The words written in the front
Welcome to scan code, pay attention to my official account, and make progress with me! Mainly committed to learning
- Using deep learning to solve computer vision related problems
- Python based Internet application services
- CPU microarchitecture design based on MIPS instruction set

introduction
For most of us, this year's summer Olympic Games are a very participatory Olympic Games after the Beijing Olympic Games. I think there are several reasons:
- The host city of the 2020 Summer Olympic Games is Tokyo, Japan, and the time difference between Tokyo time and Beijing time is only one hour. We can catch all the live events without reversing black and white.
- Some new city confirmed cases novel coronavirus pneumonia have appeared in some cities in China, and most people's summer plans are changed from "traveling" to "squatting at home".
- This year's Chinese delegation has seen a large number of post-90s and post-00s legions. They represent the Chinese young generation. Their brilliant performance in the Olympic Games has attracted extensive attention from the society.
- ... ...

For me, this year I also used all kinds of free time to watch some events of the Chinese delegation through live broadcasting or playback. In my spare time, I also participated in the discussion of related topics on microblog. One topic is called“ #Why do Chinese people no longer focus on gold medals# "Aroused my great interest. Although I browsed the comments on related topics, I still felt not satisfied. I thought I could get the data of comments and analyze them with Python.
get data
To analyze the data, we must first obtain the data. In this step, we obtain the information by analyzing the network request.
First, enter the interface of microblog Mobile Version (data cannot be obtained from the PC interface).
Link address: https://m.weibo.cn/
The interface after entering is shown in the figure.
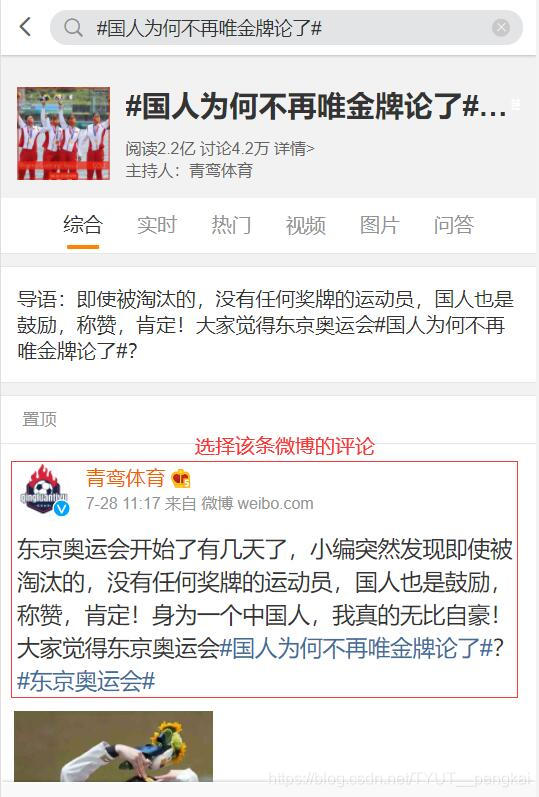
We can enter "# why do Chinese people no longer rely on gold medals #" in the search box to see the interface shown in the figure below. We choose the first microblog at the top and click in.
