preface
I want to try how to run the sql of flink. Last year, I saw that the big brother JarkWu shared it, but I haven't actually operated it. Recently, I'm interested.
Original Jarkwu sharing Demo: building streaming applications based on Flink SQL.
JarkWu github flink-sql-demo
The boss is based on flink1 Version 10 is built, but the released release package is not available now. Let's compile and run the local source code. This time, it is based on flink1.0 11, because the boss provides docker compose in version 1.11 😃, Save a lot of things
prepare
- A Linux or MacOS computer with docker and jdk8 (windows should also work)
- Download the flink source code (if the github source code is downloaded slowly, change the hosts, and the git protocol can also be downloaded)
git clone git://github.com/apache/flink.git
- All the components relied on in this practical demonstration are arranged in the container, so it can be started with one click through docker compose. You can download the docker - compose automatically through the wget command YML files can also be downloaded manually. (I copied this paragraph. Thank you again for your docker-compose.yml file)
mkdir flink-demo; cd flink-demo wget https://github.com/wuchong/flink-sql-demo/blob/v1.11-EN/docker-compose.yml
Start the container using docker compose
The docker components demonstrated by the boss are all ready and can also be used. Don't worry about downloading.
At docker compose In the YML file directory, execute docker compose up - D to start the container. If necessary, execute the docker compose down command.
If the startup is successful, you can use the docker ps command to view the container operation or use the client to view it. These are mainly the successful startup
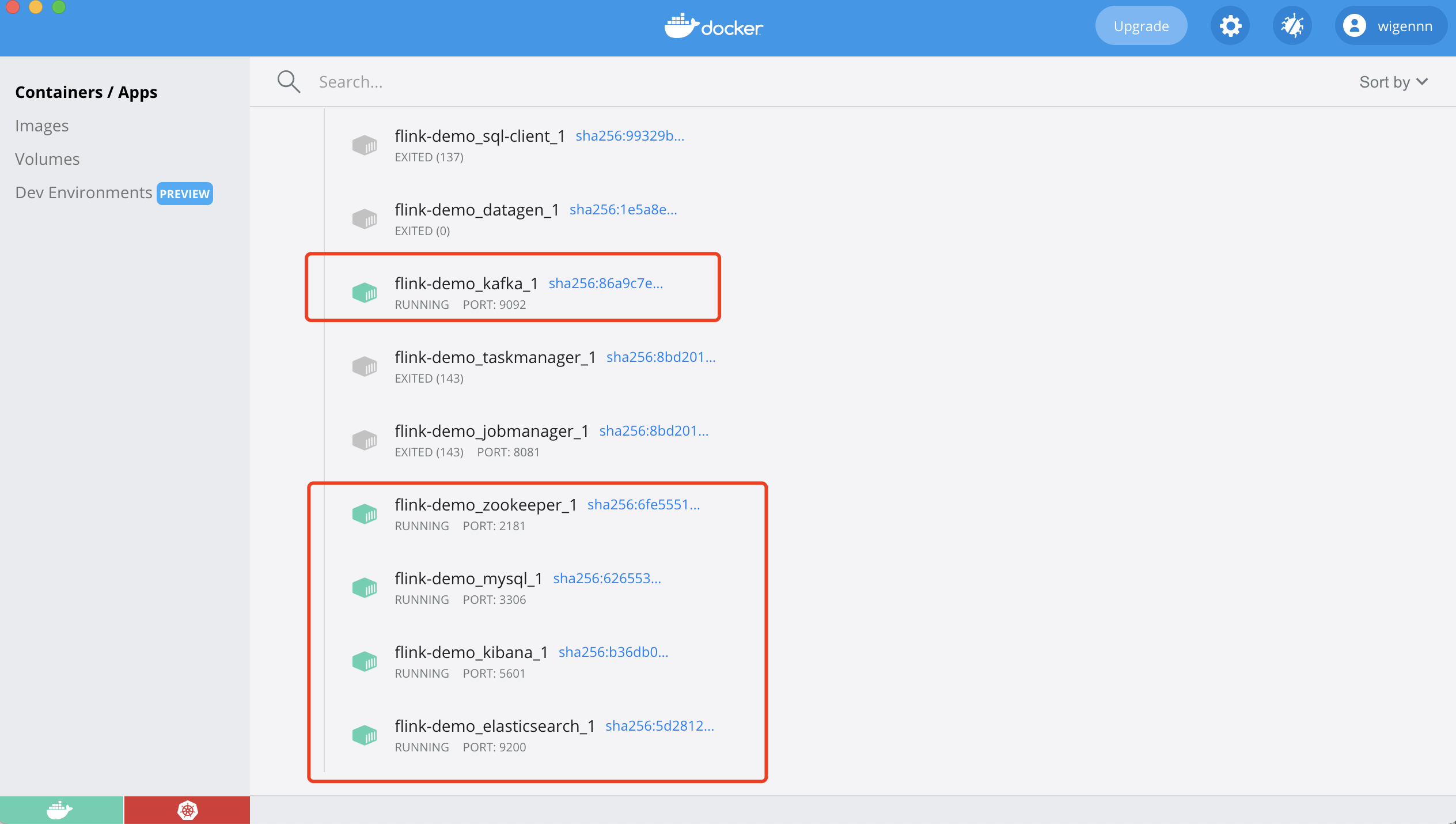
Flink source code compilation and operation
idea preparation
- Download the scala plug-in
- Download scala package
- Switch branch 1.11
- Download the missing jar package for source code compilation (there are countless pits, and time is consumed here. aliyun warehouse can't pull it, so it needs to be downloaded manually) kafka-schema-registory-client-4.1.0.jar
Compile source code
If the maven environment variable is configured, directly switch to Terminal to execute the command
mvn clean install package -DskipTests
Wait for successful compilation, about 10min +, leave a message if there is a problem
After successful compilation
Copy the file, and copy the file under build target to the file under Flink bin of Flink dist, which is easy!
