From Mr. Liu Er of station B PyTorch deep learning practice P11 My study notes
GoogLeNet
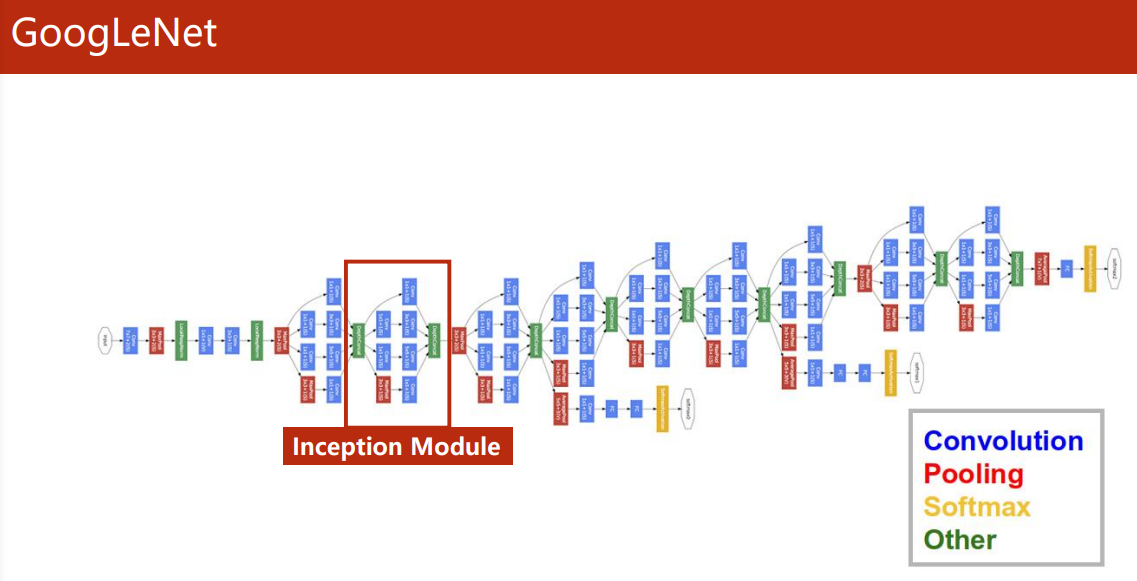
-
one × 1 convolution
Last We know that the number of convolutions depends on the number of channels of the input image.

one × Convolution can fuse features, change the number of channels and reduce the amount of computation. It is called neural network in neural networkFor example, let's go through 1 × 1 convolution reduces the number of channels and allows a large convolution kernel to calculate fewer channels, which can greatly reduce the amount of calculation:
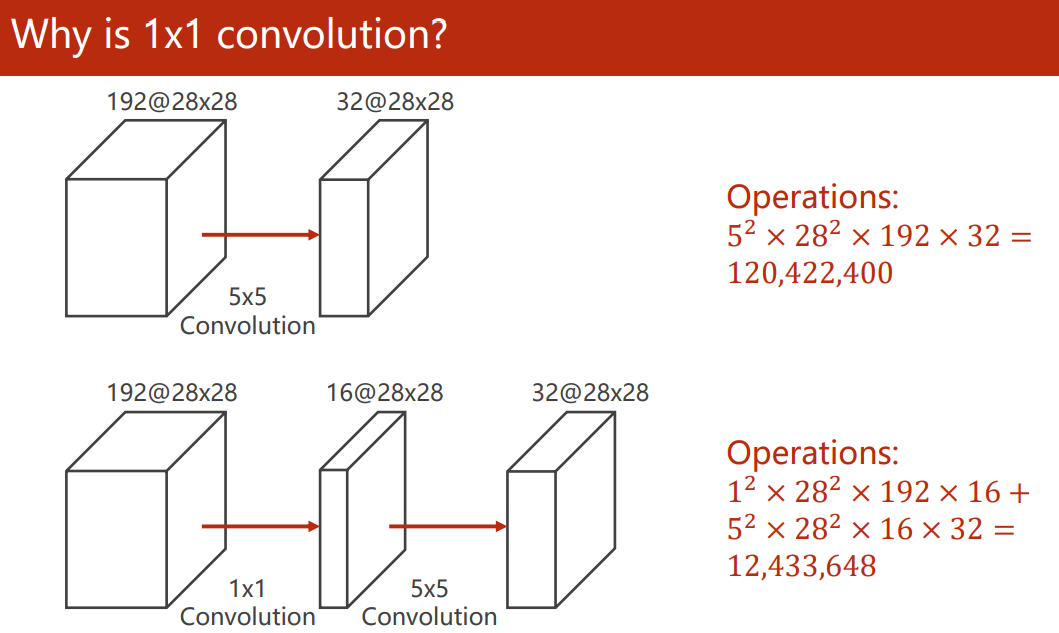
-
Inception Module
The purpose of Inception Module is to provide multiple convolution layer configurations for neural networks and select the optimal route and other auxiliary routes through training in the future.
