[source code analysis] PyTorch distributed elastic training (6) - monitoring / fault tolerance
0x00 summary
As for PyTorch elastic training, we have introduced Agent and rendezous respectively so far, but some parts are not in-depth, such as monitoring. This paper unifies them and logically combs the elastic training as a whole.
The flexibility training series is as follows:
This series of articles is as follows:
[Source code analysis] PyTorch distributed elastic training (1) - general idea
[ Source code analysis] PyTorch distributed elastic training (2) - start & single node process
[ Source code analysis] PyTorch distributed elastic training (3) - agent
[ Source code analysis] PyTorch distributed elastic training (4) - Rendezvous architecture and logic
[Source code analysis] PyTorch distributed elastic training (5) - Rendezvous engine
0x01 overall logic
We need to look at the system logic from several angles, roughly from top to bottom, from the whole to the part.
1.1 Node cluster Perspective
First, from the perspective of Node clusters, we can think of an aerial view of the elastic system from top to bottom. From this perspective, an Agent is running on each Node. The Agent contains a rendezous, which is responsible for distributed negotiation. The Agent is also responsible for starting and monitoring workers.
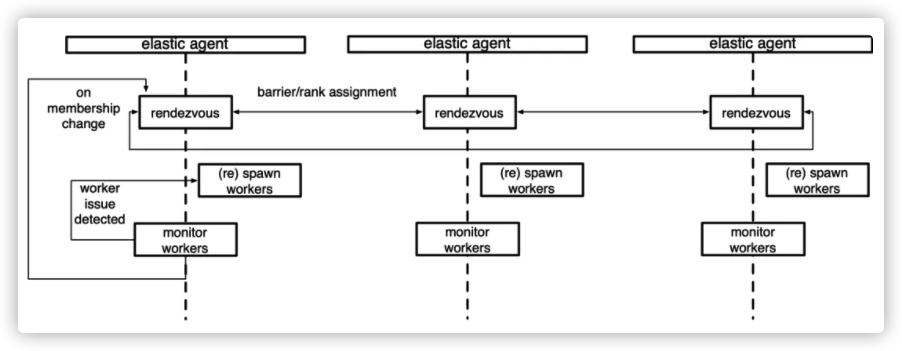
1.2 overall logic diagram of agent
We then go deep into the agent. From the above, the overall logic is shown in the figure below.
- 1) Call_ initialize_workers to start the worker process, that is, start multiple processes to execute user programs in parallel for training.
- 2) Call_ rendezvous, its interior:
- Call next_rendezvous handles membership changes,
- Call_ assign_worker_ranks creates ranks for workers.
- 3) Call_ start_workers start workers.
- 2) Call_ rendezvous, its interior:
- 4) Call_ monitor_workers monitors the results of these processes.
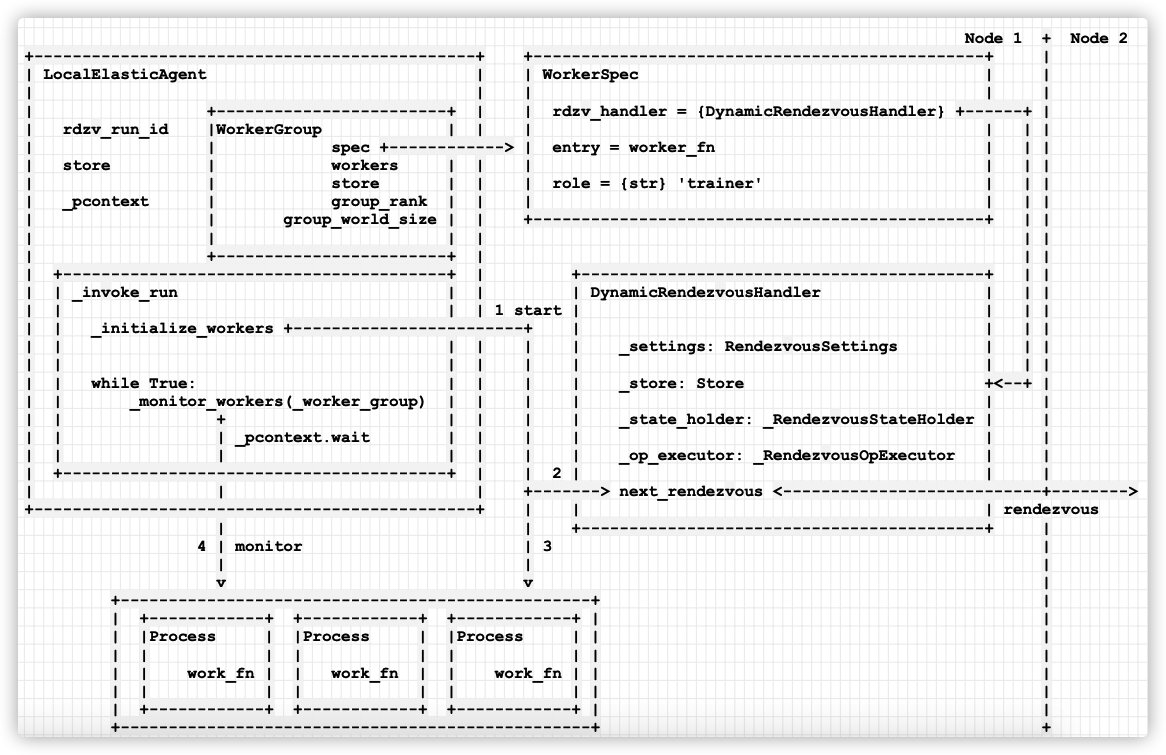
1.3 monitoring angle
The core of elastic training is monitoring / dynamic processing, so we go deep into the monitoring module for analysis. From the perspective of monitoring, Agent main loop_ invoke_ The specific logic of run is as follows:
- Call_ initialize_workers start workers.
- Call_ rendezvous, its interior:
- Call next_rendezvous handles membership changes,
- Call_ assign_worker_ranks creates ranks for workers.
- Call_ start_workers start workers.
- Call_ rendezvous, its interior:
- The program enters the while loop, and then passes_ monitor_workers regularly rotate training to monitor the operation of user programs and make judgments according to the situation.
- If the worker process is wrong or unhealthy, enter elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}: here.
- First call_ restart_ Restart the workers, start the new rendezvous, and restart the worker process.
