background
After aggregating and querying a filter field in ES, similar to groupBy operation, it is found that the new data in this field is not displayed, but the user can query the new filter data after full-text retrieval, and has carried out relevant troubleshooting for this problem.
Troubleshooting ideas
First, we need to clarify our data writing process, as shown in the figure below:
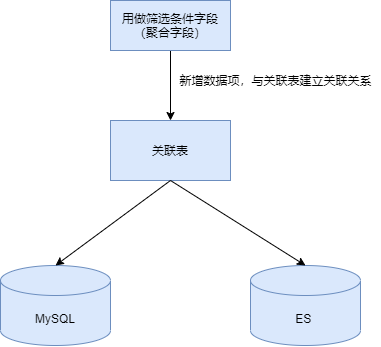
After checking that there is no problem with the data in Mysql database, start to check whether there is a problem in ES. According to the phenomenon, we know that since we can search in full-text retrieval, it means that the data must be written into es, but how to determine the aggregation result?
First, add a log to print out the final DSL statement generated by the code
LOGGER.info("\n{}", searchRequestBuilder);
This makes it easy to debug with the curl command
The following is a query executed on the generated DSL statement:
curl -XGET 'http://ip:9200/es_data_index/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query":{
"bool":{
"must":[
{
"term":{
"companyId":{
"value":1,
"boost":1
}
}
},
{
"term":{
"yn":{
"value":1,
"boost":1
}
}
},
{
"match_all":{
"boost":1
}
}
],
"must_not":[
{
"term":{
"table_sentinel":{
"value":2,
"boost":1
}
}
}
],
"disable_coord":false,
"adjust_pure_negative":true,
"boost":1
}
},
"aggregations":{
"group_by_topics":{
"terms":{
"field":"topic",
"size":10,
"min_doc_count":1,
"shard_min_doc_count":0,
"show_term_doc_count_error":false,
"order":[
{
"_count":"desc"
},
{
"_term":"asc"
}
]
}
}
}
}'
Group above_ by_ Topics is the field we want to aggregate. The following is the result of executing the DSL statement:
"aggregations" : {
"group_by_topics" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 14,
"buckets" : [
{
"key" : 1,
"doc_count" : 35
},
{
"key" : 19,
"doc_count" : 25
},
{
"key" : 18,
"doc_count" : 17
},
{
"key" : 29,
"doc_count" : 15
},
{
"key" : 20,
"doc_count" : 12
},
{
"key" : 41,
"doc_count" : 8
},
{
"key" : 161,
"doc_count" : 5
},
{
"key" : 2,
"doc_count" : 3
},
{
"key" : 3,
"doc_count" : 2
},
{
"key" : 21,
"doc_count" : 2
}
]
}
}
After observation, it is found that there are no new filter items in the aggregation results, and only 10 data are returned
"Sum_other_doc_count": 14. This is a key item. Literally, there are other documents, so what is the meaning of querying in ES?
After query, it is found that there is a paragraph Description:
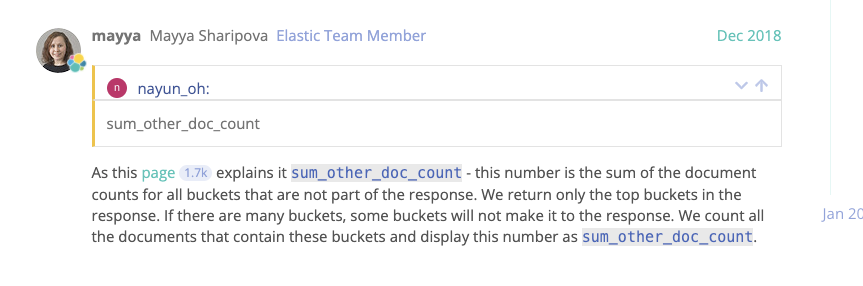
Only top results will be returned, and some results will not be returned
How to return this part of the result?
