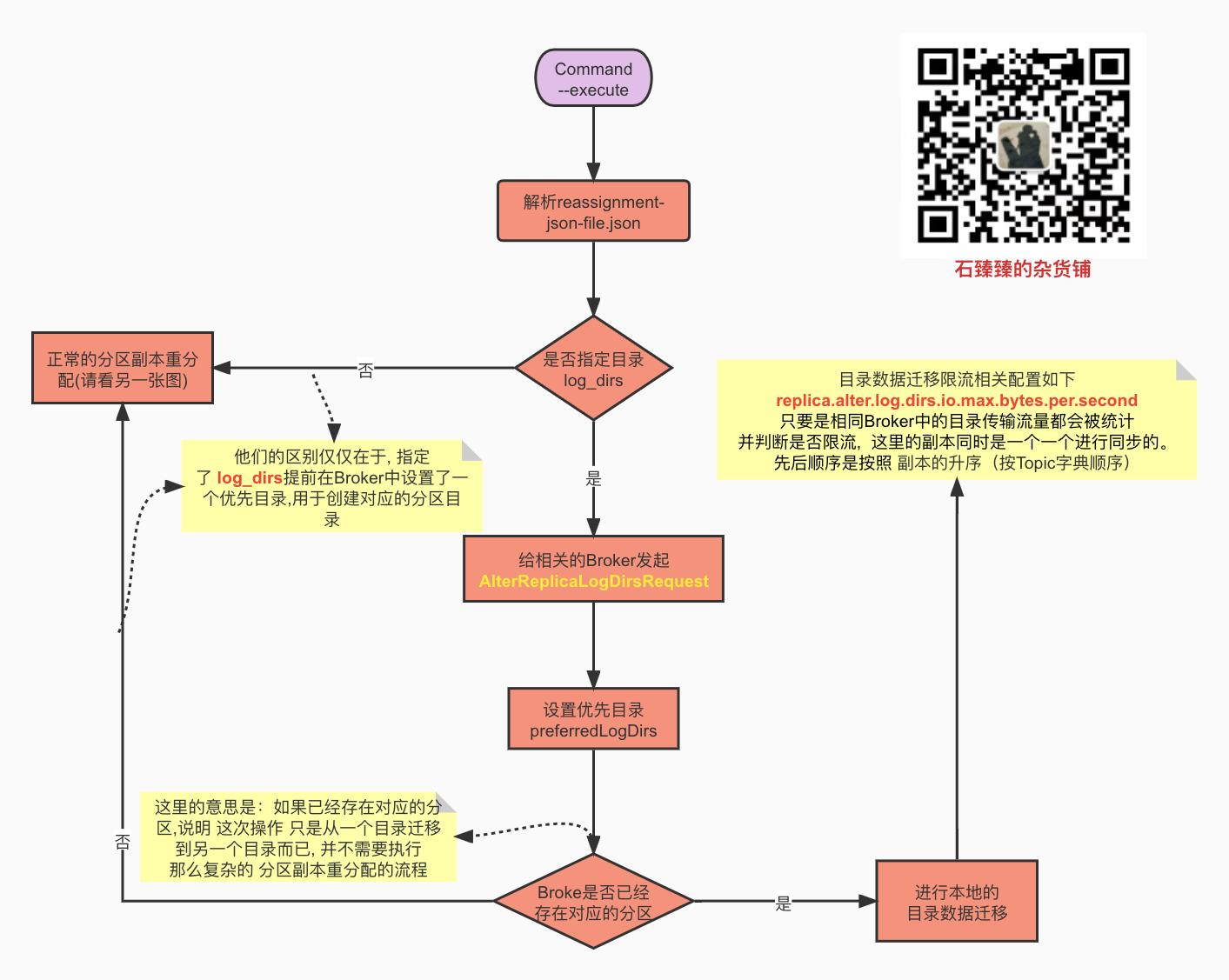
How to migrate across directories
Why does the occupation of each disk of the online Kafka machine not be uniform, and there is often a "one-sided" situation? This is because Kafka only ensures that the number of partitions is evenly distributed on each disk, but it cannot know the actual space occupied by each partition. Therefore, it is likely that a large number of partition messages will occupy a large amount of disk space. Before version 1.1, users had no choice, because before 1.1, Kafka only supported the reallocation of partition data among different brokers, but could not reallocate partition data among different disks under the same broker. Version 1.1 officially supports the migration of replicas between different paths
How to use multiple paths to store partitions on a Broker?