- If the maximum number of restarts is exceeded, close the task.
- If the program is running normally, enter state = = workerstate Healthy here.
- If it is scale up, if a new node is waiting, restart all workers.
The specific codes are as follows:
def _invoke_run(self, role: str = DEFAULT_ROLE) -> RunResult:
# NOTE: currently only works for a single role
spec = self._worker_group.spec
role = spec.role
self._initialize_workers(self._worker_group) # Start worker
monitor_interval = spec.monitor_interval
rdzv_handler = spec.rdzv_handler
while True:
assert self._worker_group.state != WorkerState.INIT
# Regular monitoring
time.sleep(monitor_interval)
# Monitor client program operation
run_result = self._monitor_workers(self._worker_group)
state = run_result.state # Process operation
self._worker_group.state = state
if state == WorkerState.SUCCEEDED:
# The program ends normally
self._exit_barrier() # If one succeeds, it's all over
return run_result
elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}:
# Program error
if self._remaining_restarts > 0: # retry
self._remaining_restarts -= 1
self._restart_workers(self._worker_group) # Restart
else:
self._stop_workers(self._worker_group) # Retry times reached, end workers
self._worker_group.state = WorkerState.FAILED
self._exit_barrier()
return run_result
elif state == WorkerState.HEALTHY:
# The program runs normally
# Node membership changes, such as scale up
# membership changes do not count as retries
num_nodes_waiting = rdzv_handler.num_nodes_waiting()
group_rank = self._worker_group.group_rank
# If a new node is waiting, restart all workers
if num_nodes_waiting > 0:
self._restart_workers(self._worker_group)
else:
raise Exception(f"[{role}] Worker group in {state.name} state")
We refine it again, as follows:
_initialize_workers <---------------------------------+ Node 1 + Node 2 _initialize_workers
+ | | +
| | | |
| | +-----------------+ | +-----------------+ |
v | |RendezvousHandler| sync |RendezvousHandler| v
_rendezvous +---------------------------------------->+ | <----+----> | +<---+ _rendezvous
+ next_rendezvous | | | | | | +
| | | | | | | |
_assign_worker_ranks | | | heartbeat | | |
| | | | <----+----> | |
v | +-----------------+ | +-----------------+ v
_start_workers | | _start_workers
+ | | +
| | | |
| | | |
v | | v
+-----+-------------------------------------------------------+ | +--------+---------+
| | | | | |
|state = _monitor_workers | | | | |
| + | | | | |
| | | | | | |
| | UNHEALTHY,FAILED 1. Process fail | | | | |
+--> | +-----------------> _restart_workers +--+ | +--> | | |
| | | | + | | | | |
| | | +--> _stop_workers| | | | LOOP Every 30S |
| | | HEALTHY 2. Node change | | | | | |
| | +-----------------> _restart_workers +--+ | | | | |
| | | | | | | |
| | | | | | | |
| | | SUCCEEDED | | | | |
| | | | | | | |
| | | 3. exit | | | | |
| | | | | | | |
| +-------------------------------------------------------------+ | | | |
| | | | | |
<---------------------------------------------------------------------+ | +--------+---------+
| LOOP Every 30S | |
| | |
v | v
_exit_barrier + _exit_barrier
The mobile phone is shown in the figure:
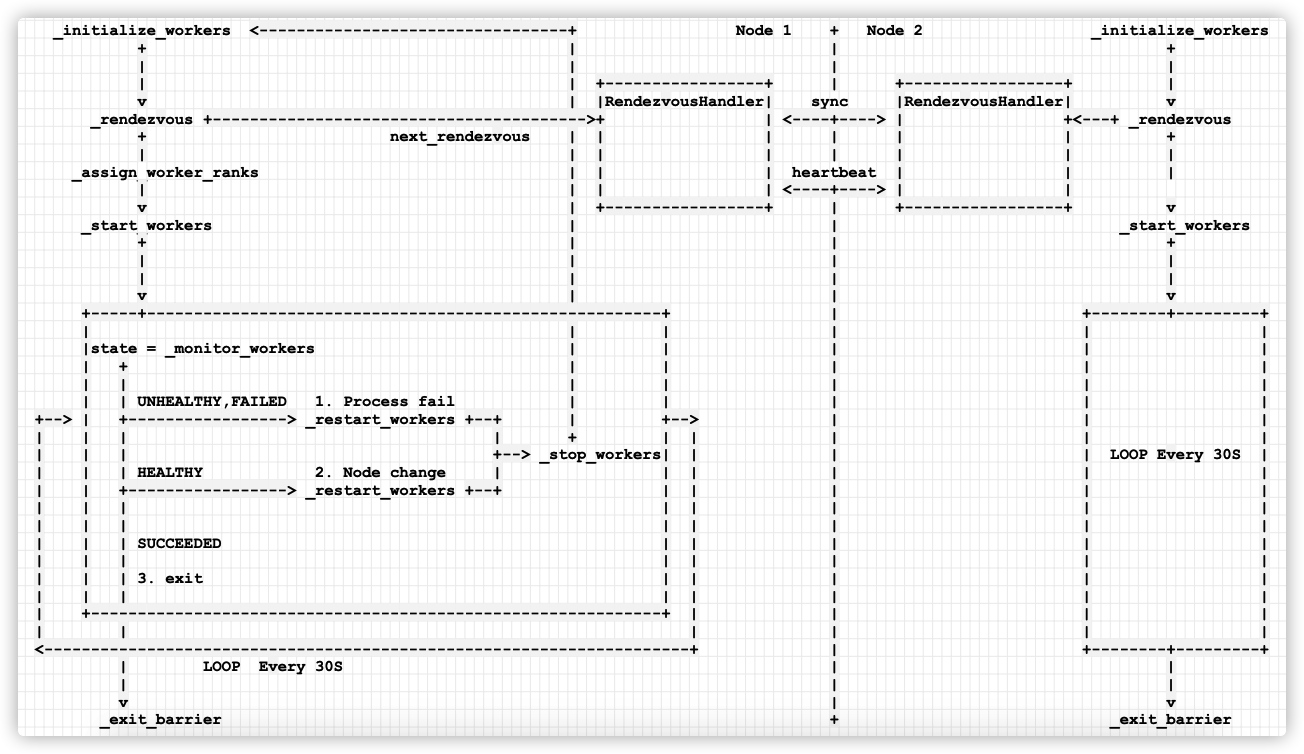
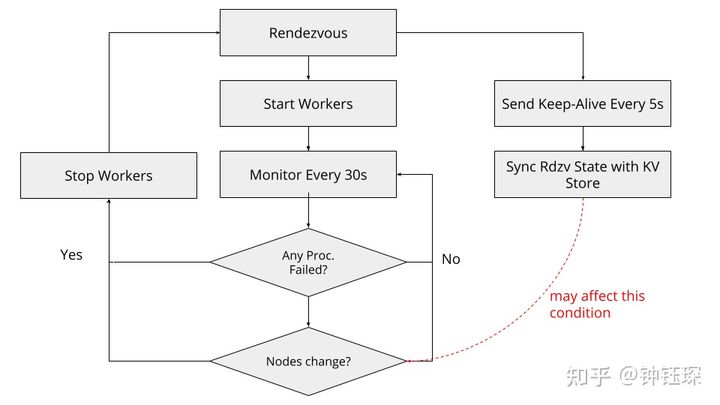
Or you can see the figure below. The picture is from https://zhuanlan.zhihu.com/p/408382623 .