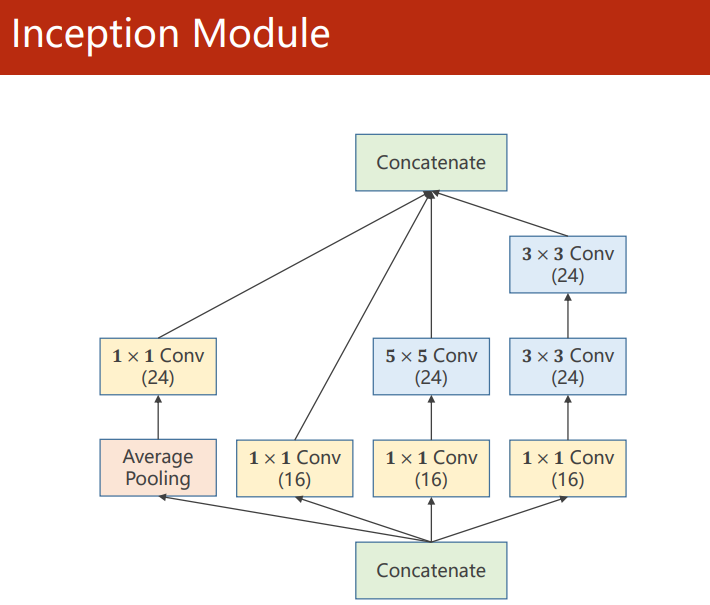
Since the final results of each route need to be stacked, it is necessary to ensure that the output feature map size is consistent. For the Average Pooling layer, it is necessary to ensure the final output size through padding and stripe.
realization
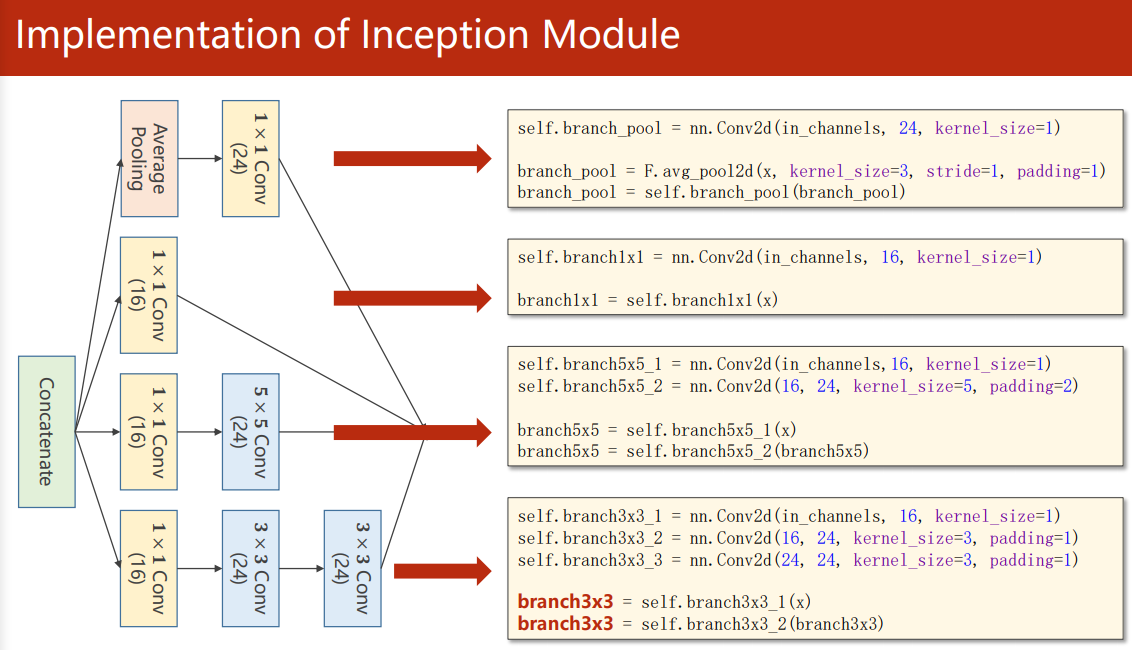
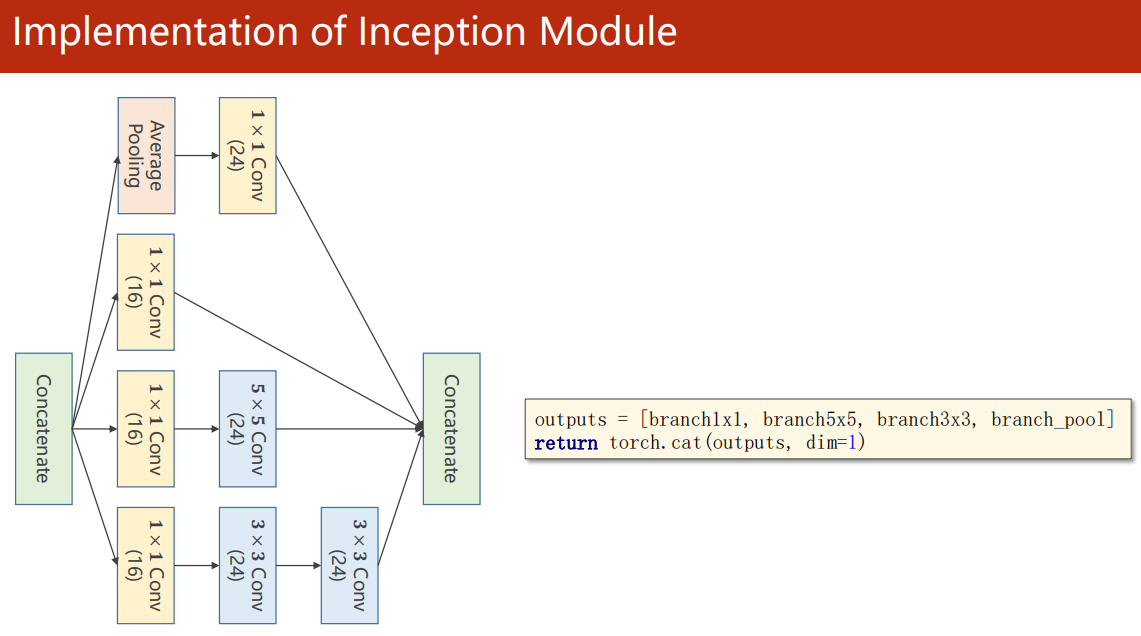
Splice the output together before entering the next layer
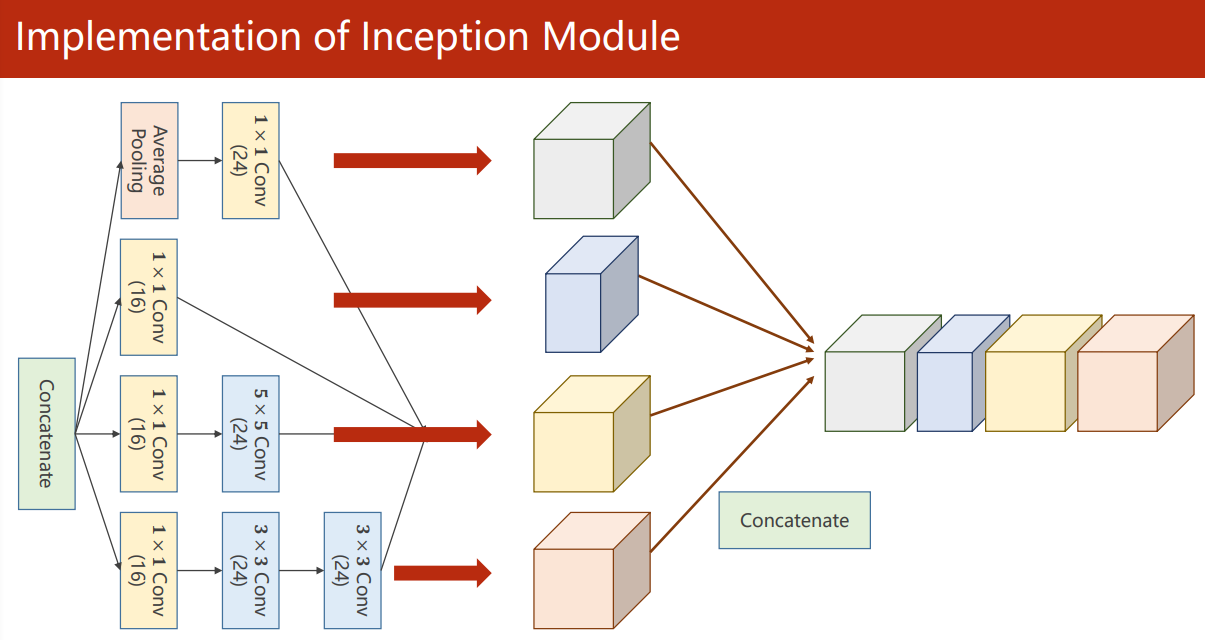
torch. In cat (outputs, dim=1), dim=1 refers to splicing in channel dimensions (N, C, W, H)
Two inception modules are used:
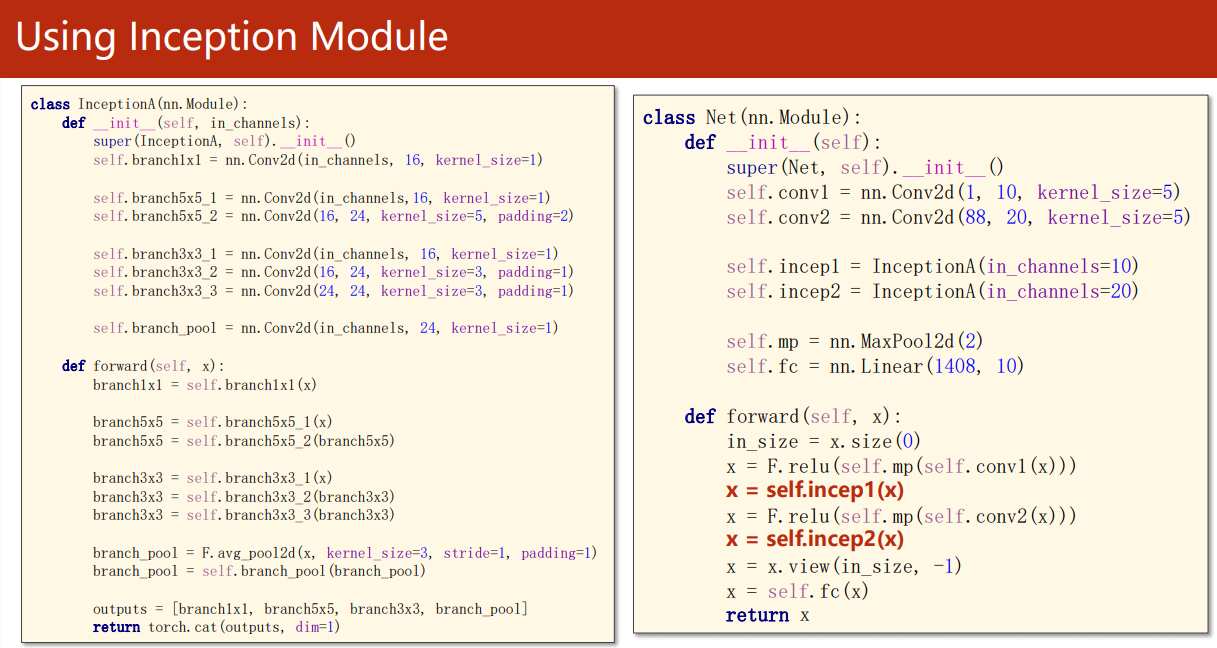
We just need to Last Replace the neural network part of the code with GoogleNet, which can be used to identify MNIST data sets:
import torch
from torch import nn
from torch.nn import functional as F
class Inception(nn.Module):
"""
Because the feature map needs to be spliced, it needs to be set by padding,stride To ensure that the size of the characteristic image remains unchanged after convolution;
