Visual training environment
Reinforcement learning is basically used for learning in many open source environments,
It's enough for beginners to use gym
gym is built based on pyglet, but it can't achieve a relatively tall effect, and it's not as good as pygame in many places
pygame
Pygame is a set of cross platform Python modules for creating video games
Install pip install pygame in conda directly
Construction process (static part)
Let's talk about the common methods first. Basically, once you master them, you can form a perfect little game
First, import pygame into the project
import pygame from pygame.locals import *
Note: it is slightly different from pyglet. Import here is to initialize the game. The render operation needs to be set in the main loop and seize the event, otherwise it will get stuck
Then do some initialization
#The annotated parts will be released in the full version. Only basic construction is introduced here
class Myenv():
def __init__(self) -> None:
#self.gen = Generator()
#self.player = Player()
#Initialize game
pygame.init()
#Set the game screen size, 500 wide and 450 high, which is defined by yourself
self.screen = pygame.display.set_mode((500, 450))
#This is a small box title, which can not be set
pygame.display.set_caption("Kousei's game")
#This is to import the picture and insert it into the game
self.line = pygame.image.load(r'E:\RLpaz\data\line.png')
self.agent = pygame.image.load(r'E:\RLpaz\data\agent.png')
#Compress the picture to the specified size
self.line = pygame.transform.scale(self.line, (Picture width, Picture high))
self.agent = pygame.transform.scale(self.agent, (Picture width, Picture high))
#This fcclock can limit the refresh rate of the game. If it is not limited, it can not be set
self.fcclock = pygame.time.Clock()
#Set refresh fps
self.fcclock.tick(100)
#self.record = []
#self.pre_render(400)
Then the environment is initialized, and then we need a refresh function to brush the pictures into the game every frame
def step(self,auto = False,a=1):
#done is reinforcement learning used to judge whether the turn is over
#done = False
#The background is filled with white. If you use the picture as the background, you can not set it
self.screen.fill((255,255,255))
#This auto is used by me to judge whether it is played by people or computers
if auto:
#Here, take the agent of reinforcement learning to take action
#self.player.step(a)
else:
#If people play, they will get the action according to the keyboard input
keys_pressed = pygame.key.get_pressed()
#If this frame A is pressed down, move - 1 grid
if keys_pressed[K_a]:
self.player.step(-1)
else:#D is + 1 grid. Move left and right
if keys_pressed[K_d]:
self.player.step(1)
#playerpos = self.player.pos
#self.record.append(self.gen.step())
#if(len(self.record)>400):
#self.record = self.record[1:]
#Here is the key. Draw the picture to the (i,index) position on the screen, which is set according to the game
for index,i in enumerate(self.record):
self.screen.blit(self.line, (i,index))
#This is the location of the drawing player
self.screen.blit(self.agent, (playerpos,400))
#update the drawn picture
pygame.display.update()
#Here you must add a flag to capture events and judge exit, anti crash + anti black screen
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
#Finally, return to s,a,r,info, etc. of reinforcement learning
#return self.record[-11:-1][::-1],self.score(self.record[-1]),done
In fact, draw a picture for each frame and upload it.
Easy
Finally, you only need to call step () in the main loop.
if __name__=='__main__':
env = Myenv()
while True:
record,_,_ = env.step()
Dynamic environment part
Before doing this part, I want you to think about it for yourself,
What kind of environment and game do you want to play
Then realize it
That's our goal
If you want to use the ready-made environment made by others, you can use gym
Make an environment and run with ai. He is our goal
Because reinforcement learning often has to build its own environment, because the world is not so gentle and will give you an interface
Finally, I give my own ideas
I want to create a discrete + continuous action space environment, so we need our protagonists to be able to move (or have acceleration) → racing
The environment can obtain one step (or multiple steps), and human can judge → path visualization
These points are very important because you only need to change a few values to apply to different algorithms
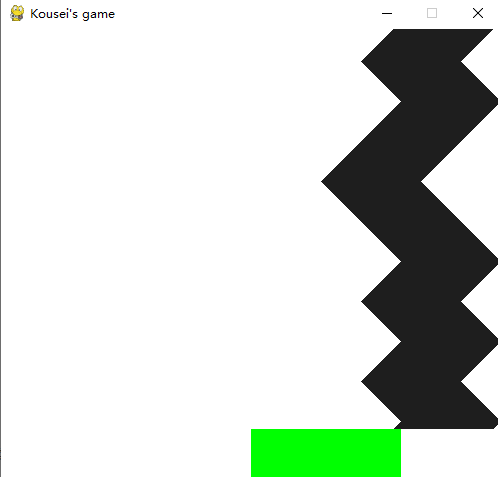
So finally, the water drop is drawn up (black is like water drop, although it is a little abstract). Of course, you can also increase the width of black into a racing game. By changing the player's (green) movement mode (move one step → acceleration), discrete input can be changed into continuous input at a low cost
Code completion
The environment code is above, and two parts can be completed:
Water droplet generator:
You can change the direction of the interval to the opposite direction (of course, you can change the direction to the edge at random)
class Generator:
def __init__(self) -> None:
self.speed = 1 #speed
self.width = 100 #width
self.limit = 500 - self.width #
self.count = 0 #Counter
self.iter = 40 #Move interval
self.dire = 1 #Direction 1 right
self.pos = 0#position
def step(self,):
if(self.count==self.iter):
if(random.randint(0,1)==1):
self.dire = -self.dire
self.count = 0
if((self.pos==self.limit and self.dire==1)or(self.pos==0 and self.dire==-1)):
self.dire = - self.dire
assert(self.limit%self.speed==0)
self.pos += self.dire * self.speed
self.count+=1
return self.pos
game player:
class Player:
def __init__(self,) -> None:
self.width = 150
self.pos = 0
self.limit = 400-self.width #width
#The following code turns the player into a continuous action input (acceleration)
#self.acc = 1
#self.nowspeed = 0
def step(self,dire):
self.pos += dire * self.acc
#self.nowspeed +=nowspeed
#self.pos += nowspeed
self.pos =min(self.limit,self.pos)
self.pos =max(0,self.pos)
Then give a score for training
Logic is what percent of the water drops are received
def score(self,epos):
score = 0
diff = abs(self.player.pos - epos)
if(self.player.pos<epos):
score = min(self.player.width +self.player.pos - epos,self.gen.width)
else:
score = self.gen.width - diff
return score/self.gen.width
#Sir, I'm a drop of water. I'm sure I can train at the beginning
def pre_render(self,steps):
assert(steps<=400)
for __ in range(steps):
self.record.append(self.gen.step())
Try running training!