0x02 multi process
The monitoring mechanism is to monitor multiple running training workers, which involves the startup and monitoring of multiple processes. We need to introduce multiple processes. This should be seen from the entry of starting the worker process.
2.1 start workers
_ start_workers call start_processes to start the worker process. By default_ start_ The method is "spawn". That is, multiple processes are started to execute user programs in parallel. At the same time, the running results of these processes will be monitored. start_ Among the processes parameters, entrypoint and args are user commands and parameters, and entrypoint can be a function or a string.
Then_ start_workers start_ The results of the processes method starting multithreading are saved in_ In pcontext, it will be used later_ Pcontext to continue control. For example, ending the worker is a direct call_ close method of pcontext.
@prof
def _start_workers(self, worker_group: WorkerGroup) -> Dict[int, Any]:
spec = worker_group.spec store = worker_group.store
assert store is not None
master_addr, master_port = super()._get_master_addr_port(store)
restart_count = spec.max_restarts - self._remaining_restarts
use_agent_store = spec.rdzv_handler.get_backend() == "static"
args: Dict[int, Tuple] = {}
envs: Dict[int, Dict[str, str]] = {}
for worker in worker_group.workers:
local_rank = worker.local_rank
worker_env = {
"LOCAL_RANK": str(local_rank),
"RANK": str(worker.global_rank),
"GROUP_RANK": str(worker_group.group_rank),
"ROLE_RANK": str(worker.role_rank),
"ROLE_NAME": spec.role,
"LOCAL_WORLD_SIZE": str(spec.local_world_size),
"WORLD_SIZE": str(worker.world_size),
"GROUP_WORLD_SIZE": str(worker_group.group_world_size),
"ROLE_WORLD_SIZE": str(worker.role_world_size),
"MASTER_ADDR": master_addr,
"MASTER_PORT": str(master_port),
"TORCHELASTIC_RESTART_COUNT": str(restart_count),
"TORCHELASTIC_MAX_RESTARTS": str(spec.max_restarts),
"TORCHELASTIC_RUN_ID": spec.rdzv_handler.get_run_id(),
"TORCHELASTIC_USE_AGENT_STORE": str(use_agent_store),
"NCCL_ASYNC_ERROR_HANDLING": str(1),
}
if "OMP_NUM_THREADS" in os.environ:
worker_env["OMP_NUM_THREADS"] = os.environ["OMP_NUM_THREADS"]
envs[local_rank] = worker_env
worker_args = list(spec.args)
worker_args = macros.substitute(worker_args, str(local_rank))
args[local_rank] = tuple(worker_args)
# scaling events do not count towards restarts (gets same attempt #)
# remove existing log dir if this restart is due to a scaling event
attempt_log_dir = os.path.join(self._log_dir, f"attempt_{restart_count}")
shutil.rmtree(attempt_log_dir, ignore_errors=True)
os.makedirs(attempt_log_dir)
assert spec.entrypoint is not None
self._pcontext = start_processes( # Save the results of starting multithreading in_ In pcontext.
name=spec.role,
entrypoint=spec.entrypoint, # Training code entry
args=args, # What matters here is local rank
envs=envs,
log_dir=attempt_log_dir,
start_method=self._start_method,
redirects=spec.redirects,
tee=spec.tee,
)
return self._pcontext.pids()
2.1.1 start_processes
Note that here start_ The processes code is in torch / distributed / elastic / multiprocessing / API Py, and the start of mp used later_ Processes are different. start_processes will extract local rank from args, and then use local rank_ Rank does operations, such as creating a log file for each process. The meaning is to synchronize each worker process with local_rank, a local_rank corresponds to a worker process.
def start_processes(
name: str,
entrypoint: Union[Callable, str],
args: Dict[int, Tuple],
envs: Dict[int, Dict[str, str]],
log_dir: str,
start_method: str = "spawn",
redirects: Union[Std, Dict[int, Std]] = Std.NONE,
tee: Union[Std, Dict[int, Std]] = Std.NONE,
) -> PContext:
"""
Starts ``n`` copies of ``entrypoint`` processes with the provided options.
``entrypoint`` is either a ``Callable`` (function) or a ``str`` (binary).
The number of copies is determined by the number of entries for ``args`` and
``envs`` arguments, which need to have the same key set.
``args`` and ``env`` parameters are the arguments and environment variables
to pass down to the entrypoint mapped by the replica index (local rank).
All local ranks must be accounted for.
That is, the keyset should be ``{0,1,...,(nprocs-1)}``.