Just connect multiple folders to the configuration
#### Log Basics ### log.dirs=k0,k1
Note that different paths on the same Broker will only store different partitions, and will not store replicas in the same Broker; Otherwise, the copy will be meaningless (disaster recovery)
What about cross path migration?
One parameter of the migrated json file is log_ dirs; If the default request is not transmitted, it is "log_dirs": ["any"] (the number of this array should be consistent with the copy) However, if you want to realize cross path migration, you only need to fill in the absolute path here, such as the following
Examples of migrated json files
{
"version": 1,
"partitions": [
{
"topic": "topic1",
"partition": 0,
"replicas": [
0
],
"log_dirs": [
"/Users/xxxxx/work/IdeaPj/source/kafka/k0"
]
},
{
"topic": "topic2",
"partition": 0,
"replicas": [
0
],
"log_dirs": [
"/Users/xxxxx/work/IdeaPj/source/kafka/k1"
]
}
]
}Then execute the script
sh bin/kafka-reassign-partitions.sh --zookeeper xxxxx --reassignment-json-file config/reassignment-json-file.json --execute --bootstrap-serverxxxxx:9092 --replica-alter-log-dirs-throttle 10000
Note -- this parameter must be passed in when bootstrap server migrates across paths
If current limiting is required, add the parameter -- replica alter log dirs throttle; Unlike -- throttle -- replica alter log dirs throttle limits the migration traffic of different paths in the Broker;
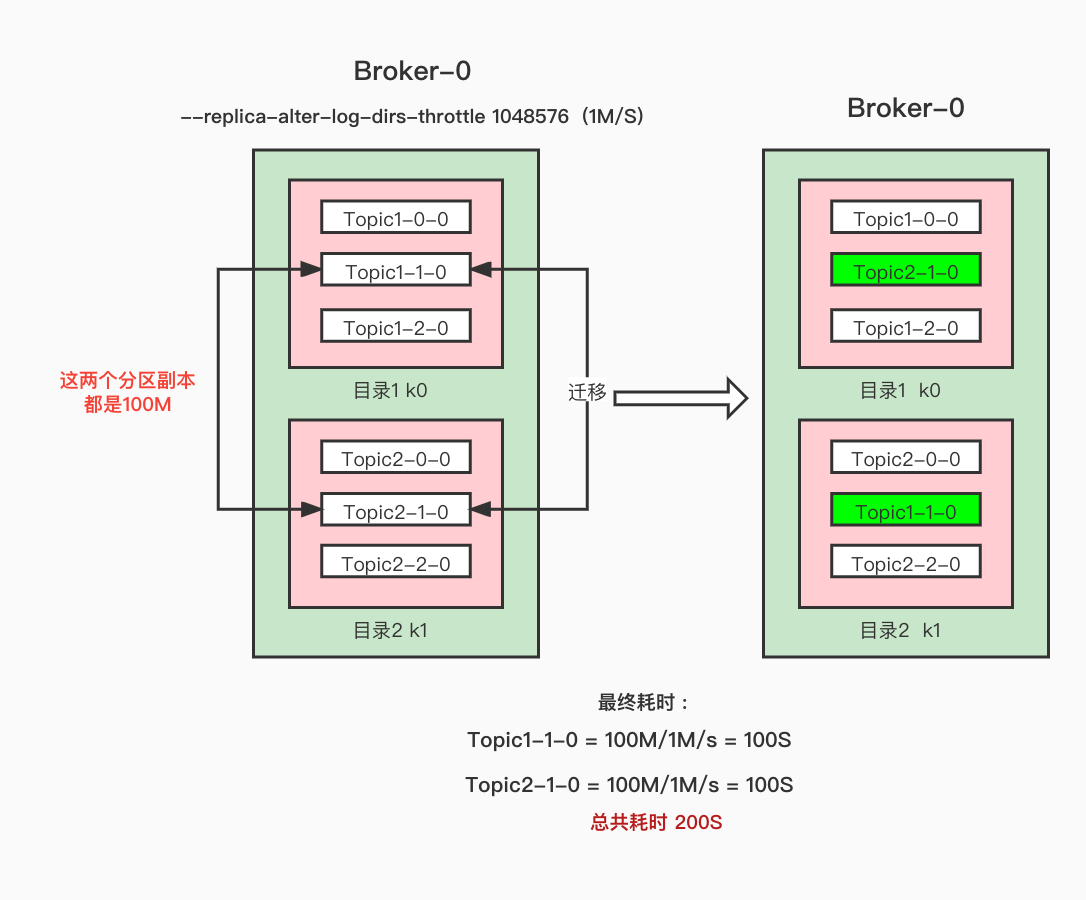
For the replica synchronization current limiting mechanism, see Multi graph diagram partition replica synchronization current limiting Trilogy - principle
Source code analysis
Because the code is Principle analysis of partition replica redistribution source code (with supporting teaching video) It is a module, but different processing has been done for different situations. The entire redistributed source code will not be analyzed, but the cross directory data migration will be explained separately.
