[source code analysis] PyTorch distributed elastic training (2) - start & single node process
0x00 summary
In the previous article, we have learned the basic distributed modules of PyTorch and introduced several official examples. Next, we will introduce the elastic training of PyTorch. This article is the second, focusing on how to start the elastic training, and we can understand the overall architecture of the system.
The flexibility training series is as follows:
[Source code analysis] PyTorch distributed elastic training (1) - general idea
0x01 important concepts
For a better explanation (this explanation may also appear in later articles because it is too important), let's first summarize the two most important concepts of TE Agent and Rendezvous.
- Agent: agent is an independent background process running on a single node. It can be considered as a worker manager or process supervisor. It is responsible for starting workers, monitoring their operation, catching woker exceptions, realizing mutual discovery among workers through rendezvous (such as reporting the status to KVStore), and synchronizing changes based on rendezvous when members change, etc.
- Rendezvous: in order to realize elastic training, there needs to be a mechanism for nodes / processes to discover each other. Rendezvous is the discovery mechanism or synchronization component. When the system starts up or the members change, all worker s will rendezvous to create a new process group.
Let's take out the schematic diagram from the source code. Let's have an overall concept first.
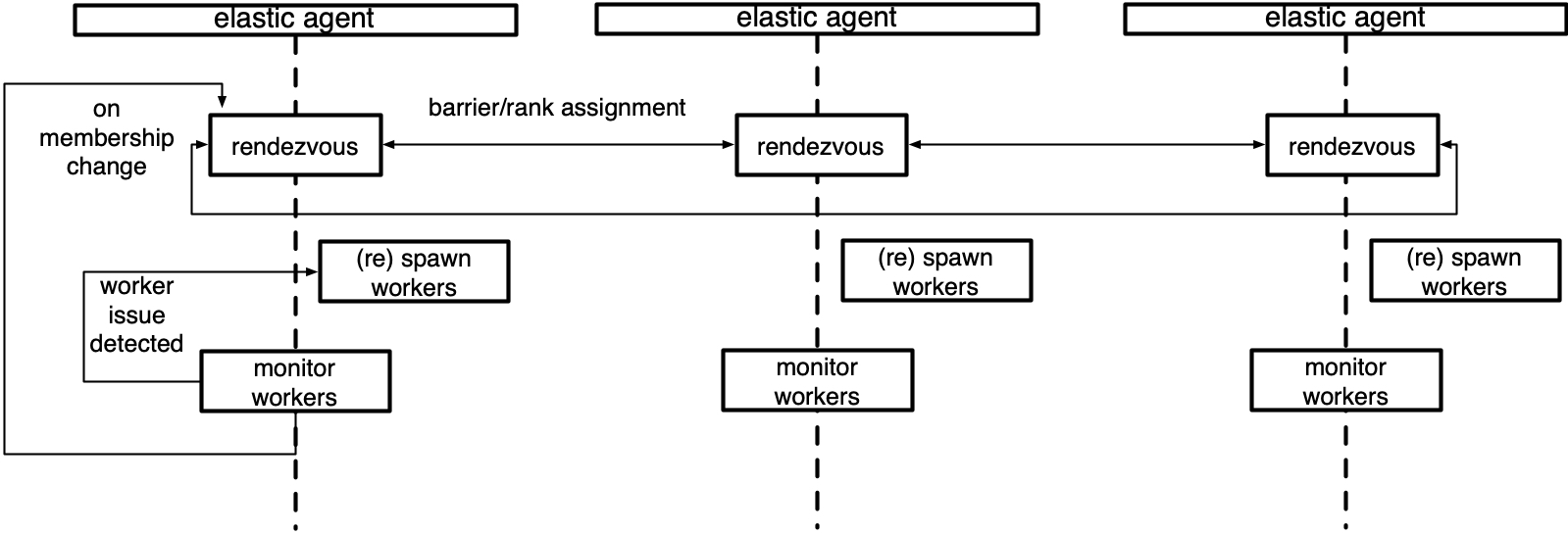
0x02 distributed operation
2.1 mode change
2.1. 1 original mode
We know that PET is from pytorch v1 9. The way of distributed startup has changed greatly because the flexible training is merged.