Args:
name: a human readable short name that describes what the processes are
(used as header when tee'ing stdout/stderr outputs)
entrypoint: either a ``Callable`` (function) or ``cmd`` (binary)
args: arguments to each replica
envs: env vars to each replica
log_dir: directory used to write log files
nprocs: number of copies to create (one on each process)
start_method: multiprocessing start method (spawn, fork, forkserver)
ignored for binaries
redirects: which std streams to redirect to a log file
tees: which std streams to redirect + print to console
"""
# listdir raises FileNotFound or NotADirectoryError so no need to check manually
if os.listdir(log_dir):
raise RuntimeError(
f"log_dir: {log_dir} is not empty, please provide an empty log_dir"
)
nprocs = len(args)
_validate_full_rank(args, nprocs, "args")
_validate_full_rank(envs, nprocs, "envs")
# create subdirs for each local rank in the logs_dir
redirs = to_map(redirects, nprocs)
ts = to_map(tee, nprocs)
# to tee stdout/stderr we first redirect into a file
# then tail -f stdout.log/stderr.log so add tee settings to redirects
for local_rank, tee_std in ts.items():
redirect_std = redirs[local_rank]
redirs[local_rank] = redirect_std | tee_std
stdouts = {local_rank: "" for local_rank in range(nprocs)}
stderrs = {local_rank: "" for local_rank in range(nprocs)}
tee_stdouts: Dict[int, str] = {}
tee_stderrs: Dict[int, str] = {}
error_files = {}
# Local is heavily used_ rank
for local_rank in range(nprocs):
clogdir = os.path.join(log_dir, str(local_rank))
os.mkdir(clogdir)
rd = redirs[local_rank]
if (rd & Std.OUT) == Std.OUT:
stdouts[local_rank] = os.path.join(clogdir, "stdout.log")
if (rd & Std.ERR) == Std.ERR:
stderrs[local_rank] = os.path.join(clogdir, "stderr.log")
t = ts[local_rank]
if t & Std.OUT == Std.OUT:
tee_stdouts[local_rank] = stdouts[local_rank]
if t & Std.ERR == Std.ERR:
tee_stderrs[local_rank] = stderrs[local_rank]
error_file = os.path.join(clogdir, "error.json")
error_files[local_rank] = error_file
envs[local_rank]["TORCHELASTIC_ERROR_FILE"] = error_file
context: PContext
if isinstance(entrypoint, str):
context = SubprocessContext(
name=name,
entrypoint=entrypoint,
args=args,
envs=envs,
stdouts=stdouts,
stderrs=stderrs,
tee_stdouts=tee_stdouts,
tee_stderrs=tee_stderrs,
error_files=error_files,
)
else:
context = MultiprocessContext(
name=name,
entrypoint=entrypoint,
args=args,
envs=envs,
stdouts=stdouts,
stderrs=stderrs,
tee_stdouts=tee_stdouts,
tee_stderrs=tee_stderrs,
error_files=error_files,
start_method=start_method,
)
try:
context.start()
return context
except Exception:
context.close()
raise
2.1.2 RunResult
The running result of the worker process is marked by RunResult. RunResult is the result returned by the worker thread. The running result follows the "all or nothing" policy. The running will succeed only if and only if all local workers managed by this agent are successfully completed.
As mentioned earlier, each worker process is the same as local_rank is linked. It's also right to think about it. If there are five GPU s, of course, start five working processes for training. These five working processes correspond to local rank 0~4.
However, the RunResult comment indicates that if the result is successful (for example, is_failed() = False), return_ The values field contains the output (return value) of the worker processes managed by this agent. These worker processes are mapped by their GLOBAL ranks. That is, result.return_values[0] is the return value of global rank 0. Therefore, there will be a mapping from local rank to global rank in _monitor_workers, which will be discussed later.
@dataclass
class RunResult:
"""
Results returned by the worker executions. Run results follow an "all-or-nothing" policy
where the run is successful if and only if ALL local workers managed by this agent
complete successfully.
If the result is successful (e.g. ``is_failed() = False``) then the ``return_values``
field contains the outputs (return values) of the workers managed by THIS agent mapped
by their GLOBAL ranks. That is ``result.return_values[0]`` is the return value of
global rank 0.
.. note:: ``return_values`` are only meaningful for when the worker entrypoint
is a function. Workers specified as a binary entrypoint do not canonically
have a return value and the ``return_values`` field is meaningless and
may be empty.
If ``is_failed()`` returns ``True`` then the ``failures`` field contains the
failure information, again, mapped by the GLOBAL rank of the worker that failed.
The keys in ``return_values`` and ``failures`` are mutually exclusive, that is,
a worker's final state can only be one of: succeeded, failed. Workers intentionally
terminated by the agent according to the agent's restart policy, are not represented
in either ``return_values`` nor ``failures``.
"""
state: WorkerState
return_values: Dict[int, Any] = field(default_factory=dict)
failures: Dict[int, ProcessFailure] = field(default_factory=dict)
def is_failed(self) -> bool:
return self.state == WorkerState.FAILED
2.1 TE use
TE uses torch MP and subprocess packages for multi process processing. When starting multiple processes, save the results in_ In PContext, this is an instance of PContext type.
self._pcontext = start_processes( # Save the results of starting multithreading in_ In pcontext.
name=spec.role,
entrypoint=spec.entrypoint,
args=args,
envs=envs,
log_dir=attempt_log_dir,
start_method=self._start_method,
redirects=spec.redirects,
tee=spec.tee,
)
Where, start_processes, PContext from:
from torch.distributed.elastic.multiprocessing import start_processes, PContext
_ monitor_workers use it when monitoring_ pcontext for monitoring. During monitoring, it will be converted to workerstate according to the thread results FAILED,WorkerState. Health or workerstate Succeeded returns to the upper layer.
@prof
def _monitor_workers(self, worker_group: WorkerGroup) -> RunResult:
role = worker_group.spec.role
worker_pids = {w.id for w in worker_group.workers}
assert self._pcontext is not None
pc_pids = set(self._pcontext.pids().values())
result = self._pcontext.wait(0) # Monitor the operation results
if result:
if result.is_failed():
# map local rank failure to global rank
worker_failures = {}
for local_rank, failure in result.failures.items():
worker = worker_group.workers[local_rank]
worker_failures[worker.global_rank] = failure
return RunResult(
state=WorkerState.FAILED, # Process error, return workerstate FAILED
failures=worker_failures,
)
else:
# copy ret_val_queue into a map with a global ranks
workers_ret_vals = {}
for local_rank, ret_val in result.return_values.items():
worker = worker_group.workers[local_rank]
workers_ret_vals[worker.global_rank] = ret_val
return RunResult(
state=WorkerState.SUCCEEDED,
return_values=workers_ret_vals,
)
else:
return RunResult(state=WorkerState.HEALTHY)
It can be seen that PContext is the key, so let's take a look at this class.