First, understand a knowledge point, future directory (- future): When we perform cross directory data migration, we will actually create a new partition directory in the target directory. Its format is topic partition uniqueId-future ; When the final synchronization is completed, the directory will be renamed, and then the directory of the old partition will be deleted.
It is similar to that when deleting a topic, it is marked delete.
Execute execute migration
ReassignPartitionsCommand#reassignPartitions
def reassignPartitions(throttle: Throttle = NoThrottle, timeoutMs: Long = 10000L): Boolean = {
// The request to send AlterReplicaLogDirsRequest allows the Broker to create a replica in the correct log dir (if the replica of that path has not been created yet)
if (proposedReplicaAssignment.nonEmpty)
alterReplicaLogDirsIgnoreReplicaNotAvailable(proposedReplicaAssignment, adminClientOpt.get, timeoutMs)
// Send AlterReplicaLogDirsRequest again to make sure broker will start to move replica to the specified log directory.
// It may take some time for controller to create replica in the broker. Retry if the replica has not been created.
var remainingTimeMs = startTimeMs + timeoutMs - System.currentTimeMillis()
val replicasAssignedToFutureDir = mutable.Set.empty[TopicPartitionReplica]
while (remainingTimeMs > 0 && replicasAssignedToFutureDir.size < proposedReplicaAssignment.size) {
replicasAssignedToFutureDir ++= alterReplicaLogDirsIgnoreReplicaNotAvailable(
proposedReplicaAssignment.filter { case (replica, _) => !replicasAssignedToFutureDir.contains(replica) },
adminClientOpt.get, remainingTimeMs)
Thread.sleep(100)
remainingTimeMs = startTimeMs + timeoutMs - System.currentTimeMillis()
}