Because in Inception There is a convolution layer before the block, so the number of input channels is not the same. You need to take the number of input channels as a parameter.
:return:
The number of output channels is 16+24×3=88,So return N,88,*,* Characteristic diagram of
"""
def __init__(self, in_channels):
super(Inception, self).__init__()
self.pool_conv1x1 = nn.Conv2d(in_channels, 24, kernel_size=1) # Pool + one 1 × 1 convolution, output 24 channels
self.conv1x1 = nn.Conv2d(in_channels, 16, kernel_size=1) # Three identical ones × 1 convolution, output 16 channels
self.conv3x3_16 = nn.Conv2d(16, 24, kernel_size=3, padding=1) # The input is 3 of 16 channels × 3 convolution, output 24 channels
self.conv3x3_24 = nn.Conv2d(24, 24, kernel_size=3, padding=1) # The input is 3 of 24 channels × 3 convolution, output 24 channels
self.conv5x5 = nn.Conv2d(16, 24, kernel_size=5, padding=2) # One 5 × 5 convolution, output 24 channels
def forward(self, x):
out1 = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1) # N,*,,
out1 = self.pool_conv1x1(out1) # N,24,,
out2 = self.conv1x1(x) # N,16,,
out3 = self.conv1x1(x) # N,16,,
out3 = self.conv5x5(out3) # N,24,,
out4 = self.conv1x1(x) # N,16,,
out4 = self.conv3x3_16(out4) # N,24,,
out4 = self.conv3x3_24(out4) # N,24,,
outputs = (out1, out2, out3, out4)
return torch.cat(outputs, dim=1) # N,88,,
class GoogleNet(nn.Module):
def __init__(self):
super(GoogleNet, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5) # return N,10,,
self.incep1 = Inception(in_channels=10) # return N,88,,
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep2 = Inception(in_channels=20) # return N,88,,
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.mp(self.conv1(x))) # N,10,12,12
x = self.incep1(x) # N,88,12,12
x = F.relu(self.mp(self.conv2(x))) # N,20,4,4
x = self.incep2(x) # N,88,4,4
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = GoogleNet()
Go Deeper
GoogleNet wants to use the concept module to achieve deeper network to improve performance, but is it really the deeper the better?