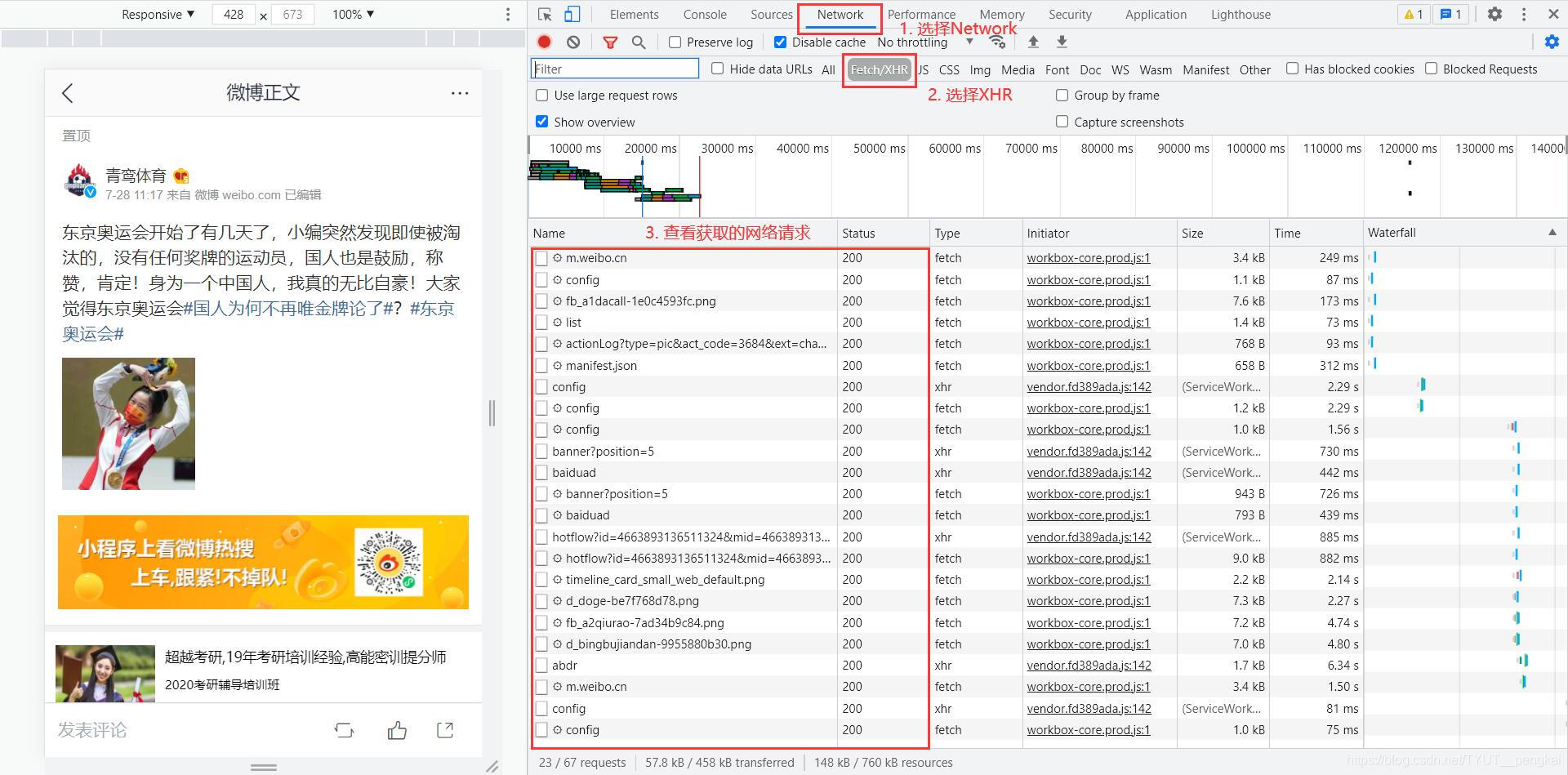
At the same time, press "F12" or right-click the page and select "check". Select "Network" in the new function bar and select "XHR" to see the Network requests during the page loading process.
Among the observed network requests, we will find a network request starting with "hotflow". Click to enter the request, view the response information and find the comment information we need.
