1. First, roughly estimate the data volume of short chain services
Daily active users in the first year: 100000 Daily new short chain data in the first year: 100000*50(Build 50 short chains a day) = 500 ten thousand Annual number of new short chains: 5 million * 365 day = 18.2 Hundred million At a high level, it is 10 billion, supporting three years
Database and table strategy
The number of single tables shall be controlled at about 10 million
It can be divided into 16 libraries with 64 tables in each library, with a total of 1024 tables
Fragment key: short chain code field
For example: G1 Short chain code of fit / 92AEva
Sub database and sub table algorithm: hash modulus of short chain code
Library ID = short chain code hash value% library quantity
Table ID = short chain code hash value / library quantity% table quantity
Advantages of using this method:
Ensure that the data are evenly distributed in different databases and tables, which can effectively avoid the problem of hot data concentration,
The method of dividing database and table is clear and easy to understand
Disadvantages: capacity expansion is not very convenient and data migration is required
16 libraries need to be established at one time, 64 tables in each library, and the total number is 1024 tables, which wastes resources
Then, this article introduces the following ways to increase the number of Library epitopes to achieve a small amount in the early stage without wasting resources. At the same time, the capacity expansion avoids data migration or migration free
For example, G1 Short chain code of fit / 92AEva
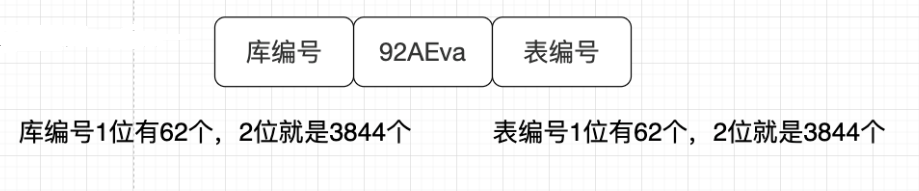
Why? Because the prefix and suffix of the short chain code are fixed, the capacity expansion will not affect the old data. And the amount of data in the early stage can build as many databases without wasting resources. What are the similar migration free expansion strategies? Time range sub database sub table id range sub database sub table
The vernacular explanation is: the short chain code is preceded by the library location and followed by the table location. There are several tables at the beginning, and the library table rules need not be written so much waste. At the same time, the database location and table location are accurately known. If there is more data in the back, you can add the location letter. The previous historical data does not need to be moved, because the database table locations in the front are not moved, but only increased. For example, at the beginning, a-c represents the library. The following a-c represents epitopes. When the three database tables have more data, change the database table rule d-f to represent the database and d-f to represent the table.
Implementation method:
Three libraries, one with two tables
Sub database strategy:
Configuration to note:
spring.shardingsphere.datasource.names=ds0,ds1,dsa, where 0/1/a is the added library epitope
The other configurations are as follows: the data items of DS0 and DS1 DSA need to be configured respectively
spring.shardingsphere.props.sql.show=true spring.shardingsphere.datasource.ds0.connectionTimeoutMilliseconds=3000 spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.ds0.idleTimeoutMilliseconds=60000 spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://xxxx.xxx.xxx.240:3306/dcloud_link_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true spring.shardingsphere.datasource.ds0.maintenanceIntervalMilliseconds=30000 spring.shardingsphere.datasource.ds0.maxLifetimeMilliseconds=1800000 spring.shardingsphere.datasource.ds0.maxPoolSize=50 