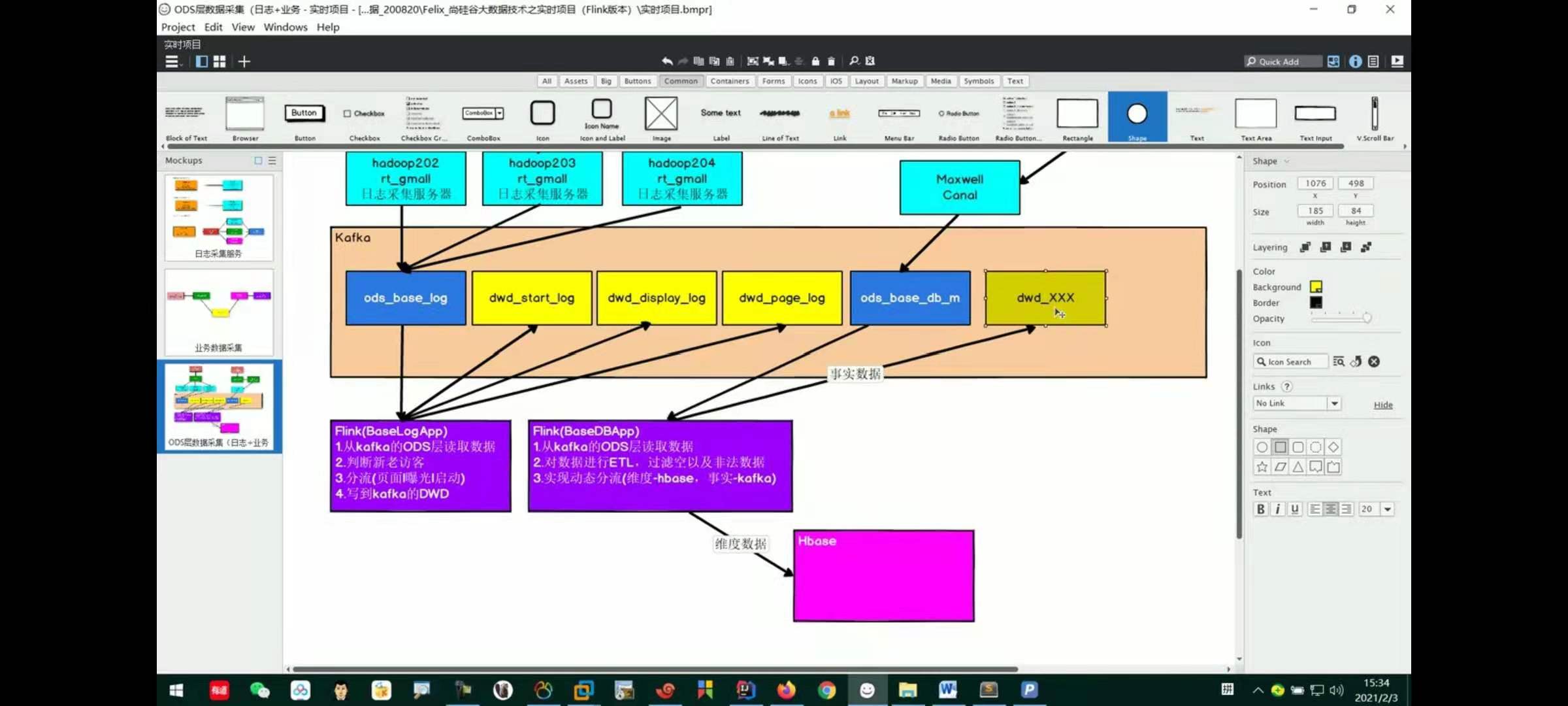
Premise summary: we have implemented dynamic shunting before, that is, we have shunted dimension data and fact data through TableProcessFunction1 class, and then we write the data into Hbase table and Kafka topic table:
hbaseDS.addSink(new DimSink()); kafkaDS.addSink(kafkaSink);
At this time, the two data types after dynamic shunting are roughly as follows:
In the category of code comments, I have introduced the output data and code logic in detail. Next, I will take the logic idea of code writing as the main explanation route. You can refer to the code logic;
Dynamic writing of dimension table and fact table
Hbase dynamic write
How to write this DimSink class? First, we need to establish contact with Hbase through Phoenix. Previously, we have completed the table creation operation corresponding to Hbase by looping through the configuration table, so at this time, we can complete the data insertion operation through Phoenix's Sql syntax;
Therefore, we should first obtain the table name to be inserted, and then sort it into the corresponding Sql statement. The specific syntax is similar to the upsert into table space Table name (column name...) values;
But one thing to note:
if(jsonObj.getString("type").equals("update")){
DimUtil.deleteCached(tableName,dataJsonObj.getString("id"));
}
//The function of this code is to play a role in the subsequent Hbase table data query optimization process, which can be ignored first;
Other code contents mainly include Phoenix link, Sql statement generation and upsert statement writing;
Kafka dynamic write
Back to the tool class of MyKafkaUtil we wrote earlier, our Producer object was generated as follows:
//Package FlinkKafkaProducer
public static FlinkKafkaProducer<String> getKafkaSink(String topic) {
//The returned is kafka's producer object;
return new FlinkKafkaProducer<String>(KAFKA_SERVER, topic, new SimpleStringSchema());
}
The topic object of this code has been determined in the method parameters, but we have more than one kafka topic table here. If we want to write all kafka topic data, we can only generate as many Producer objects as there are corresponding kafka topics in the configuration table. Even so, if there are new fact data types in the business, If a new kafka topic is needed, we must stop the cluster and add a new Producer object to generate code, which is obviously unreasonable; Therefore, here we use another creation method:
//The generated FlinkKafkaProducer can support multiple topic s;
public static <T> FlinkKafkaProducer<T> getKafkaSinkBySchema(KafkaSerializationSchema<T> kafkaSerializationSchema) {
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,KAFKA_SERVER);
//Set timeout for production data
props.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,15*60*1000+"");
//You can send to the default topic or specify topic;
//The type of KafkaSerializationSchema serialization;
//props producer configuration information;
//FlinkKafkaProducer.Semantic semantics, specifying accuracy and consistency;
//In this way, it can be sent to multiple topics;
return new FlinkKafkaProducer<T>(DEFAULT_TOPIC, kafkaSerializationSchema, props, FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
The generated FlinkKafkaProducer object can dynamically select the kafka topic name, so let's pull to see how this producer object can dynamically write kafka topic data:
FlinkKafkaProducer<JSONObject> kafkaSink = MyKafkaUtil.getKafkaSinkBySchema(
new KafkaSerializationSchema<JSONObject>() {
@Override
public void open(SerializationSchema.InitializationContext context) throws Exception {
System.out.println("kafka serialize");
}
//Core method, serialization of each piece of data;
@Override
//The two bytes [] here refer to K and V respectively; But there is no K here, only V; Note: K is not the topic here, and topic is not transmitted;
//K (i.e. Topic is used to help assign to different topics)
public ProducerRecord<byte[], byte[]> serialize(JSONObject jsonObj, @Nullable Long timestamp) {
String sinkTopic = jsonObj.getString("sink_table");
JSONObject dataJsonObj = jsonObj.getJSONObject("data");
//Two parameters respectively represent: subject name and data value;
//The meaning of serialization is to convert data into Byte array, so the value here is converted into Byte type; The topic can be located without serialization;
return new ProducerRecord<>(sinkTopic,dataJsonObj.toString().getBytes());
}
}
);
//In the ProducerRecord method, the sinkTable in the data stream is obtained (remember that the data stream is already subject data at this time) to dynamically pass in the sinkTopic;
So far, the operation of saving shunting data to Hbase and Kafka has been completed;
Summary:
1 receive Kafka Data, and then filter null data after conversion
yes Maxwell Grab data for ETL,Keep the useful parts and filter out the useless ones
2 Realize dynamic shunting function (key and difficult points)
because MaxWell Is to write all data into one file Topic in, This is obviously not conducive to future data processing. So you need to take each table apart. However, because each table has different characteristics, some tables are dimension tables, some tables are fact tables, and some tables are both fact tables and dimension tables in some cases.
In real-time calculation, dimension data is generally written into the storage container, which is generally a database convenient for query through the primary key, such as HBase,Redis,MySQL Wait. Generally, the fact data is written into the stream for further processing, and finally a wide table is formed. But it's used here Redis The memory requirement will be very high, so it is used here HBase To store dimension data;
But as Flink How to know which tables are dimension tables and which are fact tables for real-time calculation tasks? Which fields should these tables collect?
We can put the above content in a certain place and configure it centrally. Such a configuration is not suitable for writing in the configuration file, because the business side needs to modify the configuration and restart the computing program every time a table is added as the demand changes. Therefore, a dynamic configuration scheme is needed to save this configuration for a long time. Once the configuration changes, real-time computing can automatically perceive it. This can be implemented in two schemes:
➢ One is to use Zookeeper Storage, by Watch Sensing data changes.
➢ The other is to use mysql Database storage, periodic synchronization.
The second option is mainly mysql For configuration data initialization and maintenance management, use sql It is more convenient. Although the timeliness of periodic operation is poor, the configuration changes are not frequent.
