introduction
use PyTorch to realize the model of Seq2eq+Attention, and use bleu evaluation index to evaluate the quality of language generation.
1, The principle of Seq2eq+Attention in machine translation and the calculation of attention
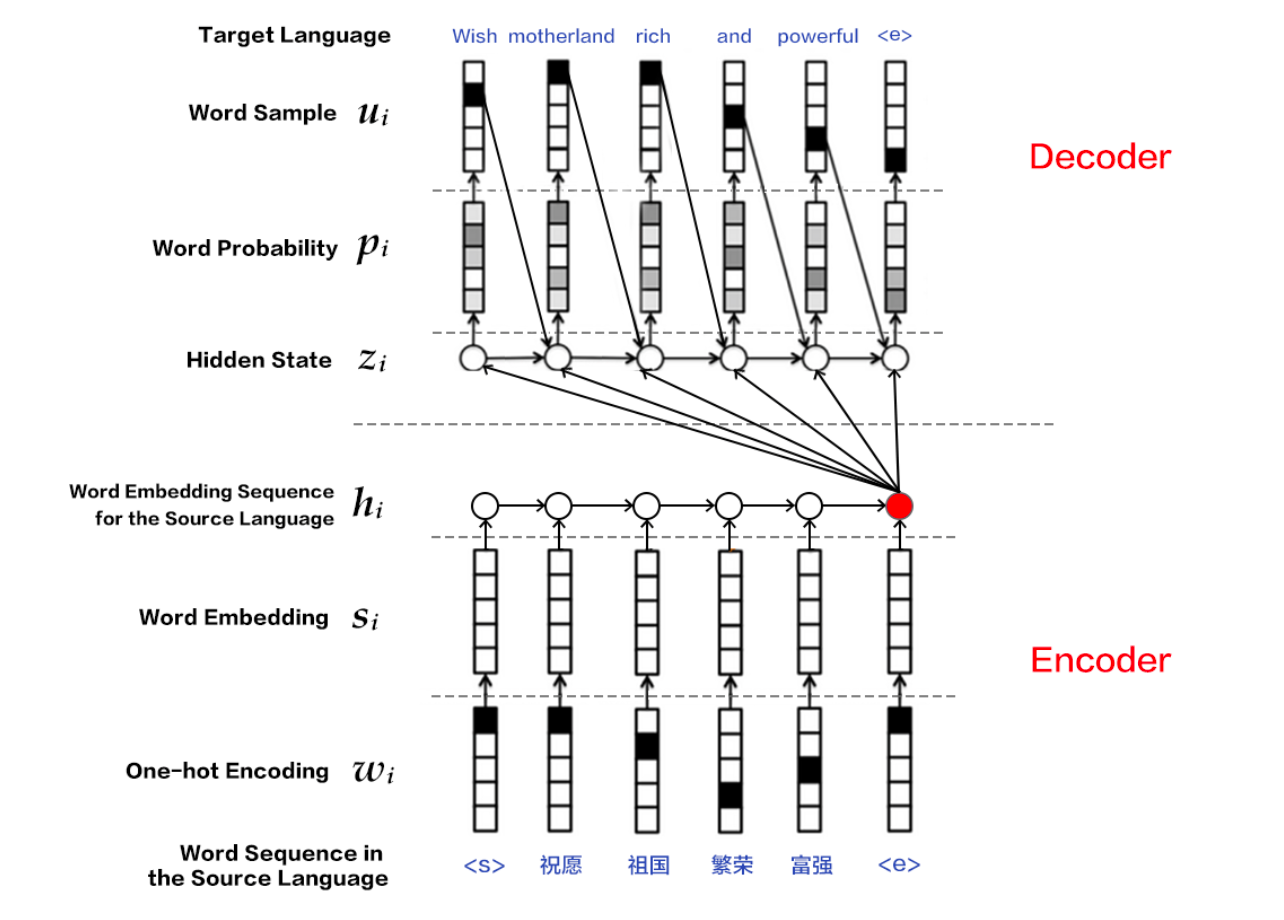
in machine translation, the input is language a, the output is language b, language a is the input of Encoder and Language B is the input of Decoder. A language obtains the hidden variables of each time step through the representation obtained by the Encoder, and uses the Attention mechanism to distribute the weight of the hidden variables of each time step to obtain the total hidden variables. The total hidden variables are spliced with the hidden variables at the last time of the Encoder layer, and the Decoder decodes the spliced variables.
the model input of machine translation model training process is different from that of prediction process. There are standard answers in the training process. The standard answer is the training goal. It will take the standard answer as the input rather than the prediction result as the input, which means that in the Decoder process, although the prediction result may be wrong, the input in the next time step is still the standard answer. Therefore, the standard answers can be input into the model together without waiting for the prediction in the last time. In the prediction process, there is obviously no standard answer. Therefore, take the prediction result as the input of the next time step.
