel"), choose "eat, sleep" or "sleep, play games, travel"
Example
+----------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------------+--------------+------+-----+---------+----------------+ | eid | int(11) | NO | PRI | NULL | auto_increment | | ename | varchar(20) | NO | | NULL | | | tel | char(11) | NO | | NULL | | | gender | char(1) | YES | | male | | | salary | double | YES | | NULL | | | commission_pct | double(3,2) | YES | | NULL | | | birthday | date | YES | | NULL | | | hiredate | date | YES | | NULL | | | job_id | int(11) | YES | | NULL | | | email | varchar(32) | YES | | NULL | | | mid | int(11) | YES | | NULL | | | address | varchar(150) | YES | | NULL | | | native_place | varchar(10) | YES | | NULL | | | did | int(11) | YES | | NULL | | +----------------+--------------+------+-----+---------+----------------+
constraint
- Rules, rules and restrictions;
- Function: ensure that the data inserted by the user is saved to the database in accordance with the specifications
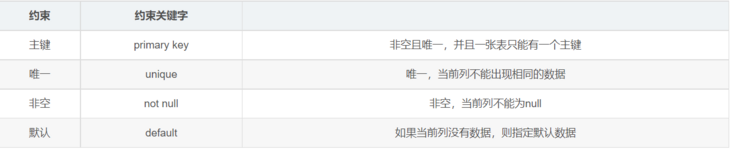
Constraint type:
- Not null: not null; eg: username varchar(40) not null username column cannot have null value
- Unique: unique constraint. The following data cannot duplicate the previous data; eg: cardNo char(18) unique; There can be no duplicate data in the cardno column
primary key; Primary key constraint (non empty + unique); It is generally used on the id column of a table A table basically has an id column, and the id column is used as the unique identifier
- auto_increment: Auto growth. Auto can only be used after the primary key is set_ increment
- id int primary key auto_increment; id doesn't need to be maintained by ourselves. When inserting data, null is directly inserted and filled in automatically to avoid duplication
be careful:
- Set the primary key before setting auto_increment
- Only when auto is set_ Increment can insert null, otherwise an error will be reported
id column:
- Set id to int type, add primary key constraint, and grow automatically
- Or set the id as a string type and add a primary key constraint. Automatic growth cannot be set
practice
Create a student table (including id field, name field can't be duplicate, gender field can't be empty, the default value is male. id is the primary key and grows automatically)
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT, -- Primary key self growth
NAME VARCHAR(30) UNIQUE, -- Unique constraint
gender CHAR(1) NOT NULL DEFAULT 'male'
);3.2. Check the table [understanding]
View all tables
show tables;
View the definition structure of the table
grammar
desc Table name;
Exercise: viewing the definition structure of the student table
desc student;
3.3. Modify the table [ master, but don't remember ]
grammar
- Add a column
alter table [Database name.]Table name add [column] Field name data type; alter table [Database name.]Table name add [column] Field name data type first; alter table [Database name.]Table name add [column] Field name data type after Another field;
- Modify column type constraints: alter table name modify field type constraints;
- Modify column name, type and constraint: alter table name change old column new column type constraint;
- Delete a column: alter table name drop column name;
- Modify table name: rename table old table name to new table name;
practice
Add a grade field to the student table. The type is varchar(20), which cannot be empty
ALTER TABLE student ADD grade VARCHAR(20) NOT NULL;
Change the gender field of the student table to type int, which cannot be empty. The default value is 1
alter table student modify gender varchar(20);
Change the grade field of the student table to the class field
ALTER TABLE student CHANGE grade class VARCHAR(20) NOT NULL;
Delete the class field
ALTER TABLE student DROP class;
Change the student form into the teacher form (understand)
RENAME TABLE student TO teacher;
3.4 delete table [ master ]
grammar
drop table Table name;
Delete the teacher table
drop table teacher;
Chapter IV - DML operation table records - addition, deletion and modification [key]
Preparation: create a commodity table (commodity id, commodity name, commodity price, commodity quantity.)
