Welcome to the blog home page: https://blog.csdn.net/u013411339
Welcome to like, collect, leave messages, and exchange messages!
This article was originally written by [Wang Zhiwu] and started on CSDN blog!
This article is the first CSDN forum. It is strictly prohibited to reprint without the permission of the official and myself!

This article is right [hard big data learning route] learning guide for experts from zero to big data (fully upgraded version) The interview part of.
Since 2010, offline computing represented by Hadoop and Hive has entered the vision of major companies in the field of big data. The field of big data has begun to develop in full swing. I personally began to pay attention to the technical iteration and update in the field of big data when I was in school, and I was lucky to become a developer in the field of big data after graduation.
In the past few years, real-time computing technologies represented by Storm, Spark and Flink have followed. In 2019, Alibaba's internal Flink was officially open source. The whole real-time computing field is surging, and some ordinary developers begin to contact Flink because of business needs or personal interests.
Apache Flink (hereinafter referred to as Flink) has changed the defects criticized by people in the field of real-time computing in the past. With its powerful computing power and advanced design concept, Flink has quickly become the representative of advanced productivity in the field of real-time computing. Companies of all sizes have begun to explore Flink's applications. The two most remarkable directions are real-time computing platform and real-time data warehouse.
Flink real time computing
If you are a developer in the big data field or a back-end developer, you should be familiar with the following demand scenarios:
I am a voice recorder. I want to see the ranking tiktok. I'm an operator. I want to see how our company sells goods TOP10?I'm a developer. I want to see the operation of servers in all production environments of our company?......
In the Hadoop era, our usual practice is to batch store data in HDFS and produce offline reports with Hive. Or we can use a database like ClickHouse or PostgreSQL to store production data and use SQL to directly summarize and view it.
So what's wrong with this approach?
First, Hive based offline report form. With the continuous enrichment of business scenarios in most companies, and after years of practice in the industry, the offline storage system based on Hadoop is mature enough. However, the natural timeliness of offline computing is not strong. It is generally the lag of the next day. The value of business data will gradually decrease with the passage of practice. More and more scenarios need to use real-time computing. In this context, the demand for real-time computing platform came into being.
The second method is to perform summary query directly based on ClickHouse or PostgreSQL. This situation is very common in some small-scale companies. The only reason is that the amount of data is not large enough. In the process of using our commonly used database with OLAP characteristics, if we directly use complex SQL query under a certain amount of data, a complex SQL is enough to cause severe jitter or even direct downtime of the database, which will have a devastating impact on the production environment. This kind of query is firmly prohibited in large companies.
Therefore, the demand for consuming real-time data based on Flink's powerful real-time computing power came into being. In the real-time data platform, Flink will collect, calculate and send real-time data to the downstream.
Flink real time data warehouse
Data warehouse originally refers to the collection of tables in Hive that we store. According to business requirements, it is generally divided into original layer, detail layer, summary layer and business layer. Each company will have a more detailed division according to the actual business needs.
The traditional method of off-line data warehouse is to clean, convert and load the data according to the fixed computing logic after the data is stored off-line on a daily basis. Finally, it is used to produce reports according to business needs or provide them to other applications. We can obviously see that the data has a delay of at least T+1 days, which greatly reduces the timeliness of the data.
At this time, real-time data warehouse came into being. The architecture diagram of a typical real-time data warehouse is as follows:
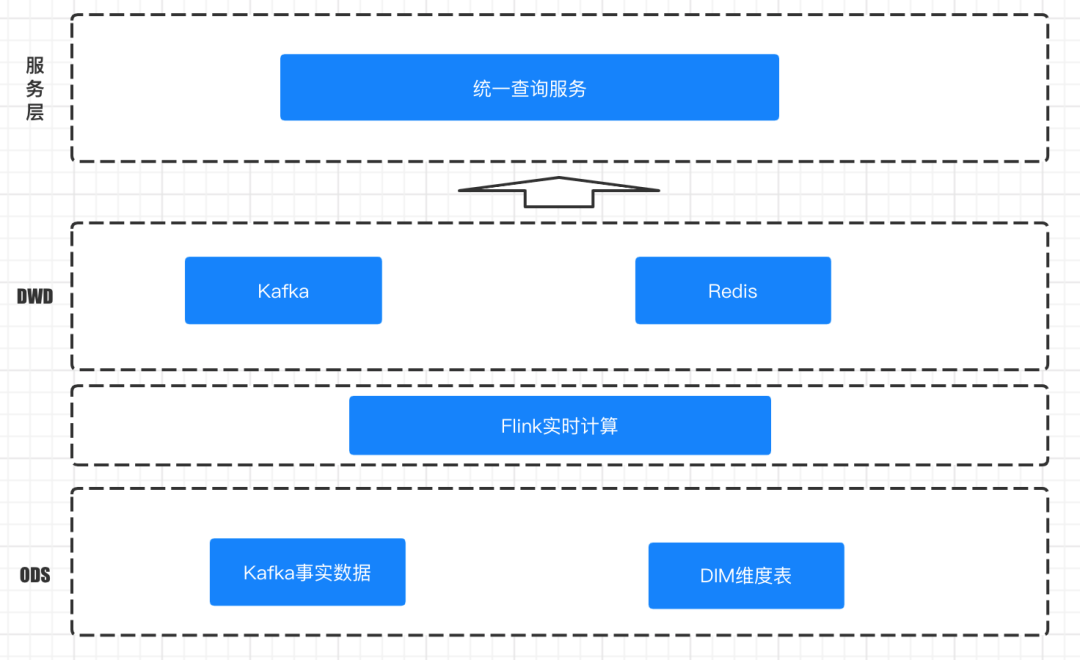
Technology selection
In this part, the author explains how to select the technology of each part of the real-time computing platform and real-time data warehouse based on his own experience in technology selection and practical application in the production environment of companies such as Alibaba.
Real time computing engine
As we mentioned above, the most important problem solved by real-time computing is real-time and stability.
Real time computing requires very high stability and accuracy of data, especially the large data screen for the public and third parties. At the same time, it requires high throughput, low delay, extremely high stability and absolute zero error. The transaction records promoted by e-commerce at any time are refreshed again and again, behind which is the peak QPS of tens of thousands or even hundreds of thousands of orders, payments and shipments.