ResNet
-
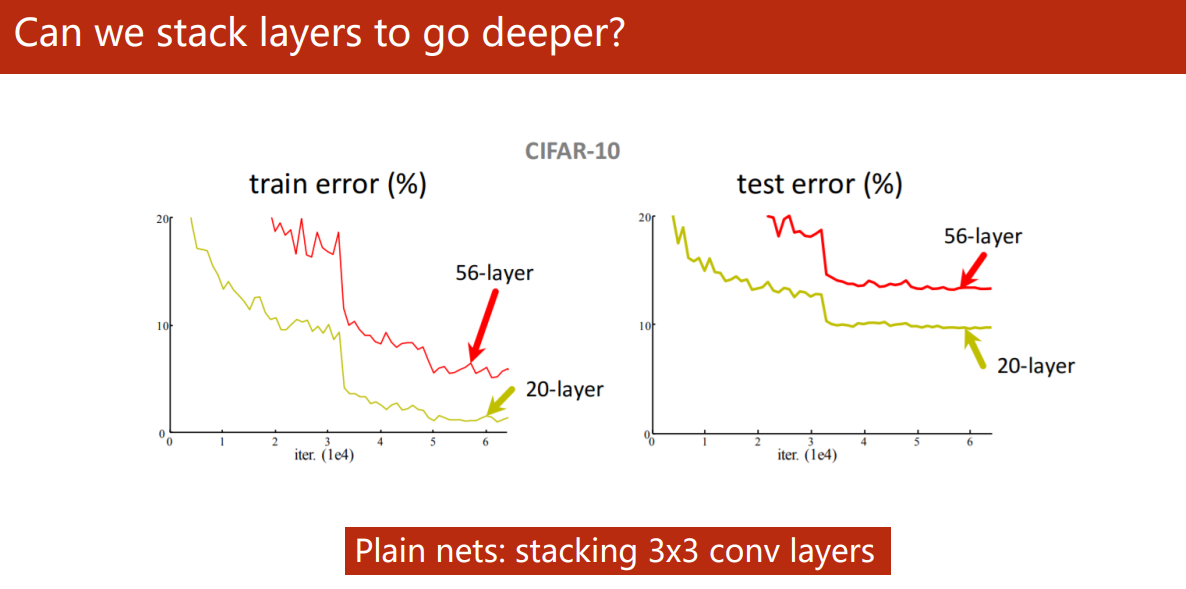
Can we stack layers to go deeper?
Five years ago, he Kaiming's paper Deep Residual Learning for Image Recognition 1 It reveals that the neural network is not blindly stacked, the deeper the better.
As shown in the figure, the error rate of training and testing of the 56 layer deep network is higher than that of the 20 layer network. One of the main reasons is that the deeper the network, the more likely the gradient disappears, making it difficult for some network layers to be updated in training.
-
Residual Block
Even so, we still don't deny that the deeper it is, the better it is. We still want to Go Deeper.
Therefore, he Kaiming proposed the residual link module, which makes it easier to retain the gradient of the previous layer by means of shortcut (BatchNorm layer is missing in the figure).
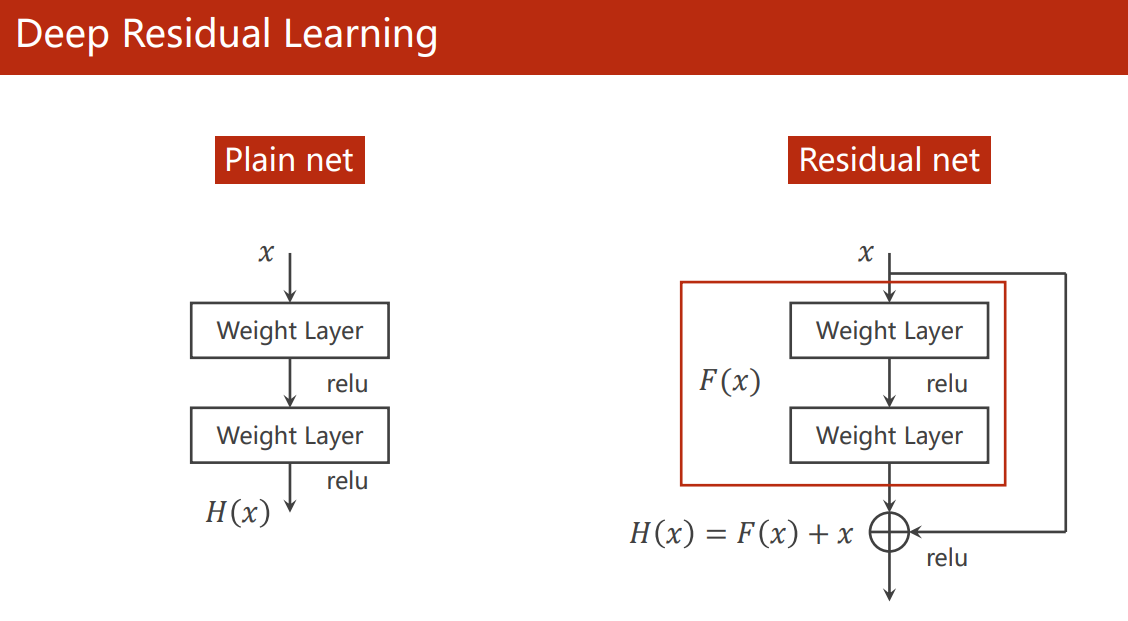
Since the convoluted feature map should be added to the output of the previous layer, the size of the output feature map of the entire ResNet convolution layer should be the same, or the convolution output in each Residual Block should be the same.
