When doing target detection, I personally prefer VOC format data sets, so when encountering COCO format data sets, I am used to converting them to VOC and then processing them.
Let's first look at the conversion from coco format to voc format
Only the path and the jsonFileName list need to be modified, which have been clearly marked with comments.
'''
Author: TuZhou
Version: 1.0
Date: 2021-08-29 16:32:52
LastEditTime: 2021-08-29 17:44:57
LastEditors: TuZhou
Description:
FilePath: \My_Yolo\datasets\coco_to_voc.py
'''
from pycocotools.coco import \
COCO # This package can be downloaded from git https://github.com/cocodataset/cocoapi/tree/master/PythonAPI , you can also directly use the modified coco py
import os, cv2, shutil
from lxml import etree, objectify
from tqdm import tqdm
from PIL import Image
#voc format picture path to be generated
image_dir = './datasets/RoadSignsPascalVOC_Voc/images'
#voc format xml annotation path to generate
anno_dir = './datasets/RoadSignsPascalVOC_Voc/annotations'
#---------------------------------------------#
#The json type and file name of your coco format. The former represents the json of train type, and the latter represents the name of the json file. The type name should preferably be consistent with the name of your corresponding type image saving folder
#My json directory has only one train type. If you have a json file of the test set, it can be written as [['train ',' instance_train '], ['test', 'instance_test']]
jsonFileName = [['train', 'instance_train']]
#----------------------------------------------#
'''
Author: TuZhou
Description: If the model saving folder does not exist, create a model saving folder. If it exists, delete and rebuild
param {*} path Folder path
return {*}
'''
def mkr(path):
if os.path.exists(path):
shutil.rmtree(path)
os.mkdir(path)
else:
os.mkdir(path)
'''
Author: TuZhou
Description: preservation xml file
param {*} filename
param {*} objs
param {*} filepath
return {*}
'''
def save_annotations(filename, objs, filepath):
annopath = anno_dir + "/" + filename[:-3] + "xml" # Save path of generated xml file
#print("filename", filename)
dst_path = image_dir + "/" + filename
img_path = filepath
img = cv2.imread(img_path)
#Here, non RGB images are filtered and can be annotated
# im = Image.open(img_path)
# if im.mode != "RGB":
# print(filename + " not a RGB image")
# im.close()
# return
# im.close()
shutil.copy(img_path, dst_path) # Copy the original image to the destination folder
E = objectify.ElementMaker(annotate=False)
anno_tree = E.annotation(
E.folder('1'),
E.filename(filename),
E.source(
E.database('CKdemo'),
E.annotation('VOC'),
E.image('CK')
),
E.size(
E.width(img.shape[1]),
E.height(img.shape[0]),
E.depth(img.shape[2])
),
E.segmented(0)
)
for obj in objs:
E2 = objectify.ElementMaker(annotate=False)
anno_tree2 = E2.object(
E.name(obj[0]),
E.pose(),
E.truncated("0"),
E.difficult(0),
E.bndbox(
E.xmin(obj[2]),
E.ymin(obj[3]),
E.xmax(obj[4]),
E.ymax(obj[5])
)
)
anno_tree.append(anno_tree2)
etree.ElementTree(anno_tree).write(annopath, pretty_print=True)
def showbycv(coco, dataType, img, classes, origin_image_dir, verbose=False):
filename = img['file_name']
#NOTE:dataType indicates the name of the image folder of the training set or test set in coco format, but all my images are placed in the JPEGImages folder, so this is empty and can be modified if necessary
#dataType is the json type in jsonFileName. If your type name is consistent with your picture folder name, it can be annotated
dataType = ''
filepath = os.path.join(origin_image_dir, dataType, filename)
I = cv2.imread(filepath)
annIds = coco.getAnnIds(imgIds=img['id'], iscrowd=None)
anns = coco.loadAnns(annIds)
objs = []
for ann in anns:
name = classes[ann['category_id']]
if 'bbox' in ann:
bbox = ann['bbox']
xmin = (int)(bbox[0])
ymin = (int)(bbox[1])
xmax = (int)(bbox[2] + bbox[0])
ymax = (int)(bbox[3] + bbox[1])
obj = [name, 1.0, xmin, ymin, xmax, ymax]
objs.append(obj)
if verbose:
cv2.rectangle(I, (xmin, ymin), (xmax, ymax), (255, 0, 0))
cv2.putText(I, name, (xmin, ymin), 3, 1, (0, 0, 255))
save_annotations(filename, objs, filepath)
if verbose:
cv2.imshow("img", I)
cv2.waitKey(0)
def catid2name(coco): # Build a dictionary of names and id numbers
classes = dict()
for cat in coco.dataset['categories']:
classes[cat['id']] = cat['name']
# print(str(cat['id'])+":"+cat['name'])
return classes
'''
Author: TuZhou
Description:
param {*} origin_anno_dir original coco of json File directory
param {*} origin_image_dir original coco Image preservation directory
param {*} verbose
return {*}
'''
def get_CK5(origin_anno_dir, origin_image_dir, verbose=False):
for dataType, annoName in jsonFileName:
#annFile = 'instances_{}.json'.format(dataType)
annFile = annoName + '.json'
annpath = os.path.join(origin_anno_dir, annFile)
coco = COCO(annpath)
classes = catid2name(coco)
imgIds = coco.getImgIds()
# imgIds=imgIds[0:1000]#For testing, take 10 pictures and see the storage effect
for imgId in tqdm(imgIds):
img = coco.loadImgs(imgId)[0]
showbycv(coco, dataType, img, classes, origin_image_dir, verbose=False)
def main():
base_dir = './datasets/RoadSignsPascalVOC_Voc' # step1 here is a new folder for the converted images and xml annotations
image_dir = os.path.join(base_dir, 'images') # Generate two subfolders images and annotations in the above folder
anno_dir = os.path.join(base_dir, 'annotations')
mkr(image_dir)
mkr(anno_dir)
origin_image_dir = './datasets/RoadSignsPascalVOC/JPEGImages' # step 2 original coco image storage location
origin_anno_dir = './datasets/RoadSignsPascalVOC_Coco/Annotations' # step 3 marked storage location of original coco
verbose = True # Check whether the switch mark is correct. If it is true, the mark will be displayed on the picture
get_CK5(origin_anno_dir, origin_image_dir, verbose)
if __name__ == "__main__":
main()
Let's look at the conversion from voc format to coco format
import xml.etree.ElementTree as ET
import os
import json
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = -1
image_id = 20210000000
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_id += 1
image_item = dict()
image_item['id'] = image_id
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x,y,w,h
# left_top
seg.append(bbox[0])
seg.append(bbox[1])
# left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
# right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
# right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def parseXmlFiles(xml_path):
for f in os.listdir(xml_path):
if not f.endswith('.xml'):
continue
bndbox = dict()
size = dict()
current_image_id = None
current_category_id = None
file_name = None
size['width'] = None
size['height'] = None
size['depth'] = None
xml_file = os.path.join(xml_path, f)
print(xml_file)
tree = ET.parse(xml_file)
root = tree.getroot()
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
# elem is <folder>, <filename>, <size>, <object>
for elem in root:
current_parent = elem.tag
current_sub = None
object_name = None
if elem.tag == 'folder':
continue
if elem.tag == 'filename':
file_name = elem.text
if file_name in category_set:
raise Exception('file_name duplicated')
# add img item only after parse <size> tag
elif current_image_id is None and file_name is not None and size['width'] is not None:
if file_name not in image_set:
current_image_id = addImgItem(file_name, size)
print('add image with {} and {}'.format(file_name, size))
else:
raise Exception('duplicated image: {}'.format(file_name))
# subelem is <width>, <height>, <depth>, <name>, <bndbox>
for subelem in elem:
bndbox['xmin'] = None
bndbox['xmax'] = None
bndbox['ymin'] = None
bndbox['ymax'] = None
current_sub = subelem.tag
if current_parent == 'object' and subelem.tag == 'name':
object_name = subelem.text
if object_name not in category_set:
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
elif current_parent == 'size':
if size[subelem.tag] is not None:
raise Exception('xml structure broken at size tag.')