2.2 PContext
PContext is an abstract class, which is actually some basic configuration.
class PContext(abc.ABC):
"""
The base class that standardizes operations over a set of processes
that are launched via different mechanisms. The name ``PContext``
is intentional to disambiguate with ``torch.multiprocessing.ProcessContext``.
.. warning:: stdouts and stderrs should ALWAYS be a superset of
tee_stdouts and tee_stderrs (respectively) this is b/c
tee is implemented as a redirect + tail -f <stdout/stderr.log>
"""
def __init__(
self,
name: str,
entrypoint: Union[Callable, str],
args: Dict[int, Tuple],
envs: Dict[int, Dict[str, str]],
stdouts: Dict[int, str],
stderrs: Dict[int, str],
tee_stdouts: Dict[int, str],
tee_stderrs: Dict[int, str],
error_files: Dict[int, str],
):
self.name = name
# validate that all mappings have the same number of keys and
# all local ranks are accounted for
nprocs = len(args)
_validate_full_rank(stdouts, nprocs, "stdouts")
_validate_full_rank(stderrs, nprocs, "stderrs")
self.entrypoint = entrypoint
self.args = args
self.envs = envs
self.stdouts = stdouts
self.stderrs = stderrs
self.error_files = error_files
self.nprocs = nprocs
self._stdout_tail = TailLog(name, tee_stdouts, sys.stdout)
self._stderr_tail = TailLog(name, tee_stderrs, sys.stderr)
However, two derived classes are critical: MultiprocessContext and SubprocessContext. As mentioned earlier, start_ Among the processes parameters, entrypoint and args are user commands and parameters, and entrypoint can be a function or a string. If entrypoint is a function, MultiprocessContext is used. If it is a string type, use SubprocessContext.
def start_processes(
name: str,
entrypoint: Union[Callable, str],
args: Dict[int, Tuple],
envs: Dict[int, Dict[str, str]],
log_dir: str,
start_method: str = "spawn",
redirects: Union[Std, Dict[int, Std]] = Std.NONE,
tee: Union[Std, Dict[int, Std]] = Std.NONE,
) -> PContext:
context: PContext
if isinstance(entrypoint, str): # If string
context = SubprocessContext(
name=name,
entrypoint=entrypoint,
args=args,
envs=envs,
stdouts=stdouts,
stderrs=stderrs,
tee_stdouts=tee_stdouts,
tee_stderrs=tee_stderrs,
error_files=error_files,
)
else:
context = MultiprocessContext( # Function comes here
name=name,
entrypoint=entrypoint,
args=args,
envs=envs,
stdouts=stdouts,
stderrs=stderrs,
tee_stdouts=tee_stdouts,
tee_stderrs=tee_stderrs,
error_files=error_files,
start_method=start_method,
)
try:
context.start() # Call here
return context
except Exception:
context.close()
raise
Specifically, the basis of the two derived classes is different.
- MultiprocessContext uses torch multiprocessing. start_ Processes to start the process.
- SubprocessContext uses subprocess Popen to start the process.
Next, we will only use MultiprocessContext to analyze.
2.3 MultiprocessContext
MultiprocessContext is defined as follows, of which the most meaningful is_ The member variable pc is actually the ProcessContext variable.
import torch.multiprocessing as mp
class MultiprocessContext(PContext):
"""
``PContext`` holding worker processes invoked as a function.
"""
def __init__(
self,
name: str,
entrypoint: Callable,
args: Dict[int, Tuple],
envs: Dict[int, Dict[str, str]],
stdouts: Dict[int, str],
stderrs: Dict[int, str],
tee_stdouts: Dict[int, str],
tee_stderrs: Dict[int, str],
error_files: Dict[int, str],
start_method: str,
):
super().__init__(
name,
entrypoint,
args,
envs,
stdouts,
stderrs,
tee_stdouts,
tee_stderrs,
error_files,
)
self.start_method = start_method
# each ret_val queue will always contain a single element.
self._ret_vals = {
local_rank: mp.get_context(self.start_method).SimpleQueue()
for local_rank in range(self.nprocs)
}
# see comments in ``join()`` for what this is
self._return_values: Dict[int, Any] = {}
self._pc: Optional[mp.ProcessContext] = None # Here is the key
self._worker_finished_event = mp.get_context(self.start_method).Event()
2.3.1 start
MultiprocessContext start is the call to MP start_ Processes, and then save the results.
import torch.multiprocessing as mp
def _start(self):
if self._pc:
raise ValueError(
"The process context already initialized."
" Most likely the start method got called twice."
)
self._pc = mp.start_processes( # This returns MP ProcessContext
fn=_wrap,
args=(
self.entrypoint,
self.args,
self.envs,
self.stdouts,
self.stderrs,
self._ret_vals,
self._worker_finished_event,
),
nprocs=self.nprocs,
join=False,
daemon=False,
start_method=self.start_method,
)
2.3.2 wait
The wait method is in its base class class class PContext(abc.ABC):. It's a loop call_ poll function to detect periodically.
def wait(self, timeout: float = -1, period: float = 1) -> Optional[RunProcsResult]:
"""
Waits for the specified ``timeout`` seconds, polling every ``period`` seconds
for the processes to be done. Returns ``None`` if the processes are still running
on timeout expiry. Negative timeout values are interpreted as "wait-forever".
A timeout value of zero simply queries the status of the processes (e.g. equivalent
to a poll).
"""
if timeout == 0:
return self._poll()
if timeout < 0:
timeout = sys.maxsize
expiry = time.time() + timeout
while time.time() < expiry: # Periodic operation
pr = self._poll() # Use poll to detect
if pr:
return pr
time.sleep(period)
return None
2.3.3 _poll
_ The poll function is specifically used for detection, calling torch mp. ProcessContext. Join to test. torch.mp.ProcessContext throws an exception when some / all worker processes fail. If it times out, the worker process status is checked and returned immediately. Because we use synchronize Event waits for all processes to complete, so the join will never return success.
