Hello, I'm brother Manon Feige. Thank you for reading this article. Welcome to one click three times. 😁 1. Take a stroll around the community. There are benefits and surprises every week. Manon Feige community, leap plan 💪🏻 2. Python basic column, you can catch all the basic knowledge. Python from introduction to mastery ❤️ 3. Ceph has everything from principle to actual combat. Ceph actual combat ❤️ 4. Introduction to Java high concurrency programming, punch in and learn java high concurrency. Introduction to Java high concurrency programming
Why did you write this article?
In the first two articles, we introduced Climb the ancient poetry website with regular expression and learn while playing [advanced introduction to python crawler] (09) CSV files are easy to operate [advanced introduction to python crawler] (10) Friends who haven't had time to watch can watch a wave. Taking doutu bar website as an example, this paper introduces how to apply producer consumer model to crawlers to improve crawler efficiency. Preview the wave effect first, as shown in Figure 1 below:
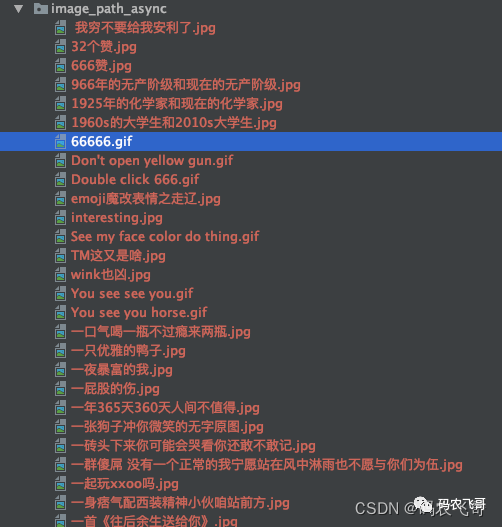
Article catalog- Why did you write this article?
- Queue secure queue
- Analyze page rules
- Single thread crawling expression package
- Producer and consumer mode crawling expression package
- Define producer
- Define consumer
- Call producers and consumers
- Complete code
- summary
- Exclusive benefits for fans
- Define producer
- Define consumer
- Call producers and consumers
Queue secure queue
Before introducing producer and consumer patterns, we first need to understand multithreading. If you are still vague about multithreading, you can read the following two articles first. [Python from introduction to mastery] (XX) basic concepts of Python concurrent programming - thread use and life cycle [Python from introduction to mastery] (XXI) application of Python concurrent programming mutex and thread communication Read through these two articles, you will master the creation of threads and how to use mutexes to deal with thread safety problems of modifying multiple threads and accessing global variables.
If you don't want to use global variables to store data, but want to store data in a queue in a thread safe way. Python has a built-in thread safe module called queue module. The queue module in Python provides synchronous and thread safe queue classes, including FIFO (first in first out) queue, LIFO (last in first out) queue and LifoQueue. These queues implement lock primitives (which can be understood as atomic operations) and can be used directly in multiple threads. In this way, queues can be used to realize synchronization between threads. The related functions are as follows:
- Initialize Queue(maxsize): create a first in first out queue
- qsize(): returns the size of the queue
- empty(): judge whether the queue is empty
- full(): judge whether the queue is full
- get(): get the last data from the queue
- put(): put a data into the queue. The following is a small diagram to illustrate the queue:
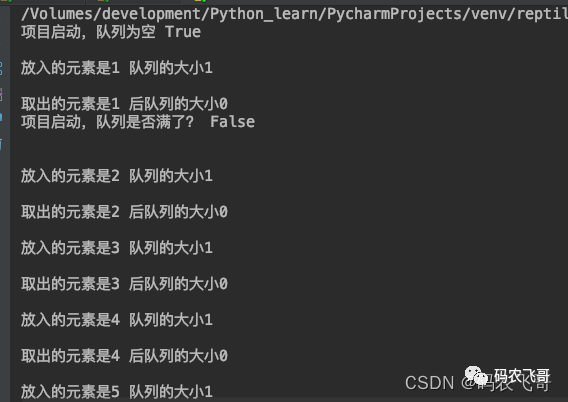
Give me a little 🌰 Describe the use of the following queue: The following code defines two threads. One thread is used to set a value to the queue and the other thread is used to take a value from the queue. The thread setting the value will sleep for 3 seconds after setting a value.