Can you imagine such a scene? On tmall's double 11, the large screen of real-time transaction amount under the spotlight suddenly got stuck and didn't respond. I guess all developers will be fired
We take one of the most common and classic real-time computing large screens as an example.
In the large data screen for actual operation, it is necessary to provide up to dozens of dimensions of data, and the amount of data per second is up to tens of millions or even billions, which puts forward quite high requirements for our real-time computing architecture. So how can the real-time processing behind our large screen achieve high throughput, low delay, high stability and absolute zero error in this data volume scale?
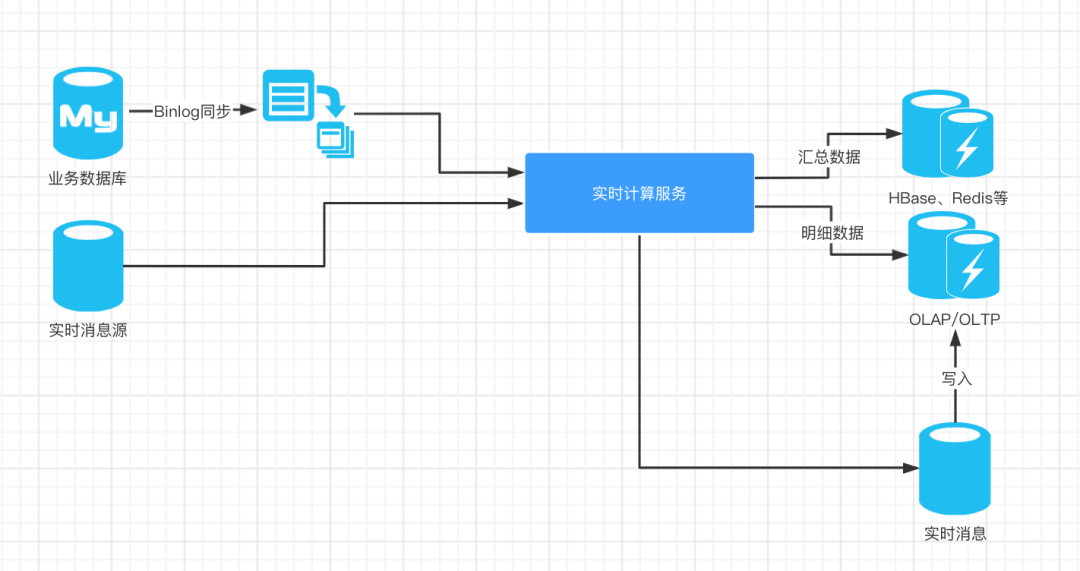
In the architecture diagram above, several key technology types are involved, which will be explained one by one below.
Business Library Binlog synchronization tool - Canal
Our real-time computing architecture is generally based on business data, but neither real-time computing large screen nor conventional data analysis report can affect the normal operation of business. Therefore, message middleware or incremental synchronization framework Canal need to be introduced here.
Most of the business data in our production environment are based on MySQL, so we need a tool that can monitor the changes of MySQL business data in real time. Canal is Alibaba's open source database Binlog log log parsing framework. Its main purpose is to provide incremental data subscription and consumption based on MySQL database incremental log parsing.
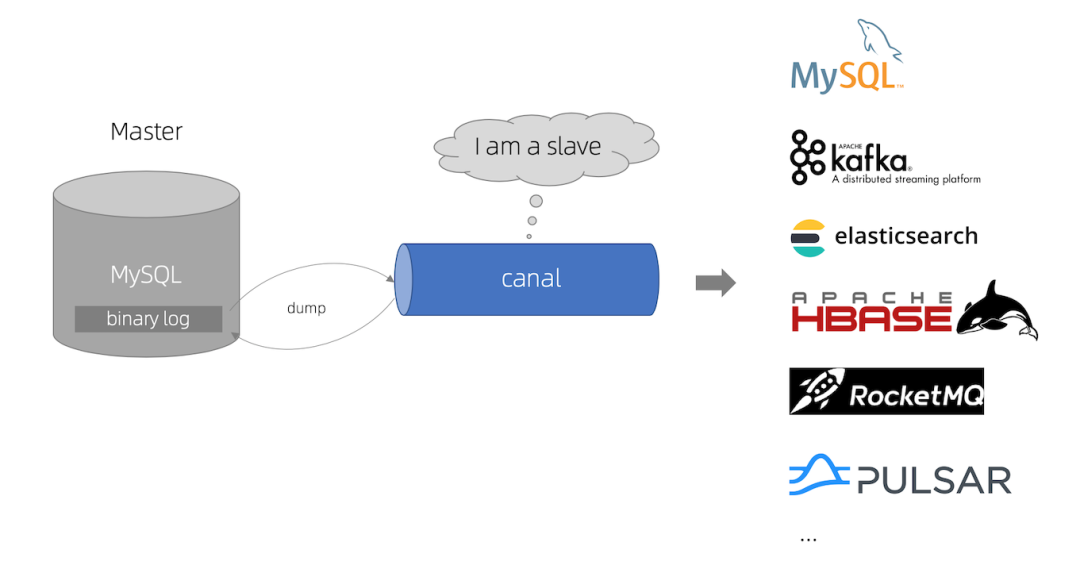
The principle of canal is also very simple. It will disguise as a slave Library of a database to read and parse Binlog. Canal has large-scale applications in Alibaba, because Alibaba has a large number of businesses deployed across machine rooms, and a large number of businesses need business synchronization. Canal has powerful functions and stable performance.
Decoupling and massive data support - Kafka
Under the technical architecture of real-time large screen, our data sources are mostly messages. We need a powerful message middleware to support hundreds of thousands of QPS and massive data storage.
First, why do we need to introduce message oriented middleware? Mainly for the following three purposes:
-
Synchronous mutation step
-
Application decoupling
-
Flow peak clipping
In our architecture, in order to isolate business data from each other, we need to use message oriented middleware to decouple them without affecting each other. In addition, in the double 11 and other big promotion scenarios, the transaction peak usually occurs in a certain period of time, during which the system pressure increases sharply, the amount of data rises sharply, and the message middleware also plays a role in reducing the peak.