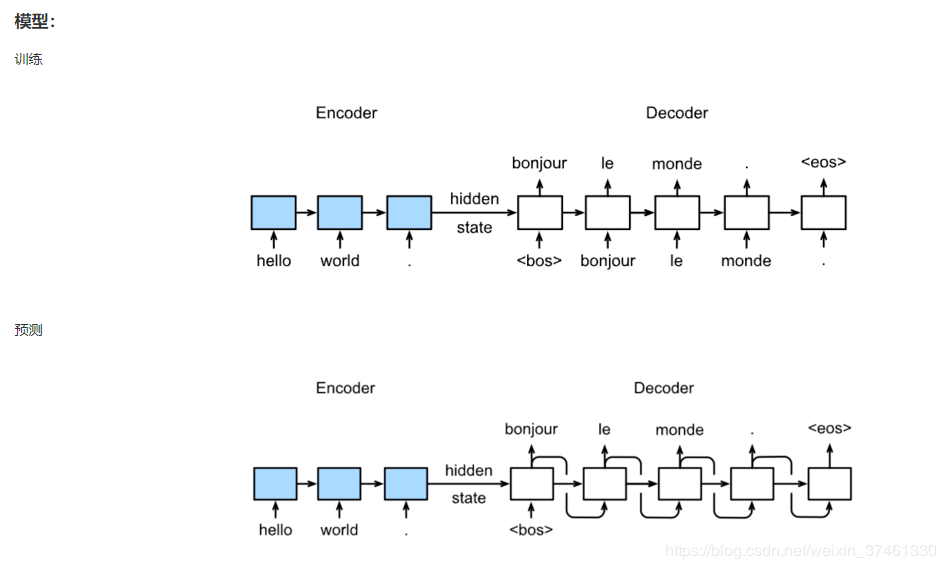
In the training process, it actually involves the optimization strategy of teacher forcing, that is, when you start learning standard answers to coach you, when the training is good, you will
ϵ
\epsilon
ϵ To choose whether to use standard answers or predict results?
ϵ
\epsilon
ϵ With the increase of training epoch, the probability increases gradually, which is selected based on probability.
in machine translation, you need to maintain two word2id and id2word. For example, the Encoder layer is applicable to word2id of language A, and the Decoder layer is applicable to word2id of language B. These two layers will automatically learn the embedding gap of different index inputs.
Summary key points:
- There are standard answers in the training process, and the standard answers are used as input
- There is no standard answer in the prediction process, and the prediction results need to be used as the input of the next time step