def set_value(feige_queue):
index = 1
while True:
feige_queue.put(index)
print('The element put in is' + str(index) + ' Size of queue' + str(feige_queue.qsize()) + "\n")
index += 1
time.sleep(3)
def get_value(feige_queue):
while True:
index = feige_queue.get()
print('The extracted element is' + str(index) + ' Size of the post queue' + str(feige_queue.qsize()) + "\n")
def main():
feige_queue = Queue(4)
print('Project started, queue is empty', feige_queue.empty() , "\n")
t1 = threading.Thread(target=set_value, args=(feige_queue,))
t2 = threading.Thread(target=get_value, args=(feige_queue,))
t1.start()
t2.start()
print('Is the queue full when the project is started?', feige_queue.full() , "\n")
if __name__ == '__main__':
main()
The operation results are shown in Figure 2 below:
Analyze page rules
For the address of doutu bar, take a series of expression packs as an example, as shown in Figure 3 below:
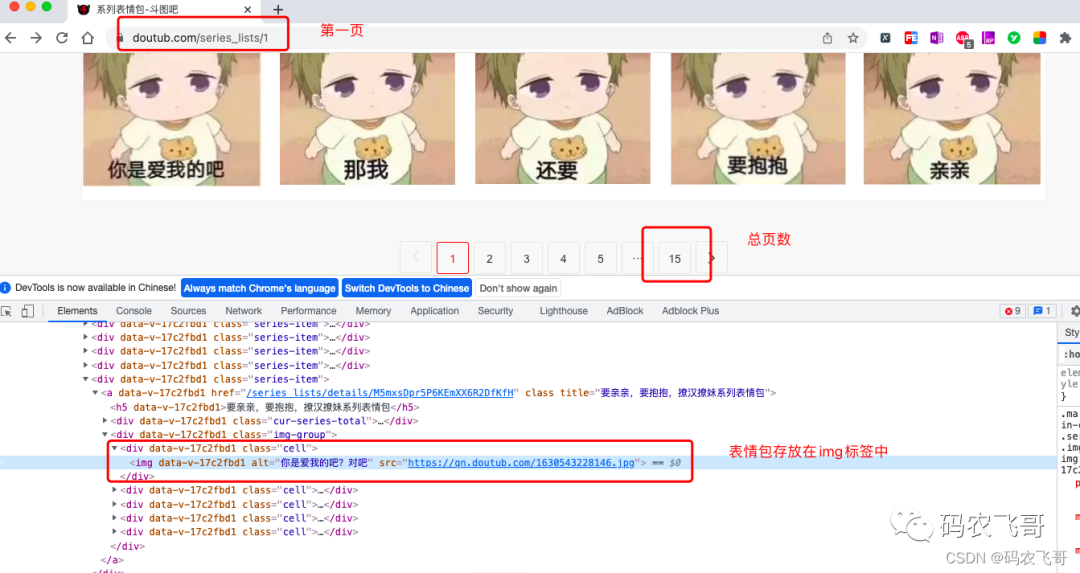
From Figure 3, we can find several laws:
- The first rule is: the address of the first page is: https://www.doutub.com/series_lists/1 , the address on the second page is: https://www.doutub.com/series_lists/2 , then the address of page n is: https://www.doutub.com/series_lists/n .