create table product(
pid int primary key auto_increment,
pname varchar(40),
price double,
num int
);4.1. Insert record
grammar
- Method 1: insert the specified column. If this column is not listed, it will be automatically assigned with null
eg: just want to insert pname, price, insert into t_ product(pname, price) values(‘mac’,18000);
insert into Table name(column,column..) values(value,value..);
Note: if no column is inserted and a non NULL constraint is set, an error will be reported
- Method 2: insert all columns. If a column does not want to insert a value, it needs to be assigned null
insert into table name values;
eg:
insert into product values(null,'Apple Computer',18000.0,10); insert into product values(null,'Huawei 5 G mobile phone',30000,20); insert into product values(null,'Mi phones',1800,30); insert into product values(null,'iPhonex',8000,10); insert into product values(null,'iPhone7',6000,200); insert into product values(null,'iPhone6s',4000,1000); insert into product values(null,'iPhone6',3500,100); insert into product values(null,'iPhone5s',3000,100); insert into product values(null,'instant noodles',4.5,1000); insert into product values(null,'Coffee',11,200); insert into product values(null,'mineral water',3,500);
4.2. Update records
- grammar
update Table name set column =value, column =value [where condition]
- practice
Revise the price of all goods to 5000 yuan
update product set price = 5000;
Change the price of apple computer to 18000 yuan
UPDATE product set price = 18000 WHERE pname = 'Apple Computer';
Change the price of apple computer to 17000 and the quantity to 5
UPDATE product set price = 17000,num = 5 WHERE pname = 'Apple Computer';
Increase the price of instant noodles by 2 yuan on the original basis
UPDATE product set price = price+2 WHERE pname = 'instant noodles';
4.3. Delete record
- delete
Delete data one by one according to conditions
grammar
delete from Table name [where condition] be careful: For deleting data delete,no need truncate
type
Delete the record named 'Apple' in the table
delete from product where pname = 'Apple Computer';
Delete commodity record with price less than 5001
delete from product where price < 5001;
Delete all records in the table (delete statement is generally not recommended to delete. Delete statement is executed line by line, and the speed is too slow)
delete from product;
truncate
DROP the table directly, and then create the same new table. Deleted data cannot be retrieved. Execute faster than DELETEtruncate table surface;
Delete data at work
- Physical deletion: when the data is deleted and the data is not available, using delete belongs to physical deletion
- Logical deletion: there is no real deletion, but the data is still there Make a mark. In fact, the logical deletion is to update eg: state 1 enable 0 disable
Chapter V - DQL operation table record - query [ key ]
5.1. Basic query syntax
select Field name to query from Table name [where condition]
5.2. Simple query
Query records for all rows and all columns
grammar
select * form surface
Query all the columns in the commodity table
select * from product;
Query records of specific columns in a table
grammar
select Listing,Listing,Listing... from surface
Query product name and price
select pname, price from product;
De duplication query distinct
grammar
SELECT DISTINCT Field name FROM Table name; //The data can be as like as two peas before being weighed.
Go to re query the name of the product
SELECT DISTINCT pname,price FROM product
Note: for a column, the column name cannot appear before distinct
Alias query
grammar
select Listing as alias ,Listing from surface //The column name as may not be written select alias.* from surface as alias //Table alias (multi table query, which will be discussed in detail tomorrow)
Query product information and use alias
SELECT pid ,pname AS 'Trade name',price AS 'commodity price',num AS 'Commodity inventory' FROM product
Operation query (+,, *, /,%, etc.)
Query the commodity name and commodity price + 10: we can not only add a fixed value to a field, but also calculate and query multiple fields
select pname ,price+10 as 'price' from product; select name,chinese+math+english as total from student
be careful
- Operation query fields. Fields can be
- String and other types can be used for operation query, but the result is meaningless
5.3 condition query (very important)
grammar
select ... from surface where condition //Take out each data in the table, the records that meet the conditions will be returned, and the records that do not meet the conditions will not be returned
operator
1. Comparison operator
Greater than:> Less than:< Greater than or equal to:>= Up to:<= be equal to:= Cannot be used for null judge Not equal to:!= or <> Safety equals: <=> Can be used for null Value judgment
2. Logical operators (words are recommended for readability)
Logic and:&& or and Logical or:|| or or Logical non:! or not Logical XOR:^ or xor
3. Scope
Interval range: between x and y
not between x and y
Set range: in (x,x,x)
not in (x,x,x)4. Fuzzy query and regular matching (only for string type and date type)
like 'xxx' Fuzzy query is to perform partial matching when processing strings If you want to represent 0~n Characters, in% If you want to represent a certain 1 character, use_ regexp 'regular'
5. Special null value handling
#(1) When judging xx is null xx is not null xx <=> null #(2) When calculating ifnull(xx,Substitute value) When xx yes null When, calculate with substitute value
- practice
Query products with commodity price > 3000
select * from product where price > 3000;
Query goods with pid=1
select * from product where pid = 1;
Query products with PID < > 1 (! =)
select * from product where pid <> 1;
Inquire about goods with prices between 3000 and 6000
select * from product where price between 3000 and 6000;
Query the goods with pid in the range of 1, 5, 7 and 15
select * from product where id = 1; select * from product where id = 5; select * from product where id = 7; select * from product where id = 15; select * from product where id in (1,5,7,15);
Query products whose product name starts with iPho (iPhone Series)
select * from product where pname like 'iPho%';
Query commodities with commodity price greater than 3000 and quantity greater than 20 (condition and...)