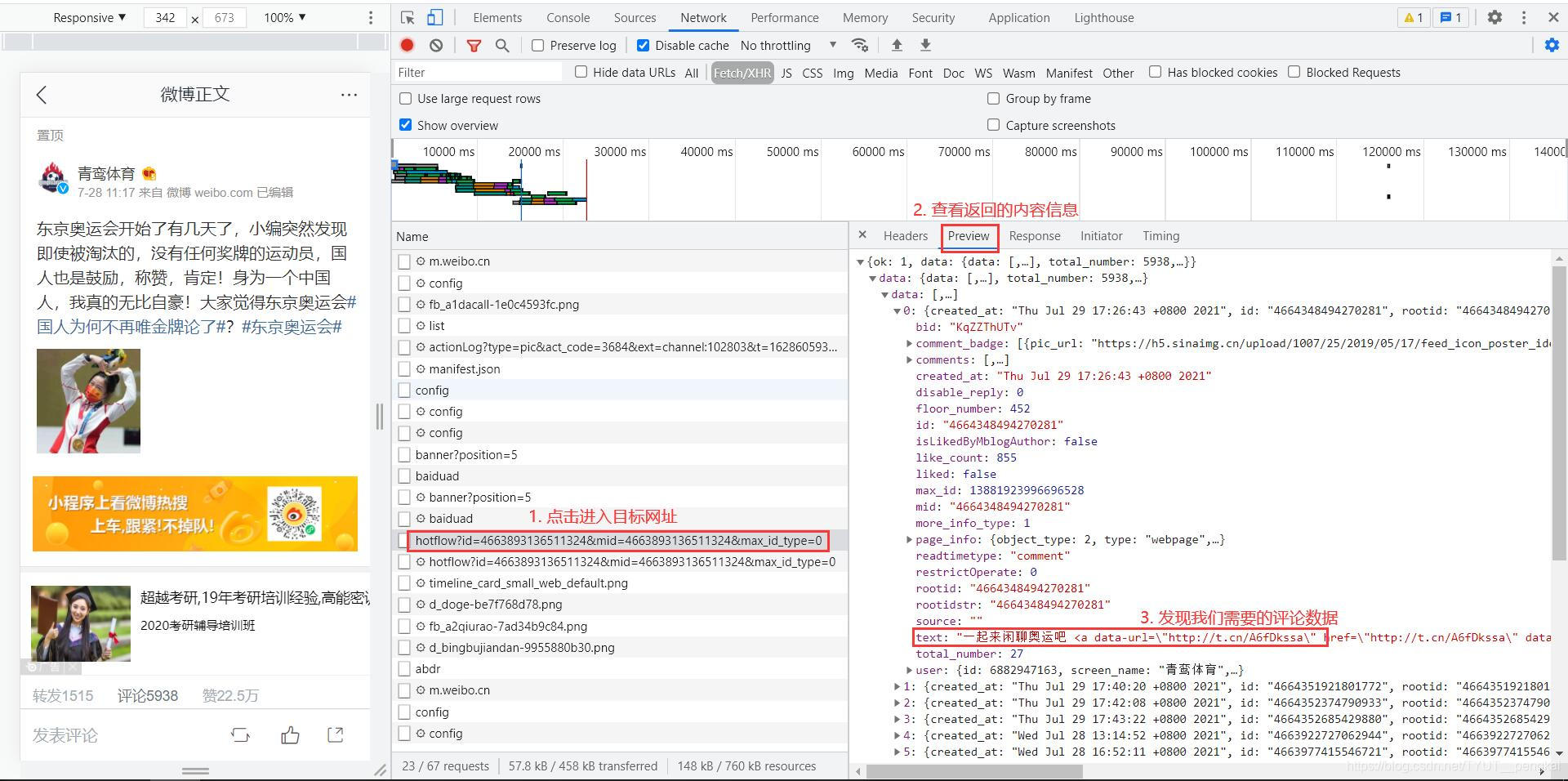
It can be concluded that the target website is the website of the comment information we need. It encapsulates the data and returns it in json format. Therefore, as long as we can get the return value of the website, we can get the comment information.
However, a new problem has emerged: there are only 20 comments, but the original microblog has 5000 + comments. Where's the other information? After analysis, we can find that the comment information is dynamically loaded. When we drag the information down, we can get all the comment information~
After solving all the problems, we only have the last step to process the obtained information and save the comments we need to a text file. We use the following Python program.
def get_data(review_file_path):
"""
Read data in the file and process the data
:param review_file_path: The storage path of the comment file, string
:return: Comment information
"""
review_contents = []
with open(review_file_path, 'r') as f:
lines = f.readlines()
f.close()
n = len(lines)
for i in range(n):
line = json.loads(lines[i])
review_datas = line['data']['data']
data_nums = len(review_datas)
# Set where to start reading comments
if i == 0:
start = 1
else:
start = 0
for j in range(start, data_nums):
# Regular matching processes text and other information
pattern_01 = re.compile(r'<span class="url-icon">.*?</span>', re.S)
pattern_02 = re.compile(r'<a .*?>.*?</a>', re.S)
origin_review_content = review_datas[j]['text']
review_content = re.sub(pattern_01, '', origin_review_content)
review_content = re.sub(pattern_02, '', review_content)
review_contents.append(review_content)
return review_contents
The finally obtained data information and comment information (processed data information) can be downloaded through the following links.
