background
For the principle of raft algorithm, it is recommended to refer to the raft official website: https://raft.github.io/
It is highly recommended to watch the process animation of raft to facilitate intuitive understanding of the algorithm process
Animation address: http://thesecretlivesofdata.com/raft/
By reading the source code of SofaJRaft and running the Counter demo program of SofaJRaft locally, this series learns and understands the specific implementation of raft algorithm in the project.
SofaJRaft source address: https://github.com/sofastack/sofa-jraft
Corresponding document address: https://www.sofastack.tech/projects/sofa-jraft/jraft-user-guide/
Code version read and demonstrated in this project:
<dependencies>
<!-- jraft -->
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>jraft-core</artifactId>
<version>1.3.9</version>
</dependency>
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>jraft-rheakv-core</artifactId>
<version>1.3.9</version>
</dependency>
<!-- jsr305 -->
<dependency>
<groupId>com.google.code.findbugs</groupId>
<artifactId>jsr305</artifactId>
<version>3.0.2</version>
</dependency>
<!-- bolt -->
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>bolt</artifactId>
<version>1.6.4</version>
</dependency>
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>hessian</artifactId>
<version>3.3.6</version>
</dependency>
<!-- log -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<!-- disruptor -->
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.7</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<!-- protobuf -->
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.5.1</version>