size[subelem.tag] = int(subelem.text)
# option is <xmin>, <ymin>, <xmax>, <ymax>, when subelem is <bndbox>
for option in subelem:
if current_sub == 'bndbox':
if bndbox[option.tag] is not None:
raise Exception('xml structure corrupted at bndbox tag.')
bndbox[option.tag] = int(option.text)
# only after parse the <object> tag
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
# x
bbox.append(bndbox['xmin'])
# y
bbox.append(bndbox['ymin'])
# w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
# h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with {},{},{},{}'.format(object_name, current_image_id, current_category_id,
bbox))
addAnnoItem(object_name, current_image_id, current_category_id, bbox)
if __name__ == '__main__':
xml_path = './datasets/RoadSignsPascalVOC/Annotations' # This is the address where the xml file is located
json_file = './datasets/RoadSignsPascalVOC_Coco/Annotations/train.json' # This is how you use xml_ json file generated from xml file under path
parseXmlFiles(xml_path) # Just change these two parameters
json.dump(coco, open(json_file, 'w'))
I haven't verified the converted json file in coco format in the training, but I transferred the converted json file back to voc format through the first code converted to voc, and there is no problem deploying it in the training.
Finally, let's look at how to deal with data sets in voc format
First, your voc format dataset directory should look like this:
-annotations
-ImageSets
--Main
-images
Where annotations is your xml annotation file and images is your picture directory.
Save the txt file after dividing the dataset in Main
Let's take a look at process_ dataset. Code in py:
'''
Author: TuZhou
Version: 1.0
Date: 2021-08-21 19:53:22
LastEditTime: 2021-08-29 17:05:35
LastEditors: TuZhou
Description: Divide the dataset xml The annotation information in the file is extracted and the picture path is saved to a new location txt In the file
FilePath: \My_Yolo\datasets\process_dataset.py
'''
from pathlib import Path
import yaml
import xml.etree.ElementTree as ET
from os import getcwd
import os
import random
random.seed()
#Path to the custom dataset configuration file
yaml_path = './cfg/dataset.yaml'
#----------------------------------------------------------------------#
# To add a test set, modify trainval_percent
# train_percent does not need to be modified
#----------------------------------------------------------------------#
trainval_percent = 0.9 #Proportion of training set + verification set in all data sets
