1, Write in front
Graduation is coming soon, brothers. The graduation thesis is a troublesome thing. You have to check the information on the Internet one by one. That's a waste of time. Let's write a crawler directly, download it in batches and read it slowly. Isn't it uncomfortable?

2, Preparatory work
Using software
Python and pycharm are OK. Any version is OK, as long as you don't use python2.
modular
requests #Simulation request Selenium # Browser automation
win+r open the search box, enter cmd, press OK to open the command prompt window, enter pip install plus the name of the module you want to install, and press enter to install. If the download speed is slow, change the domestic image source.
Then download a Google browser driver, the version closest to your browser.
No, look at my top article.
3, Start crawling
Page analysis
First, analyze the elements of the known web page. We usually enter the content you want to search in the input box of the home page, and then jump to the search page.

Through the check page of the browser, we get the XPATH of the input box and the search icon respectively:
input_xpath = '/html[1]/body[1]/div[1]/div[2]/div[1]/div[1]/input[1]' button_xpath = '/html[1]/body[1]/div[1]/div[2]/div[1]/div[1]/input[2]'
Enter the content to search in the input box and operate the search button to go to the results page.
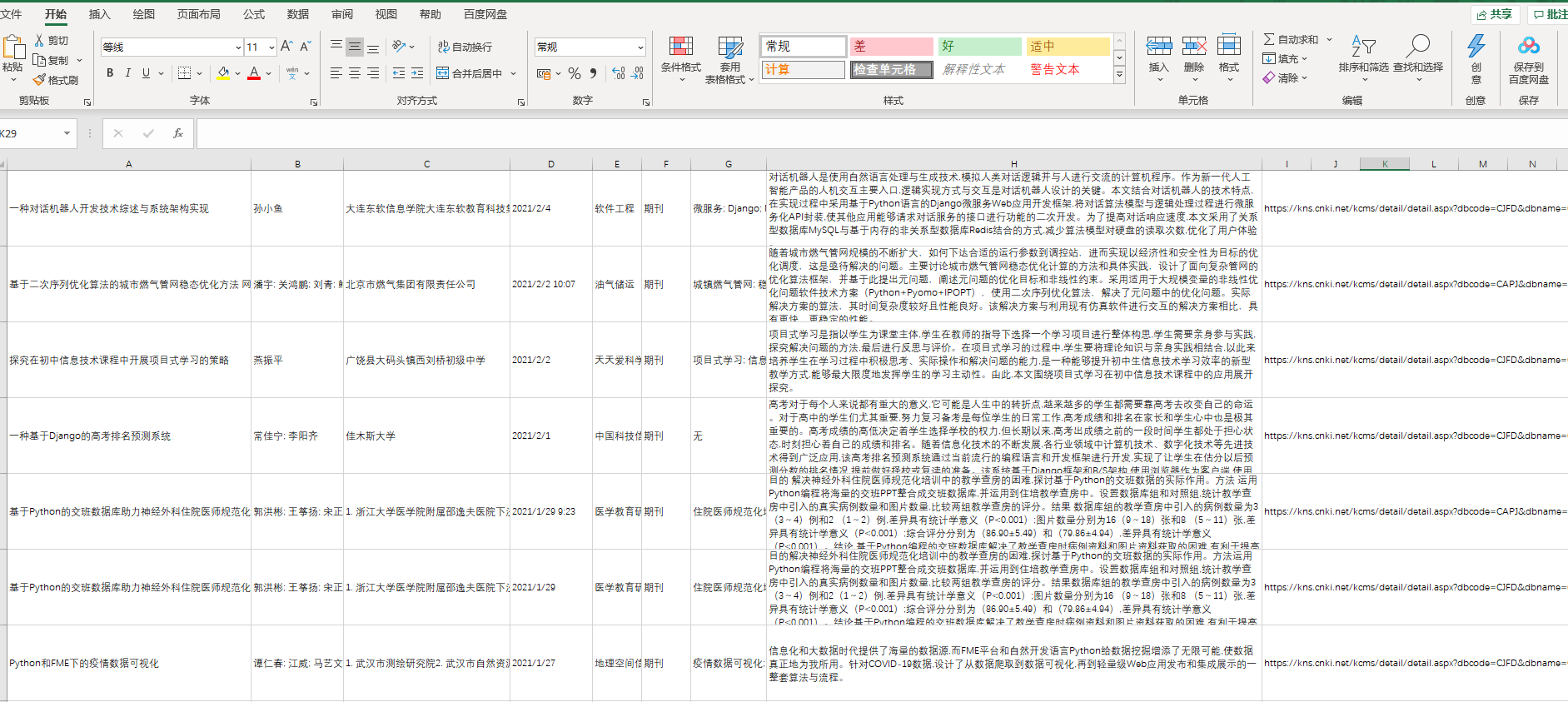
Taking Python as an example, 15925 entries and 300 pages were found. Each page contains 20 entries, and each entry contains title, author, source, etc.

