Spark introduction and spark deployment, principle and development environment construction
Introduction to spark
Spark is a fast, universal and scalable big data analysis and calculation engine based on memory.
It is a general memory parallel computing framework developed by the AMP Laboratory (Algorithms, Machines, and People Lab) at the University of California, Berkeley
Spark is supported by many big data companies, including Hortonworks, IBM, Intel, Cloudera, MapR, pivot, Baidu, Alibaba, Tencent, JD, Ctrip and Youku Tudou. At present, baidu spark has been applied to big search, direct number, baidu big data and other businesses; Ali uses GraphX to build a large-scale graph calculation and graph mining system, and realizes the recommendation algorithms of many production systems; Tencent spark cluster has reached the scale of 8000 units, which is the largest known spark cluster in the world.
Version history
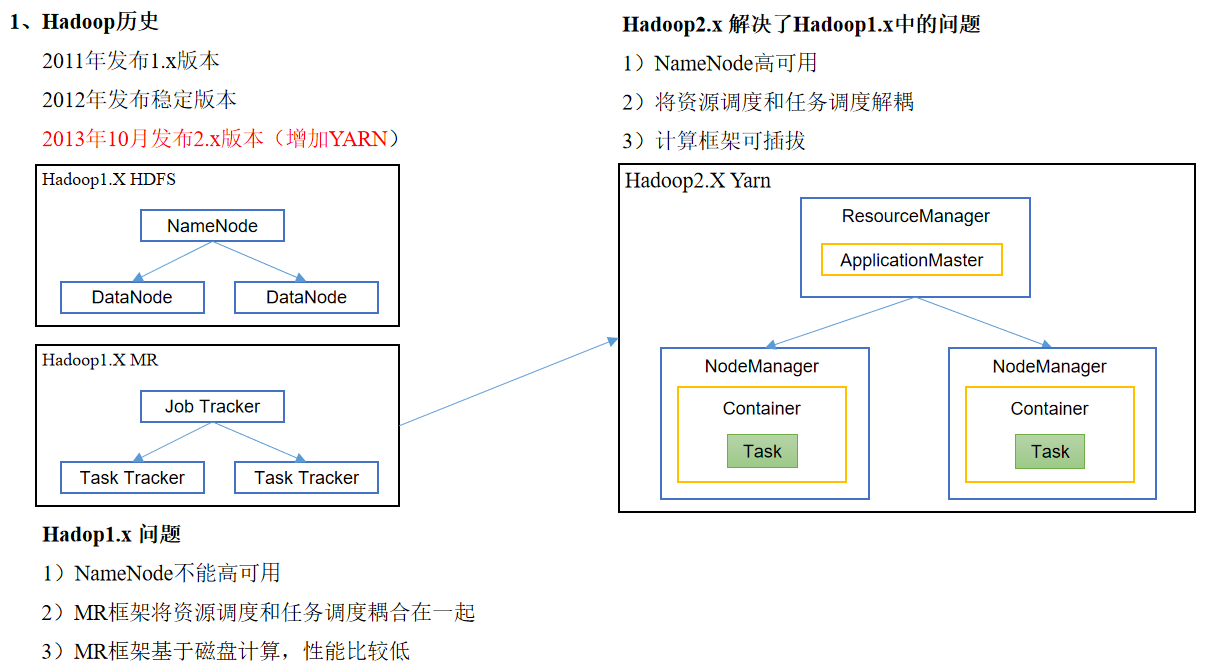
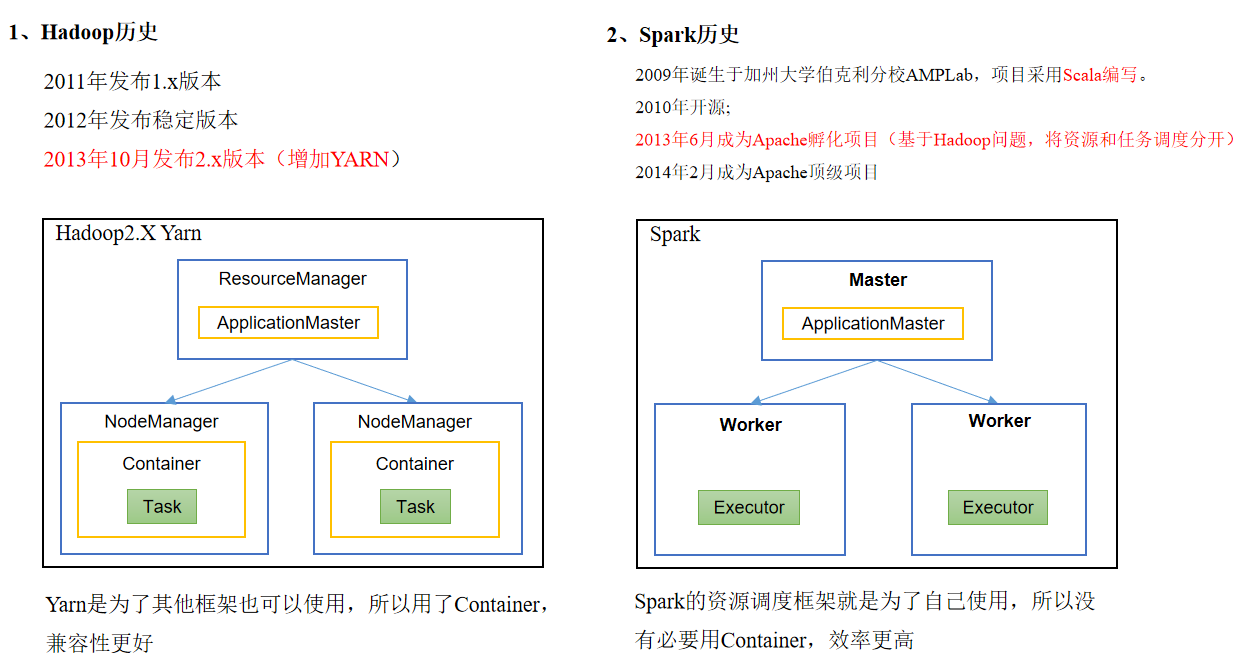
hadoop vs. version history
spark comparison version history
spark vs. MapReduce framework
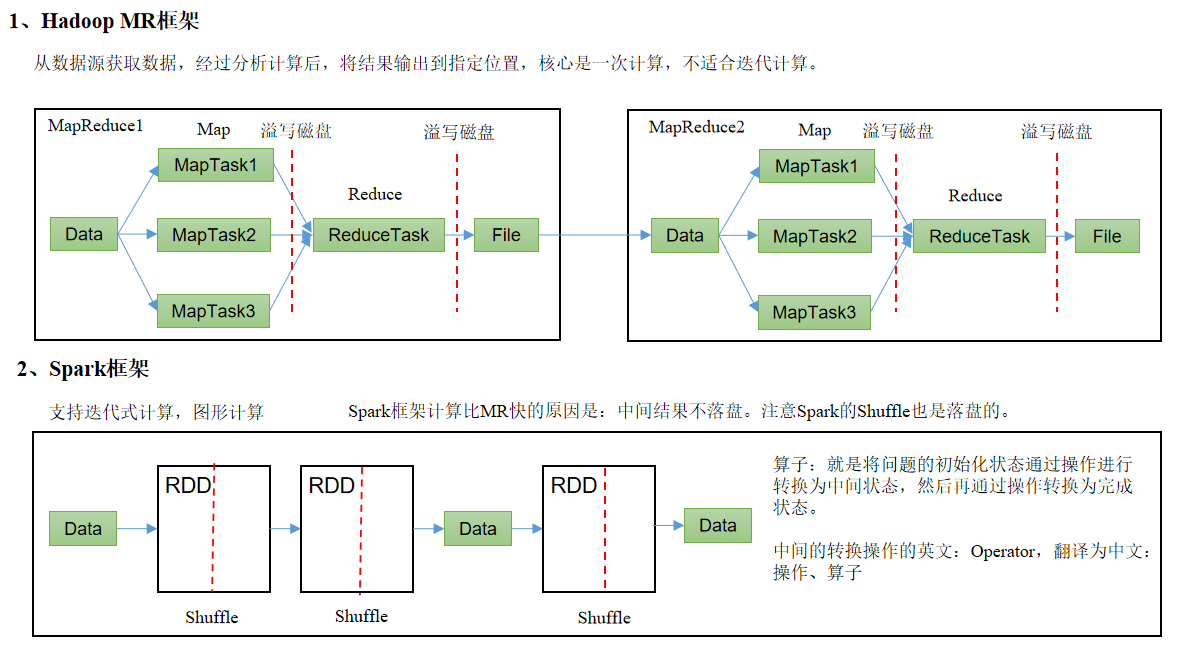
RDD: Abstract elastic distributed datasets
spark built-in module
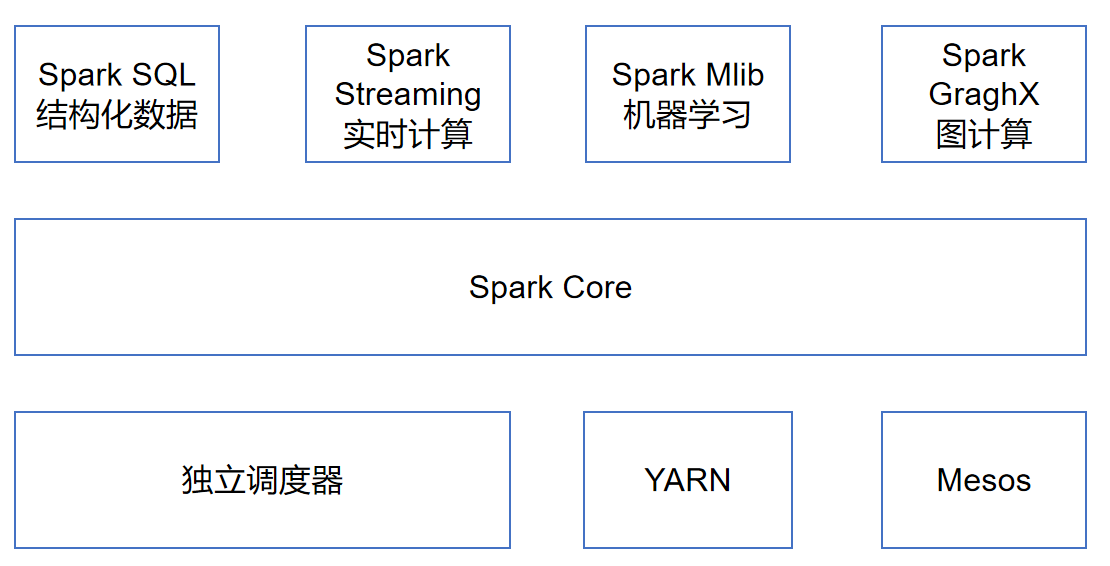
Spark Core: it realizes the basic functions of spark, including task scheduling, memory management, error recovery, interaction with storage system and other modules. Spark Core also contains API definitions for Resilient Distributed DataSet (RDD).
Spark SQL: a package used by spark to manipulate structured data. Through spark SQL, we can use SQL or HQL of Apache Hive version to query data. Spark SQL supports a variety of data sources, such as Hive table, Parquet and JSON.
Spark Streaming: a component provided by spark for streaming real-time data. The API used to operate data flow is provided and highly corresponds to the RDD API in Spark Core.
Common features of the machine learning library: mllib. It includes classification, regression, clustering, collaborative filtering, etc. it also provides additional support functions such as model evaluation and data import.
Spark GraphX: a component mainly used for graph parallel computing and graph mining system.
Cluster manager: Spark is designed to efficiently scale computing from one computing node to thousands of computing nodes. In order to meet such requirements and obtain maximum flexibility, Spark supports running on various cluster managers, including Hadoop YARN, Apache Mesos, and a simple scheduler built in Spark, called independent scheduler.