</dependency>
<!-- protostuff -->
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.6.0</version>
</dependency>
<!-- rocksdb -->
<dependency>
<groupId>org.rocksdb</groupId>
<artifactId>rocksdbjni</artifactId>
<version>6.22.1.1</version>
</dependency>
<!-- java thread affinity -->
<dependency>
<groupId>net.openhft</groupId>
<artifactId>affinity</artifactId>
<version>3.1.7</version>
</dependency>
<!-- metrics -->
<dependency>
<groupId>io.dropwizard.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>4.0.2</version>
</dependency>
</dependencies>Choose the master
According to the principle of the raft algorithm, the raft cluster is a structure of one leader and multiple followers. The leader is responsible for receiving requests from client s, processing and recording logs, and then the leader copies the logs to all followers to achieve the purpose of data redundancy backup.
When a follower in the cluster goes down, the cluster can still provide services normally under less than half of the circumstances. After the follower is restored, you can copy snapshots from the leader and all log records after the snapshot point to recover the data in memory to catch up with the cluster state.
When the leader in the cluster goes down, all follower s will elect a new leader to replace the original leader. This process is called "selecting the master".
Counter demo
Before the source code analysis, first demonstrate the start-up and selection of the main program of the raft cluster, and intuitively feel the process.
The program comes from SofaJRaft source code. The business function is very simple. It is a counter. Starting from zero, each client call can automatically increase the integer value in the server memory.
