1, Environment and dependence
Language: Python 3 eight
Grab: selenium
Agent: ipide
Note: if you want to complete the code at the end, pay attention to the novice's suggestion to read it slowly. Here's a hint about the writing steps of this article: 1 Obtain data, 2 Translation, 3 Data cleaning, 4 Segmentation weight, 5 Ci Yun
1.1 selenium preparation
For simplicity, here I use selenium (a rookie uses selenium, I'm a rookie) for data capture, and I use ipidea's agent (it's safe anyway). Otherwise, I'll blow up my IP after waiting for testing and debugging too many times.
selenium can be downloaded using pip. The command is:
pip install selenium
After downloading selenium, you also need a driver. You need to check your browser version. It only supports Firefox or Google.
Here, using Google distance, first click the three points in the upper right corner of Chorm browser:
Select help about google access chrome://settings/help Page. Then find the corresponding version number:

Next, go to the download address of the driver: http://chromedriver.storage.googleapis.com/index.html
Next, find a close driver in the corresponding version number to download:
Then click and select the corresponding version:
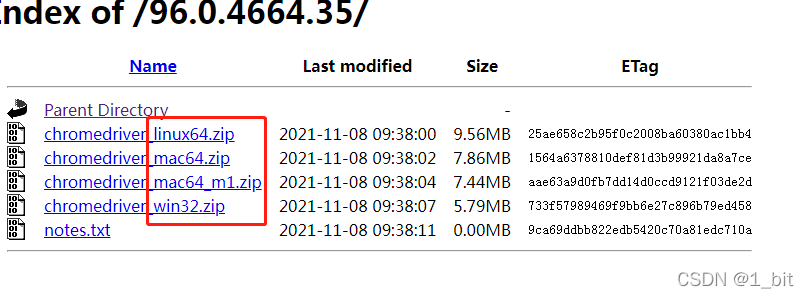
windows can use win32. After downloading, unzip it to a directory.
Then I use IPIDE as my agent, and this is the official website link , just use it for free. That's enough.
2, Data acquisition
2.1 agency
The first step is to get the data through the agent.
First, create a python file named test1. Of course, take the name yourself.
Then use vscode (you can use your) to introduce:
from selenium import webdriver import requests,json,time
Then we write a header:
#agent
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0'}After the foundation is completed, we first need to obtain the agent. We write a function named ip_:
#Proxy acquisition
def ip_():
url=r"http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1®ions=in&port=1"
r = requests.get(url, headers=headers,timeout=3)
data = json.loads(r.content)
ip_=data['data'][0]
return ip_The url stored in the above code http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1®ions=in&port=1 Some small partners may fail to obtain the link for the agent because the current ip is not set to the white list.
The way to set the white list is very simple. You can replace your own white list at the end of the link:
https://api.ip idea.net/index/index/save_white?neek= ***&Appkey = **************************************************************************** https://www.ipidea.net/getapi:
If I open my, I basically everyone can use mine, so type a code.
Let's go back to function IP_ In (), r = requests Get (URL, headers = headers, timeout = 3) will get the proxy IP address, and then I use json for conversion: data = json Loads (r.content), and finally the IP address is returned. The method of IP acquisition is too simple to explain.
Next, get the proxy and the composition ip proxy string:
ip=ip_()#ip acquisition proxy_str="http://"+ str(ip['ip'])+':'+str(ip['port'])#ip proxy combination
Then use webdriver to set up a proxy for Google Browser:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=%s" % proxy_str)
options.add_argument('--ignore-certificate-errors')
options.add_argument('-ignore -ssl-errors')Options in the above code add_ Argument adds a proxy to the browser. The next two sentences are just to ignore some errors. Of course, it's basically OK if you don't add it.
2.2 data capture
Next, create a variable url to store the link of the page to be crawled:
url='https://www.quora.com/topic/Chinese-Food?q=Chinese%20food'
Next, create a Google browser object:
driver = webdriver.Chrome(executable_path=r'C:\webdriver\chromedriver.exe',options=options) driver.get(url) input()
webdriver. Executable in Chrome_ Path is the address of the specified download driver, and option is the configuration of the agent.
After creating the driver, you can understand it as a Chrome Google browser object. To open a specified page using Google browser, you only need to use the get method and pass a url in the get method.
Because we found that the page is automatically refreshed when the browser slides to the bottom, we only need to use circular repetition to slide down:
for i in range(0,500):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(10)The code driver in the above loop execute_ Script means to execute the script command, where window scrollTo(0, document.body.scrollHeight); This is the corresponding sliding command. Give him a break after each slide, otherwise the effect of continuous stroke is not very good, so use sleep to rest for 10s and wait for loading.
Then we get the following pieces of data in the page:

In order to avoid missing anything bad, I typed here.
Right click to check and open the source code:

At this point, we can see the corresponding content under this html code:
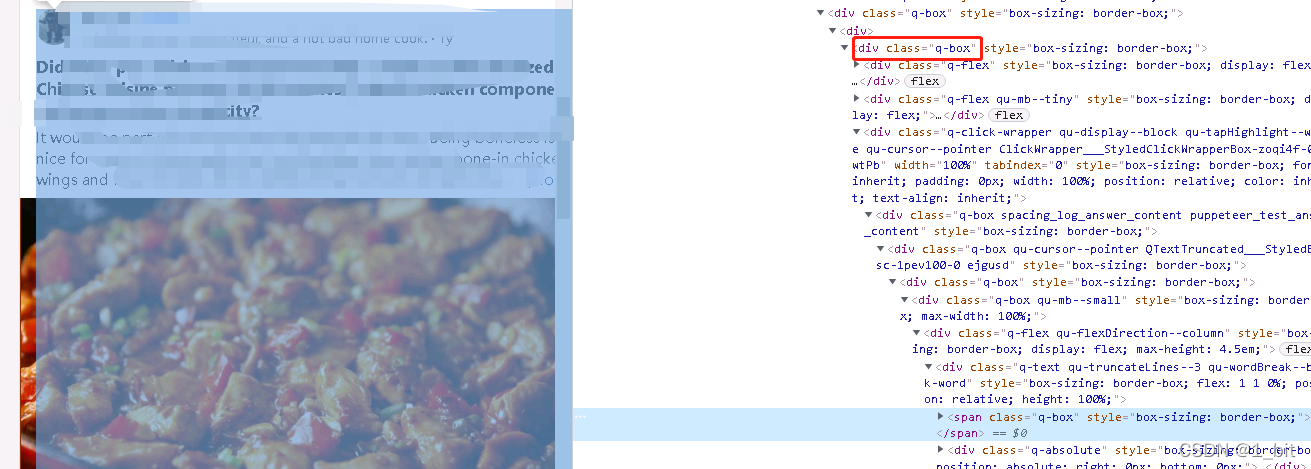
We know that the class name of this part is q-box, and we can use find in the driver_ element_ by_ class_ Name method, find the element and get the corresponding text.
Then we look at all the content blocks and know that they all use q-box as the name:

Then we just need to use the code:
content=driver.find_element_by_class_name('q-box')You can grab all the objects named q-box.
At this point, we only need to use this object Text to get the text, and then use f.write to write it into the text:
f = open(r'C:\Users\Administrator\Desktop\data\data.txt',mode='w',encoding='UTF-8') f.write(content.text) f.close()
The complete code of this part is as follows:
from selenium import webdriver
import requests,json,time
#agent
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0'}
#Proxy acquisition
def ip_():
url=r"http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1®ions=in&port=1"
r = requests.get(url, headers=headers,timeout=3)
data = json.loads(r.content)
print(data)
ip_=data['data'][0]
return ip_
ip=ip_()#ip acquisition
proxy_str="http://"+ str(ip['ip'])+':'+str(ip['port'])#ip proxy combination
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=%s" % proxy_str)
options.add_argument('--ignore-certificate-errors')
options.add_argument('-ignore -ssl-errors')
url='https://www.quora.com/topic/Chinese-Food?q=Chinese%20food'
driver = webdriver.Chrome(executable_path=r'C:\webdriver\chromedriver.exe',options=options)
driver.get(url)
input()
for i in range(0,500):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(10)
title=driver.find_element_by_class_name('q-box')
#title=driver.find_element_by_css_selector("[class='dtb-style-1 table-dragColumns']")
f = open(r'C:\Users\Administrator\Desktop\data\data.txt',mode='w',encoding='UTF-8')
f.write(title.text)
f.close() 3, Word segmentation statistics
3.1 data cleaning
Then we can translate the data, but there are daily restrictions on the free database. The best way is to assign the content to online translation at no cost. Yes, although there are a lot of data, it's OK, and the problem is not big.
After translation, I copied a text, which I named datacn.
Create a py file named cut here, and introduce in the header:
import jieba,re,jieba.analyse #Stutter participle from wordcloud import WordCloud #Ci Yun import matplotlib.pyplot as plt
After introduction, create a function to read the translated text datacn:
def get_str(path):
f = open(path,encoding="utf-8" )
data = f.read()
f.close()
return dataThe code is very simple. open the file and read it. However, some students are prone to coding errors. Remember to add encoding="utf-8". If you don't believe it, save the text as. When saving, select encoding as utf-8:

Next, let's create a function to clean the content:
def word_chinese(text):
pattern = re.compile(r'[^\u4e00-\u9fa5]')
clean= re.sub(pattern, '', text)
return cleanIn fact, the function above is used to find Chinese characters and return them. Do not use other contents, otherwise the effect will be affected, such as some punctuation marks and English letters.
Then we read the data directly:
path=r"D:\datacn.txt" text=get_str(path) text=word_chinese(text)
Where path is the path, which is the path of the text storage I translated, and then pass in the parameter get_str, so the read data is text. I'm in a hurry to pass text into the cleaning function word_ Clean in Chinese, so that bad data can be clear.
3.2 word frequency weight statistics
But there are still some bad words at this time, such as you, me, him, Hello, know How to remove these contents? At this time, use the stutter library to set some words. Don't Jieba analyse. set_ stop_ Words, the code is:
jieba.analyse.set_stop_words(r'D:\StopWords.txt')
Where D: \ stopwords Txt this text records unwanted words. I adjusted a pile of words for accurate data. What I want can be seen in the comment area. There is too much data to copy directly.
After setting, it can be filtered automatically. The next step is word segmentation and word frequency statistics. The code of this step is:
words = jieba.analyse.textrank(text, topK=168,withWeight=True)
The method used is Jieba analyse. Textrank(), where text is the text we cleaned up. topk refers to the first few words you want to get the word frequency. Here, topk=168 means you get 168 words with the most frequency. Where withWeight=True means the word frequency weight value in the result. For example, if withWeight=True is not used, the result is as follows:

If withWeight is not enabled, the result will display:

At this time, the results have been obtained. It is found that soy sauce is the most favorite and mentioned by foreigners, and then I like it. It seems that I really like it.
Then let's make a word cloud and then analyze it. The word cloud requires a string and cannot use an array. Use the following code to make it a string:
wcstr = " ".join(words)
Then create the word cloud object:
wc = WordCloud(background_color="white",
width=1000,
height=1000,
font_path='simhei.ttf'
)In the configuration of word cloud object, background_color is the string, width and height are the word cloud width, font_path is to set the font. Note here that the font must be set, otherwise you will not see any text.
Then pass the string to the generate function of the created word cloud object wc:
wc.generate(wcstr)
Next, use plt to display:
plt.imshow(wc)
plt.axis("off")
plt.show()The complete code is as follows:
import jieba,re,jieba.analyse
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def get_str(path):
f = open(path,encoding="utf-8" )
data = f.read()
f.close()
return data
def word_chinese(text):
pattern = re.compile(r'[^\u4e00-\u9fa5]')
clean = re.sub(pattern, '', text)
return clean
path=r"D:\datacn.txt"
text=get_str(path)
text=word_chinese(text)
jieba.analyse.set_stop_words(r'D:\StopWords.txt')
words = jieba.analyse.textrank(text, topK=168)
print(words)
wcstr = " ".join(words)
wc = WordCloud(background_color="white",
width=1000,
height=1000,
font_path='simhei.ttf'
)
wc.generate(wcstr)
plt.imshow(wc)
plt.axis("off")
plt.show()The final results are as follows:

4, Find the TOP from the data
Due to too much data, it is not convenient to use broken line chart and other statistics. I found the Top latitudes mentioned by foreigners from the weight.
All rankings are as follows:

Top mentioned by foreigners:
The food holy places are Hong Kong, Macao, Guangdong, Wuxi, Guangzhou, Beijing and southern Fujian;
The foods mentioned most are: fried rice, rice, tofu, soybean, beef, noodles, hot pot, fried vegetables, dumplings, cakes and steamed stuffed buns
Most mentioned flavors: sweet and sour, salty
Kitchen utensils mentioned most: hot pot, pottery pot, stone pot and stove
But the first is what soy sauce is, and like the second, it seems that everyone likes our food better! Great!