spark features
Fast running speed:
Compared with Hadoop MapReduce, Spark's memory based operation is more than 100 times faster, and the hard disk based operation is also more than 10 times faster. Spark implements an efficient DAG execution engine that can efficiently process data streams based on memory. The intermediate result of the calculation is in memory
Good usability:
Spark supports API s of Java, Python and Scala. It also supports more than 80 advanced algorithms, enabling users to quickly build different applications. Moreover, spark supports interactive Python and Scala shells. It is very convenient to use spark clusters in these shells to verify the solution to the problem
Strong versatility:
Spark provides a unified solution. Spark can be used for interactive query (Spark SQL), real-time streaming (Spark Streaming), machine learning (Spark MLlib) and graph calculation (GraphX). These different types of processing can be used seamlessly in the same application. It reduces the human cost of development and maintenance and the material cost of deploying the platform
High compatibility:
Spark can be easily integrated with other open source products. For example, spark can use Hadoop's YARN and Apache Mesos as its resource management and scheduler, and can process all Hadoop supported data, including HDFS, HBase, etc. This is particularly important for users who have deployed Hadoop clusters, because they can use the powerful processing power of spark without any data migration
spark deployment
Spark operation mode
Spark cluster deployment is generally divided into two modes: stand-alone mode and cluster mode
Most distributed frameworks support stand-alone mode, which is convenient for developers to debug the running environment of the framework. However, in a production environment, stand-alone mode is not used. Therefore, Spark clusters are deployed directly in the cluster mode.
The deployment modes currently supported by Spark are listed in detail below.
Local mode
Deploying a single spark service locally is more suitable for simply understanding the spark directory structure, getting familiar with configuration files, and simply running demo examples and other debugging scenarios.
Standalone mode
Spark's own task scheduling mode allows multiple spark machines to schedule tasks internally, but only spark's own task scheduling
YARN mode
Spark uses the YARN component of Hadoop for resource and task scheduling. In a real sense, spark cooperates with external docking.
Mesos mode
Spark uses the Mesos platform to schedule resources and tasks. Spark client directly connects to Mesos; There is no need to build an additional spark cluster.
(Mesos is a cluster management platform. It can be understood as the kernel of a distributed system, which is responsible for the allocation of cluster resources. The resources here refer to CPU resources, memory resources, storage resources, network resources, etc. in Mesos, Spark, Storm, Hadoop, Marathon and other frameworks can be run.)
spark official website
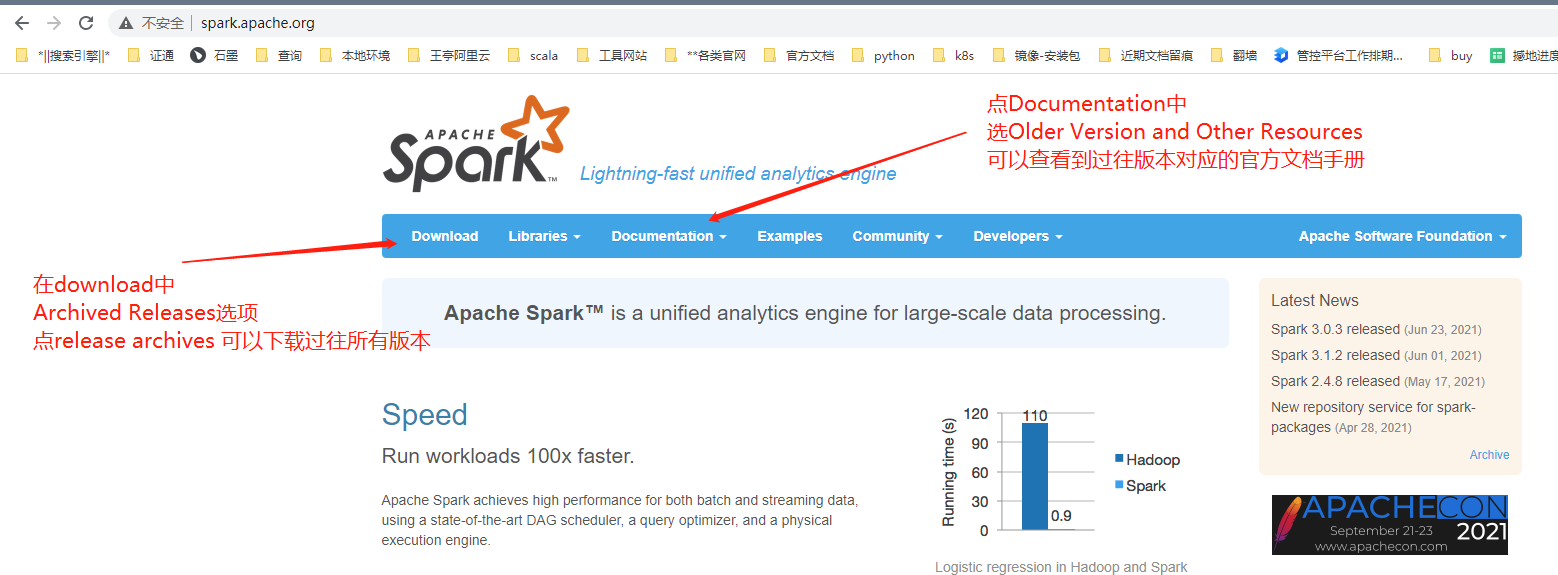
Introduction to Local mode deployment
Download the installation package: Official Website - > Download - > release Archives - > spark-2.1.1 - > spark-2.1.1-bin-hadoop 2 7.tgz Download
Unzip the Spark installation package
