1, Test environment
System: WIN10 Professional Edition
Language: Simplified Chinese
Operating system default code: 936(ANSI/GBK)
The default code of txt text file created by the computer: UTF-8 without bom header by default
2, Question raised
When opening a txt text file, there are encoding methods on the right side of the status bar below it, such as UTF-8,ANSI, etc
How is the encoding method in the status bar determined when the txt text file is opened?
3, Test method
1. Create two txt files with C + +, test1 and test2; And open it in binary mode
2. Write the UTF-8 encoding of the Chinese character "ah" to the test1 file, with a total of three bytes
Write the ANSI/GBK code of Chinese character "ah" to the test2 file, with a total of two bytes
3. Open two files respectively in the project folder and check the coding method in the status bar below the text
The C + + test code is as follows:
#include<iostream>
#include<fstream>
using namespace std;
int main()
{
ofstream fout1("test1.txt", ios::binary);
if (!fout1.is_open())
{
cout << "\n The file was not opened successfully!\n";
exit(-1);
}
//UTF-8 encoding of "ah" (hexadecimal)
unsigned char a_utf8[] = { 0xE5,0x95,0x8A };
//Write three bytes of data to the file
for (int i = 0; i < 3; i++)
fout1 << a_utf8[i];
fout1.close();
//
ofstream fout2("test2.txt", ios::binary);
if (!fout2.is_open())
{
cout << "\n The file was not opened successfully!\n";
exit(-1);
}
//ANSI/GBK encoding of "ah" (hexadecimal)
unsigned char a_ansi[] = { 0xB0,0xA1 };
Write two bytes of data to the file
for (int i = 0; i < 2; i++)
fout2 << a_ansi[i];
fout2.close();
return 0;
}
test result
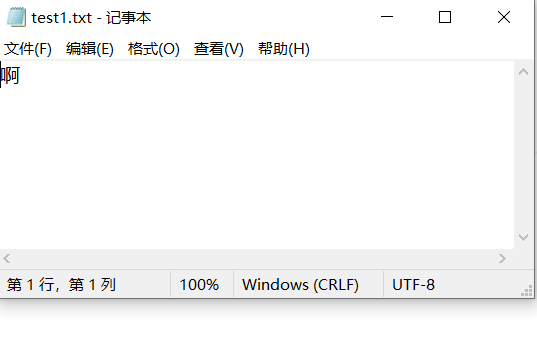
test1.txt file shows UTF-8 encoding
test2.txt displays the ANSI encoding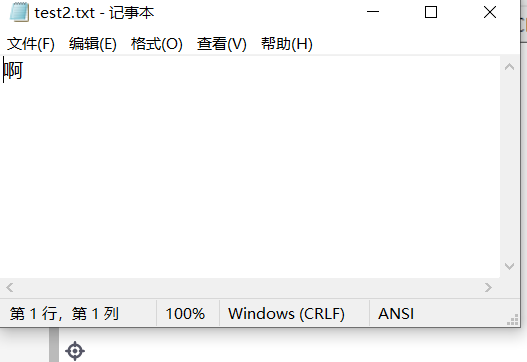
4, Test conclusion
When the TXT text file is opened, the encoding method in the status bar is automatically guessed by the txt file according to the binary string of the text content
5, Accuracy of automatic guess
In the above test environment, txt files have the following five encoding methods:
1. ANSI (i.e. GBK) (no bom)
2. Utf-16le (check hexadecimal and find that FEFF with bom header is the default)
3. Utf-16be (check hexadecimal and find that the default is fffe with bom header)
4. UTF-8 (without bom header by default) this is the default encoding method of txt text in the system
5. UTF-8 with bom header (default with bom header), but not the system default txt text encoding method
txt text file automatic detection principle:
The second, third and fifth of the above methods are directly identified by bom header
For types 1 and 4, we need * * byte by byte to combine speculation** The general inference process is as follows:
Set two variables c1,c2 Used as counter c1:Assume this byte is UTF-8 Part of a character,be c1 Indicates the number of subsequent remaining bytes c2:Assume this byte is ANSI Part of a character,be c2 Indicates the number of subsequent remaining bytes (Set counting from 1) Take the first byte,Judge whether the high order is 1,And calculate c1 c2 as:11100101 c1=2,c2=1 Take the second byte,Judge whether the high order is 1,And calculate c1 c2 as:10010101 c1=1,c2=0 (If there are no subsequent bytes at this time,Then use c2=0 Coding method of,Namely ANSI,The results show that"Merchant"word) Take the 3rd byte,Judge whether the high order is 1,And calculate c1 c2 as:10001010 c1=0,c2=1 (If there are no subsequent bytes at this time,Then use c1=0 Coding method of,Namely UTF-8 nothing bom,The results show that"ah"word) Take the 4th byte,Judge whether the high order is 1,And calculate c1 c2, The first byte is reused here as:11100101 c1=2,c2=0 Take the 5th byte,Judge whether the high order is 1 as:0xxxxxxx The high order is 0,Terminate detection,use c2=0 Coding method of,Namely ANSI The results show that"Merchant"Two words (0xxxxxxx by ASCII Binary string)
ANSI/GBK coded range:
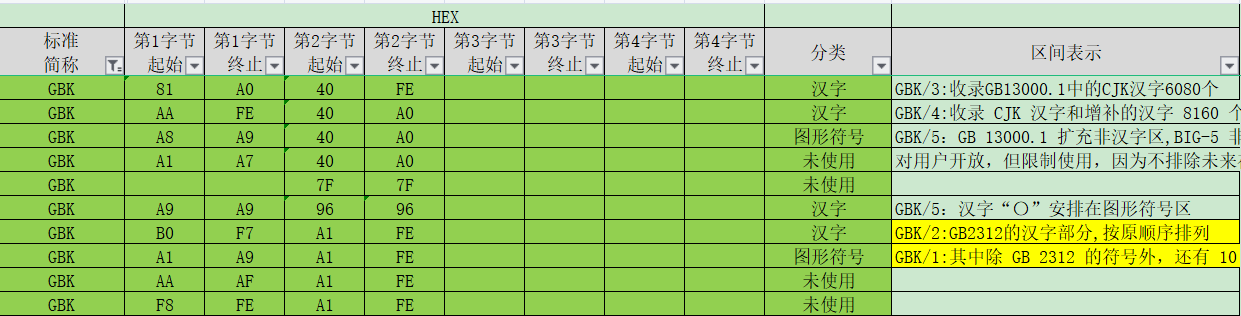
UTF-8 encoding
The first byte is at least 1100 0000, that is, the minimum is C0H. If it is a Chinese character, the minimum is E0H
Other bytes start with 10, 10xx xxxx, and the minimum is 80H
In the figure below, the horizontal is high byte and the vertical is low byte
The yellow area is the used area of GBK,
The thick wireframe area is the area of any two consecutive bytes of UTF-8 (considering the case of continuous Chinese characters)
It can be seen that most GBK codes are the same as any two consecutive bytes of UTF-8

For example:
The two Chinese characters "ah ah" UTF-8 are encoded as e5958a and e5958a
The ANSI(GBK) code of the three Chinese characters "merchant" is E595 8AE5 958A
The two codes are exactly the same. At this time, txt text will choose one of two when detecting the coding mode, which may lead to unexpected results