With the problem, it is found that bucket aggregation is used. By default, it will be based on doc_count is sorted in descending order, and only 10 aggregate results are returned by default
You can solve this problem by increasing the attribute size in the aggregate query, as follows
curl -XGET 'http://ip:9200/es_data_index/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query":{
"bool":{
"must":[
{
"term":{
"companyId":{
"value":1,
"boost":1
}
}
},
{
"term":{
"yn":{
"value":1,
"boost":1
}
}
},
{
"match_all":{
"boost":1
}
}
],
"must_not":[
{
"term":{
"table_sentinel":{
"value":2,
"boost":1
}
}
}
],
"disable_coord":false,
"adjust_pure_negative":true,
"boost":1
}
},
"aggregations":{
"group_by_topics":{
"terms":{
"field":"topic",
"size":100,
"min_doc_count":1,
"shard_min_doc_count":0,
"show_term_doc_count_error":false,
"order":[
{
"_count":"desc"
},
{
"_term":"asc"
}
]
}
}
}
}'
The following is the query result:
"aggregations" : {
"group_by_topics" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 1,
"doc_count" : 35
},
{
"key" : 19,
"doc_count" : 25
},
{
"key" : 18,
"doc_count" : 17
},
{
"key" : 29,
"doc_count" : 15
},
{
"key" : 20,
"doc_count" : 12
},
{
"key" : 41,
"doc_count" : 8
},
{
"key" : 161,
"doc_count" : 5
},
{
"key" : 2,
"doc_count" : 3
},
{
"key" : 3,
"doc_count" : 2
},
{
"key" : 21,
"doc_count" : 2
},
{
"key" : 81,
"doc_count" : 2
},
{
"key" : 801,
"doc_count" : 2
},
{
"key" : 0,
"doc_count" : 1
},
{
"key" : 4,
"doc_count" : 1
},
{
"key" : 5,
"doc_count" : 1
},
{
"key" : 6,
"doc_count" : 1
},
{
"key" : 7,
"doc_count" : 1
},
{
"key" : 11,
"doc_count" : 1
},
{
"key" : 23,
"doc_count" : 1
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 201,
"doc_count" : 1
},
{
"key" : 241,
"doc_count" : 1
}
]
}
All ES filter item data are statistically returned
Set size in the code:
TermsAggregationBuilder termAgg1 = AggregationBuilders.terms("group_by_topics")
.field("topic").size(100);
We have solved the problem. Now consider why ES does not return the result data of all statistical items at once?
The answer is determined by the ES aggregation mechanism. How does es aggregate
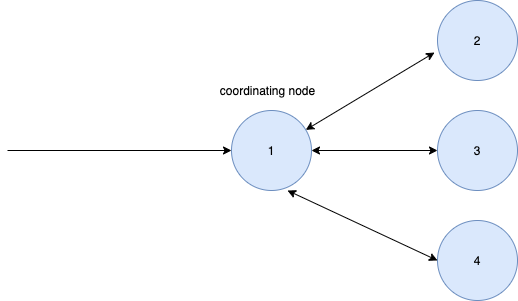
The node that accepts the client is the coordination node
On the coordination node, the search task is divided into two phases: query and fetch
The nodes of real search or aggregation tasks are data nodes, as shown in figures 2, 3 and 4
Aggregation steps:
- The client sends a request to the coordination node
- The coordination node pushes the request to each data node
- Each data node specifies the partition to participate in the data collection
- Coordinate nodes to aggregate the total results
es for efficiency and performance reasons, the result of aggregation is actually inaccurate what do you mean? Take the scenario we encountered above as an example:
By default, the top 10 aggregation result is returned. First, each node takes its own topic 10 and returns it to the coordination node, and then the coordination node summarizes it This will cause the actual aggregate result of the whole quantity to be inconsistent with the expectation
Although there are many ways to improve the accuracy of es aggregation, if the response speed is fast for accurate aggregation of large amount of data, es is not good at this scenario. It is necessary to use products such as clickhouse to solve this scenario
summary
This paper mainly aims at the application problems of practical work to troubleshoot and solve the problem that some data of ES aggregated data are not displayed, and explain the aggregation retrieval principle of ES ES is not good at business scenarios with large amount of data, high aggregation accuracy and fast response speed
reference resources
https://discuss.elastic.co/t/what-does-sum-other-doc-count-mean-exactly/159687