catalogue
Like to watch and form a habit
In the game, the chat function is almost a necessary function. There are some problems with this function, that is, it will cause the world channel to be very chaotic. There are often some sensitive words, or chat that some game manufacturers do not want to see. We also had such problems in the game before. Our company has done reporting and background monitoring, and today we will realize this kind of monitoring.
1. Demand analysis:
Because deep learning is not used very well, although reinforcement learning has been written before, but the results of reinforcement learning are not particularly satisfactory, so study a simpler method to realize it.
In fact, there are ready-made solutions for this classification task. For example, the classification of spam is the same problem. Although there are different solutions, I chose the simplest naive Bayesian classification. Mainly do some exploration,
Because most of our games are in Chinese, we need to segment Chinese words. For example, I'm a handsome man and need to split them.
2. Algorithm principle:
Naive Bayesian algorithm is an algorithm that judges the category of the new sample according to the conditional probability of the existing characteristics of the new sample in the data set; It assumes that ① each feature is independent of each other and ② each feature is equally important. It can also be understood as judging the probability when the current features are satisfied at the same time according to the past probability. Specific mathematical companies can baidu themselves. The data formula is too difficult to write. It's good to know.
Use the right algorithm at the right time.
jieba word segmentation principle: jieba word segmentation belongs to probabilistic language model word segmentation. The task of probabilistic language model word segmentation is to find a segmentation scheme S among all the results of total segmentation, so as to maximize P(S).

You can see that jieba comes with some phrases, which will be split as the basic unit during segmentation.
Note: I'm just a brief introduction to the principles of the above two technologies. If you want to fully understand, you have to write a big article, which can be found everywhere under Baidu. Just find one that can be understood. If you can use it, use it first.
3. Technical analysis
Chinese word segmentation package the most famous word segmentation package is jieba. I don't know if it's the best. I think fire has the truth of fire. Do it first. The principle of jieba does not need to be studied deeply. It gives priority to solving problems. If you encounter problems, you can learn from the problem points. This learning mode is the most efficient.
Because I've been doing voice related things recently, a big man recommended the library nltk and consulted the relevant materials. It seems that it's a well-known Library in the direction of language processing. It's very powerful and powerful. I mainly chose his classification algorithm here, so I don't need to pay attention to the specific implementation or build wheels repeatedly. Besides, it's not as good as others. It's good to use it.
python is really good, all kinds of bags, all kinds of wheels.
Installation command:
pip install jieba pip install nltk
Enter the above two codes respectively. After running, the package will be installed successfully and can be tested happily
"""
#Author: coriander
@time: 2021/8/5 0005 10 pm:26
"""
import jieba
if __name__ == '__main__':
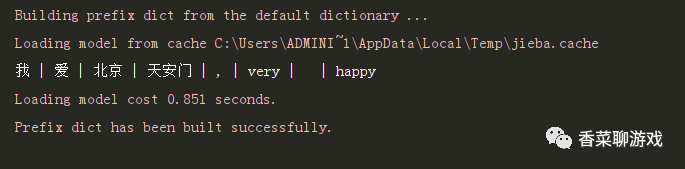
result = " | ".join(jieba.cut("I Love Beijing Tiananmen ,very happy"))
print(result)Look at the word segmentation results. It can be said that it is very good. As expected, specialty is specialty.
4. Source code
After a simple test, we can find that we basically have everything we need to complete. Now we start to work on the code directly.
1. Load the initial text resource.
2. Remove punctuation from text
3. Feature extraction of text
4. Training data set, training model (i.e. prediction model)
5. Start testing the newly entered words
#!/usr/bin/env python
# encoding: utf-8
import re
import jieba
from nltk.classify import NaiveBayesClassifier
"""
#Author: coriander
@time: 2021/8/5 0005 9 p.m:29
"""
rule = re.compile(r"[^a-zA-Z0-9\u4e00-\u9fa5]")
def delComa(text):
text = rule.sub('', text)
return text
def loadData(fileName):
text1 = open(fileName, "r", encoding='utf-8').read()
text1 = delComa(text1)
list1 = jieba.cut(text1)
return " ".join(list1)
# feature extraction
def word_feats(words):
return dict([(word, True) for word in words])
if __name__ == '__main__':
adResult = loadData(r"ad.txt")
yellowResult = loadData(r"yellow.txt")
ad_features = [(word_feats(lb), 'ad') for lb in adResult]
yellow_features = [(word_feats(df), 'ye') for df in yellowResult]
train_set = ad_features + yellow_features
# Training decision
classifier = NaiveBayesClassifier.train(train_set)
# Analysis test
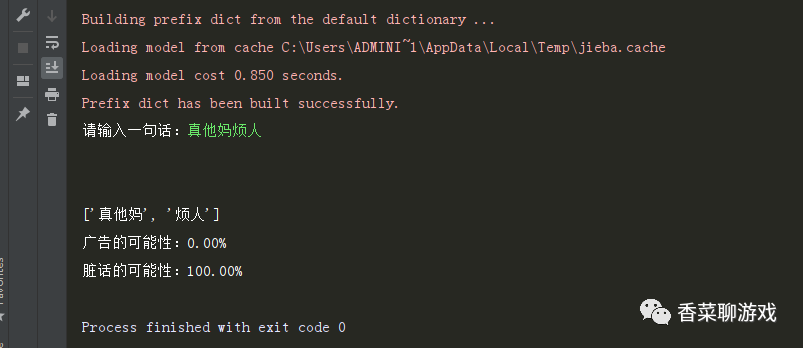
sentence = input("Please enter a sentence:")
sentence = delComa(sentence)
print("\n")
seg_list = jieba.cut(sentence)
result1 = " ".join(seg_list)
words = result1.split(" ")
print(words)
# Statistical results
ad = 0
yellow = 0
for word in words:
classResult = classifier.classify(word_feats(word))
if classResult == 'ad':
ad = ad + 1
if classResult == 'ye':
yellow = yellow + 1
# Presentation ratio
x = float(str(float(ad) / len(words)))
y = float(str(float(yellow) / len(words)))
print('Advertising possibilities:%.2f%%' % (x * 100))
print('Possibility of swearing:%.2f%%' % (y * 100))Look at the results of the operation
Download address of all resources: https://download.csdn.net/download/perfect2011/20914548
5. Expand
1. The data source can be modified, and the monitored data can be stored in the database for loading
2. More data can be classified to facilitate customer service processing, such as advertising, dirty words, official suggestions, etc., which are defined according to business needs
3. The data with high probability can be connected to other systems for automatic processing, so as to improve the processing speed of processing problems
4. You can use the player's report to increase the accumulation of data
5. This idea can be used as the processing of sensitive words, provide a sensitive word dictionary, and then match and detect
6. It can be made into a web service for callback game
7. The model can be made to predict while learning. For example, some cases need to be manually processed by customer service. After marking, they can be directly added to the data set, so that the data model can always learn s
6. Problems encountered
1. Problems encountered, punctuation problems. If punctuation is not removed, it will lead to matching. Punctuation is also counted as matching, which is unreasonable.
2. The coding problem was binary, and it took a long time to solve it
3. At the beginning, I wanted to use deep learning to solve the problem of technology selection. I also saw some solutions. However, my computer training is too slow. I choose this way to practice first
4. The code is very simple, but it is difficult to explain the technology. The code has been written long ago, but this article was written after a weekend
7. Summary:
If you encounter problems, find technical solutions. If you know the solutions, implement them. If you encounter bug s, check them. If you never forget, there will be repercussions. Any attempt you make is a good opportunity to learn.
It's not easy to be original. Please forward it with a little praise and support.