V1. Before 9, torch / distributed / launch Py, for example:
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE
--nnodes=2 --node_rank=0 --master_addr="192.168.1.1"
--master_port=1234 YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3
and all other arguments of your training script)
The meaning of the parameter here is:
- nnodes: is the number of nodes participating in training.
- nproc_per_node: the number of processes running on each node.
- node_rank: current node identifier.
- master_addr and master_port is the address and port that the master listens to.
When running, torch distributed. Launch will set some environment variables, including world_size ,master_addr and master_port, wait. Then create nproc on the current machine_ per_ Node is a process that forms a local group. If there are nodes_ If size machines participate in training, there will be node in total_ SIZE * TRAINERS_ PER_ Node processes. If you want to start a distributed training task, you need to execute relevant commands on all machines.
2.1. 2 current mode
PyTorch 1.9 uses torch / distributed / run Py to start. If you still use torch / distributed / launch Py, in fact, it has been transmitted internally to run Py, see code:
def main(args=None):
logger.warn(
"The module torch.distributed.launch is deprecated "
"and going to be removed in future."
"Migrate to torch.distributed.run"
)
args = parse_args(args)
run(args)
torch.distributed.run is the previous torch distributed. A superset of launch, which provides the following new functions:
- Fault tolerance: you can handle worker failures gracefully by restarting all workers.
- Automatic: RANK and world of Worker_ Size is automatically assigned.
- Elasticity: allows you to change the number of nodes between the minimum and maximum (elasticity).
In order to use elastic training, the user code also needs to be modified if the user's training script already supports torch distributed. Launch, you only need to modify a few places to use torch distributed. run :
- There is no need to transfer rank, world manually_ SIZE , MASTER_ Addr and MASTER_PORT.
- Rdzv must be provided_ Backend and rdzv_endpoint. For most users, this is actually "c10d" (see "rendezvous"). In fact, this replaces the previous MASTER_ADDR and MASTER_PORT.
- use_env parameter has been deleted. Please from local_ Get local from rank environment variable_ Rank (for example, os.environ["LOCAL_RANK"]).
- The user needs to ensure that there is load in the script_ Checkpoint (path) and save_checkpoint(path) logic, that is, manually processing checkpoint. Because when the worker fails, we will use the nearest checkpoint to restore the site and restart all workers.
The following is an example of a training script. The script sets checkpoints on each epoch, so the worst thing is to lose the training results of one epoch in case of failure.
def main():
args = parse_args(sys.argv[1:])
state = load_checkpoint(args.checkpoint_path)
initialize(state)
# torch.distributed.run ensure that this will work
# by exporting all the env vars needed to initialize the process group
torch.distributed.init_process_group(backend=args.backend)
for i in range(state.epoch, state.total_num_epochs)
for batch in iter(state.dataset)
train(batch, state.model)
state.epoch += 1
save_checkpoint(state)
So let's take a look at how to start distributed under the new mode.
2.2 deployment
The deployment is generally as follows.
- (not required for C10d backend) start the rendezvous backend server and obtain the endpoint (passed to the initiator script as --rdzv_endpoint)
- Single node multi worker: start the launcher on the host to start the agent process, and the agent will create and monitor the local workgroup.
- Multi node multi worker: start the launcher on all nodes with the same parameters to participate in training.
When using job / Cluster Administrator, the entry point command for multi node jobs should be launcher.
2.3 example
Let's start with a few examples to see how to start distributed training.