- Two word2id and id2word need to be maintained in machine translation
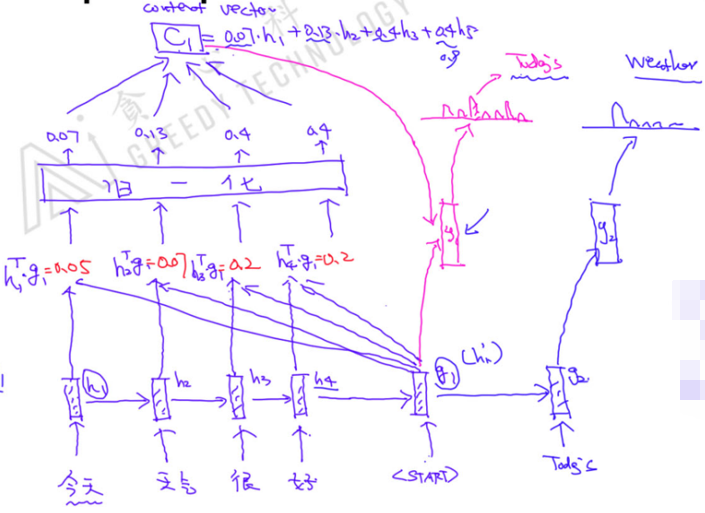
Encoder Output( h t h_t ht) there are different uses in the Decoder:
- Initialization only as a Decoder
- Can be used in every time step
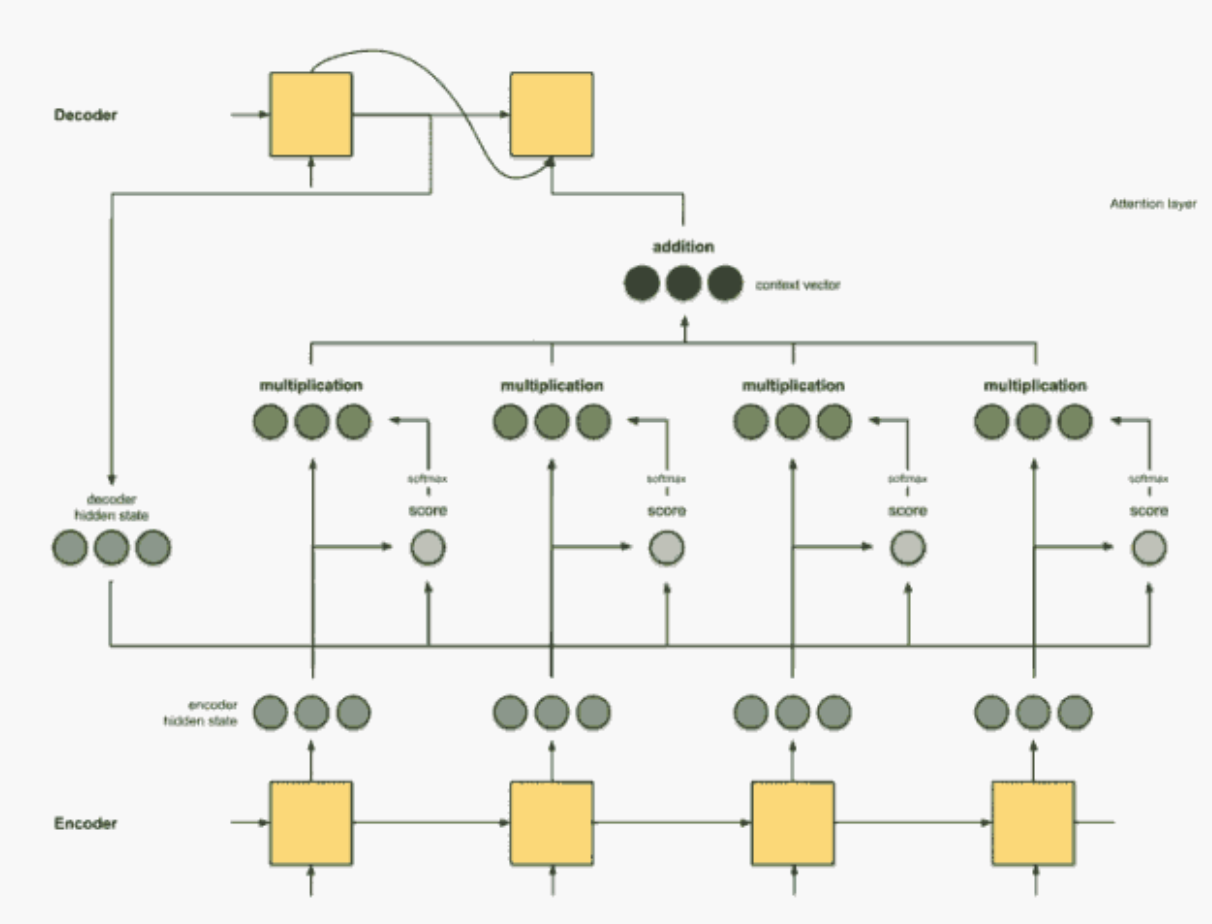
- If Attention is involved, every input of the Decoder layer involves every implicit variable in the Encoder


2, Evaluation index bleu
language generation is actually a classification problem of multiple time steps. Precision, Recall and F1 can be used as evaluation indicators. The new evaluation index bleu is introduced below
consider the Precision of the sentence,
reference:
The cat is on the mat
There is a cat on the mat
candidate:
the the the the the the
From the perspective of 1-gram, Precision=1, which is obviously wrong; From the perspective of 2-gram, Precision=0; From the perspective of 3-gram, Precision=0; Therefore, the Precision is modified to obtain modify Precision.