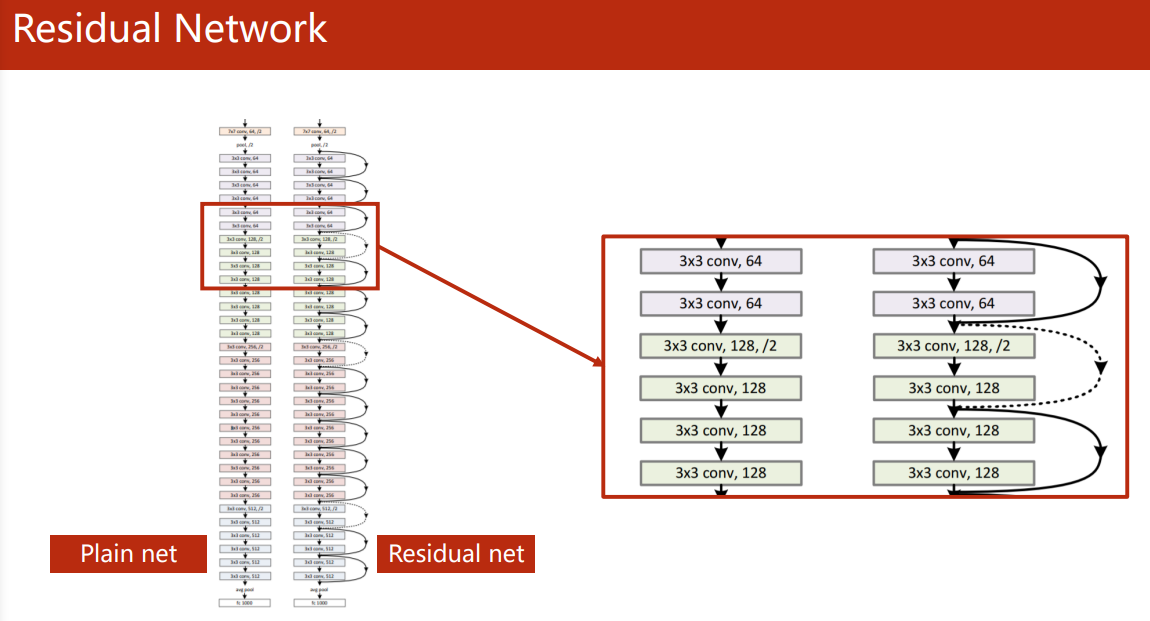
Implementation of Residual Block:

paper 2 There is a more detailed flow chart of Residual Block: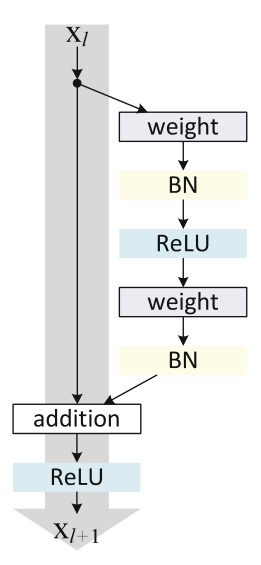
Implementation of ResNet:

from torch import nn
from torch.nn import functional as F
from train_and_test import train, test, draw
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.bn = nn.BatchNorm2d(channels)
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) # The size of the feature map has not changed
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.bn(self.conv1(x)))
y = self.bn(self.conv1(y))
return F.relu(x + y) # It is not splicing, so the number of channels returned is still channel
class ResNet(nn.Module):
def __init__(self):
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.rblock1 = ResidualBlock(channels=16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.rblock2 = ResidualBlock(channels=32)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(512, 10)