Data information
Link: https://pan.baidu.com/s/1EYC1kUf1p9XYQ_fOt_kp1w
Extraction code: dcn2
Note: only 1000 comments were obtained in this article.
Analysis data
For the processed comment information, use the third-party library of Python to segment the word and draw the result as a word cloud. It can call the library function, which will not be repeated here. It is implemented using the following Python program.
def draw_picture(review_content_file_path):
data = open(review_content_file_path, 'r', encoding='utf-8').read()
# participle
word_list = jieba.cut(data, cut_all=True)
word_list_result = ' '.join(word_list)
# Configuration of word cloud
word_cloud = WordCloud(
# Set background
background_color='white',
# Set the maximum number of word clouds displayed
max_words=50,
# Set word span
font_step=10,
# Set font
font_path=r'C:\Windows\Fonts\simsun.ttc',
# Set the height and width of the word cloud
height=300,
width=300,
# Set Color Scheme
random_state=30
)
# Get results
my_cloud = word_cloud.generate(word_list_result)
plt.imshow(my_cloud)
plt.axis("off")
plt.show()
The final drawing result is shown in the figure.

Epilogue
From the picture, it is not difficult to see some bright words, such as "self-confidence", "strong", "proof", "effort" and "Chinese". They gave the best answer to this question: our country is strong, our nation is reviving, we are more confident than ever in road, theory and culture. We no longer need to prove ourselves with gold medals. This is also the place where I am most shocked, proud and benefited from the Olympic Games!

Complete code
At the end of the article, a complete program to realize the analysis is presented.
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@ModuleName: get_data
@Function:
@Author: PengKai
@Time: 2021/8/6 22:52
"""
import re
import json
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
def get_data(review_file_path):
"""
Read data in the file and process the data
:param review_file_path: The storage path of the comment file, string
:return: Comment information
"""
review_contents = []
with open(review_file_path, 'r') as f:
lines = f.readlines()
f.close()
n = len(lines)
for i in range(n):
line = json.loads(lines[i])
review_datas = line['data']['data']
data_nums = len(review_datas)
# Set where to start reading comments
if i == 0:
start = 1
else:
start = 0
for j in range(start, data_nums):
pattern_01 = re.compile(r'<span class="url-icon">.*?</span>', re.S)
pattern_02 = re.compile(r'<a .*?>.*?</a>', re.S)
origin_review_content = review_datas[j]['text']
review_content = re.sub(pattern_01, '', origin_review_content)
review_content = re.sub(pattern_02, '', review_content)
review_contents.append(review_content)
return review_contents
def store_contents(review_contents):
"""
Save the comments in the file
:param review_contents: Comment information, List
:return: None
"""
n = len(review_contents)
with open('./review_data.txt', 'w', encoding='utf-8') as f:
for i in range(n):
text = review_contents[i] + '\n'
f.write(text)
f.close()
def draw_picture(review_content_file_path):
data = open(review_content_file_path, 'r', encoding='utf-8').read()
# participle
word_list = jieba.cut(data, cut_all=True)
word_list_result = ' '.join(word_list)
# Configuration of word cloud
word_cloud = WordCloud(
# Set background
background_color='white',
# Set the maximum number of word clouds displayed
max_words=50,
# Set word span
font_step=10,
# Set font
font_path=r'C:\Windows\Fonts\simsun.ttc',
# Set the height and width of the word cloud
height=300,
width=300,
# Set Color Scheme
random_state=30
)
# Get results
my_cloud = word_cloud.generate(word_list_result)
plt.imshow(my_cloud)
plt.axis("off")
plt.show()
if __name__ == '__main__':
review_file_path = './data.txt'
review_contents = get_data(review_file_path)
store_contents(review_contents)
review_content_file_path = './review_data.txt'
draw_picture(review_content_file_path)