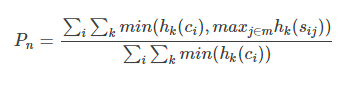
i
i
i indicates the candidate number
k
k
k represents the number of n-gram s
P
n
P_n
Pn ^ is the Precision of n-gram.
h
k
(
c
i
)
h_k(c_i)
hk (ci) is the number of n-gram s in candidate
h
k
(
s
i
j
)
h_k(s_{ij})
hk (sij) is
j
j
The number of n-gram s in j reference s.
Suppose candidate is the cat, the cat on the mat, statistics
h
k
(
c
i
)
h_k(c_i)
hk(ci),
h
k
(
s
i
j
)
h_k(s_{ij})
hk(sij)
| 2-gram | h k ( c i ) h_k(c_i) hk(ci) | h k ( s i 1 ) h_k(s_{i1}) hk(si1) | h k ( s i 2 ) h_k(s_{i2}) hk(si2) | m a x ( h k ) max(h_k) max(hk) | C o u n t c l i p Count_{clip} Countclip |
|---|---|---|---|---|---|
| the cat | 2 | 1 | 0 | 1 | 1 |
| cat the | 1 | 0 | 0 | 0 | 1 |
| cat on | 1 | 0 | 1 | 1 | 1 |
| on the | 1 | 1 | 1 | 1 | 1 |
| the mat | 1 | 1 | 1 | 1 | 1 |
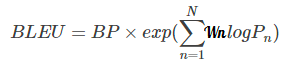
W
n
W_n
Wn ^ is the weight for n-gram.
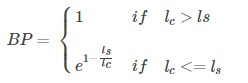
Because candidate predicts very short sentences,
P
n
P_n
Pn , will be very high, so the length needs to be punished.
1.bleu index realization
import sys
import codecs
import os
import math
import operator
import json
from functools import reduce
from nltk import bleu
def fetch_data(cand, ref):
"""
Will each reference and candidate Store as a list
:param cand: Candidate file name
:param ref: Reference file name
:return:
"""
references = []
# If the suffix of the reference file name is' txt ', add each line in the reference file to the references list
if '.txt' in ref:
reference_file = codecs.open(ref, 'r', 'utf-8')
references.append(reference_file.readlines())
# If the suffix of the reference file name is not ' txt ', that is, in a folder, find the file first and then add it
else:
# The returned is a triple (root,dirs,files), traversing each file
for root, dirs, files in os.walk(ref):
for f in files:
reference_file = codecs.open(os.path.join(root, f), 'r', 'utf-8')
references.append(reference_file.readlines())
# Returns a list of each line in the candidate file
candidate_file = codecs.open(cand, 'r', 'utf-8')
candidate = candidate_file.readlines()
# Return to reference list and candidate list
return candidate, references
# candidate = [["word peace],['make china great again !']]
# reference [["world war"],['make USA great again']]
def count_ngram(candidate, references, n):
"""
calculation n-gram of P_n
:param candidate: Candidate list
:param references: Reference list
:param n: n-gram
:return:
"""
# initialization
clipped_count = 0
# Count the number of n-gram s in the candidate set
count = 0
# Used to record the reference length
r = 0
# Used to record the length of candidates
c = 0
# Traverse each CANDIDATES
for si in range(len(candidate)):
# Calculate precision for each sentence
# Count the number of each n-gram in ref
ref_counts = []
# Count the length of REF, length
ref_lengths = []
# Traverse each REFERENCE
# Build dictionary of ngram counts - count the number of n-gram s in references
for reference in references:
# Corresponding reference set
ref_sentence = reference[si]
# ngram statistics
ngram_d = {}
# Split reference sets with spaces
words = ref_sentence.strip().split()
# Record the number of words in each reference set
ref_lengths.append(len(words))
# How many groups of n-gram s are there in the reference set
limits = len(words) - n + 1 # [1,2,3,4,5,6,7]
# Traverse each group of n-gram s
for i in range(limits):
# Construct n-gram
ngram = ' '.join(words[i:i + n]).lower()
# n-gram count in ref
if ngram in ngram_d.keys():
ngram_d[ngram] += 1
else:
ngram_d[ngram] = 1
# Add a dictionary that counts the number of reference sets n-gram s to the list
ref_counts.append(ngram_d)
# Traverse CANDIDATE
cand_sentence = candidate[si]
# Count the number of each n-gram in the can
cand_dict = {}
# Split the candidate set with spaces
words = cand_sentence.strip().split()
# Number of n-gram s corresponding to candidate sets
limits = len(words) - n + 1
# Traversal n-gram
for i in range(0, limits):