def forward(self, x):
batch_size = x.size(0)
x = self.mp(F.relu(self.conv1(x))) # N,16,12,12
x = self.rblock1(x) # N,16,12,12
x = self.mp(F.relu(self.conv2(x))) # N,32,4,4
x = self.rblock2(x) # N,32,4,4
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = ResNet()
Read the paper and reproduce ResNet v2
Reproduce he Kaiming's ResNet v2: Identity Mappings in Deep Residual Networks 2
In fact, this paper mainly discusses various possible magic modification methods of ResNet's Residual Block:
- Add other operations to the shortcut (gray arrow line, shortcut link) or make multiple branches like the concept module:
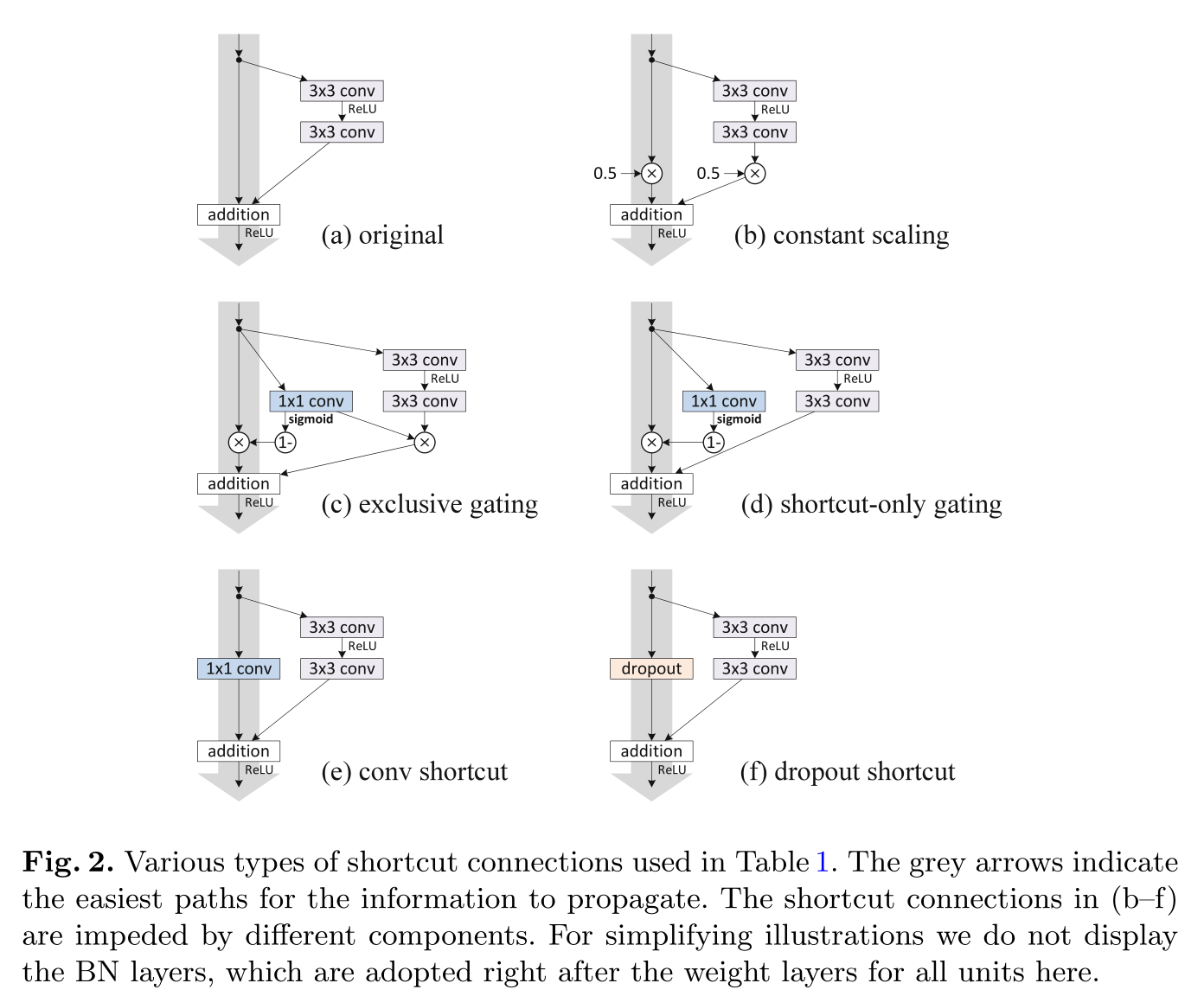
- Different order of normalization layer (BatchNorm) and activation layer (ReLU):
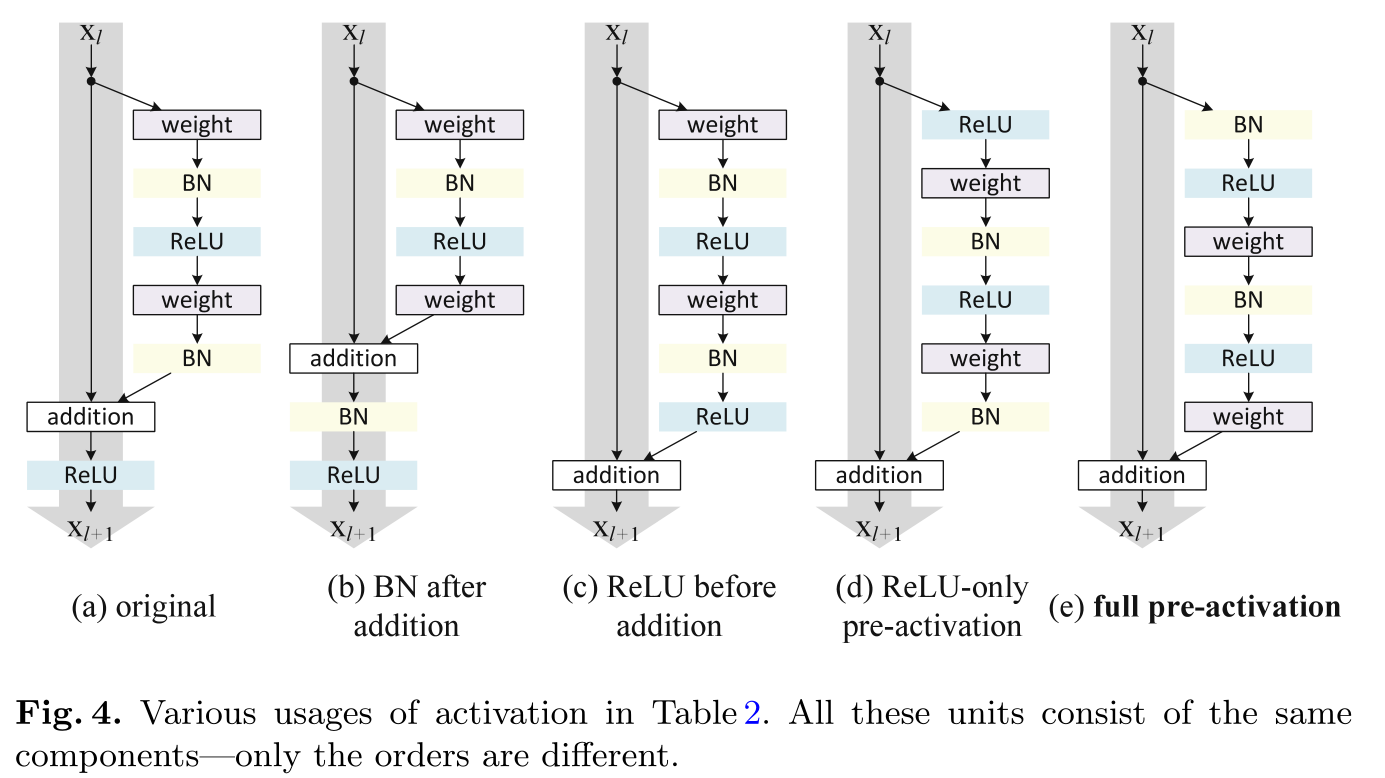
The final conclusion is that the shortcut (gray arrow line, shortcut link) had better not do other operations and keep it clean as far as possible for the dissemination of information. Ablation experiments (control variable method) also showed that the original shortcut 1 (Fig.2. (a) original) is already the best.