2.3. 1. Single node multi worker startup
The startup mode of single node multi workers is as follows. In fact, it is the Standalone mode, which is a special case of the distributed mode. Specifically, it provides some convenient settings for single machine multi workers.
python -m torch.distributed.run
--standalone
--nnodes=1
--nproc_per_node=$NUM_TRAINERS
YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)
2.3. 2 fault tolerant startup
The following is a fault-tolerant startup with a fixed number of workers and no elastic training-- nproc_ per_ node=$NUM_ Trains is generally the number of GPU s on a single node.
python -m torch.distributed.run
--nnodes=$NUM_NODES
--nproc_per_node=$NUM_TRAINERS
--rdzv_id=$JOB_ID
--rdzv_backend=c10d
--rdzv_endpoint=$HOST_NODE_ADDR
YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)
HOST_NODE_ADDR, in the format of: [], specifies the node address and port of C10d rendezvous backend. This node can be any node in the training cluster, but it is best to find a node with high bandwidth.
2.3. 3 elastic start
The following is elastic training. The elastic interval is (min=1, max=4). By specifying rdzv parameters, multi machine training can be realized, which has the ability of fault tolerance and flexibility.
Execute the following commands on multiple machines to start: the minimum number of nodes is MIN_SIZE, MAX_SIZE, using etcd services to achieve consistency and information synchronization.
python -m torch.distributed.run
--nnodes=1:4
--nproc_per_node=$NUM_TRAINERS
--rdzv_id=$JOB_ID
--rdzv_backend=c10d
--rdzv_endpoint=$HOST_NODE_ADDR
YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)
HOST_NODE_ADDR, in the format of: [], specifies the node address and port of C10d rendezvous backend. This node can be any node in the training cluster, but it is best to find a node with high bandwidth.
About rendezvous backend, there are several notes:
For multi node training, you need to specify:
- --rdzv_id: a unique job id, which is shared among all nodes participating in the job.
- --rdzv_ backend: torch. distributed. elastic. rendezvous. An implementation of rendezvoushandler. (--rdzv_backend is in static mode by default and does not support fault tolerance and elastic scaling)
- --rdzv_ Endpoint: the endpoint run by rendezvous backend. The usual format is: host:port. It replaces the previous master address / port setting.
At present, the following backend can be used directly: c10d (recommended), etcd-v2, and etcd (legacy). In order to use etcd-v2 or etcd, you need to build an etcd server (i.e. -- enable-v2) enabled by v2 api.
0x03 startup script
Since the above startup is using torch / distributed / run Py, so let's carefully analyze this script, which provides three functions:
-
Rely on "restart all workers" to handle worker failure;
-
Automatically assign rank and world of worker s_ SIZE ;
-
Elastic training, that is, the number of node s is allowed to change between minimum and maximum;
3.1 parameter definition
In the startup script, some parameters are defined as follows:
- Node - Physical instance or container; Map to the unit coordinated with the job manager.
- Worker - a worker in a distributed training environment.
- WorkerGroup - a group of worker s (for example, trainers) that perform the same function.
- LocalWorkerGroup - a subset of workers in a workgroup running on the same node.
- One node runs LOCAL_WORLD_SIZE consists of workers, which form the LocalWorkerGroup.
- All LocalWorkerGroups on the node constitute WorkerGroups.
- rank - the rank of the worker in the workgroup, which is a global rank and can be considered as a global GPU resource list.
- RANK is unstable. Local Workers will be assigned to different ranks between restarts, so don't compare RANK and local in the code_ RANK stability makes any assumptions and dependent coding.
- After rendezvous is completed, all its members will reach a consensus on job membership and everyone's role in it. This role is represented by an integer between 0 and world size, which is called rank.
- LOCAL_RANK - the rank of a worker in the local workgroup, which can be considered as the GPU resource list on the current node.
- GROUP_RANK - rank of the worker group. Number between 0 and Max nodes. If each node runs a single workgroup, then GROUP_RANK is the rank of this node.
- ROLE_RANK - the rank shared between workers with the same role, and the role is specified in "WorkerSpec".
- WORLD_SIZE - the total number of worker s in the workgroup. Because nodes join / leave, WORLD_SIZE will change and cannot depend on world_ The stability of size is encoded.