train_percent = 1 #The ratio of training set + verification set is 1 by default
'''
Author: TuZhou
Description: Read dataset configuration file
param {*} yaml_path
return {*}Returns the information dictionary in the configuration file
'''
def read_dataset_yaml(yaml_path = './cfg/dataset.yaml'):
yaml_file = Path(yaml_path)
with open(yaml_file, encoding='utf-8') as f:
yaml_dict = yaml.safe_load(f)
return yaml_dict
'''
Author: TuZhou
Description: Divide the training set, verification set and test set from the data set, txt File saved in ImageSets of Main Folder
param {*} xmlfilepath data set xml Dimension file save path
param {*} saveSplitePath Data set partition txt File save path
return {*}
'''
def splite_dataset(xmlfilepath, saveSplitePath):
#Read all xml files and store them in the list
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
#Total number of pictures
num = len(total_xml)
list = range(num)
numbers_tv = int(num * trainval_percent) #Get the number of training and validation sets
numbers_train = int(numbers_tv * train_percent)
random.seed()
trainval = random.sample(list, numbers_tv) #Select the random list from the list to generate the training verification set
random.seed()
train = random.sample(trainval, numbers_train) #Select a random list from the training verification set to generate the training set
print("train and val size: ", numbers_tv)
print("train size: ", numbers_train)
print("test size: ", num - numbers_tv)
ftrainval = open(os.path.join(saveSplitePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveSplitePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveSplitePath,'train.txt'), 'w')
fval = open(os.path.join(saveSplitePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
def convert_annotation(xmlfilepath, image_id, list_file, classes):
#in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id), encoding='utf-8')
in_file = open(xmlfilepath + '%s.xml'%(image_id), encoding='utf-8')
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = 0
if obj.find('difficult')!=None:
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
#print(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
def save_dataset_info(yaml_dict):
wd = getcwd()
sets = yaml_dict['sets']
saveSplitePath = yaml_dict['saveSplitePath']
xmlfilepath = yaml_dict['xmlfilepath']
processedPath = yaml_dict['DatasetPath']
ImagesDir = yaml_dict['ImagesDir']
classes = yaml_dict['classes']
image_format = yaml_dict['image_format']
for image_set in sets:
# image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set), encoding='utf-8').read().strip().split()
# list_file = open('%s_%s.txt'%(year, image_set), 'w', encoding='utf-8')
#Read the divided picture file name
image_ids = open(saveSplitePath + '%s.txt'%(image_set), encoding='utf-8').read().strip().split()
#Create a txt file to save paths and dimensions
list_file = open(processedPath + '%s.txt'%(image_set), 'w', encoding='utf-8')
for image_id in image_ids:
#list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
list_file.write(wd + ImagesDir + image_id + image_format)
convert_annotation(xmlfilepath, image_id, list_file, classes)
list_file.write('\n')
list_file.close()
if __name__ == '__main__':
yaml_dict = read_dataset_yaml(yaml_path)
#Partition dataset
xmlfilepath, saveSplitePath = yaml_dict['xmlfilepath'], yaml_dict['saveSplitePath']
splite_dataset(xmlfilepath, saveSplitePath)
#Save dataset information, that is, picture path and annotation information
save_dataset_info(yaml_dict)
Note that some of my configurations for paths are saved in dataset Yaml file, you can first create a yaml file to save some configurations. For example, my:
#Dataset profile information
#Save path of dataset xml annotation file
xmlfilepath: './datasets/RoadSignsPascalVOC_Voc/annotations/'
#Dataset partition save path
saveSplitePath: './datasets/RoadSignsPascalVOC_Voc/ImageSets/Main/'
#Dataset directory
DatasetPath: './datasets/RoadSignsPascalVOC_Voc/'
#Picture path. Note that the root directory path should be spliced before the beginning of the path, so do not add '.' Yes
ImagesDir: '/datasets/RoadSignsPascalVOC_Voc/images/'
#Picture format
image_format: '.png'
# Number of classification types
numbers_classes: 4
# Category name
classes: ["trafficlight", "stop", "speedlimit", "crosswalk"]
#classes: ["hero", "grass", "wild_monster", "dragon", "soldier", "tower", "buff", "crystal"]
#The processed file name, the path where the picture is saved and its corresponding annotation information can not be modified by default
#sets: [('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
sets: ['train', 'val', 'test']
After processing, your data set is divided, and the content in the xml file will be extracted.
Several files will be generated in the Main folder:
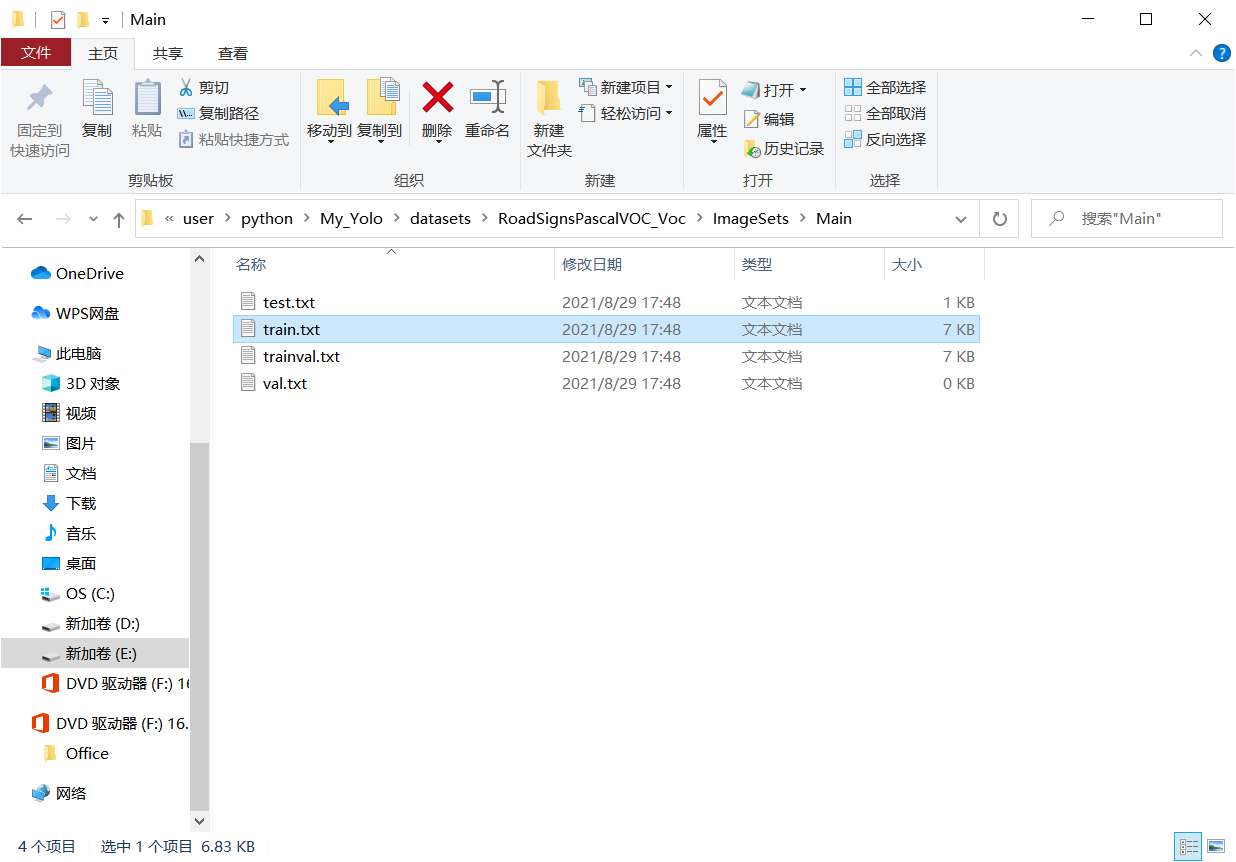
What is saved inside is the file name of the divided picture.
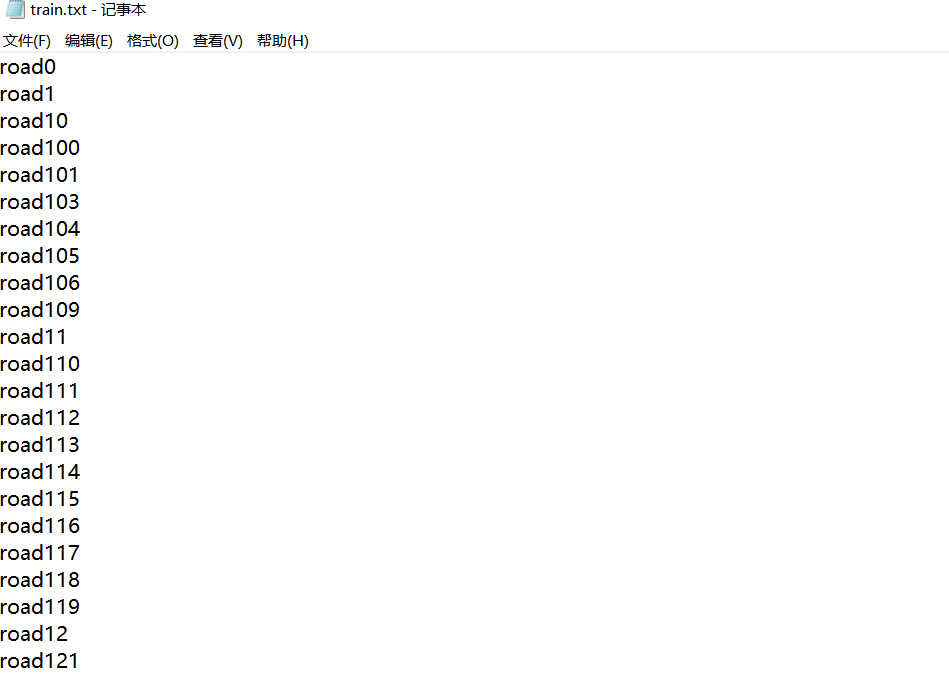
In addition, a txt file that stores the extracted xml information will be generated in your dataset directory.