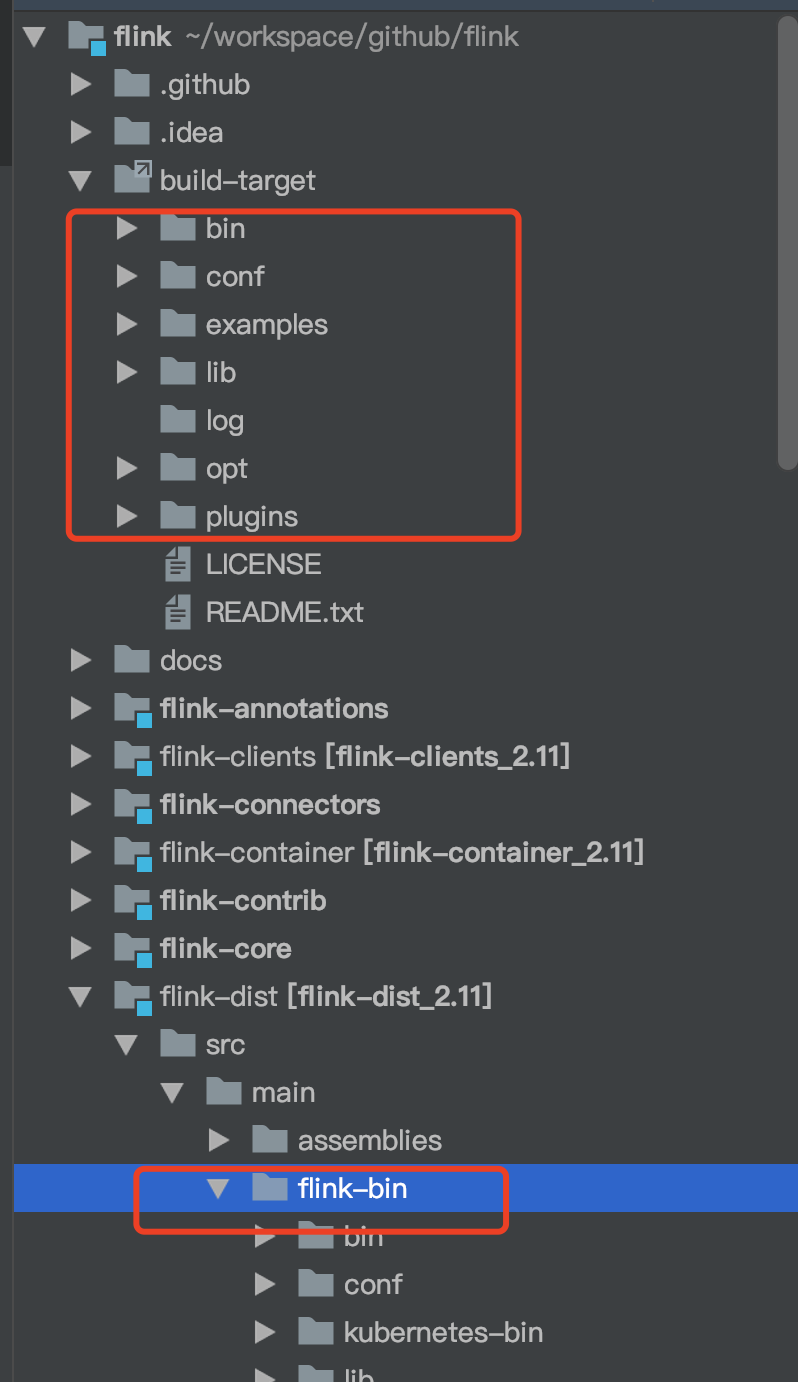
Non source startup
Execute the command to start directly in the Flink bin directory. You cannot debug directly
Start flick
./bin/start-cluster.sh
localhost:8081 check whether the startup is successful
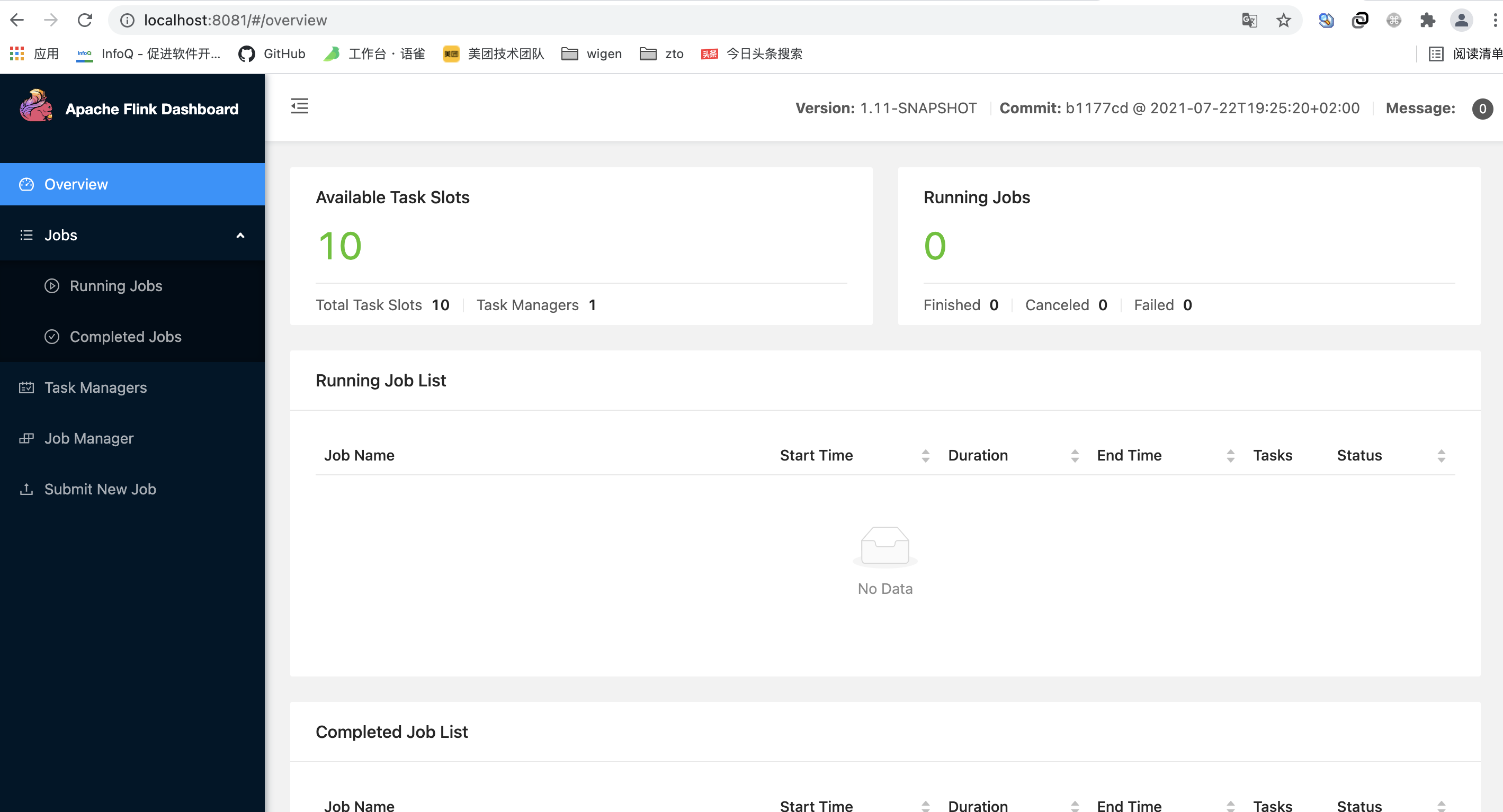
Start the flynk SQL client
./bin/sql-client.sh embedded
The console displays that SQL client is started successfully
Source startup
Three main startup classes. After successful startup, you can debug locally
Start flick
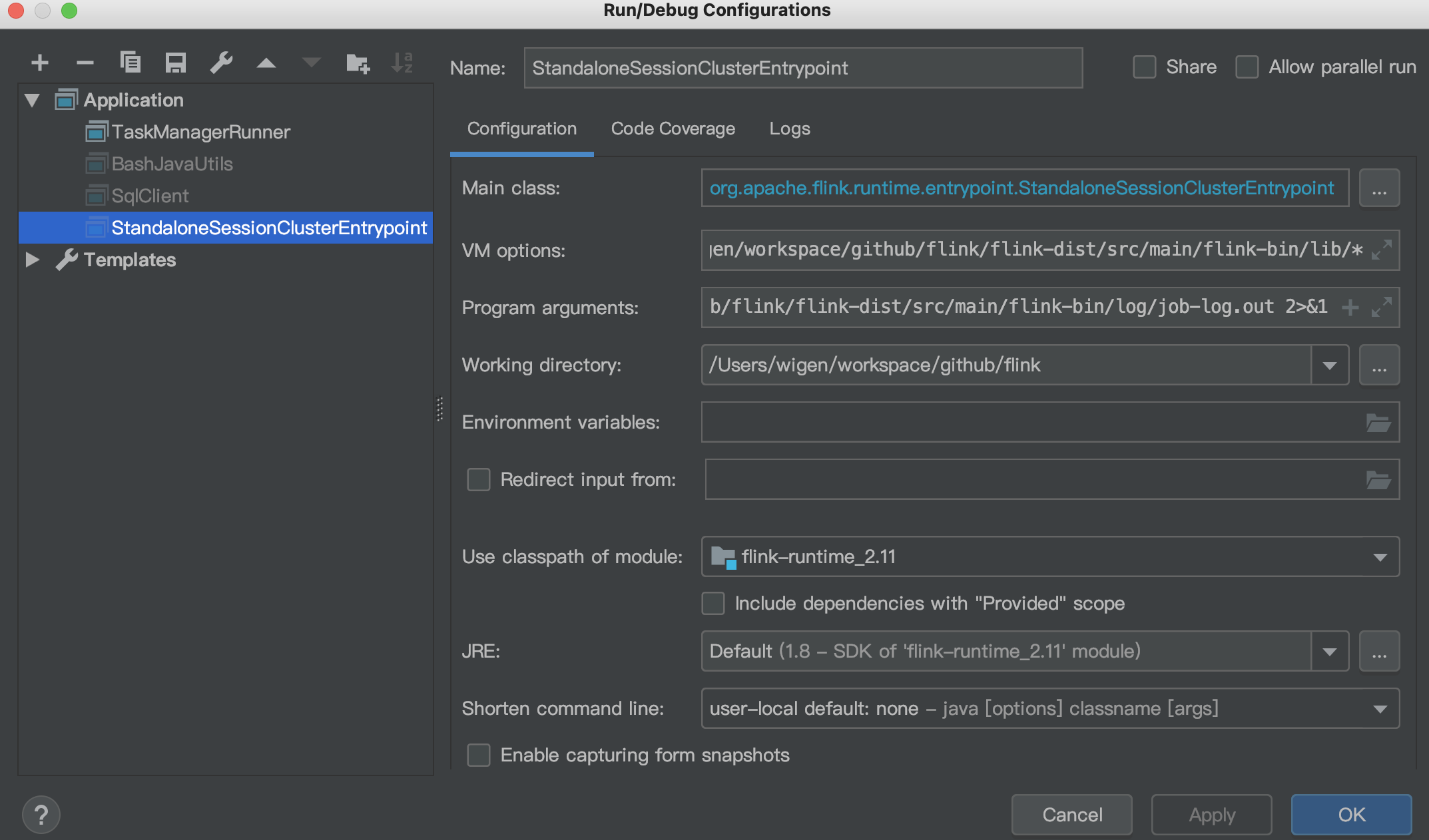
StandaloneSessionClusterEntrypoint is the key to starting jobmanager
TaskManagerRunner is the to start taskmanager
org.apache.flink.runtime.taskexecutor.TaskManagerRunner org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint
Start SQL client
org.apache.flink.table.client.SqlClient