ngram = ' '.join(words[i:i + n]).lower()
# n-gram count in cand
if ngram in cand_dict:
cand_dict[ngram] += 1
else:
cand_dict[ngram] = 1
# Traverse each CANDIDATES and accumulate Count_clip value
clipped_count += clip_count(cand_dict, ref_counts)
# Count the number of n-gram s in the candidate set
count += limits
# Calculate the sentence length of the reference set
r += best_length_match(ref_lengths, len(words))
# Calculate the sentence length of the candidate set
c += len(words)
# Get P_n
if clipped_count == 0:
pr = 0
else:
pr = float(clipped_count) / count
# Calculate BP value
bp = brevity_penalty(c, r)
# Return BP and P_n
return pr, bp
def clip_count(cand_d, ref_ds):
"""
Count the clip count for each ngram considering all references
:param cand_d: Candidate set n-gram Dictionaries
:param ref_ds: Multiple reference sets n-gram Dictionaries
:return:return Count_clip value
"""
# Based on Count_clip formula calculation
count = 0
for m in cand_d.keys():
# The number of n-gram s in the candidate set
m_w = cand_d[m]
m_max = 0
for ref in ref_ds:
if m in ref:
m_max = max(m_max, ref[m])
m_w = min(m_w, m_max)
count += m_w
return count
def best_length_match(ref_l, cand_l):
"""
Find the closest length of reference to that of candidate
:param ref_l: Number of words in multiple reference sets
:param cand_l: Number of words in candidate set
:return:Returns the sentence length of the reference set
"""
# Initial difference
least_diff = abs(cand_l - ref_l[0])
best = ref_l[0]
# Number of words traversing each reference set
for ref in ref_l:
# If it's better than least_ If diff is small, then re assign the value
if abs(cand_l - ref) < least_diff:
least_diff = abs(cand_l - ref)
best = ref
return best
def brevity_penalty(c, r):
"""
Penalize length
:param c: Sentence length of candidate set
:param r: Sentence length of reference set
:return:
"""
if c > r:
bp = 1
else:
bp = math.exp(1 - (float(r) / c))
return bp
def geometric_mean(precisions):
"""
be based on BP And P_n calculation bleu
:param precisions: Accuracy rate
:return: return bleu
"""
# Reduce function: use the function (with two parameters) passed to reduce
# First operate the first and second elements in the set, and then operate with the third data with function function to obtain a result.
# operator.mul
# exp(\sum W_n log(P_n))
return (reduce(operator.mul, precisions)) ** (1.0 / len(precisions))
def BLEU(candidate, references):
"""
calculation bleu
:param candidate:Candidate list
:param references:Reference list
:return:return bleu
"""
precisions = []
# Traversal from 1-gram to 4-gram
for i in range(4):
# Get P_n,BP
pr, bp = count_ngram(candidate, references, i + 1)
precisions.append(pr)
print('P' + str(i + 1), ' = ', round(pr, 2))
print('BP = ', round(bp, 2))
# Based on BP and P_n compute bleu
bleu = geometric_mean(precisions) * bp
return bleu
if __name__ == "__main__":
# Get data and return the reference list and candidate list
# sys.argv is the command line parameter when getting the python file
candidate, references = fetch_data(sys.argv[1], sys.argv[2])
# Calculate the evaluation index bleu
bleu = BLEU(candidate, references)
# Write the calculated bleu to 'bleu'_ out. Txt 'file
print('BLEU = ', round(bleu, 4))
out = open('bleu_out.txt', 'w')
out.write(str(bleu))
out.close()
2. bleu in nltk
from nltk.translate.bleu_score import sentence_bleu
reference = [['this', 'is', 'a', 'test'], ['this', 'is' 'test']]
candidate = ['this', 'is', 'a', 'test']
score = sentence_bleu(reference, candidate)
print(score)
1.0 1.0
3, Machine translation practice based on Seq2eq+Attention
- Data Multi30k
German to English data, English and German are one-to-one correspondence
English
GermanA man in an orange hat starring at something. A Boston Terrier is running on lush green grass in front of a white fence. A girl in karate uniform breaking a stick with a front kick. Five people wearing winter jackets and helmets stand in the snow, with snowmobiles in the background. People are fixing the roof of a house. ...