The path of each picture and the annotation information of the picture are saved.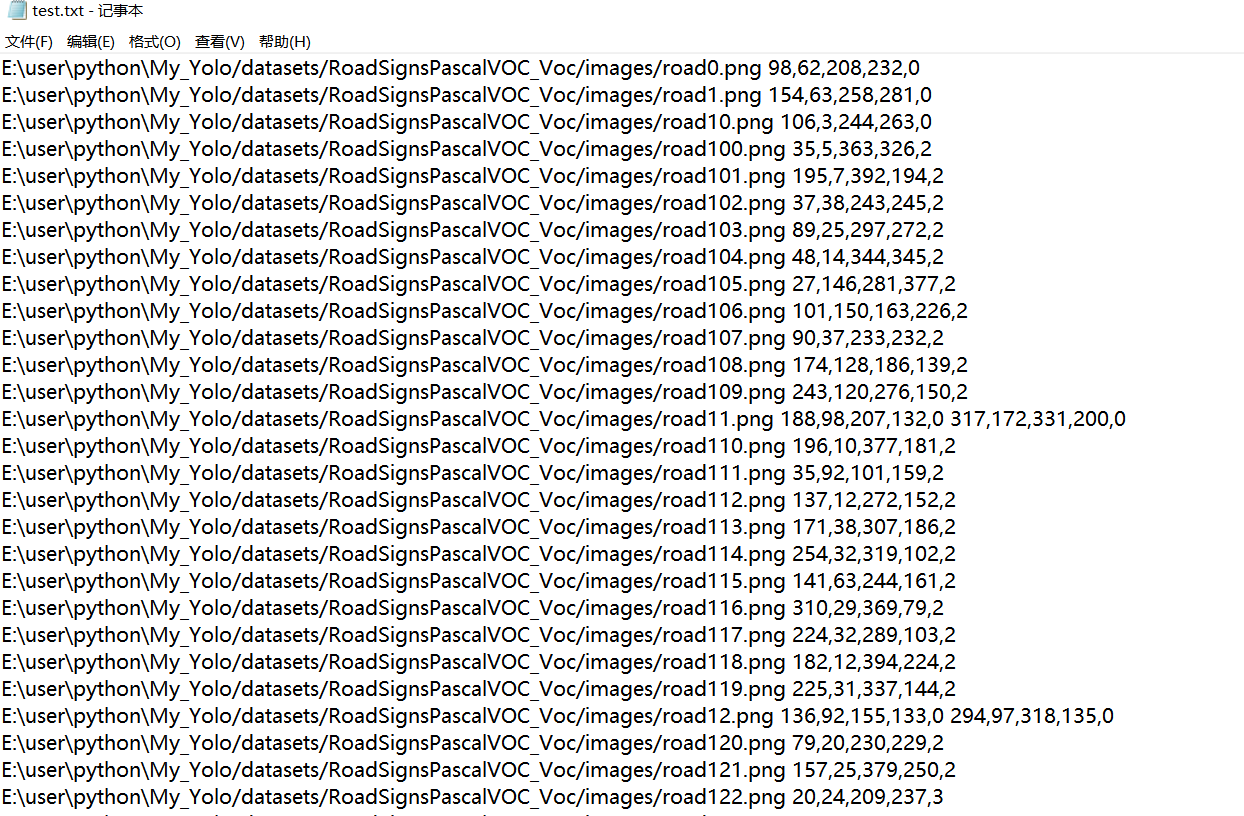
The front is the picture path, and every five numbers in the back are a group, indicating the X and Y coordinates of the upper left and lower right corners of the target in the picture and the corresponding category.
If all the voc datasets to be processed are test sets, you can change the process_ dataset. Trainval in PY_ The percent variable can be assigned to 0.