Start parameter configuration
After analyzing the startup script, I get the following startup parameters
Flick start
StandaloneSessionClusterEntrypoint
vm options: -XX:MaxPermSize=256m -Dlog.file="/Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/log/flink-wigen-jm.log" -Dlog4j.configuration=file:"/Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/conf/log4j.properties" -Dlog4j.configurationFile=file:"/Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/conf/log4j.properties" -Dlogback.configurationFile=file:"/Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/conf/logback.xml" -cp /Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/lib/*
program argument: --configDir /Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/conf/ > /Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/log/job-log.out 2>&1
TaskManagerRunner
vm options:-XX:MaxPermSize=256m -Dlog.file="/Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/log/flink-wigen-tm.log" -Dlog4j.configuration=file:"/Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/conf/log4j.properties" -Dlog4j.configurationFile=file:"/Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/conf/log4j.properties" -Dlogback.configurationFile=file:"/Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/conf/logback.xml" -cp /Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/lib/*
program arguments: -D taskmanager.memory.framework.off-heap.size=134217728b -D taskmanager.memory.network.max=67108864b -D taskmanager.memory.network.min=67108864b -D taskmanager.memory.framework.heap.size=134217728b -D taskmanager.memory.managed.size=241591914b -D taskmanager.cpu.cores=10.0 -D taskmanager.memory.task.heap.size=26843542b -D