Ein Mann mit einem orangefarbenen Hut, der etwas anstarrt. Ein Boston Terrier läuft über saftig-grünes Gras vor einem weißen Zaun. Ein Mädchen in einem Karateanzug bricht ein Brett mit einem Tritt. Fünf Leute in Winterjacken und mit Helmen stehen im Schnee mit Schneemobilen im Hintergrund. Leute Reparieren das Dach eines Hauses. Ein hell gekleideter Mann fotografiert eine Gruppe von Männern in dunklen Anzügen und mit Hüten, die um eine Frau in einem trägerlosen Kleid herum stehen. Eine Gruppe von Menschen steht vor einem Iglu. ...
Data processing part: utils py
"""
Data processing part
"""
import re
import spacy
from torchtext.data import Field, BucketIterator
from torchtext.datasets import Multi30k
# manual create date ( token 2 index , index to token)
# dataset dataloader PADDING BATCH SHUFFLE
# torchtext
# ALLENNLP (Field)
# ["<sos>" 3 ,"word"1 ,"peace" 2,"<eos>" 4 ]
def load_dataset(batch_size):
# Load English and German libraries respectively, and establish a dictionary at the bottom
# https://spacy.io/models Need to install de_core_news_sm and en_core_web_sm
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')
# Match search pattern
url = re.compile('(<url>.*</url>)')
# Change word into id through tokenizer
def tokenize_de(text):
return [tok.text for tok in spacy_de.tokenizer(url.sub('@URL@', text))]
def tokenize_en(text):
return [tok.text for tok in spacy_en.tokenizer(url.sub('@URL@', text))]
# Treatment method
DE = Field(tokenize=tokenize_de, include_lengths=True,
init_token='<sos>', eos_token='<eos>')
EN = Field(tokenize=tokenize_en, include_lengths=True,
init_token='<sos>', eos_token='<eos>')
# Divide the Multi30k into training, verification and testing
train, val, test = Multi30k.splits(exts=('.de', '.en'), fields=(DE, EN))
# Establish thesaurus respectively
DE.build_vocab(train.src, min_freq=2)
EN.build_vocab(train.trg, max_size=10000)
# Build iterition based on bucket iterator and return the same result as data loader
train_iter, val_iter, test_iter = BucketIterator.splits(
(train, val, test), batch_size=batch_size, repeat=False)
return train_iter, val_iter, test_iter, DE, EN
if __name__ == '__main__':
load_dataset(8)
Model part code: model py
import math
import torch
import random
from torch import nn
from torch.autograd import Variable
import torch.nn.functional as F
class Encoder(nn.Module):
# Parameter initialization
def __init__(self, input_size, embed_size, hidden_size,
n_layers=1, dropout=0.5):
super(Encoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.embed_size = embed_size
self.embed = nn.Embedding(input_size, embed_size)
# Bidirectional GRU
self.gru = nn.GRU(embed_size, hidden_size, n_layers,
dropout=dropout, bidirectional=True)
def forward(self, src, hidden=None): #A ---> B
embedded = self.embed(src)
# outputs is the hidden state of each time step
# Hidden is the hidden state of the last time step
outputs, hidden = self.gru(embedded, hidden)
# sum bidirectional outputs
outputs = (outputs[:, :, :self.hidden_size] +
outputs[:, :, self.hidden_size:])
return outputs, hidden
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
# Define a differentiable vector
self.v = nn.Parameter(torch.rand(hidden_size))
stdv = 1. / math.sqrt(self.v.size(0))
# Initialize self v
self.v.data.uniform_(-stdv, stdv)
def forward(self, hidden, encoder_outputs):
"""
:param hidden: Output of the last time step
:param encoder_outputs: Output of all time steps
:return:
"""
# Time step
timestep = encoder_outputs.size(0)
# 10 consecutive steps of replication
h = hidden.repeat(timestep, 1, 1).transpose(0, 1)
encoder_outputs = encoder_outputs.transpose(0, 1) # [B*T*H]
# Calculate weight
attn_energies = self.score(h, encoder_outputs)
return F.softmax(attn_energies, dim=1).unsqueeze(1)
def score(self, hidden, encoder_outputs):
# [B*T*2H]->[B*T*H]
energy = F.relu(self.attn(torch.cat([hidden, encoder_outputs], 2)))
energy = energy.transpose(1, 2) # [B*H*T]
# [B*1*H]
v = self.v.repeat(encoder_outputs.size(0), 1).unsqueeze(1)
# Do matrix multiplication to get [B*1*T]
energy = torch.bmm(v, energy)
# Get the weight of each time step
return energy.squeeze(1) # [B*T]
class Decoder(nn.Module):
# Parameter initialization
def __init__(self, embed_size, hidden_size, output_size,
n_layers=1, dropout=0.2):
super(Decoder, self).__init__()
self.embed_size = embed_size
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.embed = nn.Embedding(output_size, embed_size)
self.dropout = nn.Dropout(dropout, inplace=True)
# attention layer
self.attention = Attention(hidden_size)
# Unidirectional GRU
self.gru = nn.GRU(hidden_size + embed_size, hidden_size,
n_layers, dropout=dropout)
# Linear layer
self.out = nn.Linear(hidden_size * 2, output_size)
def forward(self, input, last_hidden, encoder_outputs):
# Get the embedding of the current input word (last output word)
embedded = self.embed(input).unsqueeze(0) # (1,B,N)
# dropout
embedded = self.dropout(embedded)
# Calculate attention weights and apply to encoder outputs
attn_weights = self.attention(last_hidden[-1], encoder_outputs)
# Weight and encoder_outputs are weighted to obtain the total hidden state
context = attn_weights.bmm(encoder_outputs.transpose(0, 1)) # (B,1,N)
context = context.transpose(0, 1) # (1,B,N)
# Combine embedded input word and attended context, run through RNN
rnn_input = torch.cat([embedded, context], 2)
# output is the hidden state of each time step
# Hidden is the hidden state of the last time step
output, hidden = self.gru(rnn_input, last_hidden)
output = output.squeeze(0) # (1,B,N) -> (B,N)
context = context.squeeze(0) # (1,B,N) -> (B,N)
# Through linear layer
output = self.out(torch.cat([output, context], 1))
# log + softmax
output = F.log_softmax(output, dim=1)
return output, hidden, attn_weights
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
# encoder
self.encoder = encoder
# decoder
self.decoder = decoder
def forward(self, src, trg, teacher_forcing_ratio=0.5):
"""
Forward propagation
:param src:each batch Then have src and trg attribute
:param trg:
:param teacher_forcing_ratio:
:return:
"""
# batch
batch_size = src.size(1)
# max_len
max_len = trg.size(0)
# vocab_size
vocab_size = self.decoder.output_size
# Initialize output
outputs = Variable(torch.zeros(max_len, batch_size, vocab_size))
# outputs is the hidden state of each time step
# Hidden is the hidden state of the last time step
encoder_output, hidden = self.encoder(src)
# Using hidden states
hidden = hidden[:self.decoder.n_layers]
# output
output = Variable(trg.data[0, :]) # sos
# iteration
for t in range(1, max_len):
# Decoding layer
# The current hidden state is used to generate the next hidden state
output, hidden, attn_weights = self.decoder(
output, hidden, encoder_output)
# Record output
outputs[t] = output
# teacher forcing
is_teacher = random.random() < teacher_forcing_ratio
# forecast
top1 = output.data.max(1)[1]
# Based on is_teacher determines the output
output = Variable(trg.data[t] if is_teacher else top1)
return outputs
Model training and evaluation: train py
import os
import math
import argparse
import torch
from torch import optim
from torch.autograd import Variable
from torch.nn.utils import clip_grad_norm
from torch.nn import functional as F
from model import Encoder, Decoder, Seq2Seq
from utils import load_dataset
def parse_arguments():
"""
Uniformly configure parameter management. Run these files on the command line and enter the corresponding parameters to run the files
"""
p = argparse.ArgumentParser(description='Hyperparams')
p.add_argument('-epochs', type=int, default=100,
help='number of epochs for train')
p.add_argument('-batch_size', type=int, default=32,
help='number of epochs for train')
p.add_argument('-lr', type=float, default=0.0001,
help='initial learning rate')
p.add_argument('-grad_clip', type=float, default=10.0,
help='in case of gradient explosion')
# p.add_argument('-hidden_size',type=int,default=10,help=" the size of hidden tensor")
return p.parse_args()
def evaluate(model, val_iter, vocab_size, DE, EN):
# Mode is test mode
model.eval()