spring.shardingsphere.datasource.ds0.minPoolSize=50 spring.shardingsphere.datasource.ds0.password=xxxxx.net168 spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.ds0.username=root spring.shardingsphere.datasource.ds1.connectionTimeoutMilliseconds=3000 spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.ds1.idleTimeoutMilliseconds=60000 spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://xxxx.xxx.xxx:3306/dcloud_link_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true spring.shardingsphere.datasource.ds1.maintenanceIntervalMilliseconds=30000 spring.shardingsphere.datasource.ds1.maxLifetimeMilliseconds=1800000 spring.shardingsphere.datasource.ds1.maxPoolSize=50 spring.shardingsphere.datasource.ds1.minPoolSize=50 spring.shardingsphere.datasource.ds1.password=xxxx.net168 spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.ds1.username=root spring.shardingsphere.datasource.dsa.connectionTimeoutMilliseconds=3000 spring.shardingsphere.datasource.dsa.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.dsa.idleTimeoutMilliseconds=60000 spring.shardingsphere.datasource.dsa.jdbc-url=jdbc:mysql://xxxx.xxx.xxx.240:3306/dcloud_link_a?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true spring.shardingsphere.datasource.dsa.maintenanceIntervalMilliseconds=30000 spring.shardingsphere.datasource.dsa.maxLifetimeMilliseconds=1800000 spring.shardingsphere.datasource.dsa.maxPoolSize=50 spring.shardingsphere.datasource.dsa.minPoolSize=50 spring.shardingsphere.datasource.dsa.password=xxxxx.net168 spring.shardingsphere.datasource.dsa.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.dsa.username=root #Configure plus to print sql logs mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl #----------Short chain, strategy: sub database + sub table-------------- # First perform horizontal sub database, and then horizontal sub table spring.shardingsphere.sharding.tables.short_link.database-strategy.standard.sharding-column=code spring.shardingsphere.sharding.tables.short_link.database-strategy.standard.precise-algorithm-class-name=net.wnn.strategy.CustomDBPreciseShardingAlgorithm
Method for routing program code to corresponding library:
import net.wnn.enums.BizCodeEnum;
import net.wnn.exception.BizException;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class CustomDBPreciseShardingAlgorithm implements PreciseShardingAlgorithm<String> {
/**
* @param availableTargetNames Data source collection
* At the time of partition, the value is the collection databaseNames of all partition libraries
* When splitting a table, it is the set tablesNames of all the shard tables in the corresponding shard library
* @param shardingValue Slice properties, including
* logicTableName Is a logical table,
* columnName Slice key (field),
* value Is the value of the partition key parsed from SQL
* @return
*/
@Override
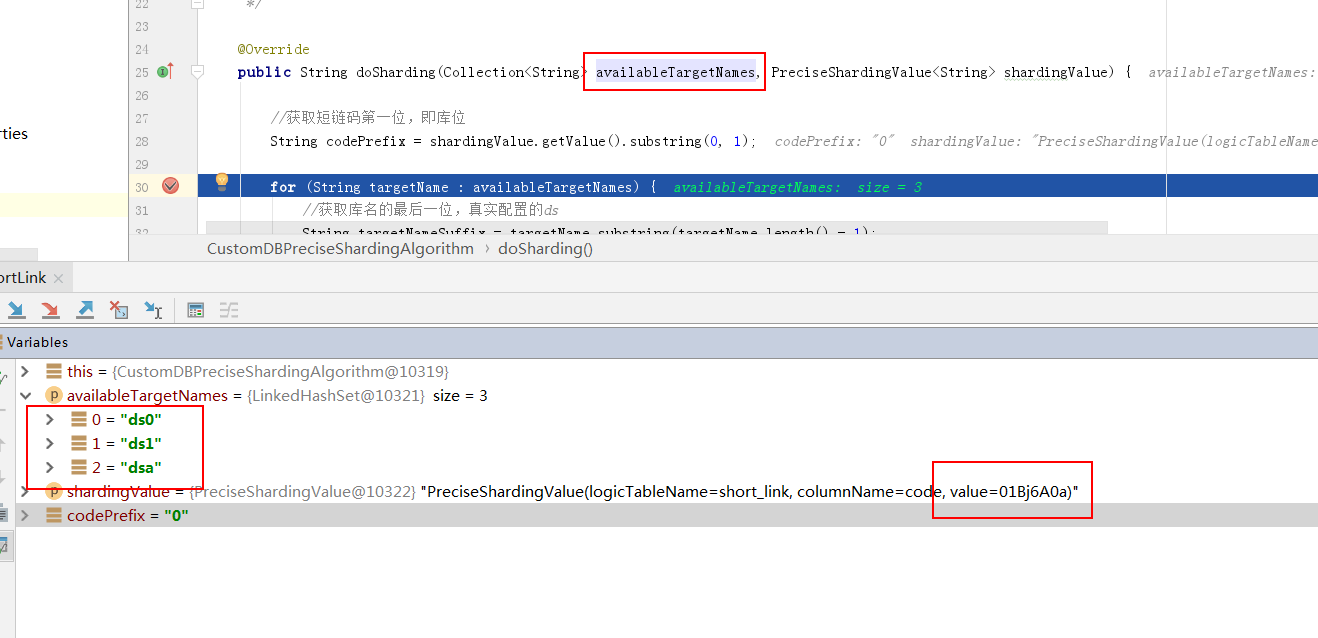
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<String> shardingValue) {
//Get the first bit of short chain code, i.e. warehouse location
String codePrefix = shardingValue.getValue().substring(0, 1);
for (String targetName : availableTargetNames) {
//Get the last bit of the library name, the real configured ds
String targetNameSuffix = targetName.substring(targetName.length() - 1);
//If consistent, return
if (codePrefix.equals(targetNameSuffix)) {
return targetName;
}
}
//Throwing anomaly
throw new BizException(BizCodeEnum.DB_ROUTE_NOT_FOUND);
}
}
Table splitting strategy:
# Horizontal sub table policy, user-defined policy. Real library Logic table
spring.shardingsphere.sharding.tables.short_link.actual-data-nodes=ds0.short_link,ds1.short_link,dsa.short_link