taskmanager.memory.task.off-heap.size=0b --configDir /Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/conf/ > /Users/wigen/workspace/github/flink/flink-dist/src/main/flink-bin/log/job-log.out 2>&1
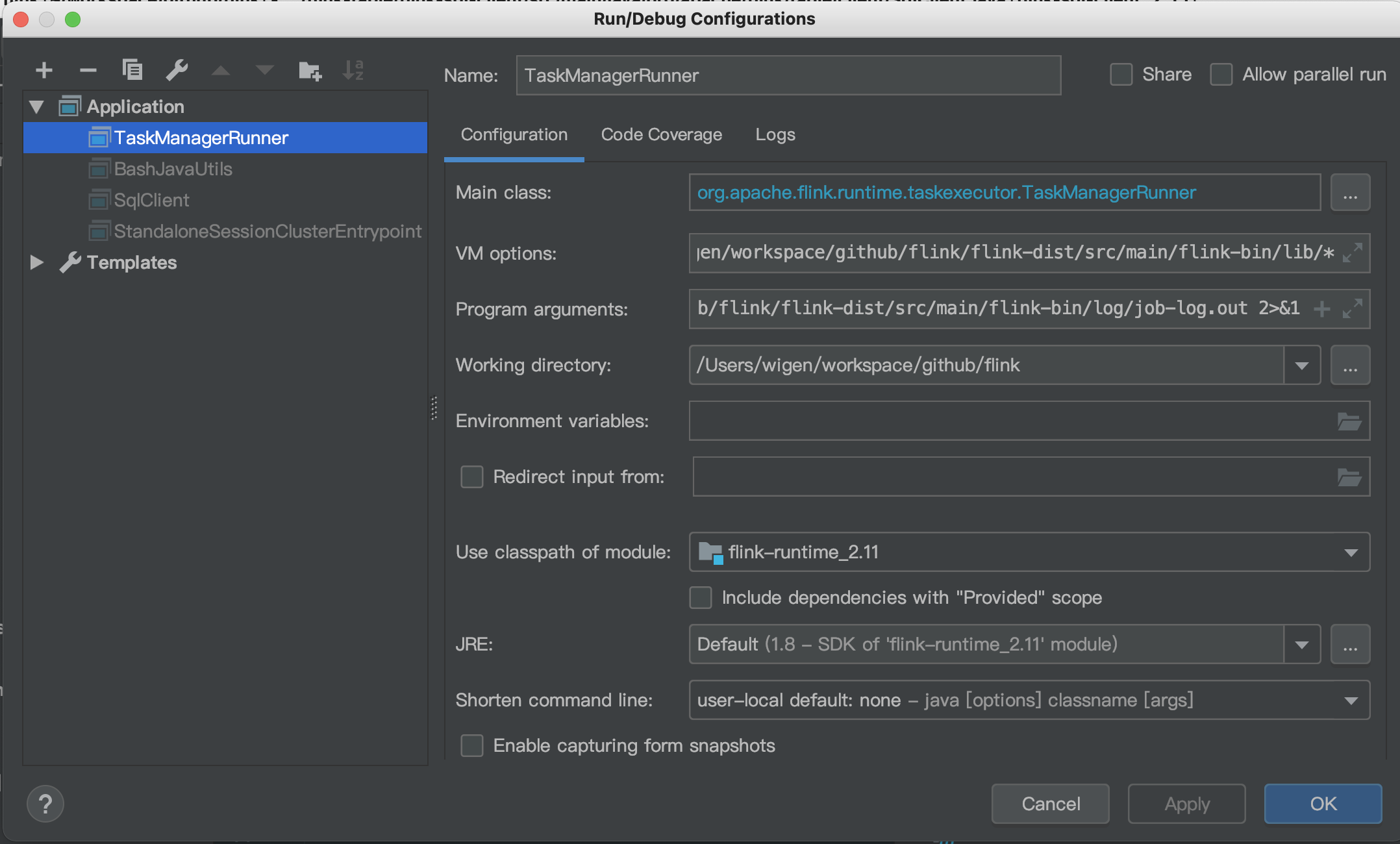
The above startup parameters need to replace the flink directory address
After the startup is completed, localhost:8081 check whether the startup is successful. If it is not successful, check the startup log in the log under Flink bin
SQL client startup
Still use the previous startup mode/ sql-client.sh embedded. You can also see SQL client SH to configure the startup parameters of SqlClient
test data
The statement construction sentence has been slightly changed because the mq field TS sent by kafka is in the format of "yyyy MM DD HH: mm: SS". The original statement construction can not be converted by parsing ts, so it has been adjusted