select * from product where price > 3000 and num > 20;
Query products with id=1 or price less than 3000
select * from product where pid = 1 or price < 3000;
5.4 Sorting Query
Sorting is written after the query, which means sorting after querying the data
Environmental preparation
# Create a student table (with Sid, student name, student gender, student age and score columns, where sid is the primary key and grows automatically) CREATE TABLE student( sid INT PRIMARY KEY auto_increment, sname VARCHAR(40), sex VARCHAR(10), age INT, score DOUBLE ); INSERT INTO student VALUES(null,'zs','male',18,98.5); INSERT INTO student VALUES(null,'ls','female',18,96.5); INSERT INTO student VALUES(null,'ww','male',15,50.5); INSERT INTO student VALUES(null,'zl','female',20,98.5); INSERT INTO student VALUES(null,'tq','male',18,60.5); INSERT INTO student VALUES(null,'wb','male',38,98.5); INSERT INTO student VALUES(null,'Xiao Li','male',18,100); INSERT INTO student VALUES(null,'Xiao Hong','female',28,28); INSERT INTO student VALUES(null,'cockroach','male',21,95);
- Single column sorting
Syntax: sort only by one field, single column
SELECT Field name FROM Table name [WHERE condition] ORDER BY Field name [ASC|DESC]; //ASC: ascending, default value; DESC: descending order
Case: query all students in descending order of scores
SELECT * FROM student ORDER BY score DESC
- Combinatorial sorting
Syntax: sort multiple fields at the same time. If the first field is equal, sort by the second field, and so on
SELECT Field name FROM Table name WHERE field=value ORDER BY Field name 1 [ASC|DESC], Field name 2 [ASC|DESC];
Exercise: query all students in descending order of scores. If the scores are consistent, then in descending order of age
SELECT * FROM student ORDER BY score DESC, age DESC
5.5 aggregation function
Aggregation functions are used for statistics. They are usually used together with grouping queries to count the data of each group
- Aggregate function list
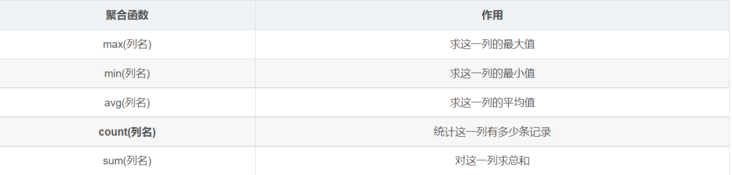
grammar
SELECT Aggregate function(Listing) FROM Table name [where condition];
case
-- Find the highest score in the student table SELECT MAX(score) FROM student -- Find the lowest score in the student table SELECT MIN(score) FROM student -- Find the sum of the scores in the student table(ignore null value) SELECT SUM(score) FROM student -- Find the average score in the student table SELECT AVG(score) FROM student -- Find the average score in the student table (if you are absent from the exam, it will be treated as 0) SELECT AVG(IFNULL(score,0)) FROM student -- Count the total number of students (ignore null) SELECT COUNT(sid) FROM student SELECT COUNT(*) FROM student
Note: the aggregate function ignores NULL values
We found that null records will not be counted. It is recommended not to use columns that may be null if the number of records is counted, but what if NULL needs to be counted? We can solve this problem through ifnull (column name, default value) function If the column is not empty, the value of this column is returned. If NULL, the default value is returned.
-- Find the average score in the student table (if you are absent from the exam, it will be treated as 0) SELECT AVG(IFNULL(score,0)) FROM student;
5.6 group query
GROUP BY takes the same contents in the grouping field results as a group and returns the first data of each group, so grouping alone is useless. The purpose of grouping is statistics. Generally, grouping is used together with aggregation functions
- grouping
grammar
SELECT Field 1,Field 2... FROM Table name [where condition] GROUP BY column [HAVING condition];
case
-- Grouped by gender, Count the total number of students in each group SELECT sex 'Gender',COUNT(sid) 'Total number' FROM student GROUP BY sex -- The average scores of students in each group were counted according to gender SELECT sex 'Gender',AVG(score) 'average' FROM student GROUP BY sex -- According to gender grouping, the total scores of students in each group were counted SELECT sex 'Gender',SUM(score) 'Total score' FROM student GROUP BY sex
- Filtering having after grouping
The conditions after grouping cannot be written after where, and the where keyword should be written before group by
According to gender grouping, count the total number of students in each group > 5 (screening after grouping)
SELECT sex, count(*) FROM student GROUP BY sex HAVING count(sid) > 5
According to gender grouping, only those whose age is greater than or equal to 18 are counted, and the number of people in the group is required to be greater than 4
SELECT sex 'Gender',COUNT(sid) 'Total number' FROM student WHERE age >= 18 GROUP BY sex HAVING COUNT(sid) > 4
- The difference between where and having [interview]
where clause function
- 1) Before grouping the query results, remove the rows that do not meet the where criteria, that is, filter the data before grouping, that is, filter before grouping.