replicasAssignedToFutureDir.size == proposedReplicaAssignment.size
}- The request to send AlterReplicaLogDirsRequest allows the Broker to create a replica in the correct log dir (if the replica of that path has not been created yet)
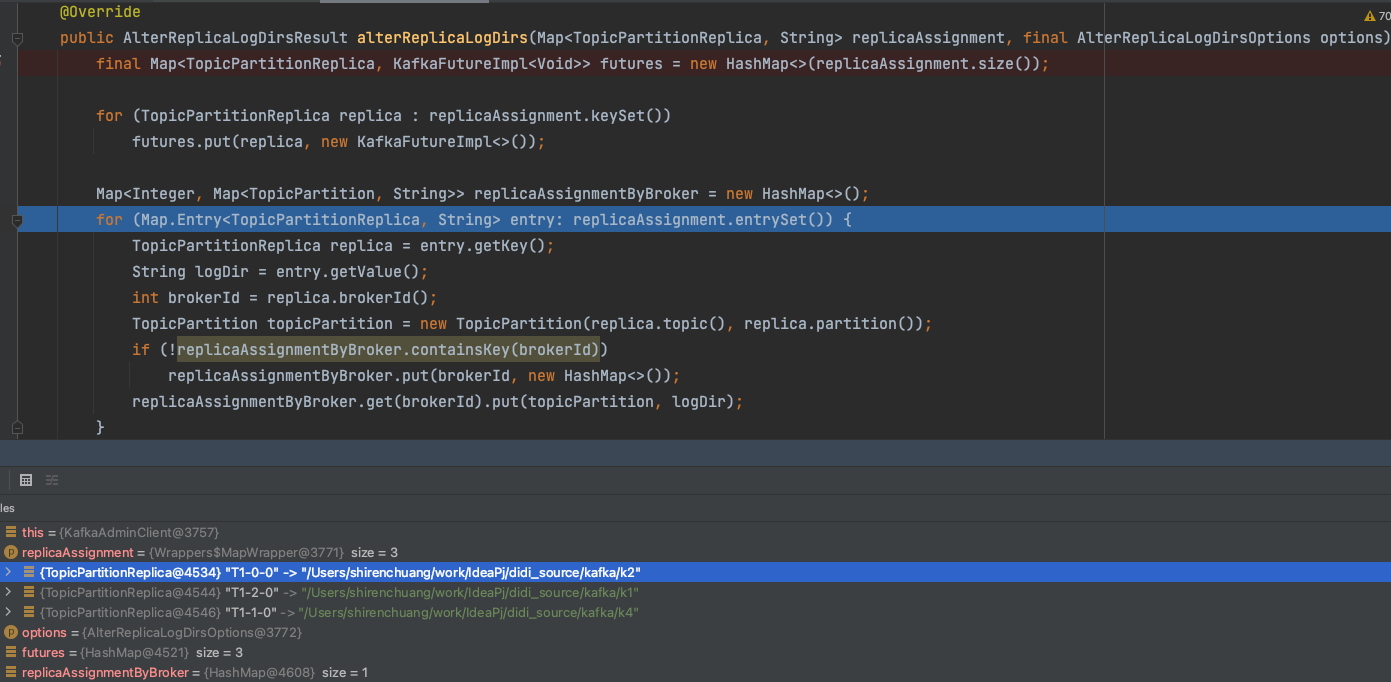
Resolve the Json file of the replicaAssignment into the format of Map > replicaassignmentbybroker. The Key is the BrokerId, and the value corresponds to the TopicPartition and directory path logDir to be changed; Then, an alterReplicaLogDirs request is initiated for these corresponding brokerids. Of course, this request is asynchronous, and a Futures object is returned here;
Of course, the next step is to traverse the future and execute the future Get () to get the return result of each request. Record all successful copies.
ALTER_REPLICA_LOG_DIRS
Handles requests to modify the replica log directory
KafkaApis.handleAlterReplicaLogDirsRequest
def alterReplicaLogDirs(partitionDirs: Map[TopicPartition, String]): Map[TopicPartition, Errors] = {
val alterReplicaDirsRequest = request.body[AlterReplicaLogDirsRequest]
val responseMap = {
if (authorize(request, ALTER, CLUSTER, CLUSTER_NAME))
// Processing logic. If it is found that there is no corresponding partition in the current Broker, nothing will be done
replicaManager.alterReplicaLogDirs(alterReplicaDirsRequest.partitionDirs.asScala)
else
alterReplicaDirsRequest.partitionDirs.asScala.keys.map((_, Errors.CLUSTER_AUTHORIZATION_FAILED)).toMap
}
sendResponseMaybeThrottle(request, requestThrottleMs => new AlterReplicaLogDirsResponse(requestThrottleMs, responseMap.asJava))- If the requested TopicPartition does not exist in the current Broker (meaning that it is not a local directory migration), ignore it and return directly without doing anything. (then, the data migration between cross brokers is done separately.)
