Hello, I'm Charlie.
Only by knowing yourself and the enemy can we win a hundred battles. When learning technology, we often face too many choices and are at a loss. We may be involved in all aspects. We don't have in-depth research in a certain field. It seems that we can do everything. When you really want to do something, you seem to catch your elbow and see your mind. If we can learn from the skills required by the recruitment position, we can practice hard Kung Fu and lay a good foundation for practical application.
Our purpose is to capture the recruitment details of hook net through python, screen the skill keywords and store them in excel.
1, Obtain position demand data
Through observation, it can be found that the position page details of the pull hook network are determined by http://www.lagou.com/jobs/ + ***** (PositionId).html, and the positionid can be obtained by analyzing Jason's XHR. The job description in the red box is the data we want to capture.
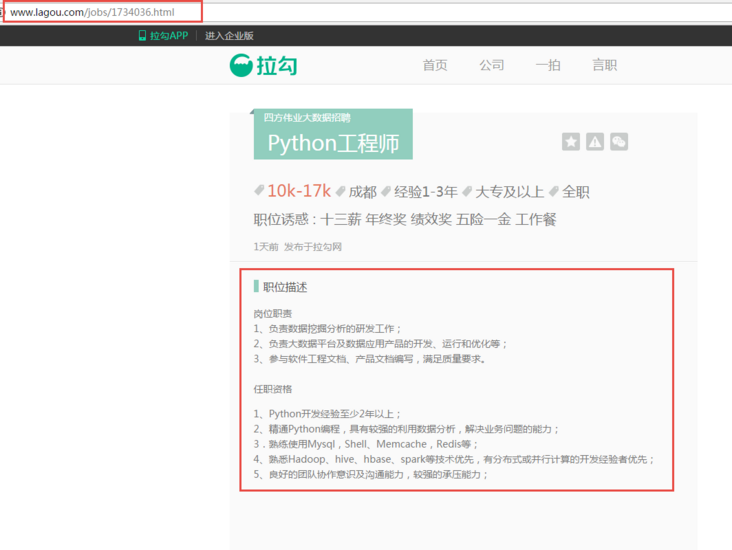
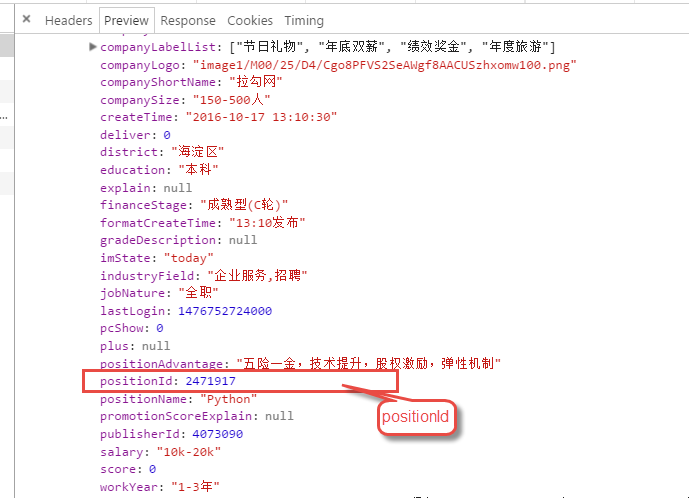
After knowing the source of the data, wrap the Headers according to the normal steps and submit FormData to obtain the feedback data.
Get the page where the PositionId list is located:
#Obtain the query page of the position (the parameters are website address, current page number and keyword respectively)
def get_page(url, pn, keyword):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Origin': 'http://www.lagou.com'
}
if pn == 1:
boo = 'true'
else:
boo = 'false'
page_data = urllib.urlencode([
('first', boo),
('pn', pn),
('kd', keyword)
])
req = urllib2.Request(url, headers=headers)
page = urllib2.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
Get PositionId through Json:
#Obtain the required position ID, and each recruitment page detail has an ID index
def read_id(page):
tag = 'positionId'
page_json = json.loads(page)
page_json = page_json['content']['positionResult']['result']
company_list = []
for i in range(15):
company_list.append(page_json[i].get(tag))
return company_list
Composite target url:
#Get the position page and combine the positionId and BaseUrl into the target address
def get_content(company_id):
fin_url = r'http://www.lagou.com/jobs/%s.html' % company_id
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Origin': 'http://www.lagou.com'
}
req = urllib2.Request(fin_url, headers=headers)
#page = urllib.urlopen(req).read()
page = urllib2.urlopen(req).read()
content = page.decode('utf-8')
return content
2, Process data
After obtaining the data, the data needs to be cleaned. The position content captured through beautiful soup contains Html tags, and the data needs to take off this "coat".