Why Kafka?
Kafka, originally developed by Linkedin, is a distributed, high throughput, multi partition message middleware. After a long period of iteration and practice, Kafka has become the mainstream distributed message engine because of its unique advantages. It is often used as enterprise message bus, real-time data storage and so on.
Kafka stands out from many message oriented middleware mainly because of its high throughput and low latency; In addition, the Kafka based ecosystem is becoming more and more perfect, and various real-time processing frameworks, including Flink, will give priority to supporting message processing. And Flink and Kafka can realize the principle of end-to-end precise one-time semantics.
As an indispensable member of the big data ecosystem, Kafka's main characteristics are as follows.
-
High throughput:
It can meet the production and consumption of millions of messages per second, and can ensure the linear expansion of data processing capacity through horizontal expansion.
-
Low latency:
The message persistence capability is provided with a time complexity of O(1), which can ensure the access performance of constant time complexity even for data above TB.
-
High fault tolerance:
Kafka allows the node of the cluster to fail.
-
Reliability:
Messages can be persisted to the disk according to the policy, and the reading and writing efficiency is very high.
-
Rich ecology:
The surrounding ecology of Kafka is extremely rich, which is closely combined with various real-time processing frameworks.
Real time computing services - Flink
Flink mainly undertakes message consumption, dimension table Association, message sending, etc. in the current architecture. In the field of real-time computing, Flink's advantages mainly include:
-
Powerful state management.
Flink uses State to store intermediate states and results, and has strong fault tolerance;
-
Very rich API.
Flink provides powerful APIs including DataSet API, DataStream API, Flink SQL, etc;
-
Perfect ecological support.
Flink supports multiple data sources (Kafka, MySQL, etc.) and storage (HDFS, ES, etc.), and is integrated with other frameworks in the field of big data;
-
Batch flow integration.
Flink has been unifying the API of stream computing and batch computing, and supports direct writing to Hive.
We won't expand too much on some features of Flink. It should be noted here that after consumption, Flink will generally send the calculation result data to three directions:
-
High summary. High summary indicators are generally stored in Redis and HBase for front-end direct query.
-
Detailed data. In some scenarios, our operators and business personnel need to query the detailed data. Some detailed data are extremely important. For example, some packages sent on the double eleventh day will be lost and damaged.
-
After the calculation of real-time messages, Flink sends a downstream message to the message system, which is mainly used to provide other services for reuse;
In addition, in some cases, we need to go through the message system again to drop the detailed data. The original direct drop is divided into two steps to facilitate problem location and troubleshooting.
Let a hundred flowers bloom - OLAP database selection
The choice of OLAP is the most controversial and difficult in the current real-time architecture. At present, the mainstream open source OLAP engines on the market include but are not limited to: Hive, Hawq, Presto, Kylin, Impala, SparkSQL, Druid, Clickhouse, greeplus, etc. it can be said that at present, no engine can achieve perfection in data volume, flexibility and performance. Users need to select according to their own needs.
I once wrote in a previous article Real time data warehouse what you need is a powerful OLAP engine This paper analyzes the selection of the mainstream OLAP database in the market with 20000 words. Here is a direct conclusion:
-
Hive,Hawq,Impala:
Based on SQL on Hadoop
-
Presto is similar to Spark SQL:
Generate execution plan based on memory parsing SQL
-
Kylin:
Space for time, pre calculation
-
Druid:
Data real-time ingestion plus real-time calculation
-
ClickHouse:
HBase in OLAP has great advantages in single table query performance
-
Greenpulm:
PostgreSQL in OLAP domain
If your scenario is an offline computing task based on HDFS, Hive, Hawq and Imapla are your research objectives.
If your scenario solves distributed query problems and has certain real-time requirements, Presto and SparkSQL may be more in line with your expectations.
If your summary dimension is relatively fixed and requires high real-time performance, you can pre calculate through the user configured dimension + indicator, you might as well try Kylin and Druid.
ClickHouse takes the lead in single table query performance, far surpassing other OLAP databases.
As a relational database product, Greenplum's performance can grow linearly with the expansion of the cluster, which is more suitable for data analysis.
Flink real time data warehouse
The development of real-time data warehouse has experienced the development from offline to real-time. A typical real-time data warehouse architecture is as follows:
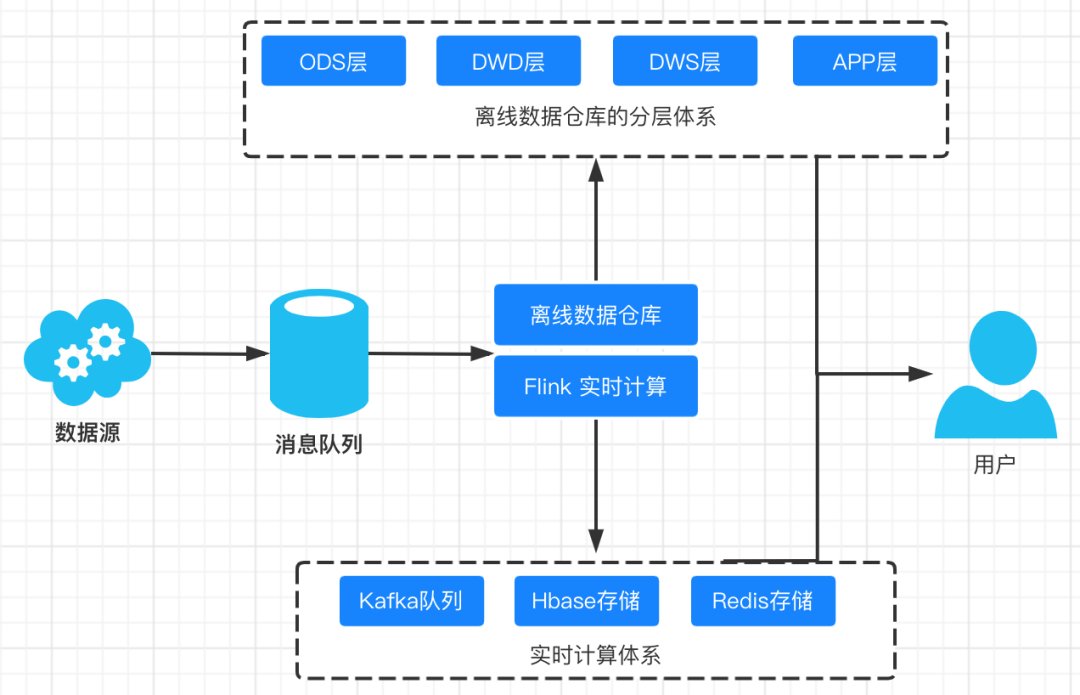
The design of general real-time data warehouse also draws lessons from the concept of offline data warehouse. We should not only improve the reuse rate of our model, but also consider the stability and ease of use of real-time data warehouse.