PyTorch uses multiprocessing The queue brings the return value of the working process back to the parent process, and the last returned result includes the running result of each process.
def _poll(self) -> Optional[RunProcsResult]:
try:
# torch.mp.ProcessContext Throws an Exception if some/all of
# worker processes failed
# timeout < 0 checks worker status and return immediately
# Join will never return success since we use synchronize.Event to wait
# for all processes to finish.
self._pc.join(-1)
# IMPORTANT: we use multiprocessing.Queue to carry worker return values
# back to the parent, the worker process will wait before terminating
# until all the buffered items are fed by the feeder thread to the underlying
# pipe. Hence to prevent deadlocks on large return values,
# we opportunistically try queue.get on each join call
# See: https://docs.python.org/2/library/multiprocessing.html#all-platforms
for local_rank in range(0, self.nprocs): # Traverse the following processes
return_queue = self._ret_vals[local_rank]
if not return_queue.empty():
# save the return values temporarily into a member var
self._return_values[local_rank] = return_queue.get() # Get process running results
if self._is_done():
# we should ALWAYS have ALL the return values when all the processes are done
self._worker_finished_event.set()
# Wait untill all processes are finished. At this point workers finished executing user function
self._pc.join()
self.close()
return RunProcsResult(
return_values=self._return_values, # Return process results
stdouts=self.stdouts,
stderrs=self.stderrs,
)
else:
return None
except (mp.ProcessRaisedException, mp.ProcessExitedException) as e:
failed_local_rank = e.error_index
# entrypoint for MultiprocessContext will always be a Callable
fn_name = self.entrypoint.__qualname__ # type: ignore[union-attr]
failed_proc = self._pc.processes[failed_local_rank]
error_filepath = self.error_files[failed_local_rank]
self.close()
return RunProcsResult( # Return process results
failures={
failed_local_rank: ProcessFailure(
local_rank=failed_local_rank,
pid=e.pid,
exitcode=failed_proc.exitcode,
error_file=error_filepath,
)
},
stdouts=self.stdouts,
stderrs=self.stderrs,
)
2.4 ProcessContext
As we can see from the above, the key variables of MultiprocessContext are:_ pc: Optional[mp.ProcessContext], this member variable is through start_processes, so we need to look at torch mp. ProcessContext.
2.4.1 start_processes
start_processes in torch / multiprocessing / spawn Py, return ProcessContext. Note that since then, the training process will run its own training code, as if there is no agent, because the agent has put torch distributed. Launch's work is done.
def start_processes(fn, args=(), nprocs=1, join=True, daemon=False, start_method='spawn'):
mp = multiprocessing.get_context(start_method)
error_queues = []
processes = []
for i in range(nprocs):
error_queue = mp.SimpleQueue()
process = mp.Process(
target=_wrap,
args=(fn, i, args, error_queue), # The training process starts running the training code
daemon=daemon,
)
process.start()
error_queues.append(error_queue)
processes.append(process)
context = ProcessContext(processes, error_queues)
if not join:
return context
# Loop on join until it returns True or raises an exception.
while not context.join():
pass
2.4.2 ProcessContext
torch.mp.ProcessContext is the class that ultimately works. Actually, torch mp. We don't care about the internal implementation of processcontext and how to start it, because through start_processes method, torch mp. Processcontext has actually been started. We can treat it as a functional black box. What we really care about is how to use torch mp. Processcontext to monitor.
From its comments, we can know that torch mp. Processcontext throws an exception when some / all worker processes fail. If it times out, the worker process status is checked and returned immediately. Because we use synchronize Event waits for all processes to complete, so the Join will never return success.
# torch.mp.ProcessContext Throws an Exception if some/all of # worker processes failed # timeout < 0 checks worker status and return immediately # Join will never return success since we use synchronize.Event to wait # for all processes to finish.
2.5 summary
The current relationship is as follows:
- During generation, the LocalElasticAgent generates a MultiprocessContext, which in turn generates a ProcessContext.
- LocalElasticAgent._pcontext saves the MultiprocessContext_ PC saved ProcessContext.
- During monitoring, localelasticagent_ monitor_ Workers called MultiprocessContext Wait, MultiprocessContext called processcontext again join,ProcessContext.join specifically monitors the running state of the process, which completes the overall logic of monitoring.
- After the child process changes or times out, processcontext Join returns the process result, multiprocesscontext Wait forwards the process results back_ monitor_workers converts the process results to workerstate Succeeded or workerstate FAILED.
See the figure for details:
+--------------------------------------------------------------------------------------+ +------------------------------------+ +----------------+ | LocalElasticAgent | | MultiprocessContext | | ProcessContext | | | | | | | | | | | | | | +----------------------------------------+ MultiprocessContext _pcontext | | ProcessContext _pc | | | | | _invoke_run | | | | | | | | | | | | | | | | _initialize_workers +--------------------> _pcontext = start_processes +--------------> start(): | | | | | | | | _pc = mp.start_processes +-----------> | | | | | | | | | | | while True: | +--------------------------------+ | | | | | | | _monitor_workers(_worker_group)+------> | _monitor_workers | | | | | | | | | | | | | | | | | | | | _pcontext.wait +---------------> wait +---> poll: | | | | | | | | | | _pc.join +---------------> | | +----------------------------------------+ +--------------------------------+ | | | | | | | | | | | +--------------------------------------------------------------------------------------+ +------------------------------------+ +----------------+
Mobile phones are as follows:

0x03 monitoring mechanism
From the front_ monitor_ As you can see in the workers code_ monitor_workers will convert the running results of child processes into the specific state of WorkerState. When the agent gets_ monitor_ After the monitoring results of workers, they will be processed according to the situation.
# Monitor client program operation
run_result = self._monitor_workers(self._worker_group)
state = run_result.state # Process operation
self._worker_group.state = state
if state == WorkerState.SUCCEEDED:
# The program ends normally
self._exit_barrier() # If one succeeds, it's all over
return run_result
elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}:
# Program error
if self._remaining_restarts > 0: # retry
self._remaining_restarts -= 1
self._restart_workers(self._worker_group) # Restart
else:
self._stop_workers(self._worker_group) # Retry times reached, end workers
self._worker_group.state = WorkerState.FAILED
self._exit_barrier()
return run_result
elif state == WorkerState.HEALTHY:
# The program runs normally
# Node membership changes, such as scale up
# membership changes do not count as retries
num_nodes_waiting = rdzv_handler.num_nodes_waiting()
group_rank = self._worker_group.group_rank
# If a new node is waiting, restart all workers
if num_nodes_waiting > 0:
self._restart_workers(self._worker_group)
else:
raise Exception(f"[{role}] Worker group in {state.name} state")
3.1 monitoring
This will call_ pcontext.wait(0) to get the status of the current worker sub processes, and then convert different WorkerState to return to the caller according to the returned results. As mentioned earlier, RunResult should be mapped to global rank, so_ monitor_workers have a mapping from local rank to gloabl rank.