- LOCAL_WORLD_SIZE - the size of the local workgroup, that is, the number of workers running locally, which is equal to that in torch distributed. Specified at run time -- nproc_per_node. Currently, torch / distributed / run Py only supports isomorphic LOCAL_WORLD_SIZE. That is, it is assumed that all nodes run the same number of local workers (each role).
- ROLE_WORLD_SIZE - the total number of workers with the same role, which is specified in the WorkerSpec.
- rdzv_id - user defined id that uniquely identifies the workgroup of the job. This id is used when each node joins a specific workgroup.
- rdzv_ Backend rendezvous (for example, "c10d"). This is usually a strongly consistent key value store.
- rdzv_endpoint - rendezvous backend endpoint; It usually appears in the form of "< host >: < port >".
- run_id: a user-defined id that uniquely identifies an instance of a distributed application. It is usually mapped to job id and used to allow nodes to join the correct distributed application.
- TORCHELASTIC_RUN_ID - with rendezvous run_ The ID is equal, that is, the unique job id.
- TORCHELASTIC_RESTART_COUNT - number of workgroup restarts to date.
- TORCHELASTIC_MAX_RESTARTS - maximum number of restarts configured.
3.2 correlation functions / variables
In order to better understand the above parameters, we select some related functions / variables.
world_size,rank
These two variables are generated dynamically, so they are taken from state.
rank, world_size = self._get_world()
def _get_world(self) -> Tuple[int, int]:
state = self._state_holder.state
return state.participants[self._this_node], len(state.participants)
_pg_group_ranks
This global variable stores the global rank to local rank mapping information of each group.
# Process group's global rank to local rank mapping
_pg_group_ranks: Dict[ProcessGroup, Dict[int, int]] = {}
An example of its assignment is as follows:
# Create the global rank to group rank mapping
_pg_group_ranks[pg] = {
global_rank: group_rank
for group_rank, global_rank in enumerate(ranks)
}
group_rank
We can use global rank from_ pg_ group_ Extract the corresponding local rank from the ranks.
def _get_group_rank(group: ProcessGroup, rank):
"""
Helper that gets a given group's local rank in the group from a given global
rank.
"""
if group is GroupMember.WORLD:
raise RuntimeError("group.WORLD does not have local rank to global "
"rank mapping")
if group not in _pg_group_ranks:
raise RuntimeError("The given group does not exist")
try:
group_rank = _pg_group_ranks[group][rank]
except KeyError:
raise RuntimeError(f"The global rank {rank} is not part of the group {group}") from None
return group_rank
global_rank
We can use the local rank of a group to obtain its gloabl rank.
def _get_global_rank(group, group_rank):
"""
Helper that gets a given group's global rank from a given local rank in the
group.
"""
if group is GroupMember.WORLD:
raise RuntimeError("group.WORLD does not have local rank to global "
"rank mapping")
group_rank_map = _pg_group_ranks[group]
for rank, grp_rank in group_rank_map.items():
if grp_rank == group_rank:
return rank
raise RuntimeError("The group rank is not part of the group")
group_size
We can_ get_group_size gets the size of a group.
def _get_group_size(group):
"""
Helper that gets a given group's world size.
"""
if group is GroupMember.WORLD or group is None:
default_pg = _get_default_group()
return default_pg.size()
if group not in _pg_group_ranks:
raise RuntimeError("The given group does not exist")
return len(_pg_group_ranks[group])
nproc_per_node
This variable can get how many processes are supported on each node.
def determine_local_world_size(nproc_per_node: str):
try:
logging.info(f"Using nproc_per_node={nproc_per_node}.")
return int(nproc_per_node)
except ValueError:
if nproc_per_node == "cpu":
num_proc = os.cpu_count()
device_type = "cpu"
elif nproc_per_node == "gpu":
if not torch.cuda.is_available():
raise ValueError("Cuda is not available.")
device_type = "gpu"
num_proc = torch.cuda.device_count()
elif nproc_per_node == "auto":
if torch.cuda.is_available():
num_proc = torch.cuda.device_count()
device_type = "gpu"
else:
num_proc = os.cpu_count()
device_type = "cpu"
else:
raise ValueError(f"Unsupported nproc_per_node value: {nproc_per_node}")
)
return num_proc
3.3 script entry
The main code of the script entry is as follows. You can see that it calls elastic_launch to complete the function, so we'll take a look at this function in the next section.
from torch.distributed.launcher.api import LaunchConfig, elastic_launch
def run(args):
if args.standalone: # There are two modes: Standalone mode and distributed mode
args.rdzv_backend = "c10d"
args.rdzv_endpoint = "localhost:29400"
args.rdzv_id = str(uuid.uuid4())
log.info(
f"\n**************************************\n"
f"Rendezvous info:\n"
f"--rdzv_backend={args.rdzv_backend} "
f"--rdzv_endpoint={args.rdzv_endpoint} "
f"--rdzv_id={args.rdzv_id}\n"
f"**************************************\n"
)
config, cmd, cmd_args = config_from_args(args)
elastic_launch(
config=config,
entrypoint=cmd,
)(*cmd_args)
def main(args=None):
args = parse_args(args)
run(args)
if __name__ == "__main__":
logging.basicConfig(
level=logging.INFO, format="[%(levelname)s] %(asctime)s %(module)s: %(message)s"
)
main()
0x04 overall process of monomer
Let's start with elastic_ Start with launch and see how to start running on a single node. We first give an overall diagram. There are two nodes on the diagram. Each node has an agent. Below the agent is a worker group and below the group are four workers.

4.1 small examples
Let's take another example from the source code. Here, only two workers are set.
import uuid
import torch
from torch.distributed.launcher.api import LaunchConfig, elastic_launch
def worker_fn(t1, t2):
return torch.add(t1, t2)
def main():
t1 = torch.rand((3,3), requires_grad=True)
t2 = torch.rand((3, 3), requires_grad=True)
config = LaunchConfig(
min_nodes=2,
max_nodes=4,
nproc_per_node=1,
run_id=str(uuid.uuid4()),
role="trainer",
rdzv_endpoint="localhost:29400",
rdzv_backend="c10d",
max_restarts=1,
monitor_interval=1,
start_method="spawn",
)
outputs = elastic_launch(config, worker_fn)(t1, t2)
if __name__ == '__main__':
main()
The output is as follows. You can see that there are two worker processes and one agent process.
{"name": "torchelastic.worker.status.SUCCEEDED", "source": "WORKER", "timestamp": 0, "metadata": {"run_id": "7fbf85fe-b8b3-462e-887e-8121e3062e0b", "global_rank": 0, "group_rank": 0, "worker_id": "12172", "role": "trainer", "hostname": "DESKTOP-0GO3RPO", "state": "SUCCEEDED", "total_run_time": 31, "rdzv_backend": "c10d", "raw_error": null, "metadata": "{\"group_world_size\": 1, \"entry_point\": \"worker_fn\", \"local_rank\": [0], \"role_rank\": [0], \"role_world_size\": [2]}", "agent_restarts": 0}}
{"name": "torchelastic.worker.status.SUCCEEDED", "source": "WORKER", "timestamp": 0, "metadata": {"run_id": "7fbf85fe-b8b3-462e-887e-8121e3062e0b", "global_rank": 1, "group_rank": 0, "worker_id": "3276", "role": "trainer", "hostname": "DESKTOP-0GO3RPO", "state": "SUCCEEDED", "total_run_time": 31, "rdzv_backend": "c10d", "raw_error": null, "metadata": "{\"group_world_size\": 1, \"entry_point\": \"worker_fn\", \"local_rank\": [1], \"role_rank\": [1], \"role_world_size\": [2]}", "agent_restarts": 0}}
{"name": "torchelastic.worker.status.SUCCEEDED", "source": "AGENT", "timestamp": 0, "metadata": {"run_id": "7fbf85fe-b8b3-462e-887e-8121e3062e0b", "global_rank": null, "group_rank": 0, "worker_id": null, "role": "trainer", "hostname": "DESKTOP-0GO3RPO", "state": "SUCCEEDED", "total_run_time": 31, "rdzv_backend": "c10d", "raw_error": null, "metadata": "{\"group_world_size\": 1, \"entry_point\": \"worker_fn\"}", "agent_restarts": 0}}
4.2 entrance
Let's dig deeper into the code. elastic_ The function of launch is to start a torch last agent, and then call the user program entry through this agent. The agent will start the worker for training and manage the worker life cycle.
class elastic_launch:
"""
Launches an torchelastic agent on the container that invoked the entrypoint.
1. Pass the ``entrypoint`` arguments as non ``kwargs`` (e.g. no named parameters)/
``entrypoint`` can be a function or a command.
2. The return value is a map of each worker's output mapped
by their respective global rank.
"""
def __init__(
self,
config: LaunchConfig,
entrypoint: Union[Callable, str, None],
):
self._config = config
self._entrypoint = entrypoint
def __call__(self, *args, **kwargs):
return launch_agent(self._config, self._entrypoint, list(args)) # The user program is called internally
4.3 start agent
launch_agent starts a LocalElasticAgent and calls its run method.
@record
def launch_agent(
config: LaunchConfig,
entrypoint: Union[Callable, str, None],
args: List[Any],
) -> Dict[int, Any]:
if not config.run_id:
run_id = str(uuid.uuid4().int)
config.run_id = run_id
entrypoint_name = _get_entrypoint_name(entrypoint, args)
rdzv_parameters = RendezvousParameters(
backend=config.rdzv_backend,
endpoint=config.rdzv_endpoint,
run_id=config.run_id,
min_nodes=config.min_nodes,
max_nodes=config.max_nodes,
**config.rdzv_configs,
)
agent = None
rdzv_handler = rdzv_registry.get_rendezvous_handler(rdzv_parameters)
master_addr, master_port = _get_addr_and_port(rdzv_parameters)
try:
spec = WorkerSpec( # 1. Get spec
role=config.role,
local_world_size=config.nproc_per_node,
entrypoint=entrypoint,
args=tuple(args),
rdzv_handler=rdzv_handler, # RendezvousHandler
max_restarts=config.max_restarts,
monitor_interval=config.monitor_interval,
redirects=config.redirects,
tee=config.tee,
master_addr=master_addr,
master_port=master_port,
)
cfg = metrics.MetricsConfig(config.metrics_cfg) if config.metrics_cfg else None
metrics.initialize_metrics(cfg)
agent = LocalElasticAgent( # 2. Build agent
spec=spec, start_method=config.start_method, log_dir=config.log_dir
)
result = agent.run() # 3. Start the agent
events.record(agent.get_agent_status_event(WorkerState.SUCCEEDED))
if result.is_failed():
# ChildFailedError is treated specially by @record
# if the error files for the failed children exist
# @record will copy the first error (root cause)
# to the error file of the launcher process.
raise ChildFailedError(
name=entrypoint_name,
failures=result.failures,
)
else:
return result.return_values
except ChildFailedError:
raise
except Exception:
if agent:
events.record(agent.get_agent_status_event(WorkerState.FAILED))
else:
events.record(_construct_event(config))
raise
finally:
rdzv_handler.shutdown()
Here are some key points:
4.3.1 WorkerSpec
WorkerSpec: This is the configuration information, which contains some global information required by the agent, such as RendezvousHandler, role and entry (user function).
spec = {WorkerSpec}
args = {tuple: 2} (tensor, tensor)
fn = {NoneType} None
local_world_size = {int} 1
master_addr = {NoneType} None
master_port = {NoneType} None
max_restarts = {int} 1
monitor_interval = {int} 1
rdzv_handler = {DynamicRendezvousHandler}
redirects = {Std} Std.NONE
role = {str} 'trainer'
tee = {Std} Std.NONE
entry = worker_fn
The agent will extract various required information from here. For example_ start_workers will get the store from it.
use_agent_store = spec.rdzv_handler.get_backend() == "static"
The logic is:
+--------------------------+ +---------------------------------------------------+
|LocalElasticAgent | | WorkerSpec |
| | | |
| WorkerSpec +--------------> | rdzv_handler = {DynamicRendezvousHandler} --------+
| | | | |
| rdzv_run_id | | entry = worker_fn | |
| | | | |
| store | | role = {str} 'trainer' | |
| | | | |
| | +---------------------------------------------------+ |
| | |
| | |
| | |
| | |
| | +-----------------------------------------+ |
+--------------------------+ |DynamicRendezvousHandler | |
| | |
| | |
| _settings: RendezvousSettings | <---+
| |
| _store: Store |
| |
| _state_holder: _RendezvousStateHolder |
| |
| _op_executor: _RendezvousOpExecutor |
| |
+-----------------------------------------+
4.3.2 WorkerGroup
The WorkerGroup represents a working group. The WorkerGroup manages multiple workers as a whole for batch processing.
class WorkerGroup:
"""
Represents the set of ``Worker`` instances for the given ``WorkerSpec``
managed by ``ElasticAgent``. Whether the worker group contains cross
instance workers or not depends on the implementation of the agent.
"""
__slots__ = ["spec", "workers", "store", "group_rank", "group_world_size", "state"]
def __init__(self, spec: WorkerSpec):
self.spec = spec
self.workers = [Worker(local_rank=i) for i in range(self.spec.local_world_size)]
# assigned after rdzv
self.store = None
self.group_rank = None
self.group_world_size = None
self.state = WorkerState.INIT
During the initialization of SimpleElasticAgent, a WorkerGroup will be established.
class SimpleElasticAgent(ElasticAgent):
"""
An ``ElasticAgent`` that manages workers (``WorkerGroup``)
for a single ``WorkerSpec`` (e.g. one particular type of worker role).
"""
def __init__(self, spec: WorkerSpec, exit_barrier_timeout: float = 300):
self._worker_group = WorkerGroup(spec)
self._remaining_restarts = self._worker_group.spec.max_restarts
self._store = None
self._exit_barrier_timeout = exit_barrier_timeout
self._total_execution_time = 0
The details are as follows:
+-----------------------------+ +------------------------------------------------+
| LocalElasticAgent | | WorkerSpec |
| | | |
| +------------------------+ | | rdzv_handler = {DynamicRendezvousHandler} -------+
| |WorkerGroup | | | | |
| | spec +--------------> | entry = worker_fn | |
| | workers | | | | |
| | store | | | role = {str} 'trainer' | |
| | group_rank | | | | |
| | group_world_size | | +------------------------------------------------+ |
| | | | |
| +------------------------+ | |
| | |
| rdzv_run_id | |
| store | +-----------------------------------------+ |
| | |DynamicRendezvousHandler | |
+-----------------------------+ | | |
| | |
| _settings: RendezvousSettings | <--+
| |
| _store: Store |
| |
| _state_holder: _RendezvousStateHolder |
| |
| _op_executor: _RendezvousOpExecutor |
| |
+-----------------------------------------+
4.4 agent operation
SimpleElasticAgent is the base class of LocalElasticAgent, so it will run to workerspec Run method here, the run method calls_ invoke_run.
@prof
def run(self, role: str = DEFAULT_ROLE) -> RunResult:
start_time = time.monotonic()
try:
result = self._invoke_run(role) # call
self._total_execution_time = int(time.monotonic() - start_time)
self._record_metrics(result)
self._record_worker_events(result)
return result
finally:
# record the execution time in case there were any exceptions during run.
self._total_execution_time = int(time.monotonic() - start_time)
self._shutdown()
4.5 agent main cycle
Agent in invoke_ Do the following in run:
- Start_ initialize_workers, which will be used here_ Rendezvous builds a rendezvous and then calls it. start_workers start workers.