By analyzing the current page, we can find the rule of xpath corresponding to each entry
/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[1]/td[2]
The penultimate tag number represents the items on this page, and the last tag 2 - 6 represents the title, author, source, publication time and database respectively. You can't download the summary information or literature on the current page. You need to further Click to enter the relevant literature items.
After entering the details page, you can easily locate the summary text according to class name: abstract text, and class name: BTN dlcaj locate the download link. Other elements are the same.

 After completing the surface analysis, you can start writing code!
After completing the surface analysis, you can start writing code!
Import the library to use
import time from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from urllib.parse import urljoin
Create browser objects and set relevant parameters
get returns directly without waiting for the interface to load
desired_capabilities = DesiredCapabilities.CHROME desired_capabilities["pageLoadStrategy"] = "none"
Setting up Google drive environment
options = webdriver.ChromeOptions()
Set chrome not to load pictures to improve the speed.
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
Set not to display windows
options.add_argument('--headless')
Create a Google drive
driver = webdriver.Chrome(options=options)
Set search subject
theme = "Python"
Set the required number of articles
papers_need = 100
Open the page to search for keywords
Open page
driver.get("https://www.****.net")
I blocked the website. Please change to the largest website for literature review.
Incoming keyword
WebDriverWait( driver, 100 ).until( EC.presence_of_element_located( (By.XPATH ,'''//*[@id="txt_SearchText"]''') ) ).send_keys(theme)
Click search
WebDriverWait( driver, 100 ).until( EC.presence_of_element_located( (By.XPATH ,"/html/body/div[1]/div[2]/div/div[1]/input[2]") ) ).click() time.sleep(3)
Click to switch to Chinese Literature
WebDriverWait( driver, 100 ).until( EC.presence_of_element_located( (By.XPATH ,"/html/body/div[5]/div[1]/div/div/div/a[1]") ) ).click() time.sleep(1)
Get the total number of documents and pages
res_unm = WebDriverWait( driver, 100 ).until( EC.presence_of_element_located( (By.XPATH ,"/html/body/div[5]/div[2]/div[2]/div[2]/form/div/div[1]/div[1]/span[1]/em") ) ).text
Remove commas from the thousandths
res_unm = int(res_unm.replace(",",'')) page_unm = int(res_unm/20) + 1 print(f"Total found {res_unm} Article results, {page_unm} Page.")
Parse result page
Assign sequence number to control the number of articles crawled.
count = 1
When the number of crawls is less than the demand, the page number of the web page is cycled.
while count <= papers_need:
Wait until the load is complete and sleep for 3S.
Add time where appropriate Sleep (3) delays for a few seconds, which can not only wait for the page to load, but also prevent the IP from being blocked too fast.
time.sleep(3) title_list = WebDriverWait( driver, 10 ).until( EC.presence_of_all_elements_located( (By.CLASS_NAME ,"fz14") ) )
Looping through entries on a page
for i in range(len(title_list)): try: term = count%20 # What are the entries on this page title_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[2]" author_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[3]" source_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[4]" date_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[5]" database_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[6]" title = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,title_xpath) ) ).text authors = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,author_xpath) ) ).text source = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,source_xpath) ) ).text date = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,date_xpath) ) ).text database = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,database_xpath) ) ).text
Click entry
title_list[i].click()
Gets the handle to the driver
n = driver.window_handles
driver switches to the latest production page
driver.switch_to_window(n[-1])
Start getting page information
# title = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,"/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h1") ) ).text # authors = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,"/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h3[1]") ) ).text institute = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,"/html[1]/body[1]/div[2]/div[1]/div[3]/div[1]/div[1]/div[3]/div[1]/h3[2]") ) ).text abstract = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.CLASS_NAME ,"abstract-text") ) ).text try: keywords = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.CLASS_NAME ,"keywords") ) ).text[:-1] except: keywords = 'nothing' url = driver.current_url
Get download link
link = WebDriverWait( driver, 10 ).until( EC.presence_of_all_elements_located((By.CLASS_NAME ,"btn-dlcaj") ) )[0].get_attribute('href') link = urljoin(driver.current_url, link)
write file
res = f"{count}\t{title}\t{authors}\t{institute}\t{date}\t{source}\t{database}\t{keywords}\t{abstract}\t{url}".replace("\n","")+"\n" print(res) with open('CNKI_res.tsv', 'a', encoding='gbk') as f: f.write(res)
Skip this item and move on to the next one. If there are multiple windows, close the second window and switch back to the home page.
except: print(f" The first{count} Strip crawling failed\n") continue finally: n2 = driver.window_handles if len(n2) > 1: driver.close() driver.switch_to_window(n2[0])
Count to determine whether the demand is sufficient.
count += 1 if count == papers_need:break
Switch to the next page
WebDriverWait( driver, 10 ).until( EC.presence_of_element_located( (By.XPATH ,"//a[@id='PageNext']") ) ).click()
Close browser
driver.close()
# All functions have been realized here. I have prepared these materials for you. You can get them free directly in the group. # Group: 872937351 (add two groups if the group is full) # Group II: 924040232 # python Learning route summary # Boutique Python 100 learning books # Python Getting started video collection # Python Actual combat cases # Python Interview questions # Python Related software tools/pycharm Permanent activation
4, Effect display
Brothers, remember to follow the three companies. Your help is the driving force for me to update~