Why use Global rank as an indicator of process status? Because communication is required between nodes, Global rank is required at this time.
@prof
def _monitor_workers(self, worker_group: WorkerGroup) -> RunResult:
role = worker_group.spec.role
worker_pids = {w.id for w in worker_group.workers} # Get the pid of all worker s of this agent
pc_pids = set(self._pcontext.pids().values())
if worker_pids != pc_pids:
return RunResult(state=WorkerState.UNKNOWN)
result = self._pcontext.wait(0) # Monitor the operating structure
if result:
if result.is_failed(): # If the process fails
# map local rank failure to global rank
worker_failures = {}
# The returned results include the running results of each process
for local_rank, failure in result.failures.items(): # local_rank is the process index
worker = worker_group.workers[local_rank] # Get the corresponding worker
worker_failures[worker.global_rank] = failure # Get its global_rank to set the worker status
return RunResult(
state=WorkerState.FAILED,
failures=worker_failures, # Return run results
)
else:
# copy ret_val_queue into a map with a global ranks
workers_ret_vals = {}
for local_rank, ret_val in result.return_values.items():
worker = worker_group.workers[local_rank] #
workers_ret_vals[worker.global_rank] = ret_val
return RunResult(
state=WorkerState.SUCCEEDED,
return_values=workers_ret_vals, # Return run results
)
else:
return RunResult(state=WorkerState.HEALTHY)
3.2 treatment
Depending on the return status, there will be different processing:
- If workerstate Succeeded, it indicates that the training is completed and returns to normal.
- If workerstate Health indicates that the training is running normally. At this time, we will check whether there are new nodes, which will be explained in detail later.
- If workerstate UNHEALTHY, WorkerState. Failed indicates that there is a problem in training. There are two situations.
- One is program error, TE will retry.
- One is node exit, which we will analyze below, but its processing flow is consistent with program error.
Next, let's analyze how to deal with the end of training and program errors.
0x04 end of training
if state == WorkerState.SUCCEEDED:
# The program ends normally
self._exit_barrier() # If one succeeds, it's all over
return run_result
The above is the treatment at the normal end of training, which is special_ exit_ Use of barrier.
4.1 unified completion
Torchelastic currently supports DDP style applications. In other words, TE wants all workers to complete at about the same time. In fact, it is almost impossible to ensure that all workers in DDP can finish at the same time. Therefore, TE provides a finalization barrier, which is used to implement the waiting timeout (5 minutes) for worker finalization. That is, if one worker training is completed, TE (torch last) wants all workers of the user to finish with an error of 5 minutes.
def _exit_barrier(self):
"""
Wait for ``exit_barrier_timeout`` seconds for all agents to finish
executing their local workers (either successfully or not). This
acts as a safety guard against user scripts that terminate at different
times. This barrier keeps the agent process alive until all workers finish.
"""
start = time.time()
try:
store_util.barrier(
self._store,
self._worker_group.group_rank,
self._worker_group.group_world_size,
key_prefix=_TERMINAL_STATE_SYNC_ID,
barrier_timeout=self._exit_barrier_timeout,
)
except Exception:
log.exception(
f"Error waiting on exit barrier. Elapsed: {time.time() - start} seconds"
)
exit_ barrier_ The default value of timeout is 300 seconds, or 5 minutes.
exit_barrier_timeout: float = 300,
4.2 synchronization
In torch / distributed / elastic / utils / store Py, the barrier will call synchronize to synchronize.
def barrier(
store, rank: int, world_size: int, key_prefix: str, barrier_timeout: float = 300
) -> None:
"""
A global lock between agents.
Note: Since the data is not removed from the store, the barrier can be used
once per unique ``key_prefix``.
"""
data = f"{rank}".encode(encoding="UTF-8")
synchronize(store, data, rank, world_size, key_prefix, barrier_timeout)
synchronize is synchronized through the store.
def get_all(store, prefix: str, size: int):
r"""
Given a store and a prefix, the method goes through the array of keys
of the following format: ``{prefix}{idx}``, where idx is in a range
from 0 to size, and tries to retrieve the data.
Usage
::
values = get_all(store, 'torchelastic/data', 3)
value1 = values[0] # retrieves the data for key torchelastic/data0
value2 = values[1] # retrieves the data for key torchelastic/data1
value3 = values[2] # retrieves the data for key torchelastic/data2
"""
data_arr = []
for idx in range(size):
data = store.get(f"{prefix}{idx}")
data_arr.append(data)
return data_arr
def synchronize(
store,
data: bytes,
rank: int,
world_size: int,
key_prefix: str,
barrier_timeout: float = 300,
) -> List[bytes]:
"""
Synchronizes ``world_size`` agents between each other using the underlying c10d store.
The ``data`` will be available on each of the agents.
Note: The data on the path is not deleted, as a result there can be stale data if
you use the same key_prefix twice.
"""
store.set_timeout(timedelta(seconds=barrier_timeout))
store.set(f"{key_prefix}{rank}", data)
agent_data = get_all(store, key_prefix, world_size)
return agent_data
0x05 error handling
5.1 error type
Each host in the distributed PyTorch job runs a TorchElastic agent and multiple workers (as subprocesses of the TorchElastic agent). Since workers are provided by users (PyTorch script/job), TorchElastic can propagate errors to the trainer through the agent until the scheduler (scheduler), and finally notify the end user of the status of these jobs and apply some retry strategies.
TE classifies errors into the following categories.
+----------------+----------------+--------------------------------------------------------------+ | Category | Sub-Category | Description | +================+================+==============================================================+ | User Error | Input Error | invalid inputs to TorchElastic APIs (e.g. min > max nodes) | | +----------------+--------------------------------------------------------------+ | | Worker Failure | any failures on the worker child process | +----------------+----------------+--------------------------------------------------------------+ | Platform Error | n/a | failures caused by the agent | +----------------+----------------+--------------------------------------------------------------+ | Infra Error | n/a | failures outside the domain of the agent and workers | | | | (e.g. host failures) | +----------------+----------------+--------------------------------------------------------------+
5.1 error handling mode
The corresponding error handling modes are as follows. According to the fault level from small to large:
- User Error: it is divided into the following processing methods:
- User Error: such as error input, which can be directly captured by the program.