- Enter the topic of the parameter to judge whether the character size after renaming exceeds 255 and throw exceptions The renamed format is topic partition uniqueId-future; (is it similar to deleting topic. - delete). Don't make the name of topic too long
- Judge whether the incoming logDir is an absolute path. If not, an exception will be thrown. And the target logDir must be an existing and online directory file.
- If destinationDir is different from the existing target log directory, stop the current copy move
- If the parent directory of the topicPartition of the current operation is not the given future migration directory destinationDir & & the given destinationDir directory does not exist in the future LogfutureLogs, cache the topicPartition and destinationDir into MappreferredLogDirs. It sounds awkward. To sum up, if the destinationDir has not been marked, cache it first. Of course, if the destinationDir is consistent with the path of your current partition, there is no need to migrate and mark it
- Check the availability of the partition replica again. Is it online
- Create a new Log file directory and file, but the Log file directory at this time is suffixed with - future, and the Log is also saved in the futureLog object in this partition.
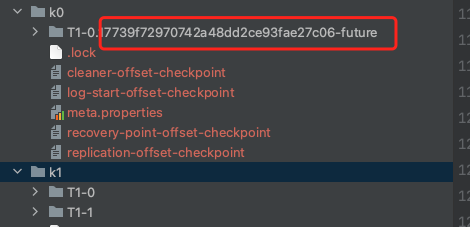
- Suspend the cleaning and deletion of this Log (it is not too late to clean up after the - future partition replica is synchronized)
- AbstractFetcherManager#addFetcherForPartitions add a Fetcher to prepare for synchronization
AbstractFetcherManager#addFetcherForPartitions add a Fetcher thread
Add a Fetcher thread
/**
* Create a ReplicaAlterLogDirsThread thread and add the partition to be migrated to the Fetcher
* Finally, start the thread and start synchronization
**/
def addFetcherForPartitions(partitionAndOffsets: Map[TopicPartition, InitialFetchState]): Unit = {
lock synchronized {
val partitionsPerFetcher = partitionAndOffsets.groupBy { case (topicPartition, brokerAndInitialFetchOffset) =>
BrokerAndFetcherId(brokerAndInitialFetchOffset.leader, getFetcherId(topicPartition))
}
// Add and start a Fetcher thread ReplicaAlterLogDirsThread
def addAndStartFetcherThread(brokerAndFetcherId: BrokerAndFetcherId,
brokerIdAndFetcherId: BrokerIdAndFetcherId): T = {
val fetcherThread = createFetcherThread(brokerAndFetcherId.fetcherId, brokerAndFetcherId.broker)
fetcherThreadMap.put(brokerIdAndFetcherId, fetcherThread)
fetcherThread.start()
fetcherThread
}
for ((brokerAndFetcherId, initialFetchOffsets) <- partitionsPerFetcher) {
val brokerIdAndFetcherId = BrokerIdAndFetcherId(brokerAndFetcherId.broker.id, brokerAndFetcherId.fetcherId)
val fetcherThread = fetcherThreadMap.get(brokerIdAndFetcherId) match {
case Some(currentFetcherThread) if currentFetcherThread.sourceBroker == brokerAndFetcherId.broker =>
// reuse the fetcher thread if the thread already exists, reset the thread directly
currentFetcherThread
case Some(f) =>
f.shutdown()
//Add and start a Fetcher thread ReplicaAlterLogDirsThread
addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId)
case None =>
//Add and start a Fetcher thread ReplicaAlterLogDirsThread
addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId)
}
val initialOffsetAndEpochs = initialFetchOffsets.map { case (tp, brokerAndInitOffset) =>
tp -> OffsetAndEpoch(brokerAndInitOffset.initOffset, brokerAndInitOffset.currentLeaderEpoch)
}
// After the ReplicaAlterLogDirsThread is started, the partitions to be pulled are added to the thread (marked - future, of course)
addPartitionsToFetcherThread(fetcherThread, initialOffsetAndEpochs)
}
}
}Build Fetch request to pull data
- Move only one partition at a time to improve its catch-up rate, thereby reducing the cost of moving any given replica.