In the technology selection of real-time data warehouse, the core technologies used include Kafka, Flink, Hbase, etc.
Among them, the advantages of Kafka and Flink have been introduced in detail in the technical selection of the above real-time data platform. There are also two key indicators: Hbase and Redis.
Among them, Hbase is a typical column distributed storage system, and Redis is the first choice in the cache system. Their main advantages include:
-
Strong consistency
-
Automatic failover and fault tolerance
-
Extremely high read-write QPS, which is very suitable for storing indicators in K-V form
Batch flow integration is the future
With the release of Flink version 1.12, the integration of Flink and Hive has reached a new level. Flink can easily read and write Hive directly.
What does this mean?
As long as we are still using real-time data warehouse, we can read and write Hive directly. Flink has become a processing engine on Hive, either in batch or stream. From Flink 1.12, a large number of offline real-time integrated data warehouses will appear.
Our data warehouse architecture becomes:
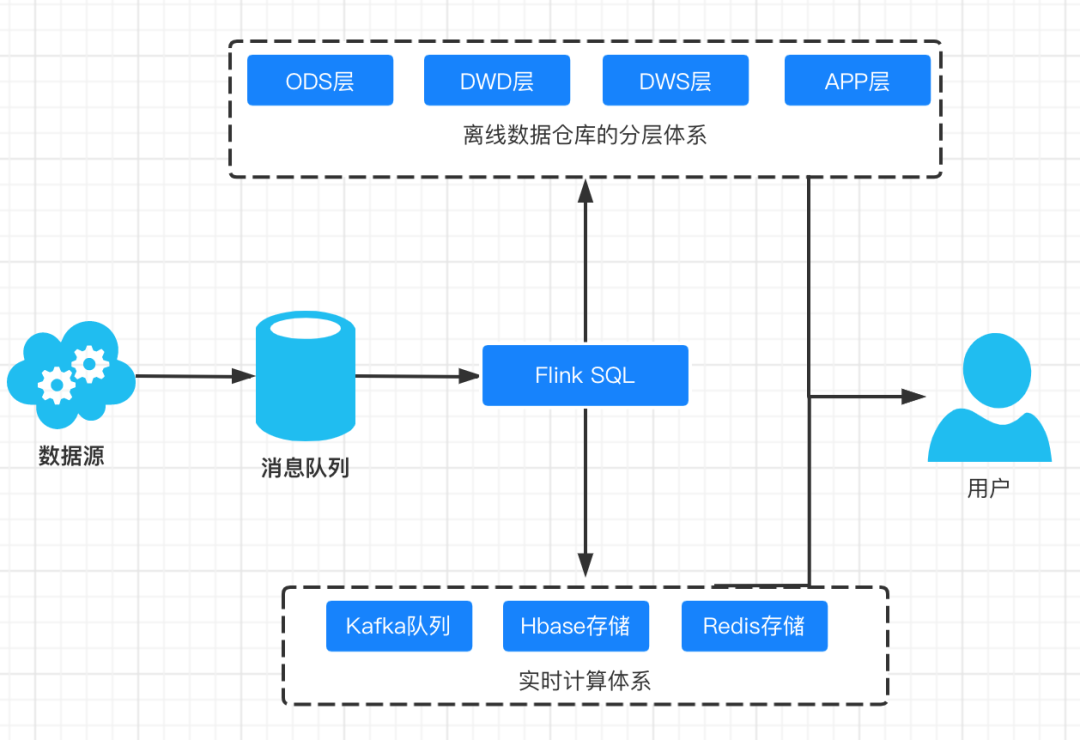
Flink SQL unifies the logic of real-time and offline, avoids the need for two sets of architecture and code support for offline and real-time, and basically solves the embarrassing situation of uneven offline and real-time data.
Real time computing platform and real-time warehouse technology scheme of large factories
Combined with their own experience in the actual production environment and referring to the real-time computing platform and real-time warehouse design of several major companies in the market, this part selects the most stable and commonly used technical scheme for everyone.
Author's experience
The typical Kappa architecture is adopted in our real-time computing architecture. Our business difficulties and priorities mainly focus on:
-
Too many data sources
We have dozens of real-time message sources, which are distributed in major production systems. The message data formats in these systems are different.
-
Time GAP between data sources is huge
Our business data needs to wait for each other. Take the simplest example. After placing an order, the user may operate after 7 days, which leads to a problem. When we build a real-time data warehouse, the intermediate State is huge. Directly using Flink's native State will lead to huge and unstable task resource consumption.
-
Offline data and real-time data require strong consistency
Our data will eventually be distributed in the form of assessment to directly guide the salary and bonus payment of front-line employees. Strong data consistency guarantee is required, otherwise it will cause complaints and even public opinion.