For the magic modification of the order of normalization layer (BatchNorm) and activation layer (ReLU). The final Ablation Experiment (control variable method) shows that it is better for BN+ReLU layer to calculate the input before the convolution layer (Fig. 4. (E) full pre activation) 1 not so bad.
Therefore, the code only needs to change the BN+ReLU order of ResidualBlock:
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.bn = nn.BatchNorm2d(channels)
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) # The size of the feature map has not changed
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = self.conv1(F.relu(self.bn(x)))
y = self.conv2(F.relu(self.bn(y)))
return x + y # No reactivation required
Read the paper and reproduce DenseNet
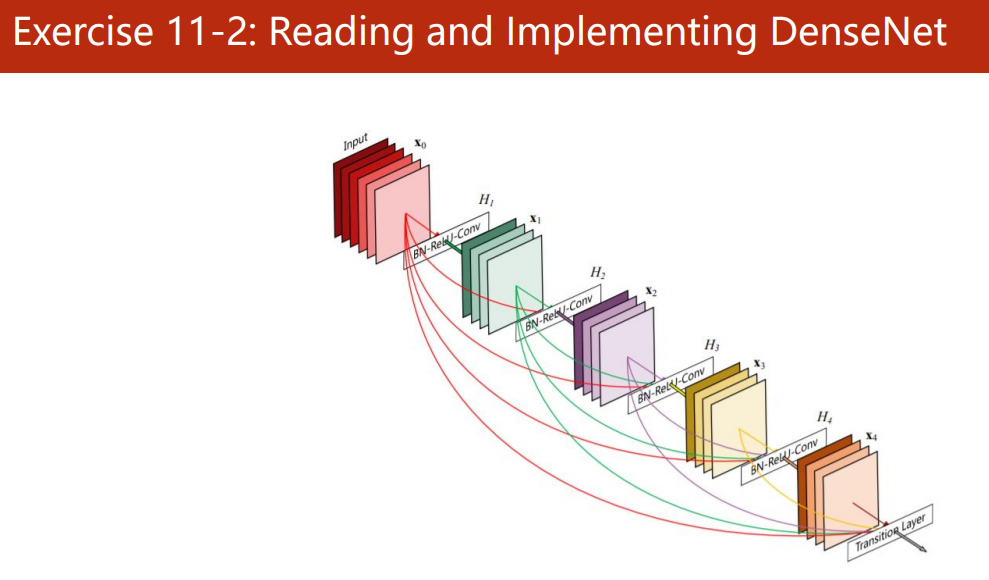
To be continued...