- 2) Aggregate functions cannot be used after where
The function of having sentence
- 1) The function of having clause is to filter groups that meet the conditions, that is, filter data after grouping, that is, group first and then filter.
- 2) Aggregate functions can be used after having
5.7 paging query
grammar
select ... from .... limit a ,b

case
-- Paging query -- limit Keywords are used at the back of the query. If there is sorting, they are used at the back of the sorting -- limit Grammar of: limit offset,length among offset Indicates how many pieces of data are skipped, length Indicates how many pieces of data to query SELECT * FROM product LIMIT 0,3 -- query product The first three data in the table(0 It means that 0 items are skipped and 3 items are queried) SELECT * FROM product LIMIT 3,3 -- query product Table 4-6 data(3 It means skipping 3 items, and 3 means querying 3 items) -- When paging, I will only tell you which page of data I need and how many pieces of data there are on each page -- If you need 3 pieces of data per page, I want the first page of data: limit 0,3 -- If,Each page needs 3 pieces of data. I want the second page of data: limit 3,3 -- If you need 3 pieces of data per page, I want the data on the third page: limit 6,3 -- conclusion: length = Number of data pieces per page, offset = (Current number of pages - 1)*Number of data pieces per page -- limit (Current number of pages - 1)*Number of data pieces per page, Number of data pieces per page
5.8 syntax summary of query
select...from...where...group by...order by...limit select...from...where... select...from...where...order by... select...from...where...limit... select...from...where...order by...imit
Chapter VI three paradigms of database
Good database design will have an important impact on data storage performance and later program development. To establish a scientific and standardized database, we need to meet some rules to optimize the design and storage of data. These rules are called paradigms.
6.1. First paradigm: ensure that each column remains atomic
The first paradigm is the most basic paradigm. If all field values in the database table are non decomposable atomic values, it means that the database table meets the first normal form.
The reasonable compliance of the first paradigm needs to be determined according to the actual needs of the system. For example, some database systems need to use the "address" attribute. Originally, the "address" attribute was directly designed as a field of a database table. However, if the system often accesses the "city" part of the "address" attribute, it is necessary to re divide the "address" attribute into provinces, cities, detailed addresses and other parts for storage, which will be very convenient when operating on a part of the address. This design meets the first paradigm of the database, as shown in the following table.
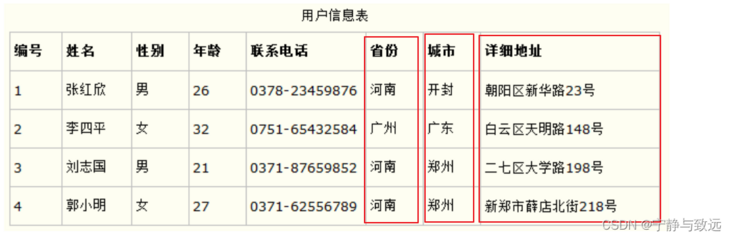
If the first normal form is not followed, the queried data needs further processing (inconvenient query). If the first normal form is followed, the data of any field needs to be queried (convenient query)
6.2. The second paradigm: ensure that each column in the table is related to the primary key
The second paradigm goes further on the basis of the first paradigm. The second paradigm needs to ensure that every column in the database table is related to the primary key, not only a part of the primary key (mainly for the joint primary key). That is, in a database table, only one kind of data can be saved in one table, and multiple data can not be saved in the same database table.
For example, to design an order information table, because there may be multiple commodities in the order, the order number and commodity number should be used as the joint primary key of the database table, as shown in the following table
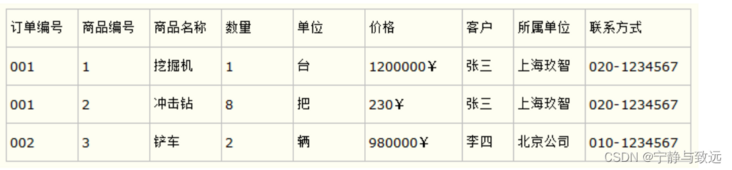
This leads to a problem: in this table, the order number and commodity number are used as the joint primary key. In this way, the commodity name, unit, commodity price and other information in the table are not related to the primary key of the table, but only related to the commodity number. Therefore, it violates the design principle of the second paradigm.