- Copies are prepared in ascending order (in Topic dictionary order) for acquired partitions.
- If the request for a partition is already being processed, it will continue to be selected the next time it is fetched Becomes unavailable or deleted.
ReplicaAlterLogDirsThread#buildFetch
def buildFetch(partitionMap: Map[TopicPartition, PartitionFetchState]): ResultWithPartitions[Option[ReplicaFetch]] = {
// If the current limit is found, the request will not be initiated. Current limiting here refers to cross path current limiting of the same Broker
if (quota.isQuotaExceeded) {
println(new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss").format(new Date())+"AlterLogThread The current is limited...")
ResultWithPartitions(None, Set.empty)
} else {
selectPartitionToFetch(partitionMap) match {
case Some((tp, fetchState)) =>
println(new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss").format(new Date())+"AlterLogThread buildFetchForPartition...")
//Start building Fetch requests for each partition that needs to synchronize data
buildFetchForPartition(tp, fetchState)
case None =>
ResultWithPartitions(None, Set.empty)
}
}
}- First judge whether the current limit threshold is exceeded. If it is found that the current limit has been exceeded, the request will not be built this time. Please see whether the current limit has been exceeded Partitioned replica current limiting Trilogy ; Of course, the current limit configuration here is replica alter log dirs throttle
- Obtain fetchOffset, logStartOffset, fetchSize and other data to construct a Fetch request; fetchSize can be configured by configuring replica Fetch. Max.bytes, which means the maximum amount of data obtained by a Fetch request. The default is 1M
- If there is no Fetch request (no replica needs to be synchronized or the current limit is exceeded), wait for 1S.
- Traverse the request parameter fetchRequestOpt obtained above and initiate the Fetch request processFetchRequest. We can see that we process it one copy at a time
Initiate Fetch request to read data
It can be seen that the request is initiated locally, and the data is not obtained through the network request
AbstractFetcherThread#processFetchRequest
private def processFetchRequest(sessionPartitions: util.Map[TopicPartition, FetchRequest.PartitionData],
fetchRequest: FetchRequest.Builder): Unit = {
// Others omitted This is the place where you request the Leader to obtain data through fetchRequest
responseData = fetchFromLeader(fetchRequest)
}Looking at the fetchFromLeader above, we seem to think that we need to read data from the partition Leader, but this is actually an abstract method. ReplicaAlterLogDirsThread#fetchFromLeader has a specific implementation for it
def fetchFromLeader(fetchRequest: FetchRequest.Builder): Map[TopicPartition, FetchData] = {
// Other ignore Here is the data read from the copy
replicaMgr.fetchMessages(
0L, // timeout is 0 so that the callback will be executed immediately
Request.FutureLocalReplicaId,
request.minBytes,
request.maxBytes,
false,
request.fetchData.asScala.toSeq,
UnboundedQuota,
processResponseCallback,
request.isolationLevel,
None)
}Here is to read the data directly from the copy.