spring.shardingsphere.sharding.tables.short_link.table-strategy.standard.sharding-column=code
spring.shardingsphere.sharding.tables.short_link.table-strategy.standard.precise-algorithm-class-name=net.wnn.strategy.CustomTablePreciseShardingAlgorithm
#id generation strategy
spring.shardingsphere.sharding.tables.short_link.key-generator.column=id
spring.shardingsphere.sharding.tables.short_link.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.short_link.key-generator.props.worker.id=${workerId}How to route the program to the corresponding table:
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class CustomTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<String> {
/**
* @param availableTargetNames Data source collection
* At the time of partition, the value is the collection databaseNames of all partition libraries
* When splitting a table, it is the set tablesNames of all the shard tables in the corresponding shard library
* @param shardingValue Slice properties, including
* logicTableName Is a logical table,
* columnName Slice key (field),
* value Is the value of the partition key parsed from SQL
* @return
*/
@Override
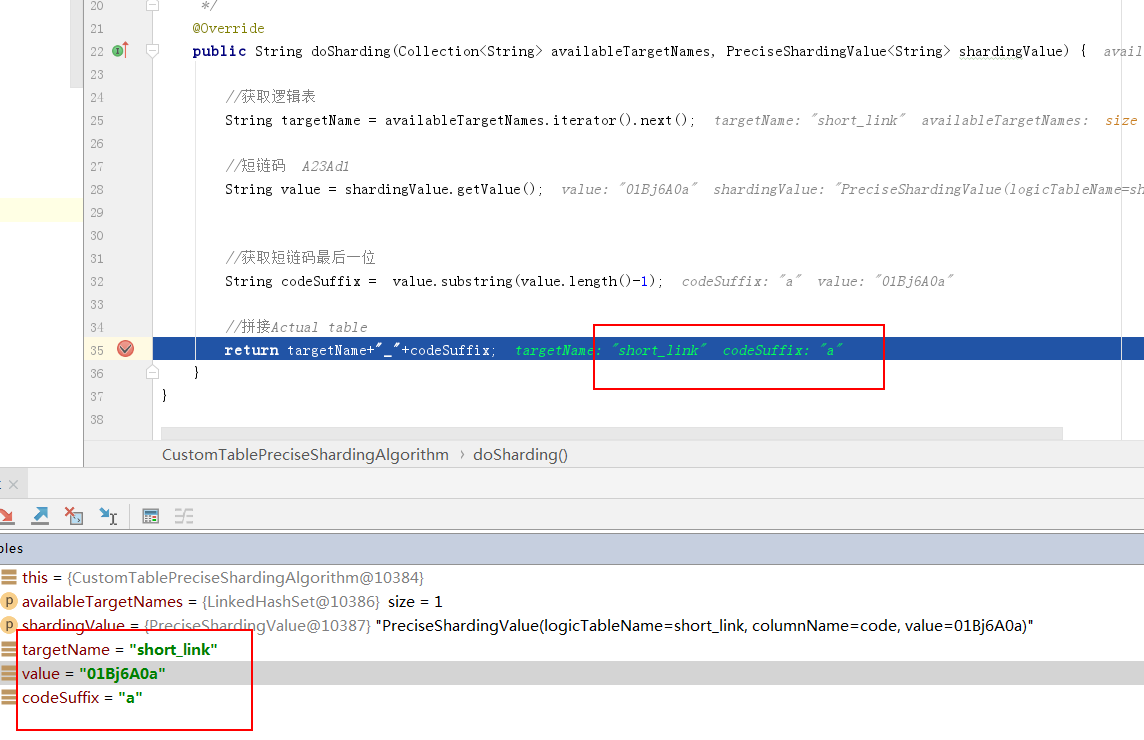
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<String> shardingValue) {
//Get logical table
String targetName = availableTargetNames.iterator().next();
//Short chain code A23Ad1
String value = shardingValue.getValue();
//Get the last bit of short chain code
String codeSuffix = value.substring(value.length()-1);
//Splice Actual table
return targetName+"_"+codeSuffix;
}
}
When generating a short chain, add a library epitope to the short chain code:
Bit configuration of shardingdbconfig DB
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class ShardingDBConfig {
/**
* Storage database location number
*/
private static final List<String> dbPrefixList = new ArrayList<>();
private static Random random = new Random();
//Configure the prefixes that enable those libraries
static {
dbPrefixList.add("0");
dbPrefixList.add("1");
dbPrefixList.add("a");
}
/**
* Get random prefix
* @return
*/
public static String getRandomDBPrefix(){
int index = random.nextInt(dbPrefixList.size());
return dbPrefixList.get(index);
}
}
Bit configuration of shardingTableConfig table
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class ShardingTableConfig {
/**
* Storage data sheet location number
*/
private static final List<String> tableSuffixList = new ArrayList<>();
private static Random random = new Random();
//Configure and enable suffixes for those tables
static {
tableSuffixList.add("0");
tableSuffixList.add("a");
}
/**
* Get random suffix
* @return
*/
public static String getRandomTableSuffix(){
int index = random.nextInt(tableSuffixList.size());
return tableSuffixList.get(index);
}
}
Generate short chain code:
/**
* Generate short chain code
* @param param
* @return
*/
public String createShortLinkCode(String param){
long murmurhash = CommonUtil.murmurHash32(param);
//Binary conversion
String code = encodeToBase62(murmurhash);
String shortLinkCode = ShardingDBConfig.getRandomDBPrefix() + code + ShardingTableConfig.getRandomTableSuffix();
return shortLinkCode;
}The short chain code generation method and some logic are shown in: Short chain service problem solving - jump problem - Introduction to short chain generation scheme (II) continuous updating of serialization_ Column of wnn654321 - CSDN blog
Unit test verification:
Get location:
Get epitope:
Successfully saved in 0 library a table:
