1, ik remote Thesaurus
The previous article explained ik as a whole, including the remote dynamic thesaurus. However, the previous article is based on nginx + static txt file. After modifying the file with nginx, the last modified attribute is automatically added. This method is also officially recommended:

Officials recommend using another tool to update this txt file, since we have written another tool, it's better to provide the dictionary by another tool. It's better to store the data in the database.
Let's talk about the following events. For those who don't know about ik, please refer to my last article:
https://blog.csdn.net/qq_43692950/article/details/122274613
2, Ik part of the source code interpretation
The following is the address of ik source code. You can pull it down first:
https://github.com/medcl/elasticsearch-analysis-ik
We can find the runUnprivileged method of Monitor and find the following:
First look at the official notes:

The implementation process has been clearly described here, and the following is the specific implementation.
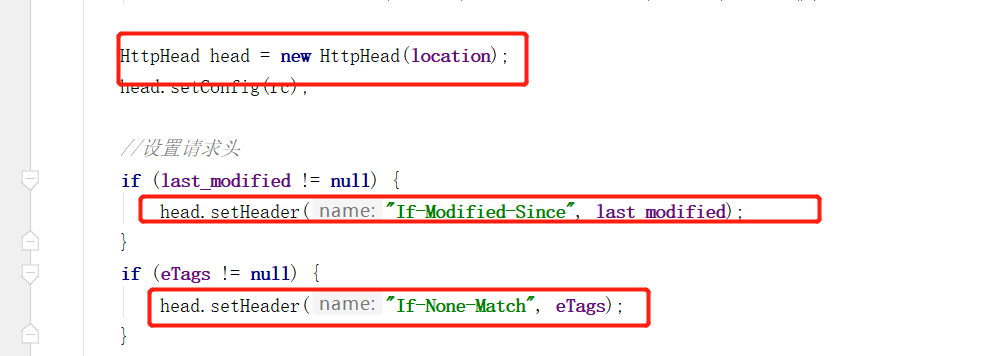
First send the request of head to the address we configured, and carry the current last modify and ETags. At first, it is not null.
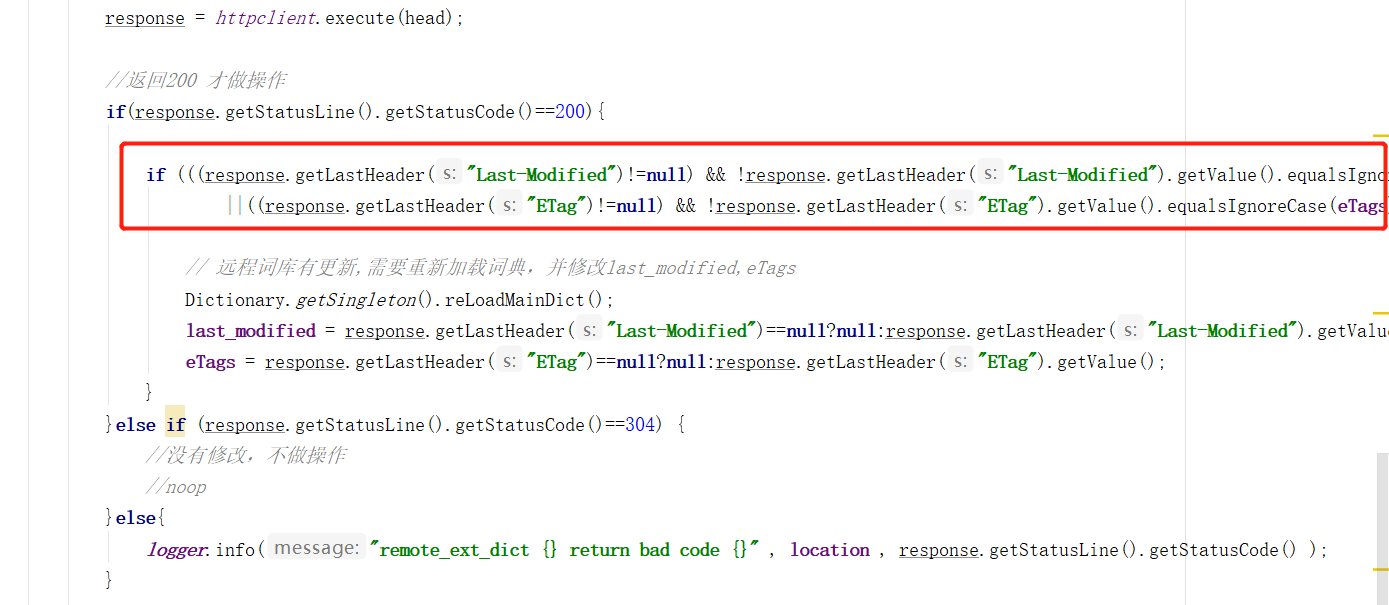
Here is the returned last modify and ETags fields. If they are different from the current ones, reload the thesaurus and update the current last modify and ETags. Continue to look at the dictionary getSingleton(). In the reloadandict() method.
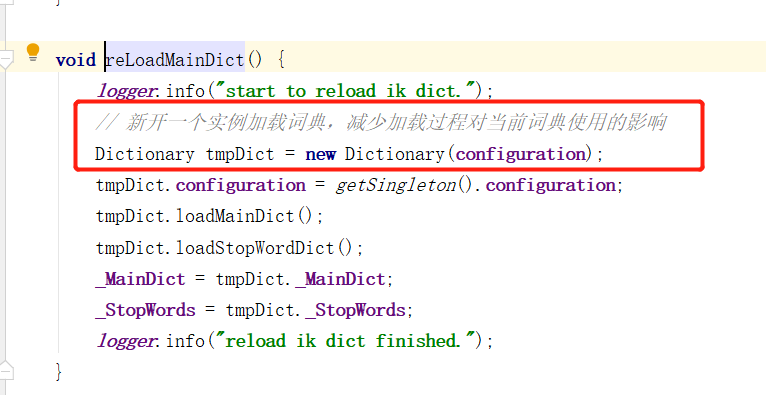
The comments here are also clear. A new Dictionary instance is opened. Next, go to the Dictionary class and find the getRemoteWordsUnprivileged method, which is the method to obtain the remote thesaurus.
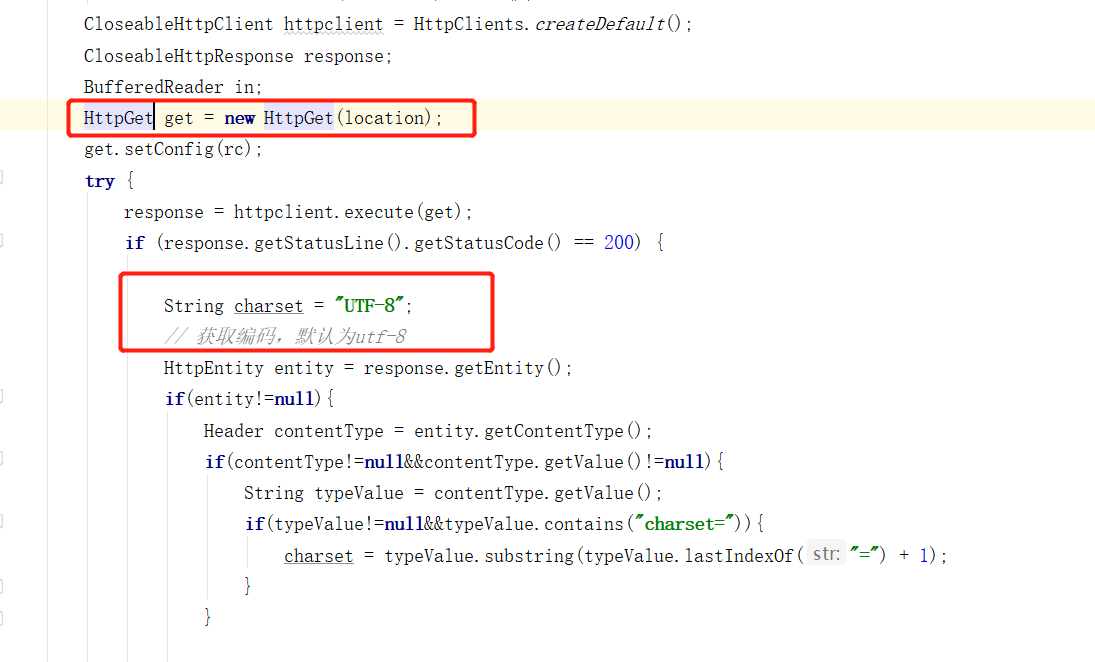
It can be seen from here that a Get request is also made to the address we configured. And decode the obtained return in the way of default UTF-8, which is why we had better set the encoding of the extended dictionary in nginx to UTF-8.
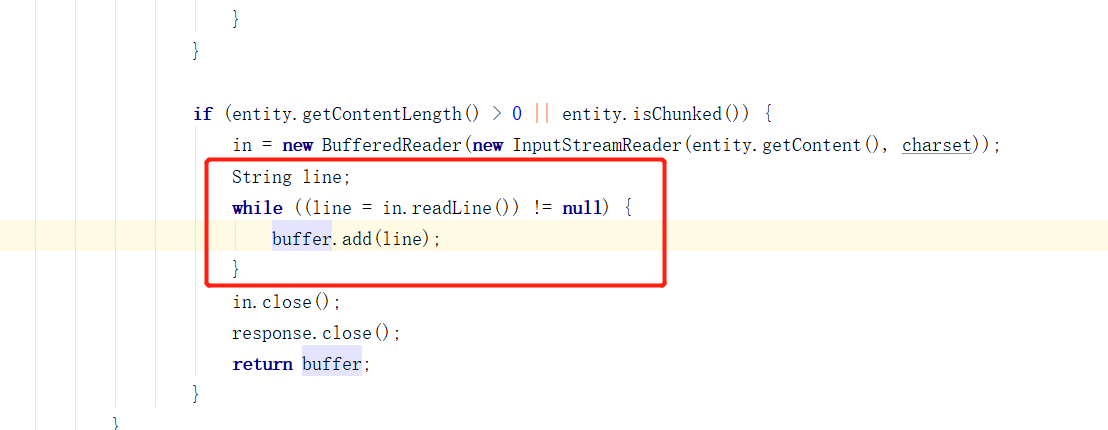
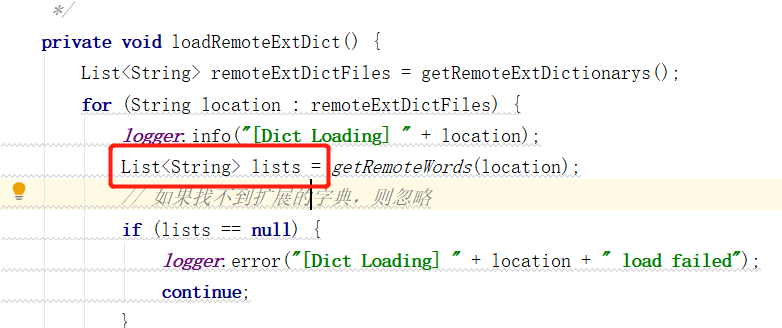
The list returned by this method is the content of the remote dictionary. During parsing, it is parsed according to the paradigm of one word per line. Therefore, in the previous article, we divided one word per line.
Here, we can know how to implement our customized interface from the analysis of the above part of the source code:
- First, create a head interface. In this interface, you can get es the current modified and eTag. We can write our own judgment, or directly return the latest modified and eTag.
- If the returned modified and eTag are inconsistent with those in the current ik, ik will call this url again to Get the thesaurus, and our thesaurus will be returned in the form of one word per line.
That's all. Let's start practicing.
3, Custom remote Thesaurus
We put the thesaurus in mysql for management. First, create a ik database and a dict word segmentation table:
CREATE TABLE `dict` ( `id` int(11) NOT NULL AUTO_INCREMENT, `dict_text` varchar(255) NOT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
Next, create a new SpringBoot project, which introduces dependencies and connecting to the database. This will be skipped directly.
Before writing the interface to ik, write an interface with participle as the following test:
@Service
public class DictServiceImpl implements DictService {
@Autowired
DictDao dictDao;
@Override
public boolean addDict(String text) {
DictEntity entity = new DictEntity(null, text, new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()));
return dictDao.insert(entity) > 0;
}
}
@RestController
public class DictController {
@Autowired
DictService dictService;
//Add vocabulary
@PutMapping("/dict/{text}")
public String addVocabulary(@PathVariable String text) {
return dictService.addDict(text) ? "success" : "err";
}
}
The above two paragraphs are very simple, which is to add data to the database, and each addition will give the current addition time. Here are the interfaces provided to ik:
@Slf4j
@RestController
public class IkController {
@Autowired
IkService ikService;
@RequestMapping(value = "/extDict", method = RequestMethod.HEAD)
public String headExtDict(HttpServletRequest request, HttpServletResponse response) throws ParseException {
String modified = request.getHeader("If-Modified-Since");
String eTag = request.getHeader("If-None-Match");
log.info("head Request, receive modified: {} ,eTag: {}", modified, eTag);
String newModified = ikService.getCurrentNewModified();
String newTag = String.valueOf(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(newModified).getTime());
response.setHeader("Last-Modified", newModified);
response.setHeader("ETag", newTag);
return "success";
}
@RequestMapping(value = "/extDict", method = RequestMethod.GET)
public String getExtDict(HttpServletRequest request, HttpServletResponse response) throws ParseException {
String newModified = ikService.getCurrentNewModified();
String newTag = String.valueOf(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(newModified).getTime());
response.setHeader("Last-Modified", newModified);
response.setHeader("ETag", newTag);
return ikService.getDict();
}
}
@Service
public class IkServiceImpl implements IkService {
@Autowired
DictDao dictDao;
@Override
public String getCurrentNewModified() {
return dictDao.getCurrentNewModified();
}
@Override
public String getDict() {
List<DictEntity> updateList = dictDao.selectList(null);
return String.join("\n", updateList.stream().map(DictEntity::getText).collect(Collectors.toSet()));
}
}
@Mapper
@Repository
public interface DictDao extends BaseMapper<DictEntity> {
@Select("select max(update_time) from dict")
String getCurrentNewModified();
}
Two interfaces, one is to verify whether the current is the latest head interface, and the other is the Get interface to obtain word segmentation. Note that the two routes must be written in the same way. After all, we only configure one interface for ik.
In the head interface, we directly return the last updated time of the current database as newModified, and newTag is the timestamp of the time and returned to ik. If the ik side judges that it is inconsistent, it will access our get interface, and then the interface directly returns all participles to ik, which has been \ n divided.
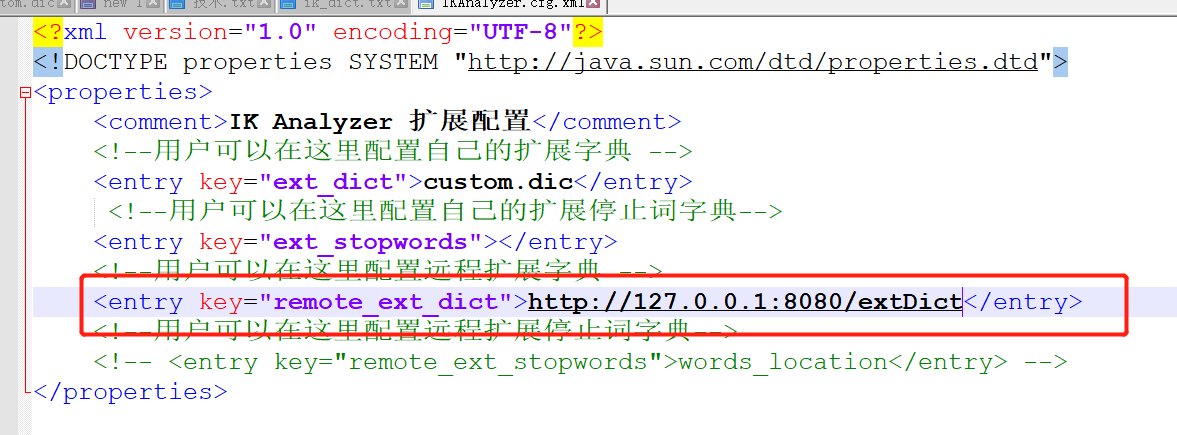
Next, start our spring boot project and modify the configuration file ik \ configikanalyzer cfg. xml:
Restart es, and you can see the print on our SpringBoot console:

For the first time, ik is empty, so what we accept is also empty.

The next request is to take it and we'll return it.
4, Word segmentation test
First, let's test Xiaobi Chao, our custom word:
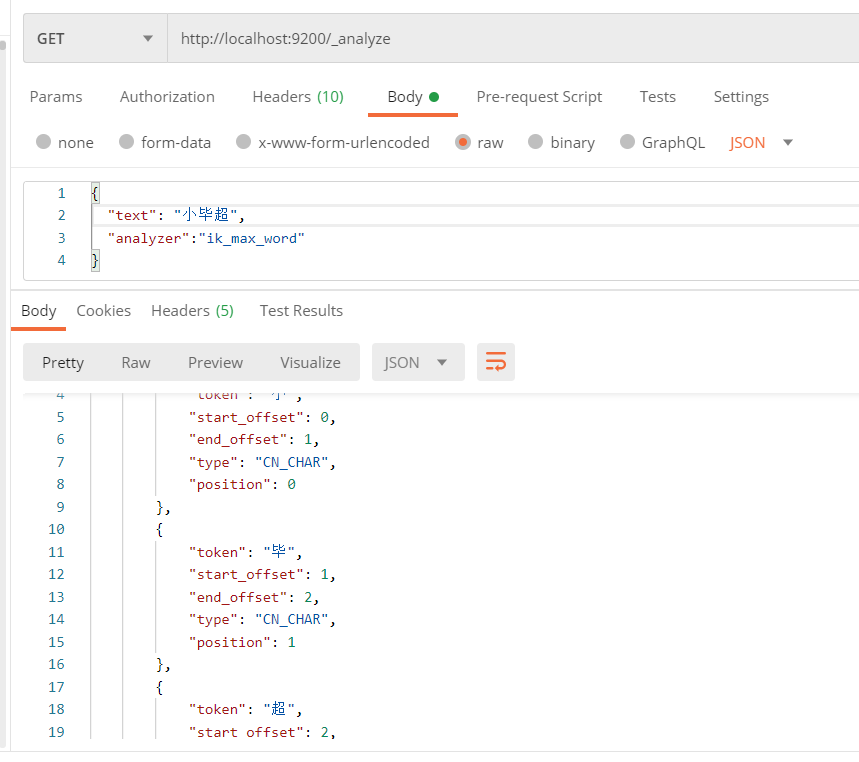
You can see that there is no word segmentation. Let's call the interface to add words and add Xiao Bi Chao
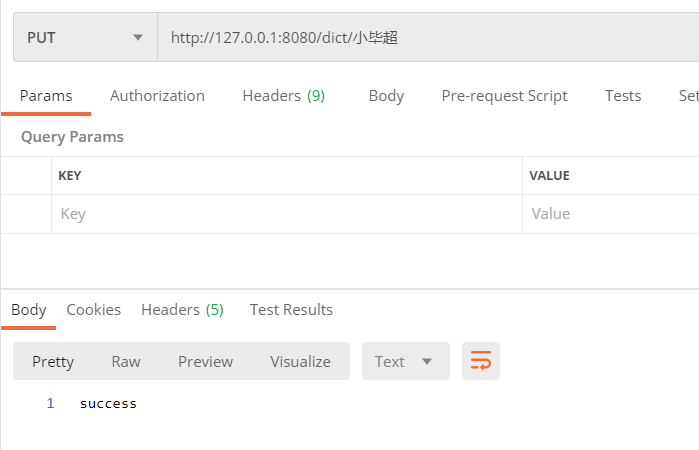
Then test again. It may not take effect immediately. As mentioned above when looking at the source code, ik makes a head request every 1 minute to judge whether the file has been modified, so wait about 1 minute and test again:
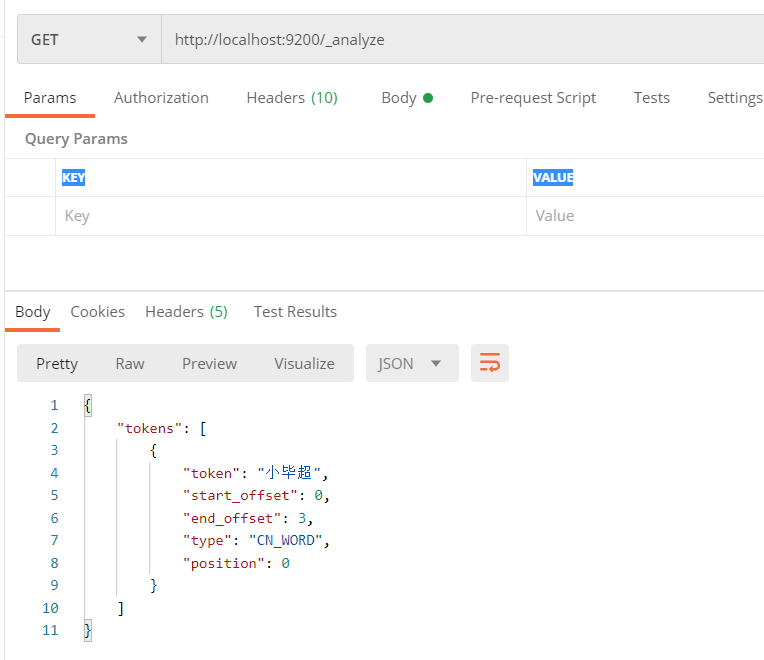
We have customized word segmentation effect.

Love little buddy can pay attention to my personal WeChat official account and get more learning materials.