- Enter the while True loop, in which:
- Pass_ monitor_workers regularly rotate the user program operation, get the customer process operation results, and then make judgments according to the situation.
- If the program ends normally, return.
- If the program fails, Retry, that is, restart all workers. If there are still problems after the number of retries, end all workers.
- If the node membership changes, such as scale up, a new node will be waiting. At this time, restart all workers.
- Pass_ monitor_workers regularly rotate the user program operation, get the customer process operation results, and then make judgments according to the situation.
def _invoke_run(self, role: str = DEFAULT_ROLE) -> RunResult:
# NOTE: currently only works for a single role
spec = self._worker_group.spec
role = spec.role
self._initialize_workers(self._worker_group) # Start worker
monitor_interval = spec.monitor_interval
rdzv_handler = spec.rdzv_handler
while True:
assert self._worker_group.state != WorkerState.INIT
# Regular monitoring
time.sleep(monitor_interval)
# Monitor client program operation
run_result = self._monitor_workers(self._worker_group) # Get process running results
state = run_result.state
self._worker_group.state = state
put_metric(f"workers.{role}.remaining_restarts", self._remaining_restarts)
put_metric(f"workers.{role}.{state.name.lower()}", 1)
if state == WorkerState.SUCCEEDED:
# The program ends normally
self._exit_barrier()
return run_result
elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}:
# Program error
if self._remaining_restarts > 0: # retry
self._remaining_restarts -= 1
self._restart_workers(self._worker_group)
else:
self._stop_workers(self._worker_group) # Retry times reached, end workers
self._worker_group.state = WorkerState.FAILED
self._exit_barrier()
return run_result
elif state == WorkerState.HEALTHY:
# If the node membership changes, such as scale up, there will be a new node waiting
# membership changes do not count as retries
num_nodes_waiting = rdzv_handler.num_nodes_waiting()
group_rank = self._worker_group.group_rank
# If a new node is waiting, restart all workers
if num_nodes_waiting > 0:
self._restart_workers(self._worker_group)
else:
raise Exception(f"[{role}] Worker group in {state.name} state")
The final logic is as follows:
+----------------------------------------------+
| LocalElasticAgent |
| | +---------------------------------------------------+
| rdzv_run_id | | WorkerSpec |
| | | |
| store +------------------------+ | | rdzv_handler = {DynamicRendezvousHandler} +-------+
| |WorkerGroup | | | | |
| _pcontext | spec +------------> | entry = worker_fn | |
| | workers | | | | |
| | store | | | role = {str} 'trainer' | |
| | group_rank | | | | |
| | group_world_size | | +---------------------------------------------------+ |
| | | | |
| +------------------------+ | |
| +----------------------------------------+ | |
| | _invoke_run | | |
| | | | +-----------------------------------------+ |
| | _initialize_workers +------------------------+ |DynamicRendezvousHandler | |
| | | | | | | |
| | | | | | | |
| | while True: | | | | _settings: RendezvousSettings | <---+
| | _monitor_workers(_worker_group) | | | | |
| | + | | | | _store: Store |
| | | _pcontext.wait | | | | |
| | | | | | | _state_holder: _RendezvousStateHolder |
| +----------------------------------------+ | | | |
| | | | | _op_executor: _RendezvousOpExecutor |
+----------------------------------------------+ | | |
| | +-----------------------------------------+
| |
v v
+-------------------------------------------------+
| +------------+ +------------+ +------------+ |
| |Process | |Process | |Process | |
| | | | | | | |
| | work_fn | | work_fn | | work_fn | |
| | | | | | | |
| +------------+ +------------+ +------------+ |
+-------------------------------------------------+
Mobile phones are as follows:

So far, we have analyzed how the script starts and the monomer process. In the next article, we will analyze the agent in detail.