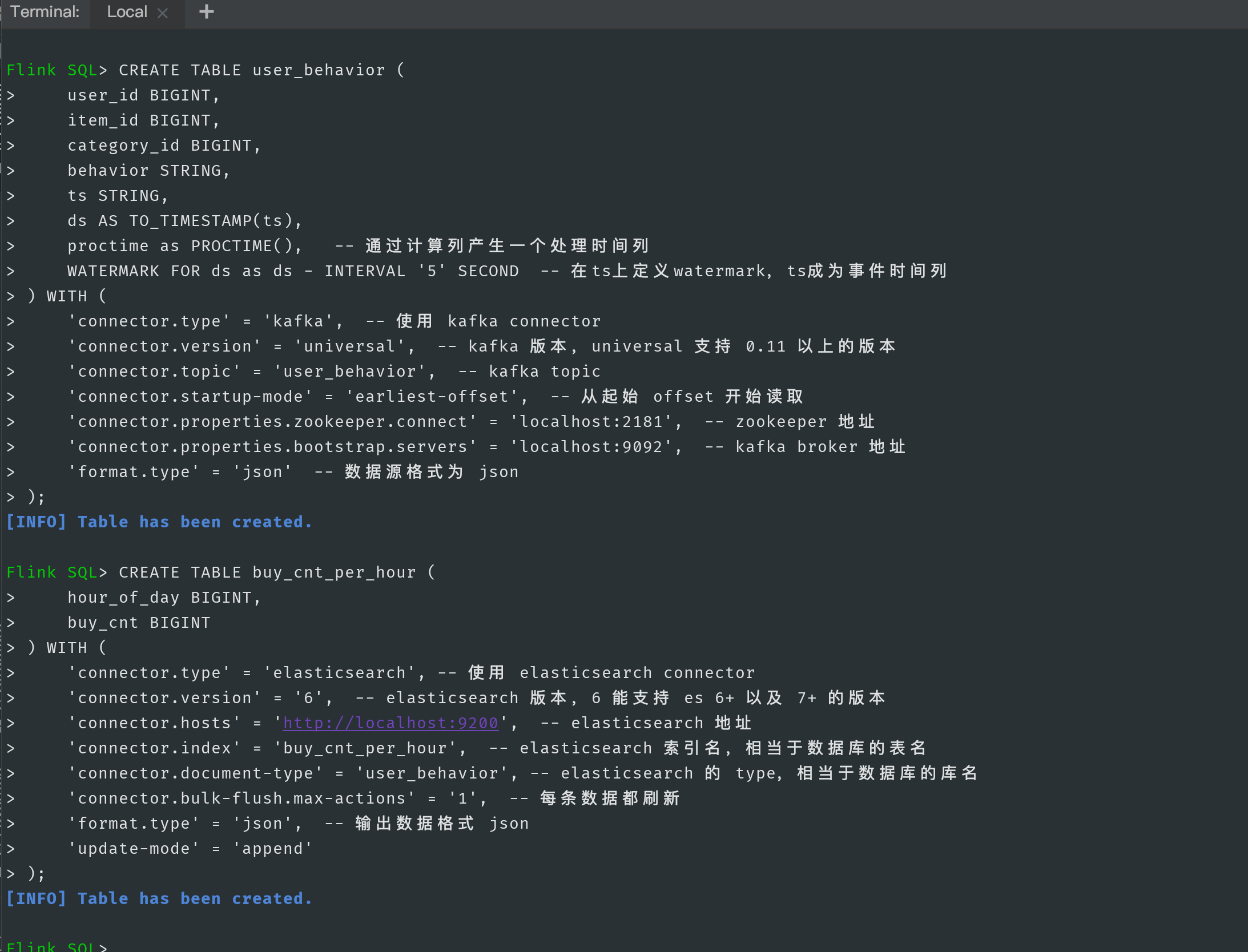
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts STRING,
ds AS TO_TIMESTAMP(ts),
proctime as PROCTIME(), -- A processing time column is generated by calculating the column
WATERMARK FOR ds as ds - INTERVAL '5' SECOND -- stay ts Upper definition watermark,ts Become event time column
) WITH (
'connector.type' = 'kafka', -- use kafka connector
'connector.version' = 'universal', -- kafka edition, universal Support 0.11 Version above
'connector.topic' = 'user_behavior', -- kafka topic
'connector.startup-mode' = 'earliest-offset', -- From start offset Start reading
'connector.properties.zookeeper.connect' = 'localhost:2181', -- zookeeper address
'connector.properties.bootstrap.servers' = 'localhost:9092', -- kafka broker address