Based on the above considerations, our real-time data warehouse architecture is as follows:
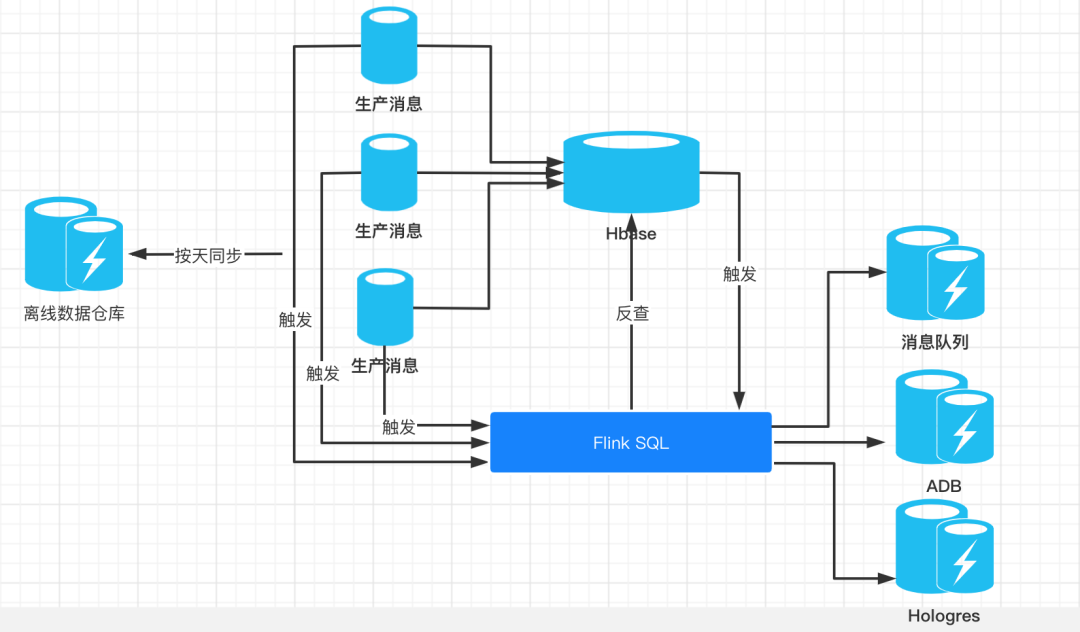
Several key technical points are as follows:
First, we use Hbase as the storage of intermediate states. We mentioned above that because the calculation in Flink SQL needs to store intermediate states, and our data sources are too many and the time gap is too large, the state storage of real-time calculation becomes extremely huge, and the task becomes very unstable under the impact of a large amount of data. In addition, if the task fails over, the status will be lost and the result will be seriously distorted. So all our data will be stored in Hbase.
Second, real-time data trigger mode calculation. In the logic of Flink SQL, the change message of Hbase is sent out. We only need to accept the rowkey information, and then all the data is checked against Hbase. As we mentioned in the above article, Hbase is widely used in real-time storage and high-frequency query by major companies because of its extremely high read-write QPS.
Third, double write ADB and Hologres. ADB and Hologres are powerful OLAP engines provided by Alibaba cloud. We double write the results after Flink SQL calculation, and the front-end query can be shunted and load balanced.
Fourth, offline data synchronization. Here, we use the middleware to synchronize messages directly. In the offline data warehouse, we have the same logic to write data into Hive. After Flink 1.12, offline and real-time computing logic are unified into one set, completely avoiding the inconsistency between offline and real-time messages.
However, objectively speaking, is there any problem with this data architecture?
-
This data architecture introduces Hbase as intermediate storage, and the data link becomes longer. As a result, the operation and maintenance cost increases greatly, and the real-time performance of the whole architecture is subject to whether the change information of Hbase can be sent in time.
-
Indicators are not layered, which will cause ADB and Hologres to become query bottlenecks. In this data architecture, we completely abandon the intermediate indicator layer and rely entirely on SQL direct summary query. On the one hand, it benefits from the accuracy of indicators after omitting the middle tier. On the other hand, direct SQL query will have great query pressure on ADB, which makes ADB consume huge resources and costs.
In future planning, we hope to grade business SQL. Indicators and data with high priority and high real-time performance can be directly queried in the database. Non high priority and high real-time indicators can assemble results by combining historical data with real-time data to reduce the query pressure on the database.
Design of Tencent's real-time data system
Tencent watch data center undertakes the development, retrieval and viewing needs of Tencent QQ watch, applet, browser, express and other services. The amount of data reported by Tencent in one day can reach trillions, which brings great technical challenges to low latency, sub second real-time computing and multi-dimensional query.
First, let's take a look at the architecture design of Tencent's real-time data system:
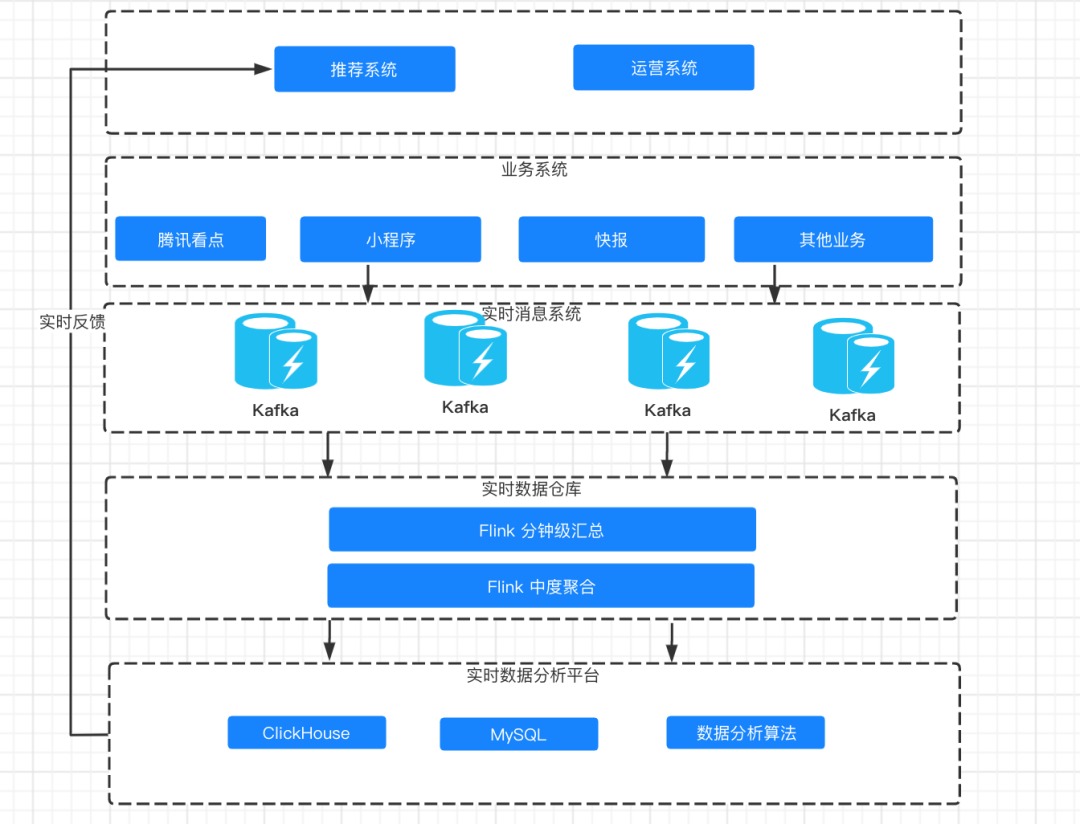
The above figure is the overall real-time architecture design of Tencent. We can see that the overall architecture is divided into three layers:
-
Data acquisition layer
In this layer, Tencent focuses on using the message queue Kafka to understand the coupling operation and avoid reading the business system data directly.