- The second rule is: the total number of pages is 15, which is stored in the < a data-v-07bcd2f3 = "" href = "/ series_lists / 15" class = "last" title = "page 15 of series expression package" > 15 < / a > tab. Therefore, its xpath expression is / / a[@class="last"]/text()
- The third rule is that the expression package pictures are stored in the
<div data-v-17c2fbd1="" class="cell"><img data-v-17c2fbd1="" alt="Do you love me? Right" src="https://qn.doutub.com/1630543228146.jpg"></div>
So its xpath expression is / / div[@class="cell"]//img.
Single thread crawling expression package
After analyzing the page rules, the next step is to write code to crawl the expression package. In order to make everyone better understand the difference between producer consumer model and ordinary synchronous model. Here, we use the single thread synchronization mode to crawl the expression package. The core code is as follows: This paper focuses on the methods of extracting page data and saving expression package. The main method of extracting page data is to get the img tag of the expression package, and then get the link of the expression package and the name of the expression package. Here, the name of the expression package may have special symbols, so it needs to be filtered and replaced through the sub method.
def parse_article_list(url):
resp = requests.get(url, headers=headers, verify=False)
html = etree.HTML(resp.content.decode('utf-8'))
# Get the addresses of all expression packages
imgs = html.xpath('//div[@class="cell"]//img')
for img in imgs:
img_url = img.get('src')
filename = img_url.split('/')[-1]
suffix = filename.split('.')[1]
alt = img.get('alt')
# Remove the special symbols in the title
alt = re.sub(r'[??\.,. !!]', '', alt)
if alt is not None and len(alt) != 0:
filename = alt + '.' + suffix
save_img(url, filename)
#Save picture
def save_img(url, filename):
resp = requests.get(url, verify=False)
with open(os.path.join(image_path, filename), 'wb') as f:
f.write(resp.content)
From the above analysis, we can see the main time-consuming points of single thread crawling expression package:
- The data crawling of each page is synchronous. If a page is blocked, it will affect the data crawling of the next page
- Downloading network pictures to local is also a time-consuming action.
Producer and consumer mode crawling expression package
After finishing the code of single thread crawling expression package, the next step is to introduce the use of multi-threaded producer and consumer mode to crawl expression package. The reason why multithreading is used is to improve the crawling efficiency. The main ideas are:
- Define a queue page_queue is used to store the url address of each page, such as: https://www.doutub.com/series_lists/1 .
- Define a queue img_queue is the url address used to store the expression package. For example: https://qn.doutub.com/1630543228146.jpg . It is to change these two time-consuming actions into asynchronous parallel execution. Using queues can ensure the security of data. The relationship between producers and consumers is shown in Figure 4 below:

The main task of producers is consumption_ The data in the queue, extract the expression package link and expression package name of each page, Then put the obtained data into the queue img_ From the queue. The main task of consumers is to consume img_queue the data in the queue, and then download and save each expression package image locally.
Define producer
import threading
class Producer(threading.Thread):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
}
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
resp = requests.get(url, headers=self.headers, verify=False)
html = etree.HTML(resp.content.decode('utf-8'))
# Get the addresses of all expression packages
imgs = html.xpath('//div[@class="cell"]//img')
for img in imgs:
img_url = img.get('src')
filename = img_url.split('/')[-1]
suffix = filename.split('.')[1]
alt = img.get('alt')
# Remove the special symbols in the title
alt = re.sub(r'[??\.,. !!]', '', alt)
if alt is not None and len(alt) != 0:
filename = alt + '.' + suffix
self.img_queue.put((img_url, filename))
Here, by inheriting threading The thread class makes the producer a thread and initializes the method__ init__ Incoming page_queue, img_queue two queue parameters. It should be noted that__ init__ You must first call its parent class constructor, otherwise you cannot successfully create a thread. The key point here is the run method
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
This method uses an endless cycle to continuously consume pages_ Queue data in the queue. Until page_ If the queue is empty, the loop will jump out, otherwise the dead loop cannot end. parse_ The page method is used as an instance method of the Producer class. After obtaining the link and name of the picture, the method of downloading and saving is no longer called directly. Instead, image links and file names are saved to img as tuples_ Queue is in the queue.