We can also look at the implementation method of another implementation class, ReplicaFetcherThread#fetchFromLeader
override protected def fetchFromLeader(fetchRequest: FetchRequest.Builder): Map[TopicPartition, FetchData] = {
try {
// A Fetch request was made to LeaderEndPoint
val clientResponse = leaderEndpoint.sendRequest(fetchRequest)
val fetchResponse = clientResponse.responseBody.asInstanceOf[FetchResponse[Records]]
if (!fetchSessionHandler.handleResponse(fetchResponse)) {
Map.empty
} else {
fetchResponse.responseData.asScala
}
} catch {
case t: Throwable =>
fetchSessionHandler.handleError(t)
throw t
}
}It is obvious that the ReplicaFetcherThread initiates a network request to read data from the Leader replica.
About current limiting
When reading data, it will judge whether the current limit threshold is exceeded, Leader current limiting Follower current limiting How are they realized?
Current limit at Leader level
There is no need to limit the flow at the Leader level, because the data is not obtained from the Leader copy, but the local disk data read from the same Broker source directory to another directory, so there is no need to limit the flow at the Leader level.
There is a piece of code in ReplicaManager#readFromLocalLog
// Judge whether current limit is required. If the current limit is exceeded, no data will be returned (of course, the data has been read at this time)
val fetchDataInfo = if (shouldLeaderThrottle(quota, tp, replicaId)) {
// If the partition is being throttled, simply return an empty set.
FetchDataInfo(readInfo.fetchedData.fetchOffsetMetadata, MemoryRecords.EMPTY)
} else if (!hardMaxBytesLimit && readInfo.fetchedData.firstEntryIncomplete) {Judge whether current limiting is required. If the threshold is exceeded, no data will be returned (of course, the data has been read here). Please see the specific current limiting information Partition replica synchronization Trilogy . However, the return of this step is always false. See the following code for the specific reason
// replicaId = Request.FutureLocalReplicaId = -3
def shouldLeaderThrottle(quota: ReplicaQuota, topicPartition: TopicPartition, replicaId: Int): Boolean = {
val isReplicaInSync = nonOfflinePartition(topicPartition).exists(_.inSyncReplicaIds.contains(replicaId))
!isReplicaInSync && quota.isThrottled(topicPartition) && quota.isQuotaExceeded
}Here is cross directory data migration. Replicaid = request Futurelocalreplicaid = - 3. The input parameter type of quota is unbounded quota, which can be seen from the name. This means unlimited flow restriction, that is, unlimited flow. No matter what you configure and how many records you record, it is unlimited flow. Why? Because we are here to synchronize data from the source directory of the current Broker to another directory. Without Leader synchronization, there will be no issues related to partition Leader flow restriction.
Current limiting at Follower level
Record current limiting data
Process read data
ReplicaAlterLogDirsThread#processPartitionData
// process fetched data
override def processPartitionData(topicPartition: TopicPartition,
fetchOffset: Long,
partitionData: PartitionData[Records]): Option[LogAppendInfo] = {
// Omit irrelevant code
....
// Calculate the size of the data
val records = toMemoryRecords(partitionData.records)
// Count the read data, and then judge whether the current limit threshold is reached according to the data
quota.record(records.sizeInBytes)
}- When recording data here, the type passed in by quota is ReplicationQuotaManager, and the type of replicationType is AlterLogDirsReplication After the data is saved, it will be judged whether the current limit is exceeded.
Current limiting timing
As we have already mentioned before, the timing of current limiting is determined when the fetch is initiated
ReplicaAlterLogDirsThread#buildFetch
def buildFetch(partitionMap: Map[TopicPartition, PartitionFetchState]): ResultWithPartitions[Option[ReplicaFetch]] = {
// Here, we will directly judge whether current limiting is required
if (quota.isQuotaExceeded) {
ResultWithPartitions(None, Set.empty)
} else {
....
}
}You can see the quota above Isquotaexceeded is to judge whether the flow limit is exceeded. Unlike lead and Follower, it is also necessary to judge whether the replica is in ISR and whether the partition is in flow limit configuration. The type of quota incoming is ReplicationQuotaManager, and the type of replicationType is AlterLogDirsReplication. Corresponding to the flow limit of ReplicaAlterLogDirs, it directly calculates the flow values of all cross replica data synchronization of this Broker. Exceeding the threshold will limit the speed.