-
Real time data warehouse layer
In this layer, Tencent focuses on using Flink to do minute level aggregation and moderate aggregation respectively, which greatly reduces the pressure of real-time SQL query.
-
Real time data storage layer
Tencent focuses on using ClickHouse and MySQL as real-time data storage. We will analyze the advantages and characteristics of ClickHouse as real-time data storage below.
As for data selection, Tencent chose Lambda architecture for the overall architecture of real-time data warehouse, mainly because of high flexibility, high fault tolerance, high maturity and very low migration cost.
In terms of real-time computing, Tencent chose Flink as the computing engine. The reasons why Flink is favored include exactly once semantic support, lightweight snapshot mechanism and high throughput. Another important reason is Flink's efficient dimension table Association, which supports real-time data flow (million / s) Association of HBase dimension tables.
In terms of data storage, Tencent focuses on the heavy use of ClickHouse. ClickHouse's advantages include:
-
Multi core CPU parallel computing
-
SIMD parallel computing acceleration
-
Distributed horizontal expansion cluster
-
Sparse index, column storage, data compression
-
Aggregation analysis optimization
Finally, Tencent's real-time data system supports sub second response to multi-dimensional conditional query requests:
-
In the past 30 minutes, 99% of the requests took less than 1 second
-
For content queries in the past 24 hours, 90% of requests took 5 seconds and 99% took 10 seconds
Alibaba batch flow integrated data warehouse construction
We introduced the advantages of Flink above. Especially after version 1.12 of Flink, the integration of Flink and Hive has reached a new level. Flink can easily read and write Hive directly.
Alibaba took the lead in realizing a real-time data warehouse integrating batch flow in its business. According to public data, Alibaba's exploration in batch flow integration mainly includes three aspects:
-
Unified metadata management
Flink has simplified the way to connect Hive since version 1.11. Flink communicates with Hive through a simple Hive catalog API. Makes it easy to access Hive.
-
Unified computing engine
In the construction of our traditional real-time data warehouse, based on the difference between offline and real-time engines, we need to write two sets of SQL for calculation and data warehousing. Flink efficiently solves this problem. It provides a unified syntax of batch and stream based on ANSI-SQL standard, and uses Flink engine to execute. It can read and write Hive and other OLAP databases at the same time.
-
Unified data storage
Under this architecture, offline data becomes the historical backup of real-time data, and offline data can also be ingested in real time as a data source. The scenario of batch computing becomes real-time scheduling, which no longer depends on scheduled scheduling tasks.
Based on the above work, the batch stream integrated real-time data warehouse based on Flink and Hive came into being. The overall architecture is as follows:
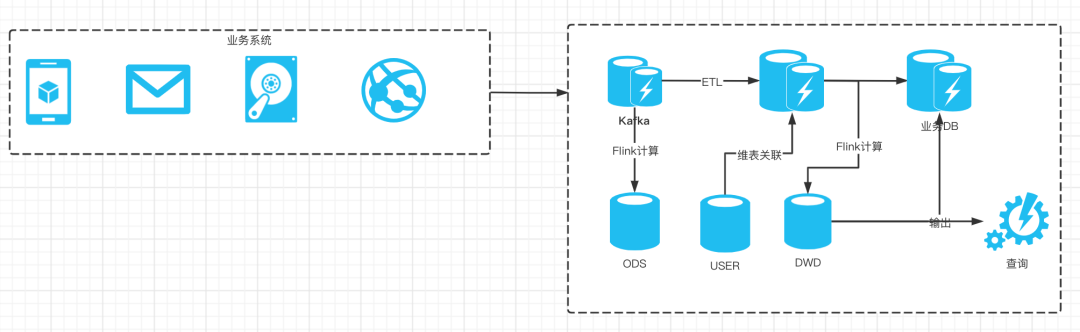
We can see that the original offline and real-time double write link has evolved into a single channel, and a set of code can complete offline and real-time computing operations. Moreover, based on Flink's support for SQL, code development has become extremely concise. Alibaba's batch flow integrated data warehouse was launched and put into use in 2020, with remarkable results, supporting the data demand of double 11.
Actual combat cases
In this part, we will introduce the architecture design, technology selection and final implementation in real-time computing based on a real-time statistics project. It involves log data embedding point, log data collection, cleaning, final index calculation and so on.