Define consumer
class Consumer(threading.Thread):
def __init__(self, page_queue, img_queue):
super().__init__()
self.img_queue = img_queue
self.page_queue = page_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
self.save_img(img_url, filename)
def save_img(self, img_url, filename):
resp = requests.get(img_url, verify=False)
with open(os.path.join(image_path, filename), 'wb') as f:
f.write(resp.content)
print(threading.current_thread().getName() + '' + filename + 'Download complete')
The Consumer class inherits threading The thread class becomes a thread class__ init__ Method is the same as that of Producer class. Similarly, we still need to focus on the run method.
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
self.save_img(img_url, filename)
The run method defines an endless loop in which img is continuously consumed_ The queue queue takes the address of the picture and calls save_. The IMG method saves the picture locally. The end of the damn loop is when img_queue queue is empty and page_ Jump out of loop when queue is empty. That is, when there is no picture download and all pages have been traversed.
Call producers and consumers
After the producer class and consumer class are defined, the next step is 1 Create page_queue and img_queue, 2 The producer and consumer instances are created and started. Relevant codes are as follows:
page_queue = Queue(15)
img_queue = Queue()
for i in range(1, 16):
url = 'https://www.doutub.com/series_lists/%d' % i
page_queue.put(url)
for i in range(5):
producer_thread = Producer(page_queue, img_queue)
producer_thread.start()
for i in range(5):
consumer_thread = Consumer(page_queue, img_queue)
consumer_thread.start()
Five producers and five consumers are created here. When initializing, the page is displayed_ The url address of all pages placed in the queue.
Complete code
"""
@url: https://blog.csdn.net/u014534808
@Author: Mainong Feige
@File: doutula_sync_test.py
@Time: 2021/12/9 18:56
@Desc: Producer and consumer model
"""
import re
import requests
from lxml import etree
import os
from queue import Queue
import ssl
import threading
requests.packages.urllib3.disable_warnings()
image_path = os.path.join(os.path.abspath('.'), 'image_path_async')
if not os.path.exists(image_path):
os.mkdir(image_path)
context = ssl._create_unverified_context()
# Define producer
class Producer(threading.Thread):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
}
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
resp = requests.get(url, headers=self.headers, verify=False)
html = etree.HTML(resp.content.decode('utf-8'))
# Get the addresses of all expression packages
imgs = html.xpath('//div[@class="cell"]//img')
for img in imgs:
img_url = img.get('src')
filename = img_url.split('/')[-1]
suffix = filename.split('.')[1]
alt = img.get('alt')
# Remove the special symbols in the title
alt = re.sub(r'[??\.,. !!]', '', alt)
if alt is not None and len(alt) != 0:
filename = alt + '.' + suffix
self.img_queue.put((img_url, filename))
# Define consumer
class Consumer(threading.Thread):
def __init__(self, page_queue, img_queue):
super().__init__()
self.img_queue = img_queue
self.page_queue = page_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
self.save_img(img_url, filename)
def save_img(self, img_url, filename):
resp = requests.get(img_url, verify=False)
with open(os.path.join(image_path, filename), 'wb') as f:
f.write(resp.content)
print(threading.current_thread().getName() + '' + filename + 'Download complete')
if __name__ == '__main__':
page_queue = Queue(15)
img_queue = Queue()
for i in range(1, 16):
url = 'https://www.doutub.com/series_lists/%d' % i
page_queue.put(url)
for i in range(5):
producer_thread = Producer(page_queue, img_queue)
producer_thread.start()
for i in range(5):
consumer_thread = Consumer(page_queue, img_queue)
consumer_thread.start()
summary
This paper takes the expression package in the producer consumer mode crawling bucket graph bar as an example to introduce how to improve the crawling efficiency through multithreading and producer consumer mode.