- Worker Failure:
- Worker Failures is special because the exception / failure originates from a process different from the agent, so the error needs to be propagated between processes (for example, the agent cannot simply try catch the exception thrown on a worker process).
- The TorchElastic agent uses torch distributed. elastic. multiprocessing. start_ Processes starts the worker with a simple file based interprocess error propagation built in.
- Any function or binary entry point decorated with record will write an uncapped exception (with trace information) to the file specified by the environment variable TORCHELASTIC_ERROR_FILE. The parent process (such as agent) sets this environment variable on each child process it starts, then aggregates the error files of all child processes and propagates the error file with the minimum timestamp (for example, the first error).
- The document discusses as follows: for a training job with "n" workers, if the worker with "K < = n" name fails, all workers will stop and restart until the number of "max_restarts" is reached. The meaning of the above sentence is: if a worker fails and the maximum number of restarts has not been reached, TE will start a new rendezvous and restart all workers. Because it is a new rendezvous, other TE agents will also restart their workers.
- The failure of one worker will lead to the failure of the whole cluster: if a single worker fails continuously, it will lead to the max of TE agent_ The restarts variable becomes zero. This will cause the agent to complete its work and close rendezvous. If there are any other workers on different agents, they will also be terminated.
- Worker Failures is special because the exception / failure originates from a process different from the agent, so the error needs to be propagated between processes (for example, the agent cannot simply try catch the exception thrown on a worker process).
- Platform Error:
- All errors other than Worker Failure will be raised normally from the agent process, which will crash the agent process implicitly or explicitly. Therefore, the exception handling strategy provided by standard language (python) can be applied.
- Agent failure can also cause the local workgroup to fail. How it is handled depends on the job manager, such as failing the entire job (gang semantics) or trying to replace nodes. Both behaviors are supported by agents.
- Infra Error (node failure): it is handled in the same way as agent failure.
Let's take a look at how to deal with "Worker Failure".
5.2 handling mechanism
The specific error handling mechanism is as follows. If the maximum number of retries has not been reached, try to restart workers. If the maximum number of times has been reached, stop workers.
elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}:
# Program error
if self._remaining_restarts > 0: # retry
self._remaining_restarts -= 1
self._restart_workers(self._worker_group) # Restart
else:
self._stop_workers(self._worker_group) # Retry times reached, end workers
self._worker_group.state = WorkerState.FAILED
self._exit_barrier()
return run_result
5.2. 1 restart
_ restart_workers will stop all workers, and then a new round of rendezvous.
@prof
def _restart_workers(self, worker_group: WorkerGroup) -> None:
"""
Restarts (stops, rendezvous, starts) all local workers in the group.
"""
role = worker_group.spec.role
self._stop_workers(worker_group)
worker_group.state = WorkerState.STOPPED
self._initialize_workers(worker_group)
5.2. 2 stop
To stop workers is to close the context.
def _shutdown(self) -> None:
if self._pcontext:
self._pcontext.close()
@prof
def _stop_workers(self, worker_group: WorkerGroup) -> None:
self._shutdown()
In MultiprocessContext, the close method is to close all child processes and wait for them to stop.
def _close(self) -> None:
if self._pc:
for proc in self._pc.processes:
proc.terminate()
proc.join()
5.4 restart of other agents
It can be seen from the source code comments that the new round of rendezvous will enable other agent s to restart their worker s.
When worker fails, TE will check the number of restarts available, if there is more than 0 restarts, TE will start a new rendezvous round and restart the worker process. New rendezvous round will other TE agents to terminate their workers.
How did this happen? The details are as follows:
- **Agent 0 (failed agent) * * a failure was found through monitoring.
- Agent 0 call_ restart_workers restart worker.
- Agent 0 will call next_rendezvous launched a new round of rendezvous.
- Agent 0 will call sync to obtain cluster information from kvstore before any operation, such as keep alive, so as to ensure that the agent gets the latest status of the cluster.
- Agent 0 will add itself to the local waiting_list.
- Agent 0 also calls mark_dirty means that my status has been updated and needs to be written to KVStore.
- Agent 0 will call sync to send its own waiting_list is written to KVStore.
- **Agent 1 (other agents working normally) * * before any operation, such as keep alive, it will call sync to obtain the latest information from KVStore.
- Agent 1 uses this information to update its status so that it can wait locally_ The list will be updated.
- After monitoring every 30 seconds, the train loop of Agent 1 is in a Healthy state because the system is normal.
- Agent 1 calls num_nodes_waiting() look at waiting_list number.
- Agent 1 will get the number of local waiting list s.
- If the waiting list is not empty, call_ restart_workers.
- It will eventually call next_rendezvous.
The details are as follows:
Agent 0 Agent 1 +---------------------------+ +--------------------------------------------+ | _invoke_run | | _invoke_run | | + | | + | | | | | | | | | 1 | | | | | v | | | | | Worker Process Error | | | | | + | | | | | | | | | 10 | | | 2 | | v | | v | | HEALTHY | | _restart_workers | | + | | + | | | 11 | | | | | | | | | 3 | | v | | v | | +--> num_nodes_waiting() > 0 | | next_rendezvous | | | + | | + | | | | | | | 4 | | | 12 | 13 | | | + +----------+ | | v | | v cluster info | | | | _restart_workers | | sync <------------+-> | KV Store | | | + | | + | | | | | | | | | 5 | | | | | | 14 | | v | | | | | v | | Add to local waiting_list| | | | | next_rendezvous | | + | | | | | | | | | | | | | | | | 6 | | | | v | | v | | | | | | mark_dirty | | | | Add to local waiting_list | | + | | | | ^ | | | | | | | | | | | 7 | | | | 9 | waiting_list | | v 7 | | | | 8 + | | sync +---------------> | +--------------> sync | | waiting_list | | | |waiting_list | | | +----------+ | | +---------------------------+ +--------------------------------------------+
So far, we have completed the preliminary introduction to the monitoring mechanism. Due to space constraints, we will continue to introduce how to deal with Scale up/down in the next article.
0xEE personal information
★★★★★★★ thinking about life and technology ★★★★★★
Wechat public account: Rossi's thinking
If you want to get the news push of personal articles in time, or want to see the technical materials recommended by yourself, please pay attention.