It is perfect to split the order information table, separate the commodity information into another table, and separate the order item table into another table. As shown below
<img src="imgs/tu_13.png" style="zoom: 67%;" />
This design reduces the redundancy of the database to a great extent. If you want to obtain the product information of the order, use the product number to query in the product information table
6.3. The third paradigm: ensure that each column is directly related to the primary key column, not indirectly
The third paradigm needs to ensure that each column of data in the data table is directly related to the primary key, not indirectly.
For example, when designing an order data table, you can use the customer number as a foreign key to establish a corresponding relationship with the order table. Instead of adding fields about other customer information (such as name, company, etc.) in the order table, the design shown in the following two tables is a database table that meets the third paradigm.
<img src="imgs/tu_14.png" style="zoom:67%;" />
In this way, when querying the order information, you can use the customer number to reference the records in the customer information table, and there is no need to enter the content of customer information in the order information table for many times, which reduces the data redundancy
Chapter 7 foreign key constraints
7.1 concept of foreign key constraint
On the premise of following the three paradigms, we must split tables and store data in multiple tables to reduce redundant data. However, there is an association relationship between the split tables. We must agree the relationship between tables through a constraint, which is a foreign key constraint
7.2 function of foreign key constraint
Foreign key constraint is to ensure the referential integrity between one or two tables. Foreign key is a reference relationship between two fields of one table or two fields of two tables.
7.3. Syntax for creating foreign key constraints
Specify foreign key constraints when creating tables
create table [Data name.]From table name( Field name 1 data type primary key , Field name 2 data type , ...., [constraint Foreign key constraint name] foreign key (From table field) references Main table name(Main table fields) [on update Foreign key constraint level][on delete Foreign key constraint level] #Foreign keys can only be specified individually after the list of all fields #If you want to name the foreign key constraint name yourself, the main table name is recommended_ From table name_ Associated field name_ fk );
Specify foreign key constraints after creating tables
alter table From table name add [constraint Foreign key constraint name] foreign key (Field name from table) references Main table name(Referenced field name of main table) [on update xx][on delete xx];
7.4. Syntax for deleting foreign key constraints
ALTER TABLE Table name DROP FOREIGN KEY Foreign key constraint name; #View constraint nameselect * from information_ schema. table_ constraints WHERE table_ Name = 'table name'; #Deleting the foreign key constraint will not delete the corresponding index. If you need to delete the index, you need to use the ALTER TABLE table name DROP INDEX index index name; #View index nameShow index from table name;
7.5 requirements for foreign key constraints
- Create a foreign key on the slave table, and the master table must exist first.
- A table can establish multiple foreign key constraints
- Generally, the foreign key column of the slave table must point to the primary key column of the primary table
- The foreign key column of the slave table and the referenced column of the master table may have different names, but the data type must be the same
7.6 foreign key constraint level
- Cascade method: when updating / deleting records on the master table, synchronize update/delete to delete matching records from the slave table
- Set null method: when updating / deleting records on the primary table, set the columns matching records on the secondary table to null, but note that the foreign key columns of the child table cannot be not null
- No action method: if there are matching records in the child table, the update/delete operation on the candidate key corresponding to the parent table is not allowed
- Restrict method: the same as no action, it is to check the foreign key constraints immediately
- Set default mode (blank may be displayed in the visualizer SQLyog): when the parent table changes, the child table sets the foreign key column to a default value, but Innodb cannot recognize it
- If no grade is specified, it is equivalent to Restrict
7.7 foreign key constraint exercise
-- Department table
create table dept(
id int primary key,
dept_name varchar(50),
dept_location varchar(50)
);
-- Employee table
CREATE TABLE emp(
eid int primary key,
name varchar(50) not null,
sex varchar(10),
dept_id int
);
-- For employees dept_id Add a foreign key to the primary key of the Department table
alter table emp add foreign key(dept_id) references dept(id)Chapter VIII relationship between multiple tables
8.1 one to many relationship
- concept
The one to many relationship means that one row of data in the master table can correspond to multiple rows of data in the slave table at the same time. Conversely, the multiple rows of data in the slave table point to the same row of data in the master table.