Server startup
The server execution entry is the main method of CounterServer in the source code
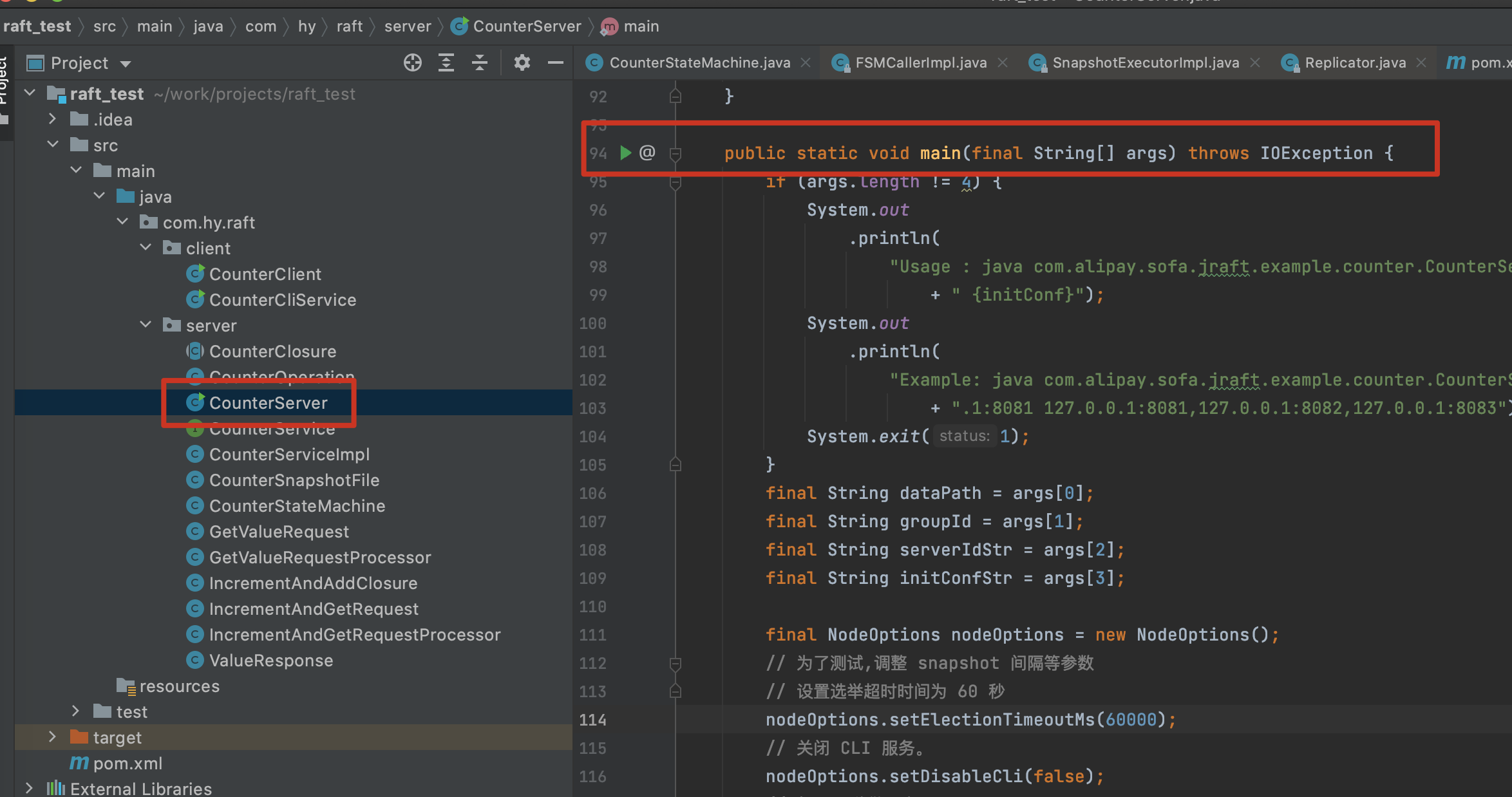
Here, I will start three local service host s in idea to simulate the cluster structure of one master and two slaves.
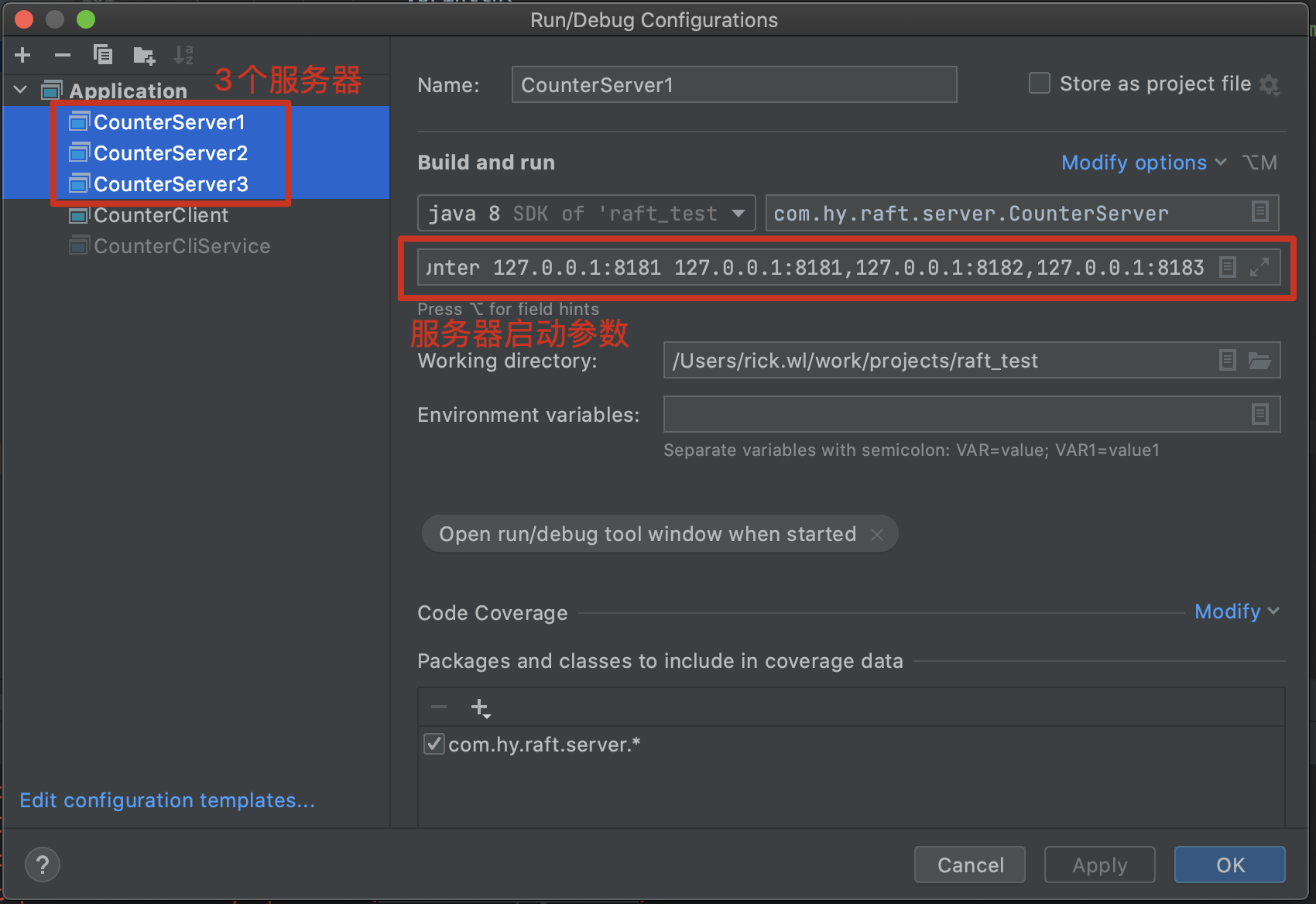
CounterServer1, CounterServer2 and CounterServer3 are three servers. The execution entry is the same main method mentioned above, but the startup parameters are slightly different:
CounterServer1 Startup parameters for: /tmp/server1 counter 127.0.0.1:8181 127.0.0.1:8181,127.0.0.1:8182,127.0.0.1:8183 CounterServer2 Startup parameters for: /tmp/server2 counter 127.0.0.1:8182 127.0.0.1:8181,127.0.0.1:8182,127.0.0.1:8183 CounterServer3 Startup parameters for: /tmp/server3 counter 127.0.0.1:8183 127.0.0.1:8181,127.0.0.1:8182,127.0.0.1:8183
Four parameters separated by commas. The first is the service directory, the second is the group name, the third is the service ip, and the fourth is the group configuration.
The group name needs to be the same as the flag of the same cluster joined by three servers; Because it is a local demonstration, the service ip is the same, which is distinguished by the port; Finally, group configuration is actually a list of service ip addresses, which saves all ip addresses of the cluster.
Next, start CounterServer1 (port 8181), CounterServer2 (port 8182), and CounterServer3 (port 8183)
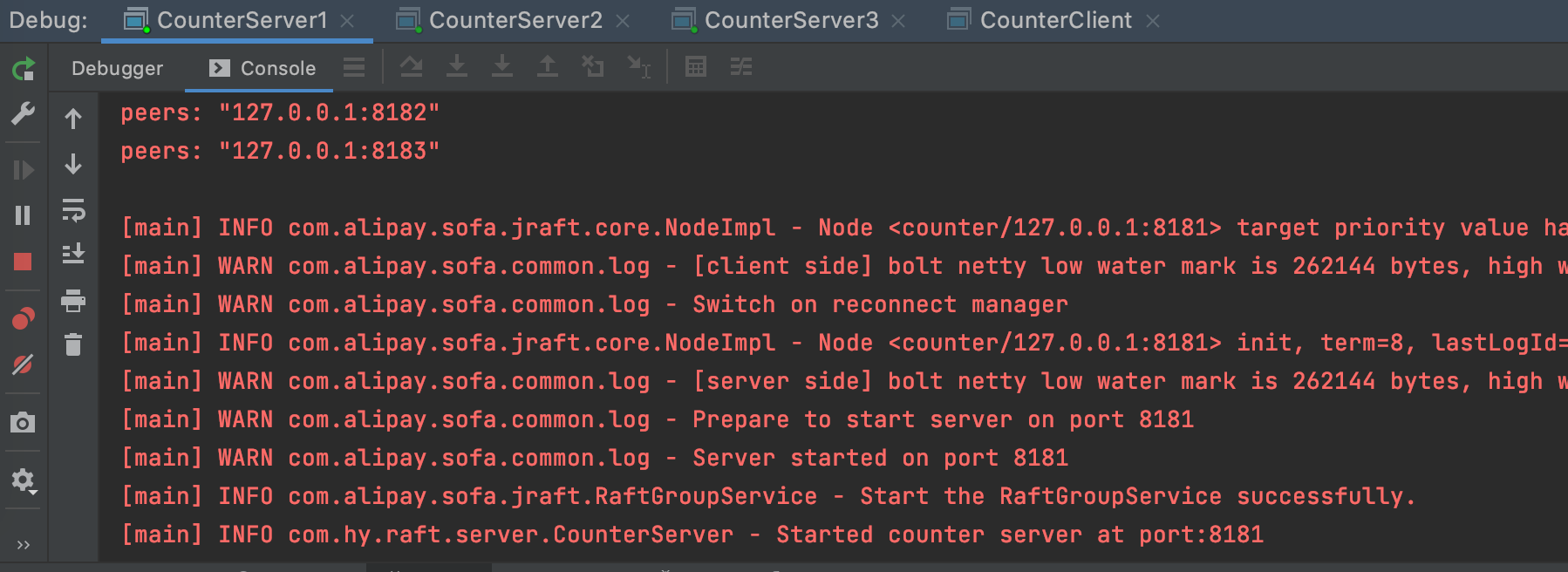
You can see "Start the RaftGroupService successfully.", Indicates that server startup is complete.