# Get the value corresponding to '< pad >' in the English dictionary
pad = EN.vocab.stoi['<pad>']
total_loss = 0
# Traverse each batch
for b, batch in enumerate(val_iter):
# src is the processed English input
# trg is the processed result
src, len_src = batch.src
trg, len_trg = batch.trg
src = Variable(src.data, volatile=True)
trg = Variable(trg.data, volatile=True)
# Forward propagation
output = model(src, trg, teacher_forcing_ratio=0.0)
# Cross entropy loss
loss = F.nll_loss(output[1:].view(-1, vocab_size),
trg[1:].contiguous().view(-1),
ignore_index=pad)
# Loss accumulation
total_loss += loss.data.item()
return total_loss / len(val_iter)
def train(e, model, optimizer, train_iter, vocab_size, grad_clip, DE, EN):
# Training mode, model weight update
model.train()
total_loss = 0
# Get the value corresponding to '< pad >' in the English dictionary
pad = EN.vocab.stoi['<pad>']
# Traverse each batch
for b, batch in enumerate(train_iter):
# src is the processed English input
# trg is the processed result
src, len_src = batch.src
trg, len_trg = batch.trg
src, trg = src, trg
# Gradient clearing
optimizer.zero_grad()
# Forward propagation
output = model(src, trg)
# Cross entropy loss function
loss = F.nll_loss(output[1:].view(-1, vocab_size),
trg[1:].contiguous().view(-1),
ignore_index=pad)
# Back propagation
loss.backward()
# Gradient truncation
clip_grad_norm(model.parameters(), grad_clip)
# Gradient update
optimizer.step()
# loss accumulation
total_loss += loss.data.item()
if b % 100 == 0 and b != 0:
total_loss = total_loss / 100
print("[%d][loss:%5.2f][pp:%5.2f]" %
(b, total_loss, math.exp(total_loss)))
total_loss = 0
def main():
# Unified configuration parameters
args = parse_arguments()
hidden_size = 512
embed_size = 256
# assert torch.cuda.is_available()
print("[!] preparing dataset...")
# Get iterations for training, verification and prediction
train_iter, val_iter, test_iter, DE, EN = load_dataset(args.batch_size)
# Thesaurus length
de_size, en_size = len(DE.vocab), len(EN.vocab)
print("[TRAIN]:%d (dataset:%d)\t[TEST]:%d (dataset:%d)"
% (len(train_iter), len(train_iter.dataset),
len(test_iter), len(test_iter.dataset)))
print("[DE_vocab]:%d [en_vocab]:%d" % (de_size, en_size))
print("[!] Instantiating models...")
# Initialization coding
encoder = Encoder(de_size, embed_size, hidden_size,
n_layers=2, dropout=0.5)
# Initialize decoding
decoder = Decoder(embed_size, hidden_size, en_size,
n_layers=1, dropout=0.5)
# Initialize seq2seq
seq2seq = Seq2Seq(encoder, decoder)
# optimizer
optimizer = optim.Adam(seq2seq.parameters(), lr=args.lr)
print(seq2seq)
best_val_loss = None
# Traverse each epoch
for e in range(1, args.epochs+1):
# train
train(e, seq2seq, optimizer, train_iter,
en_size, args.grad_clip, DE, EN)
# verification
val_loss = evaluate(seq2seq, val_iter, en_size, DE, EN)
print("[Epoch:%d] val_loss:%5.3f | val_pp:%5.2fS"
% (e, val_loss, math.exp(val_loss)))
# Save the model if the validation loss is the best we've seen so far.
if not best_val_loss or val_loss < best_val_loss:
print("[!] saving model...")
if not os.path.isdir(".save"):
os.makedirs(".save")
torch.save(seq2seq.state_dict(), './.save/seq2seq_%d.pt' % (e))
best_val_loss = val_loss
# forecast
test_loss = evaluate(seq2seq, test_iter, en_size, DE, EN)
print("[TEST] loss:%5.2f" % test_loss)
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt as e:
print("[STOP]", e)
The model structure is:
Seq2Seq(
(encoder): Encoder(
(embed): Embedding(8014, 256)
(gru): GRU(256, 512, num_layers=2, dropout=0.5, bidirectional=True)
)
(decoder): Decoder(
(embed): Embedding(10004, 256)
(dropout): Dropout(p=0.5, inplace=True)
(attention): Attention(
(attn): Linear(in_features=1024, out_features=512, bias=True)
)
(gru): GRU(768, 512, dropout=0.5)
(out): Linear(in_features=1024, out_features=10004, bias=True)
)
)
If it is helpful to you, please praise and pay attention, which is really important to me!!! If you need to communicate with each other, please comment or send a private letter!