'format.type' = 'json' -- The data source format is json
);
CREATE TABLE buy_cnt_per_hour (
hour_of_day BIGINT,
buy_cnt BIGINT
) WITH (
'connector.type' = 'elasticsearch', -- use elasticsearch connector
'connector.version' = '6', -- elasticsearch Version 6 can support es 6+ And 7+ Version of
'connector.hosts' = 'http://Localhost: 9200 ', -- elasticsearch address
'connector.index' = 'buy_cnt_per_hour', -- elasticsearch Index name, which is equivalent to the table name of the database
'connector.document-type' = 'user_behavior', -- elasticsearch of type,Equivalent to the database name
'connector.bulk-flush.max-actions' = '1', -- Every data is refreshed
'format.type' = 'json', -- Output data format json
'update-mode' = 'append'
);
INSERT INTO buy_cnt_per_hour SELECT HOUR(TUMBLE_START(ds, INTERVAL '1' HOUR)), COUNT(*) FROM user_behavior WHERE behavior = 'buy' GROUP BY TUMBLE(ds, INTERVAL '1' HOUR);
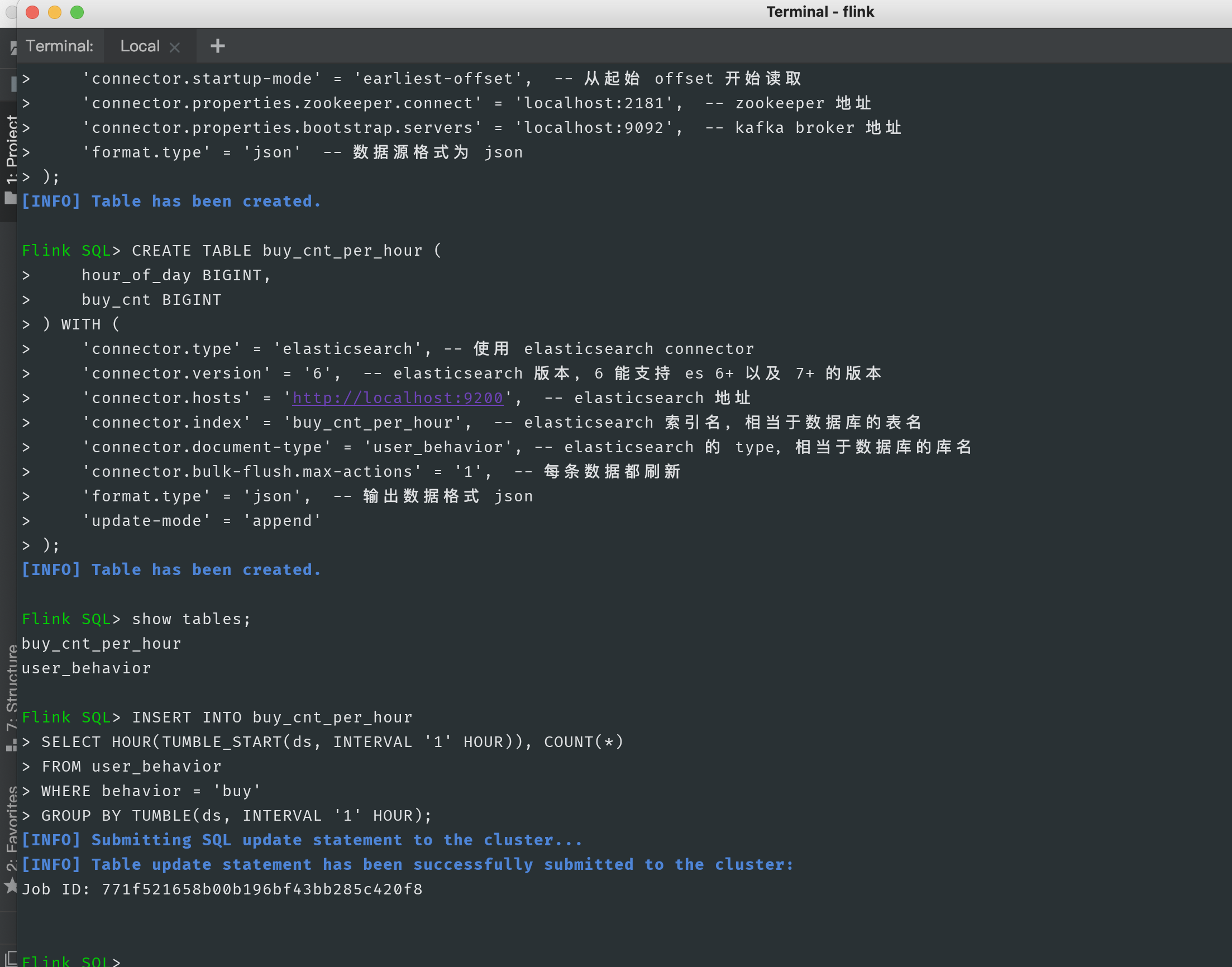
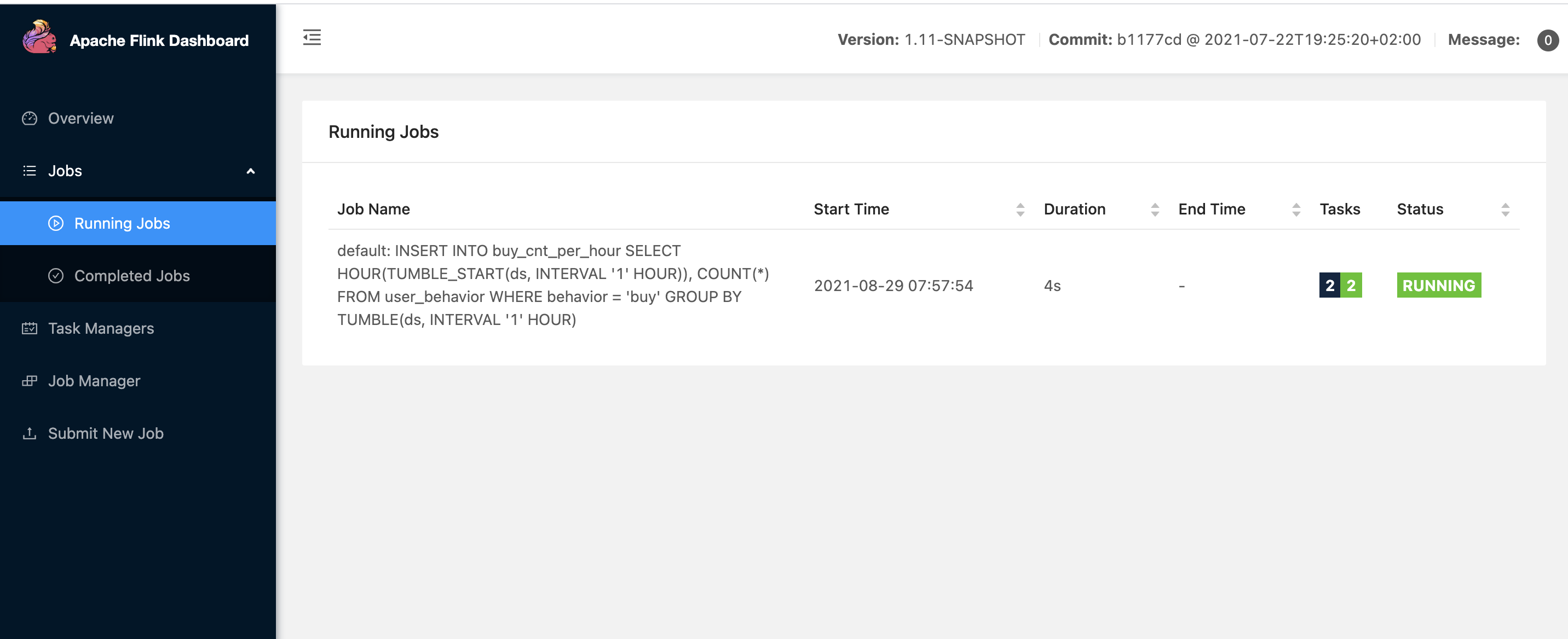
Use show tables; Command to view the table creation and submit SQL jobs. At this time, you can view the submitted jobs on the flink console. If the operation fails, you can view the log
Push kafka data
At docker compose YML directory execution
docker-compose exec kafka bash -c 'kafka-console-consumer.sh --topic user_behavior --bootstrap-server kafka:9094 --from-beginning --max-messages 10'
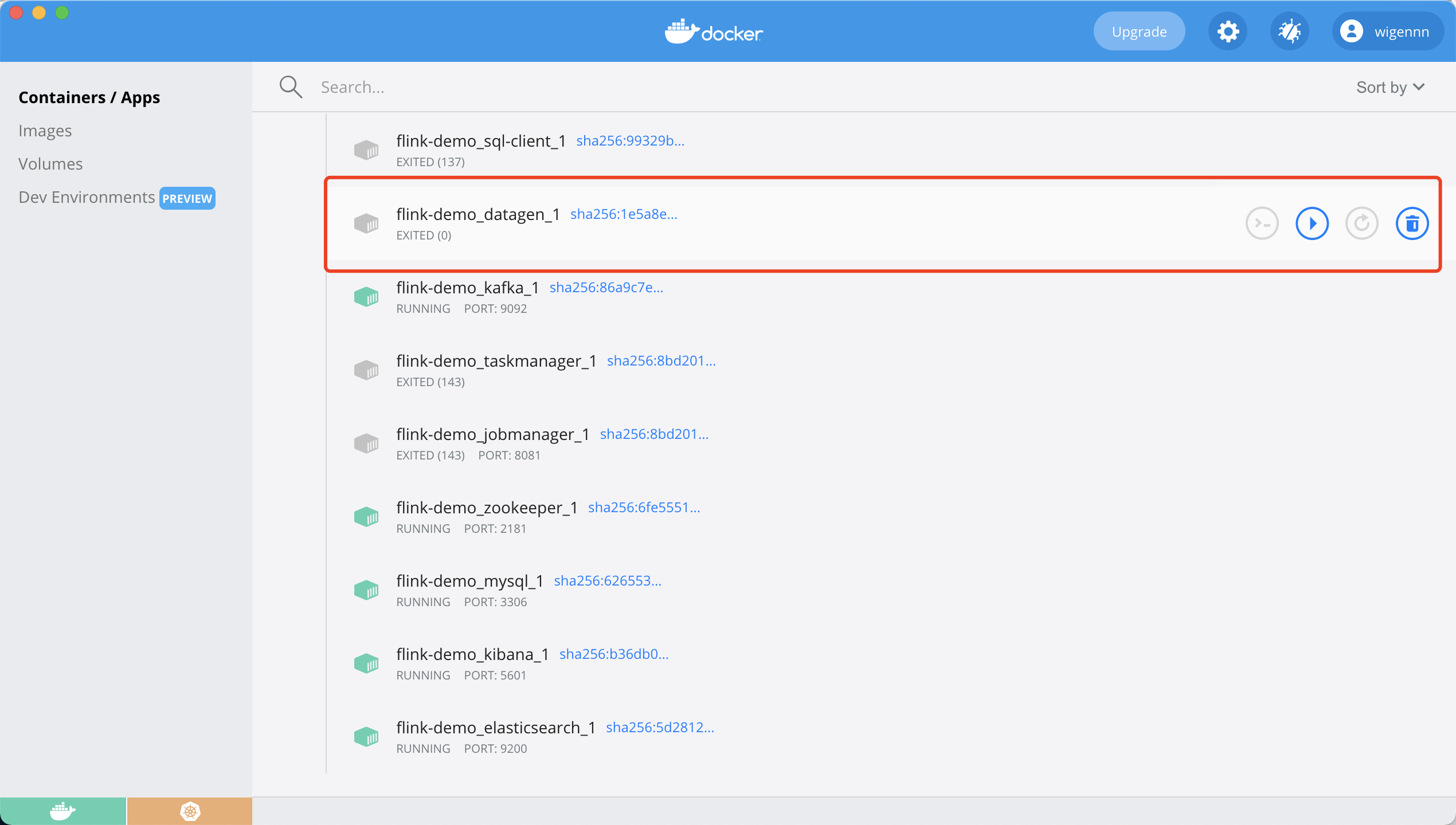
Or start datagen on docker dashboard
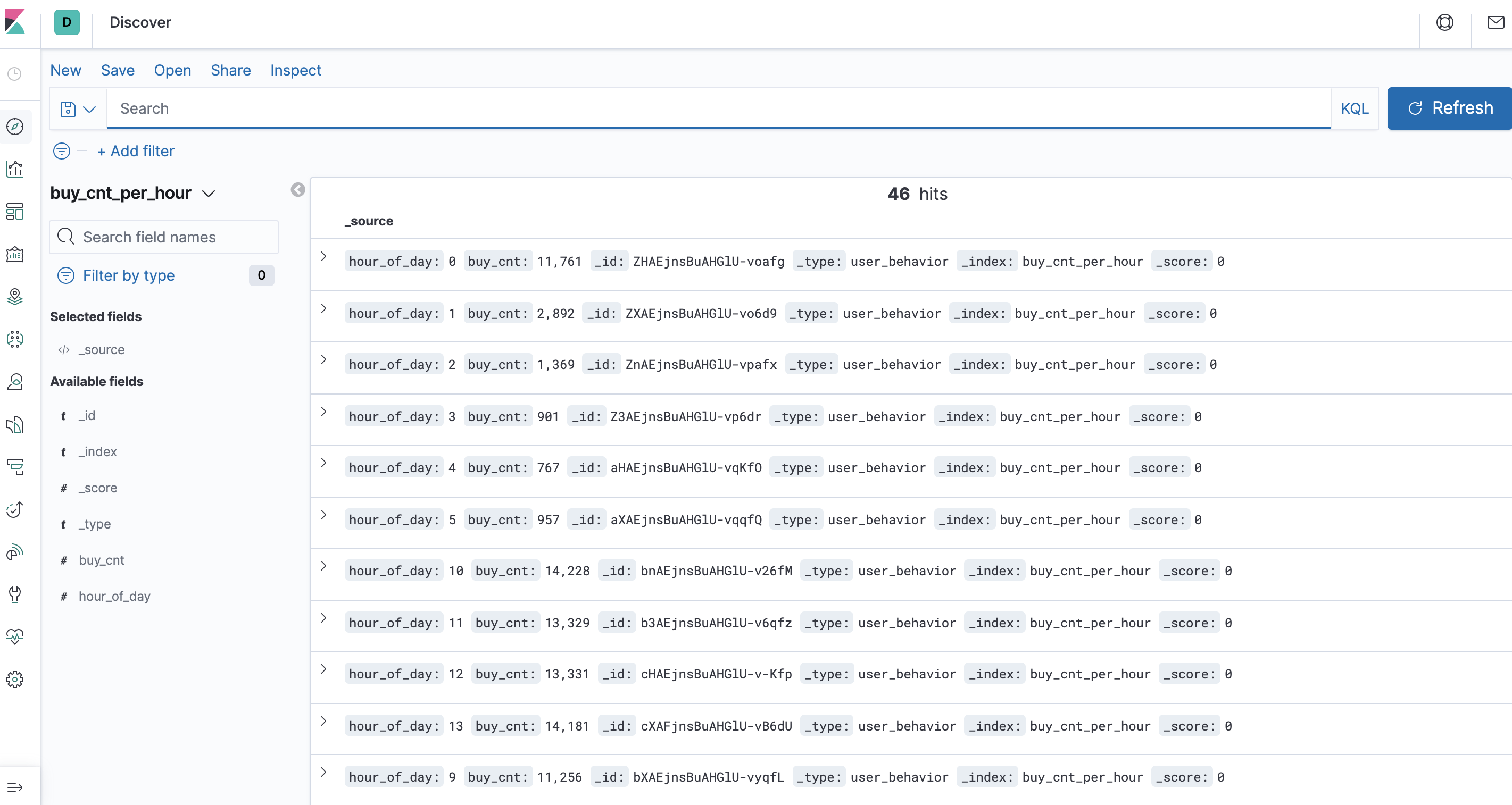
Localhost: kibana view data on 5601
end
So far, I have a general understanding of the whole Flink SQL operation process. If you want to further understand the source code, you can start debug with the source code