Data synchronization is complete. The ReplicaAlterLogDirsThread thread is closed
After all data synchronization is completed, it is now automatically closed
LogDir directory selection policy?
Cross directory form
In the case of cross directory, kafkaapis Handlealterreplicalogdirsrequest#maybecreatefuturereplica will create the corresponding partition directory file according to the passed logDir parameter. The file directory at the time of creation is at the end of - future.
Not in the form of cross directory, but LogDir is specified
If we specify LogDir during data migration; For example:
{"version":1,"partitions":[{"topic":"Topic2","partition":1,"replicas":[0],"log_dirs":["/Users/shirenchuang/work/IdeaPj/didi_source/kafka/k1"]}]}Topic2-1 was originally in Broker-1. Execute the above script to migrate topic2-1 to the "/ Users/shirenchuang/work/IdeaPj/didi_source/kafka/k1" directory in Broker-0. This is a non cross directory migration, but the directory is specified.
If a directory is specified, a request AlterReplicaLogDirsRequest will be initiated;
In this request, although it does not create the corresponding Log directory in this form, it makes a mark in this Broker preferredLogDirs: preferredlogdir, which stores the directory we just transmitted.
Then wait until a leaderandisrequest request is received and execute the becomeLeaderOrFollower method
ReplicaManager#makeFollowers... Finally to the method of creating Log
LogManager#getOrCreateLog
After we set preferredLogDirs: above, it is used when creating the Log!
def getOrCreateLog(topicPartition: TopicPartition, config: LogConfig, isNew: Boolean = false, isFuture: Boolean = false): Log = {
logCreationOrDeletionLock synchronized {
getLog(topicPartition, isFuture).getOrElse {
// create the log if it has not already been created in another thread
if (!isNew && offlineLogDirs.nonEmpty)
throw new KafkaStorageException(s"Can not create log for $topicPartition because log directories ${offlineLogDirs.mkString(",")} are offline")
val logDirs: List[File] = {
// Look here. Did we just set this priority directory and use it at this time
val preferredLogDir = preferredLogDirs.get(topicPartition)
if (preferredLogDir != null)
List(new File(preferredLogDir))
else
nextLogDirs()
}
..... Part omitted .....
val logDirName = {
if (isFuture)
Log.logFutureDirName(topicPartition)
else
Log.logDirName(topicPartition)
}
}
}LogDir is not specified for non cross directory
Please look How to select a directory to store data when Kafka has multiple directories? In fact, it is simple to sort and create according to the number of partitions in the directory, and try to ensure that the number of partition directories is balanced.
Source code summary
Q&A
- How to create a partition copy in the corresponding directory? Log specified_ Dirs is created in the AlterReplicaLogDirsRequest request in the case of directory migration. Other cases are created in the LeaderAndIsrRequest.
- In which directory is the partition created? For details, please see How to select a directory to store data when Kafka has multiple directories? Specifically, if dir is specified, the specified dir will be used to create partitions during creation. Otherwise, each directory will be sorted according to the number of partitions and the one with the least number will be selected.
- When migrating data across directories, do you read the partition copy data from the source directory? Or get data from the Leader of the partition? Data is read from the source directory in the same Broker, not from the Leader.
- In the partition replica flow restriction mechanism, in the scenario of cross directory data migration, will the data synchronization traffic of this part be calculated into the statistics of partition Leader flow restriction? can't! In the scenario of cross directory data migration, when judging whether the flow restriction at the Leader level is required, the object passed in by shouldleaderthrottle and quota flow restriction is unbounded quota, which means no flow restriction. Moreover, cross directory migration is not synchronized by reading data from the Leader replica, so there is no flow restriction at the Leader level
- Where does Follower record traffic? ReplicaAlterLogDirsThread#processPartitionData