//In the current project, you choose to maintain the configuration information table by yourself, but in the actual project, it is often maintained by web pages;
//For example: an event occurs in the actual business: a new brand is added to the brand table of the database, which is equivalent to adding to the base_ A record is added to the trade mark table. Binlog will save this record. Maxwell will listen to the change of binlog, and then send the changed record to Kafka in the form of json (ods_base_db_m); Basedbapp from kafaka_ base_ db_ Read this record in MySql. Then get the relevant information from the MySql configuration table:
--Send dimension data to HBase
--Fact data sent to kafka of dwd layer
3.to configure phoenix and hbase Create the corresponding namespace according to the relevant contents of the; (see for details) PDF (file)
4 Save the divided streams into corresponding tables and topics
Save business data to Kafka In the topic of
Save dimension data to Hbase In the table
/*
Approximate data style:
{"database":"gmall0709","table":"order_info","type":"update","ts":1626008658,"xid":254,"xoffset":4651,
"data":{"id":28993,"consignee":"Jiang Lianzhen "," consignee_tel":"13494023727","total_amount":21996.00,
"order_status":"1001","user_id":438,"payment_way":null,"delivery_address":"Door 977, unit 1, building 39, 17th Street ",
"order_comment":"Description 178284","out_trade_no":"352538349474172","trade_body ":" October rice field long grain fragrant rice northeast rice 5kg and other 10 commodities ",
"create_time":"2021-07-11 21:04:17","operate_time":"2021-07-11 21:04:18","expire_time":"2021-07-11 21:19:17",
"process_status":null,"tracking_no":null,"parent_order_id":null,"img_url":"http://img.gmall.com/646283.jpg",
"province_id":29,"activity_reduce_amount":0.00,"coupon_reduce_amount":0.00,"original_total_amount":21989.00,
"feight_fee":7.00,"feight_fee_reduce":null,"refundable_time":null},
"old":{"operate_time":null}}
Some data are incomplete
*/
//The data carries the table information and type information. According to this, you can find out whether you belong to dimension data or fact data in the configuration table;
//log test:
open zk.sh,kk.sh,maxwell.sh,Current application; Then open the business data jar Package:
/opt/module/rt_dblog $java -jar gmall2020-mock-db-2020-11-27.jar
//Check whether data is received in mysql;
//Configuration information table test:
//Test whether the table just created can be read_ Data information of process table;
//Manually add a piece of data, and then run com chenxu. gmall. realtime. utils. MyKafkaUtil;
//Configure API testing of phoenix and HBase;
//Open zk, kk, hdfs, hbase, phoenix, maxwell and this application. Remember to go to gmall0709 in advance_ Manually insert a configuration file information into the realtime database;
//At this time, phoenix will automatically create a table GMALL0709_REALTIME
//Manually modify base in gmall0709 database_ The data of the trade mark table should give an output similar to the following;
//Dimension > > > >: 2 > {database ":" gmall0709 "," XID ": 18593," data ": {" Id ": 17}," commit ": true," sink_table ":" dim_base_trademark "," type ":" insert "," table ":" base_trademark "," ts ": 1626230909}
//Specific data will not be received in hbase;
//Then put the sink in the configuration table just now_ Change the type to kafka and put sink_ Change table to first
//At this time, the Map will re read the new configuration information, add it to the memory, and the data will also be output to kafka;
//Restart the application and the following output will appear:
//Facts > > > >: 4 > {database ":" gmall0709 "," XID ": 19366," data ": {" Id ": 19}," commit ": true," sink_table ":" first "," type ":" insert "," table ":" base_trademark "," ts ": 1626231206}
//However, data will not be received in kafka;
//So the next thing to do is to save the corresponding dimension data to hbase table and output the fact data to kafka;
//Test TODO6 newSink function to see if dimension data will be stored in the corresponding HBase table;
//Start zk, kk, hdfs, hbase, maxwell, phoenix and applications;
//Manually modify the configuration table information just now and change it back to hbase and DIM_BASE_TRADEMARK;
//Go to base again_ Add the following data to the trade mark table;
//Output a message as follows:
//Dimension > > > >: 2 > {database ":" gmall0709 "," XID ": 30932," data ": {tm_name": "20", "Id": 20}, "commit": true, "sink_table": "dim_base_trademark", "type": "insert", "table": "base_trademark", "ts": 1626240730}
//SQL for inserting data into Phoenix: upsert into gmall0709_ REALTIME. DIM_ BASE_ TRADEMARK(tm_name,id) values ('20','20')
//Query whether to insert data in phoenix:
//select * from GMALL0709_REALTIME.DIM_BASE_TRADEMARK;
//test
//Start hdfs, zk, kafka, Maxwell, HBase and kafka's dwd_order_info theme consumption
//To gmall2021_ Table of realtime database_ Insert test data into the process table
//For example, the corresponding data is: order_info insert kafka dwd_order_info id,consignee,consignee_tel,total_count,order_status,user_id,payment_way,delivery_address,order_comment,out_trade_no,trade_body,create_time,operate_time,expire_time,process_status,tracking_no,parent_order_id,img_url,province_id,activity_reduce_amount,coupon_reduce_amount,original_total_amount,feight_fee,feight_fee_reduce,refundable_time id
//Run BaseDBApp in idea
//Run RT_ The jar package under dblog simulates the generated data
//View console output and kafka topic name consumption configured in the configuration table (kafka consumes order data)
//At this point, you can add a base_ For the data in the trade mark table, check whether the console will output the information of the dimension table, and then check whether there is data in phoenix:
//select * from GMALL0709_REALTIME.DIM_BASE_TRADEMARK;
The flow chart is summarized as follows: (note that how to use the specific dimension data and fact data here has not been realized, but a simple table test has been done.)