When the environment is finished, of course you have to run, because the environment is equipped by yourself. If you are unhappy with it or are not satisfied with it, just change it
First run DQN with a simple discrete action. The previous chapter of DQN code has Oh
dqn=DQN(10)
env = Myenv()
playermid = env.player.pos + env.player.width/2
emid = np.array(env.record[-11:-1][::-1]) + env.gen.width/2
s = playermid-emid
index = 1
loss = 0
while True:
a = dqn.choose_action(s)
aa = a
if(a==0):
aa=-1
# Select actions to get environmental feedback
s_, r, done = env.step(True,aa*20)
playermid = env.player.pos + env.player.width/2
emid = np.array(s_) + env.gen.width/2
s_ = playermid-emid
# Save memory
dqn.store_transition(s, a, r, s_)
if dqn.memory_counter > MEMORY_CAPACITY:
loss = dqn.learn() # Learn when the memory bank is full
if done: # If the turn ends, go to the next turn
break
if(index%100==0):
print("r:{},islearn:{},loss:{},a:{}".format(r,dqn.memory_counter > MEMORY_CAPACITY,loss,a))
s = s_
index +=1
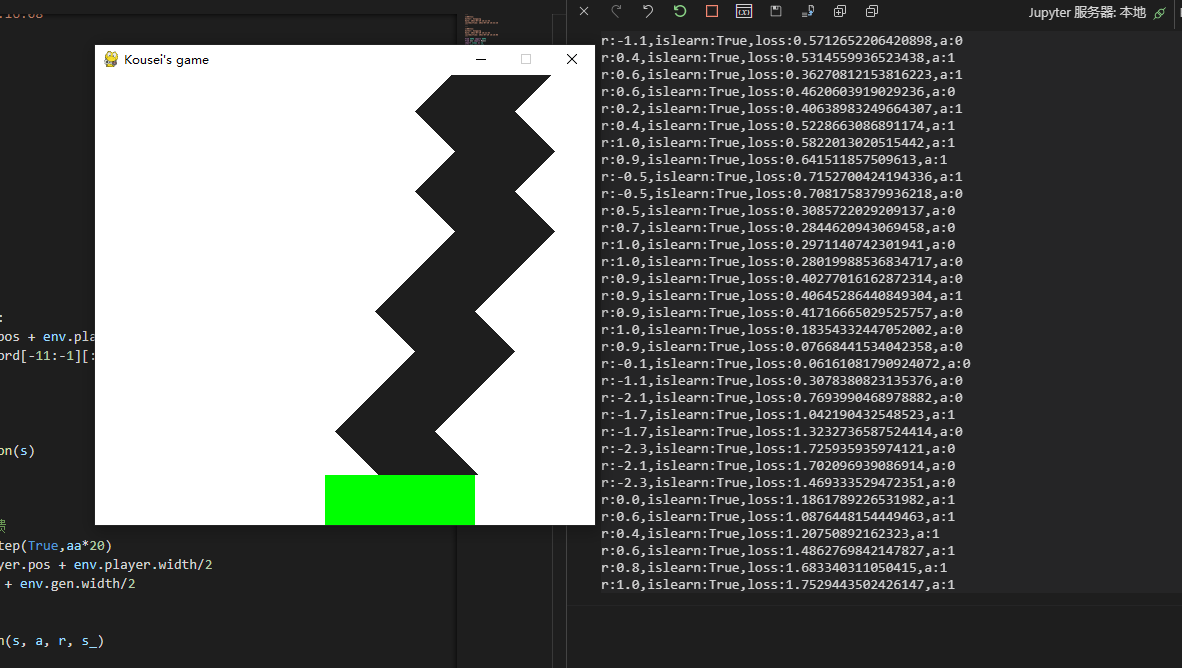
The effect is OK~
With your own environment, if you want to try other algorithms, you don't have to find the environment. Just change your environment according to the algorithm!