Then, CounterServer1 starts to launch the election, vote for itself, and ask for votes from CounterServer2 and CounterServer3. As can be seen from the above figure, CounterServer3 returned graded = true, indicating that CounterServer3 agreed to the self recommendation request of CounterServer1. In addition, CounterServer1 cast its own vote, and the two votes agreed to more than half of the three servers in the cluster, so in the end, CounterServer1 successfully became the leader of the cluster: "come leader of group".
As can be seen from the above figure, CounterServer3 returned graded = true, indicating that CounterServer3 agreed to the self recommendation request of CounterServer1. In addition, CounterServer1 cast its own vote, and the two votes agreed to more than half of the three servers in the cluster, so in the end, CounterServer1 successfully became the leader of the cluster: "come leader of group".
Let's take another look at the logs of CounterServer3:

It can be seen that CounterServer3 received the preVote and Vote requests from CounterServer1 without objection. Finally, he began to become a follower of the cluster and recognized CounterServer1 as the leader.
Take another look at the log of CounterServer2:

There are also similar requests to receive preVote and Vote from {CounterServer1, and recognize CounterServer1 as a leader.
Reselect primary server
At this time, the small cluster of our three servers has reached a stable state of external services, with CounterServer1 as the leader and CounterServer2 and CounterServer3 as the follower.
Next, let's simulate the scenario where the leader hangs up and terminate the process of CounterServer1
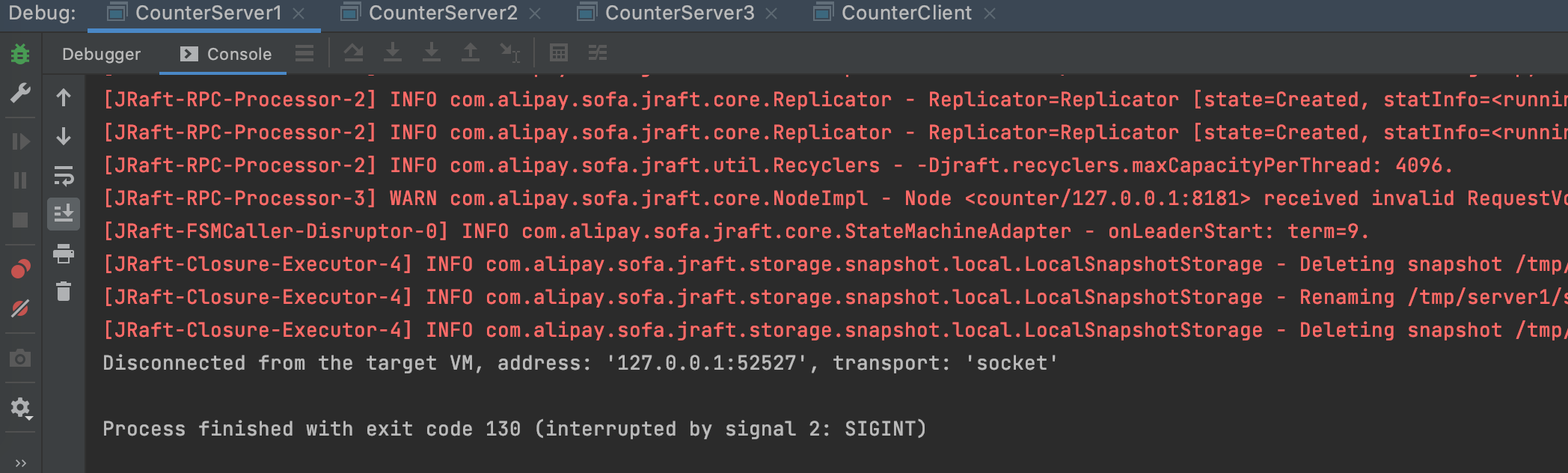
Then it is found that CounterServer3 starts electing itself as a leader, sends an election request to {CounterServer2, and receives a confirmation reply:

Finally, CounterServer3 became the new leader of the cluster, and then kept trying to reconnect the suspended CounterServer1:

Take another look at CounterServer2. You can see the log that CounterServer3 is recognized as a new leader:

The above is the brief process of starting and selecting the main process of the Counter demonstration program. For more complex scenarios, such as network splitting and merging, more processes need to be started for demonstration. You can try it yourself.
The next article will read and analyze the simple source code process of this process.