- Application scenario
Classification table and commodity table, class table and student table, user table and order table, etc
- Table building principle
Take one party of one table as the master table and the other party as the slave table. Specify a field in the slave table as the foreign key to point to the primary key of the master table
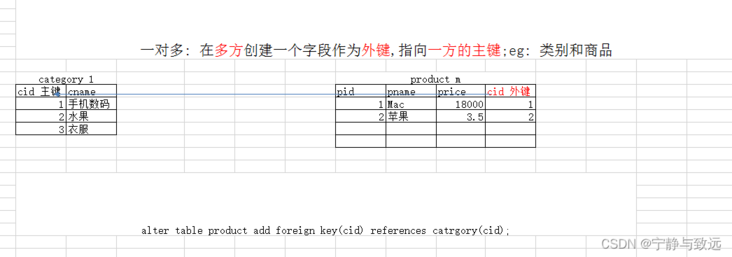
Table building statement exercise
-- Create classification table CREATE TABLE category( cid INT PRIMARY KEY AUTO_INCREMENT, cname VARCHAR(50) ); -- Create item table CREATE TABLE product( pid INT PRIMARY KEY AUTO_INCREMENT, pname VARCHAR(50), price DOUBLE, cid INT ) -- Add a foreign key to the item table alter table product add foreign key(cid) references category(cid)
8.2. Many to many relationship
- concept
Both tables are one of multiple tables. A row of data in table a can correspond to multiple rows of data in table B at the same time. Conversely, a row of data in table B can also correspond to multiple rows of data in table a at the same time
- Application scenario
Order form and commodity form, student form and course form, etc
- Table building principle
Because the two tables are one of many parties, foreign keys cannot be created in both tables. Therefore, you need to create a new intermediate table and define two fields in the intermediate table. These two fields are used as foreign keys to point to the primary keys of the two tables
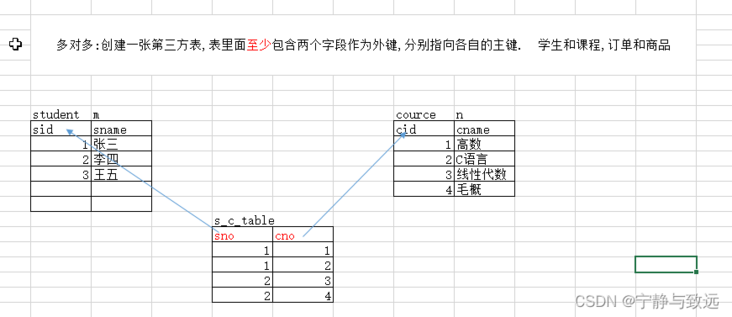
Table building statement exercise
-- Create student table CREATE TABLE student( sid INT PRIMARY KEY AUTO_INCREMENT, sname VARCHAR(50) ); -- Create Curriculum CREATE TABLE course( cid INT PRIMARY KEY AUTO_INCREMENT, cname VARCHAR(20) ); -- Create intermediate table CREATE TABLE s_c_table( sno INT, cno INT ); -- to sno Add foreign key to field student Tabular sid Primary key ALTER TABLE s_c_table ADD CONSTRAINT fkey01 FOREIGN KEY(sno) REFERENCES student(sid); -- to cno Add foreign key to field course Tabular cid Primary key ALTER TABLE s_c_table ADD CONSTRAINT fkey03 FOREIGN KEY(cno) REFERENCES course(cid);
8.3 one to one relationship (understanding)
- The first one-to-one relationship
We have learned the one to many relationship before. In the one to many relationship, one row of data in the master table can correspond to multiple rows of data in the slave table. On the contrary, one row of data in the slave table can only correspond to one row of data in the master table. This relationship of one row of data corresponding to one row of data can be regarded as a one-to-one relationship
- The second one-to-one relationship
A row of data in table a corresponds to a row of data in table B. conversely, a row of data in table B also corresponds to a row of data in table A. at this time, we can use table a as the master table, table B as the slave table, or table B as the master table, and table a as the slave table
- Table building principle
Specify a field in the slave table to create a foreign key and point to the primary key of the master table, and then add a unique constraint to the foreign key field of the slave table
Chapter 9 multi table Association query
Multi table Association query uses one SQL statement to query the data of associated multiple tables
9.1 environmental preparation
-- Create a classification table(category id,Category name.remarks:category id Is the primary key and grows automatically)
CREATE TABLE t_category(
cid INT PRIMARY KEY auto_increment,
cname VARCHAR(40)
);
INSERT INTO t_category values(null,'Mobile digital');
INSERT INTO t_category values(null,'food');
INSERT INTO t_category values(null,'Shoes, boots, luggage');
-- Create a product table(commodity id,Trade name,commodity price,Quantity of goods,category.remarks:commodity id Is the primary key and grows automatically)
CREATE TABLE t_product(
pid INT PRIMARY KEY auto_increment,
pname VARCHAR(40),
price DOUBLE,
num INT,
cno INT
);
insert into t_product values(null,'Apple Computer',18000,10,1);
insert into t_product values(null,'iPhone8s',5500,100,1);
insert into t_product values(null,'iPhone7',5000,100,1);
insert into t_product values(null,'iPhone6s',4500,1000,1);
insert into t_product values(null,'iPhone6',3800,200,1);
insert into t_product values(null,'iPhone5s',2000,10,1);
insert into t_product values(null,'iPhone4s',18000,1,1);
insert into t_product values(null,'instant noodles',4.5,1000,2);
insert into t_product values(null,'Coffee',10,100,2);
insert into t_product values(null,'mineral water',2.5,100,2);
insert into t_product values(null,'Ferrari',3000000,50,null);
-- Add foreign key to item table
ALTER TABLE t_product ADD FOREIGN KEY(cno) REFERENCES t_category(cid);9.2. Cross query [ understanding ]
In fact, cross query is to display the data of multiple tables unconditionally
grammar
select a.column,a.column,b.column,b.column from a,b ; select a.*,b.* from a,b ; --perhaps select * from a,b;
- practice
Use cross query categories and products
select * from t_category,t_product;
Through the query results, we can see that cross query is actually a wrong practice. There are a large number of wrong data in the query result set. We call the cross query result set Cartesian product
- Cartesian product
Assuming set A={a,b}, set B={0,1,2}, the Cartesian product of two sets is {(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}. It can be extended to multiple sets.
9.3. Internal connection query
Cross query is not what we want, so how to remove wrong and unwanted records? Of course, it is through conditional filtering. Usually, there is an association relationship between multiple tables to be queried, so the Cartesian product is removed through the association relationship (primary foreign key relationship). This kind of query that removes Cartesian product through conditional filtering is called join query. Connection query can be divided into internal connection query and external connection query. Let's learn internal connection query first
- Implicit join query
There is no inner join keyword in the implicit inner join query
select [field,field,field] from a,b where Connection conditions (b Foreign keys in the table = a Primary key in the table )
- Explicit inner join query
There is an inner join keyword in the explicit inner join query
select [field,field,field] from a [inner] join b on Connection conditions [ where Other conditions]
- Join query exercise
Query the commodity information under all categories. If there are no commodities under this category, they will not be displayed
-- 1 Implicit inner connection select *from t_category c, t_product p WHERE c.cid = p.cno; -- 2 Display internal connection mode -- Query the information and classification information of all products under the mobile phone digital category SELECT * FROM t_product tp INNER JOIN t_category tc ON tp.cno = tc.cid WHERE tc.cname = 'Mobile digital'; SELECT * from t_category c INNER JOIN t_product p ON c.cid = p.cno
- Characteristics of inner join query
The data in the master table and the slave table can be queried if they meet the connection conditions, and will not be queried if they do not meet the connection conditions
9.4 external connection query
We found that the internal connection query is the public part that meets the connection conditions. If you want to ensure that all the data of a table is queried, you can perform the connection query Then you need to use external connection query The external connection is divided into left external connection and right external connection
- Left outer connection query
concept
Use the table on the left of the join as the main table to display all the data of the main table. Query and connect the data of the table on the right according to the conditions. If the conditions are met, it will be displayed. If not, it will be displayed as null. It can be understood as: on the basis of internal connection, ensure that all the data in the left table are displayed
grammar
select field from a left [outer] join b on condition
practice
Query the commodity information under all categories. Even if there are no commodities under this category, the information of this category needs to be displayed
SELECT * FROM t_category c LEFT OUTER JOIN t_product p ON c.cid = p.cno
- Right outer connection query
concept
Take the table on the right of the join as the main table to display all the data of the table on the right. Query the data of the table on the left of the join according to the criteria. If it is satisfied, it will be displayed. If it is not satisfied, it will be displayed as null. It can be understood as: on the basis of internal connection, ensure that all the data in the right table are displayed
grammar
select field from a right [outer] join b on condition
practice
Query the category information corresponding to all commodities
SELECT * FROM t_category c RIGHT OUTER JOIN t_product p ON c.cid = p.cno
9.5. union joint query realizes all external connection query
First of all, it should be clear that joint query is not a way of multi table join query. Joint query is to combine the query results of multiple query statements into one result and remove duplicate data.