architecture design
Taking the PV and UV of the statistical website as an example, we involve several key processing steps:
-
Log data reporting
-
Log data cleaning
-
Real time computing program
-
Result storage
Based on the above business processing processes, the selection and architecture of our common real-time processing technologies are shown in the figure below:
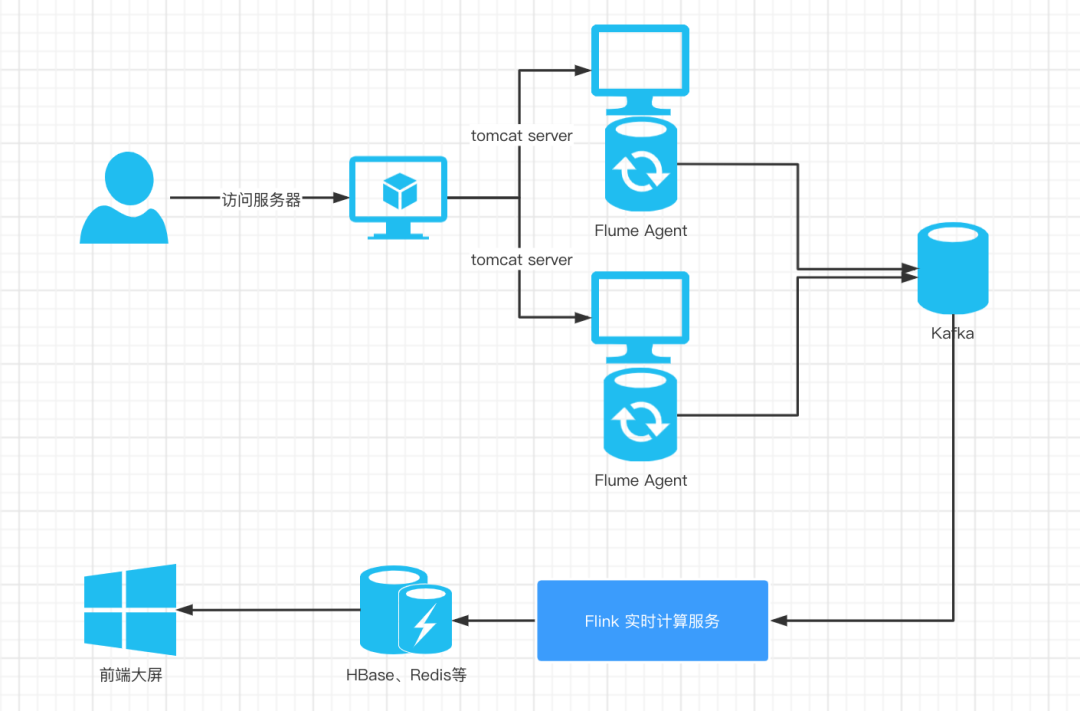
The overall code development includes:
-
Flume and Kafka integration and deployment
-
Kafka analog data generation and transmission
-
Flink and Kafka integrate time window design
-
Implementation of PV and UV code for Flink calculation
-
Flink and Redis integration and Redis Sink implementation
Flume and Kafka integration and deployment
We can download the installation package on Flume's official website. Here we can download a 1.8 0, and then unzip it:
tar zxf apache-flume-1.8.0-bin.tar.gz
You can see that there are several key directories, among which the conf / directory is the directory where we store the configuration files.
Next, we integrate Flume and Kafka. The overall integration idea is that our two Flume agents are deployed on two Web servers to collect the business logs of the two servers, and Sink to another Flume Agent, and then Sink the data to the Kafka cluster. Three Flume agents need to be configured here.
First, create configuration files on Flume Agent 1 and Flume Agent 2, modify the configuration of source, channel and sink, and VIM log_ kafka. The conf code is as follows:
#Define the name of each component in this {agent A1 sources = r1a1. sinks = k1a1. channels = c1
# Configure source to listen for new data in the log file A1 sources. r1. type = execa1. sources. r1. command = tail -F /home/logs/access. log
#sink configuration, using avro logs for data consumption A1 sinks. k1. type = avroa1. sinks. k1. hostname = flumeagent03a1. sinks. k1. port = 9000
#channel configuration, using files as temporary data cache A1 channels. c1. type = filea1. channels. c1. checkpointDir = /home/temp/flume/checkpointa1. channels. c1. dataDirs = /home/temp/flume/data
#Describe and configure the connection relationship between source channel sink A1 sources. r1. channels = c1a1. sinks. k1. channel = cThe above configuration will listen to / home / logs / access The data in the log file changes, and the data Sink to the 9000 port of flumegagent03.
Then we start Flume Agent 1 and Flume Agent 2 respectively. The commands are as follows:
$ flume-ng agent -c conf -n a1 -f conf/log_kafka.conf >/dev/null 2>&1 &
The third Flume Agent is used to receive the data of the above two agents and send it to Kafka. We need to start the local Kafka and create a log_kafka's Topic.
Then, we create a Flume configuration file and modify the configuration of source, channel and sink, VIM Flume_ kafka. The conf code is as follows:
# Define the name of each component in the agent A1 sources = r1a1. sinks = k1a1. channels = c1 #source configuration A1 sources. r1. type = avroa1. sources. r1. bind = 0.0. 0.0a1. sources. r1. port = 9000 #Sink configuration A1 sinks. k1. type = org. apache. flume. sink. kafka. KafkaSinka1. sinks. k1. topic = log_ kafkaa1. sinks. k1. brokerList = 127.0. 0.1:9092a1. sinks. k1. requiredAcks = 1a1. sinks. k1. batchSize = 20 #channel configuration A1 channels. c1. type = memorya1. channels. c1. capacity = 1000a1. channels. c1. transactionCapacity = 100 #Describe and configure the connection relationship between source channel sink A1 sources. r1. channels = c1a1. sinks. k1. channel = c1
After configuration, we start the Flume Agent:
$ flume-ng agent -c conf -n a1 -f conf/flume_kafka.conf >/dev/null 2>&1 &
When Flume Agent 1 and 2 listen to new log data, the data will be sent to the Topic specified by Kafka by Sink, and we can consume the data in Kafka.