#Get the position requirements (remove the html tag through re), and store the position details separately
def get_result(content):
soup = Bs(content, 'lxml')
job_description = soup.select('dd[class="job_bt"]')
job_description = str(job_description[0])
rule = re.compile(r'<[^>]+>')
result = rule.sub('', job_description)
return result
The data obtained now is the job description information. We need to filter the job requirements keywords we are concerned about from the job information.
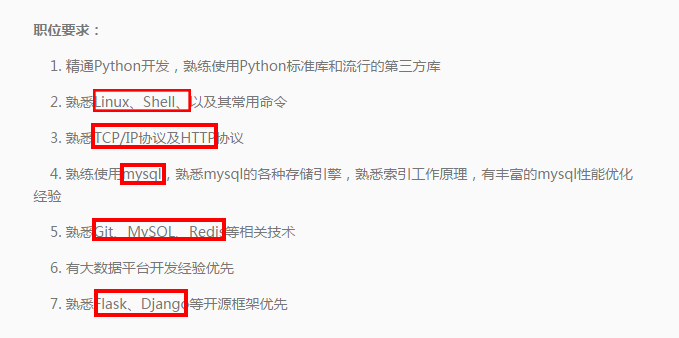
We filter out these keywords and store them in the List. After crawling through the whole 500 + positions, we get the summary table of position skill keywords.
#Keywords filtering: Currently, only English keywords are selected
def search_skill(result):
rule = re.compile(r'[a-zA-z]+')
skil_list = rule.findall(result)
return skil_list
Sort the keywords according to the frequency of 500 + position requirements, select the keywords with the frequency of Top80, and remove the invalid keywords.
# Count and sort the keywords, and select the keywords of Top80 as the sample of data
def count_skill(skill_list):
for i in range(len(skill_list)):
skill_list[i] = skill_list[i].lower()
count_dict = Counter(skill_list).most_common(80)
return count_dict
3, Store and visualize data
# Store the results and generate an Area diagram
def save_excel(count_dict, file_name):
book = xlsxwriter.Workbook(r'E:\positions\%s.xls' % file_name)
tmp = book.add_worksheet()
row_num = len(count_dict)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, ['key word', 'frequency'])
else:
con_pos = 'A%s' % i
k_v = list(count_dict[i-2])
tmp.write_row(con_pos, k_v)
chart1 = book.add_chart({'type':'area'})
chart1.add_series({
'name' : '=Sheet1!$B$1',
'categories' : '=Sheet1!$A$2:$A$80',
'values' : '=Sheet1!$B$2:$B$80'
})
chart1.set_title({'name':'Keyword ranking'})
chart1.set_x_axis({'name': 'key word'})
chart1.set_y_axis({'name': 'frequency(/second)'})
tmp.insert_chart('C2', chart1, {'x_offset':15, 'y_offset':10})
book.close()
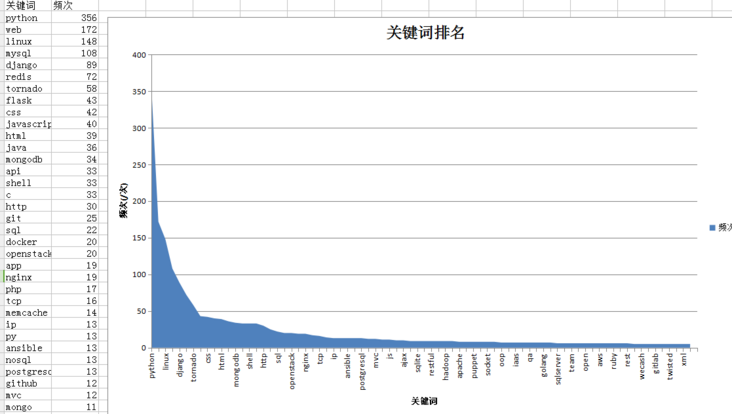
Data visualization
If you find an error or don't understand, you can put it forward in the comment area for everyone to communicate!
If the article is helpful to you, like + pay attention, your support is my biggest motivation