All external connection query means to query the data of the left table and the right table, and then connect according to the connection conditions
union syntax
Query statement 1 union Query statement 2 union Query statement 3 ...
practice
# Use A union outside the left and B outside the right SELECT * FROM t_category c LEFT OUTER JOIN t_product p ON c.cid = p.cno union SELECT * FROM t_category c RIGHT OUTER JOIN t_product p ON c.cid = p.cno
9.6. Self connection query
Self join query is a special multi table join query, because the tables of two associated queries are the same table. They are virtualized into two tables by taking aliases, and then the join query of the two tables is performed
preparation
-- Employee table CREATE TABLE emp ( id INT PRIMARY KEY, -- staff id ename VARCHAR(50), -- Employee name mgr INT , -- Superior leaders joindate DATE, -- Entry date salary DECIMAL(7,2) -- wages ); -- Add employee INSERT INTO emp(id,ename,mgr,joindate,salary) VALUES (1001,'Sun WuKong',1004,'2000-12-17','8000.00'), (1002,'Lu Junyi',1006,'2001-02-20','16000.00'), (1003,'Lin Chong',1006,'2001-02-22','12500.00'), (1004,'Tang Monk',1009,'2001-04-02','29750.00'), (1005,'Li Kui',1006,'2001-09-28','12500.00'), (1006,'Song Jiang',1009,'2001-05-01','28500.00'), (1007,'Liu Bei',1009,'2001-09-01','24500.00'), (1008,'Zhu Bajie',1004,'2007-04-19','30000.00'), (1009,'Luo Guanzhong',NULL,'2001-11-17','50000.00'), (1010,'Wu Yong',1006,'2001-09-08','15000.00'), (1011,'Monk Sha',1004,'2007-05-23','11000.00'), (1012,'Li Kui',1006,'2001-12-03','9500.00'), (1013,'Little white dragon',1004,'2001-12-03','30000.00'), (1014,'Guan Yu',1007,'2002-01-23','13000.00'); #Query Monkey King's superior SELECT employee.*,manager.ename mgrname FROM emp employee,emp manager where employee.mgr=manager.id AND employee.ename='Sun WuKong'
- Self join query exercise
Query the employee's number, name and salary and the number, name and salary of his leader
#These data are all in the employee table
#Put t_ The employee table is regarded as both the employee table and the leader table
#Leadership table is a virtual concept. We can use alias to make it virtual
SELECT employee.id "Employee number",emp.ename "Employee's name" ,emp.salary "Employee's salary",
manager.id "Leader's number" ,manager.ename "Name of leader",manager.salary "Salary of leaders"
FROM emp employee INNER JOIN emp manager
#emp employee: employee., Represents the of the employee table
#emp manager: if manager is used, It represents the leadership table
ON employee.mgr = manager.id # The mgr of the employee points to the id of the superior
#Do not add "" to the alias of the table to alias the column. You can use "" instead of "" for the alias of the column, but avoid including special symbols such as spaces.Chapter 10 sub query
If a query statement is nested in another query statement, the query statement is called a sub query. According to different locations, it is divided into where type, from type and exists type. Note: no matter where the subquery is, the subquery must be enclosed with ().
10.1 where type
① If the subquery is a single value result (single row and single column), you can use (=, > and other comparison operators)
# Query the commodity information with the highest price select * from t_product where price = (select max(price) from t_product)
② If the subquery is a multi value result, you can use it ([not] in (subquery result), or > all (subquery result), or > = all (subquery result), < all (subquery result), or > any (subquery result), or > = any (subquery result), < any (subquery result), < = any (subquery result))
# Query the commodity information with the highest price SELECT * FROM t_product WHERE price >=ALL(SELECT price FROM t_product) select * from t_product order by price desc limit 0,1
10.2. from type
The result of subquery is the result of multiple rows and columns, which is similar to a table.
The sub query must be aliased, that is, the name of the temporary table. The alias of the table should not be added with "" and spaces.
-- Train of thought I: Use join query -- Use the external connection to query all the data in the classification table SELECT tc.cname,COUNT(tp.pid) FROM t_category tc LEFT JOIN t_product tp ON tp.cno = tc.cid GROUP BY tc.cname -- Train of thought II: Use subquery -- First step:yes t_product according to cno Group query and count the quantity of goods in each category SELECT cno,COUNT(pid) FROM t_product GROUP BY cno -- Step 2: use t_category Table to connect the results of the first step of the query and perform the connection query,At this time, you are required to query all classifications SELECT tc.cname,IFNULL(tn.total,0) 'Total quantity' FROM t_category tc LEFT JOIN (SELECT cno,COUNT(pid) total FROM t_product GROUP BY cno) tn ON tn.cno=tc.cid
10.3. exists type
# Query the categories of goods SELECT cid,cname FROM t_category tc WHERE EXISTS (SELECT * FROM t_product tp WHERE tp.cno = tc.cid);
Link: blog csdn. net/qq_ 42076902/article/details/121701974