We now need to consume Kafka Topic information and convert the serialized message into the user's behavior object:
public class UserClick {
private String userId; private Long timestamp; private String action;
public String getUserId() { return userId; }
public void setUserId(String userId) { this.userId = userId; }
public Long getTimestamp() { return timestamp; }
public void setTimestamp(Long timestamp) { this.timestamp = timestamp; }
public String getAction() { return action; }
public void setAction(String action) { this.action = action; }
public UserClick(String userId, Long timestamp, String action) { this.userId = userId; this.timestamp = timestamp; this.action = action; }}
enum UserAction{ //Click CLICK("CLICK"), / / PURCHASE("PURCHASE"), / / other OTHER("OTHER");
private String action; UserAction(String action) { this.action = action; }}In the business scenario of calculating PV and UV, we choose to use the event time in the message as the time feature. The code is as follows:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// For checkpoint configuration, env must be configured if the state backend is used setStateBackend(new MemoryStateBackend(true));
Properties properties = new Properties();properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
properties.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS, "10");FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("log_user_action", new SimpleStringSchema(), properties);//Set the consumer from the earliest offset setStartFromEarliest();
DataStream<UserClick> dataStream = env .addSource(consumer) .name("log_user_action") .map(message -> { JSONObject record = JSON.parseObject(message); return new UserClick( record.getString("user_id"), record.getLong("timestamp"), record.getString("action") ); }) .returns(TypeInformation.of(UserClick.class));Because our user access log may be out of order, we use boundedoutordernesstimestampextractor to process out of order messages and delay time. We specify the out of order time of messages for 30 seconds. The specific code is as follows:
SingleOutputStreamOperator<UserClick> userClickSingleOutputStreamOperator = dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<UserClick>(Time.seconds(30)) { @Override public long extractTimestamp(UserClick element) { return element.getTimestamp(); }});So far, we have read the data in Kafka, serialized it into DataStream of user click events, and completed the design and development of watermark and timestamp.
Next, according to business needs, we need to open a window and calculate the PV and UV of user click events within a day. Here, we use the scrolling window provided by Flink and use the continuous processing time trigger to periodically trigger the periodic calculation of the window.
dataStream .windowAll(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))).trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(20)))
In order to reduce the amount of data cached in the window, we can group according to the day of the user's access timestamp, then disperse the data in each window for calculation, and then summarize it in the State.
First, we group the DataStream according to the day of the user's access time:
userClickSingleOutputStreamOperator .keyBy(new KeySelector<UserClick, String>() { @Override public String getKey(UserClick value) throws Exception { return DateUtil.timeStampToDate(value.getTimestamp()); } }) .window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))) .trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(20))) .evictor(TimeEvictor.of(Time.seconds(0), true)) ...Then it is grouped according to the day of the user's access time, and the evictor is called to eliminate the calculated data. DateUtil is the month, year and day of obtaining the timestamp:
public class DateUtil { public static String timeStampToDate(Long timestamp){ ThreadLocal<SimpleDateFormat> threadLocal = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")); String format = threadLocal.get().format(new Date(timestamp)); return format.substring(0,10); }}Next, we implement our own ProcessFunction:
public class MyProcessWindowFunction extends ProcessWindowFunction<UserClick,Tuple3<String,String, Integer>,String,TimeWindow>{
private transient MapState<String, String> uvState; private transient ValueState<Integer> pvState;
@Override public void open(Configuration parameters) throws Exception {
super.open(parameters); uvState = this.getRuntimeContext().getMapState(new MapStateDescriptor<>("uv", String.class, String.class)); pvState = this.getRuntimeContext().getState(new ValueStateDescriptor<Integer>("pv", Integer.class)); }
@Override public void process(String s, Context context, Iterable<UserClick> elements, Collector<Tuple3<String, String, Integer>> out) throws Exception {
Integer pv = 0; Iterator<UserClick> iterator = elements.iterator(); while (iterator.hasNext()){ pv = pv + 1; String userId = iterator.next().getUserId(); uvState.put(userId,null); } pvState.update(pvState.value() + pv);
Integer uv = 0; Iterator<String> uvIterator = uvState.keys().iterator(); while (uvIterator.hasNext()){ String next = uvIterator.next(); uv = uv + 1; }
Integer value = pvState.value(); if(null == value){ pvState.update(pv); }else { pvState.update(value + pv); }
out.collect(Tuple3.of(s,"uv",uv)); out.collect(Tuple3.of(s,"pv",pvState.value())); }}
We can directly use the custom ProcessFunction in the main program:
userClickSingleOutputStreamOperator .keyBy(new KeySelector<UserClick, String>() { @Override public String getKey(UserClick value) throws Exception { return value.getUserId(); } }) .window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))) .trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(20))) .evictor(TimeEvictor.of(Time.seconds(0), true)) .process(new MyProcessWindowFunction());
So far, we have calculated PV and UV. Next, we will explain how Flink and Redis integrate and implement Flink Sink.
Here, we directly use the open source Redis implementation. First, we add Maven dependencies as follows:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-redis_2.11</artifactId> <version>1.1.5</version></dependency>
Redis Sink can be customized by implementing RedisMapper. Here, we use HASH in redis as the storage structure. HASH in redis is equivalent to HashMap in Java language:
public class MyRedisSink implements RedisMapper<Tuple3<String,String, Integer>>{
/** * Set redis data type */ @Override public RedisCommandDescription getCommandDescription() { return new RedisCommandDescription(RedisCommand.HSET,"flink_pv_uv"); }
//Specify key @ override public string getkeyfromdata (tuple3 < string, string, integer > data) {return data. F1;}// Specify value @ override public string getvaluefromdata (tuple3 < string, string, integer > data) {return data. F2. Tostring();}}The above implements RedisMapper and overrides three methods: getCommandDescription, getKeyFromData and getValueFromData. getCommandDescription defines the data format stored in Redis. Here, we define RedisCommand as HSET and use HASH in Redis as the data structure; getKeyFromData defines the Key of HASH; getValueFromData defines the value of HASH.
Then we can directly call the addSink function:
...userClickSingleOutputStreamOperator .keyBy(new KeySelector<UserClick, String>() { @Override public String getKey(UserClick value) throws Exception { return value.getUserId(); } }) .window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))) .trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(20))) .evictor(TimeEvictor.of(Time.seconds(0), true)) .process(new MyProcessWindowFunction()) .addSink(new RedisSink<>(conf,new MyRedisSink()));...So far, we will save the results in Redis. We can choose to use different target databases in actual business, such as Hbase or MySQL.
summary
The real-time computing technology represented by Flink is still developing rapidly, and many new features such as Flink Hive Connector and CDC incremental synchronization continue to emerge. We have reason to believe that the development of real-time computing platform and real-time data warehouse based on Flink will shine in the future and solve the pain points of the industry in the field of real-time computing and real-time data warehouse, Become the representative of advanced productivity in the field of big data.