wangting@ops01:/opt/software >tar -xf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
Directory rename
wangting@ops01:/opt/software >cd /opt/module/ wangting@ops01:/opt/module >mv spark-2.1.1-bin-hadoop2.7 spark-local
directory structure
wangting@ops01:/opt/module >cd spark-local/ wangting@ops01:/opt/module/spark-local > wangting@ops01:/opt/module/spark-local >ll total 104 drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 bin drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 conf drwxr-xr-x 5 wangting wangting 4096 Apr 26 2017 data drwxr-xr-x 4 wangting wangting 4096 Apr 26 2017 examples drwxr-xr-x 2 wangting wangting 12288 Apr 26 2017 jars -rw-r--r-- 1 wangting wangting 17811 Apr 26 2017 LICENSE drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 licenses -rw-r--r-- 1 wangting wangting 24645 Apr 26 2017 NOTICE drwxr-xr-x 8 wangting wangting 4096 Apr 26 2017 python drwxr-xr-x 3 wangting wangting 4096 Apr 26 2017 R -rw-r--r-- 1 wangting wangting 3817 Apr 26 2017 README.md -rw-r--r-- 1 wangting wangting 128 Apr 26 2017 RELEASE drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 sbin drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 yarn
The official demo example calculates Pi
wangting@ops01:/opt/module/spark-local >bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[4] /opt/module/spark-local/examples/jars/spark-examples_2.11-2.1.1.jar 20 Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 21/07/22 10:52:01 INFO SparkContext: Running Spark version 2.1.1 21/07/22 10:52:02 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 21/07/22 10:52:02 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-cee9f744-b8dd-4c75-83be-3884f3b4425b 21/07/22 10:52:02 INFO MemoryStore: MemoryStore started with capacity 366.3 MB 21/07/22 10:52:02 INFO SparkEnv: Registering OutputCommitCoordinator 21/07/22 10:52:02 INFO Utils: Successfully started service 'SparkUI' on port 4040. 21/07/22 10:52:02 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://11.8.37.50:4040 21/07/22 10:52:02 INFO SparkContext: Added JAR file:/opt/module/spark-local/examples/jars/spark-examples_2.11-2.1.1.jar at spark://11.8.37.50:46388/jars/spark-examples_2.11-2.1.1.jar with timestamp 1626922322910 21/07/22 10:52:02 INFO Executor: Starting executor ID driver on host localhost 21/07/22 10:52:04 INFO Executor: Fetching spark://11.8.37.50:46388/jars/spark-examples_2.11-2.1.1.jar with timestamp 1626922322910 21/07/22 10:52:04 INFO TransportClientFactory: Successfully created connection to /11.8.37.50:46388 after 28 ms (0 ms spent in bootstraps) 21/07/22 10:52:04 INFO Utils: Fetching spark://11.8.37.50:46388/jars/spark-examples_2.11-2.1.1.jar to /tmp/spark-86795505-2fa5-4e6e-9331-f26233e462b2/userFiles-174c50ee-3aff-4523-a89b-17910dcd467e/fetchFileTemp632487868763480019.tmp 21/07/22 10:52:04 INFO Executor: Adding file:/tmp/spark-86795505-2fa5-4e6e-9331-f26233e462b2/userFiles-174c50ee-3aff-4523-a89b-17910dcd467e/spark-examples_2.11-2.1.1.jar to class loader 21/07/22 10:52:05 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.386012 s Pi is roughly 3.140143570071785 # < < < < < < result output 21/07/22 10:52:05 INFO SparkUI: Stopped Spark web UI at http://11.8.37.50:4040 21/07/22 10:52:05 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 21/07/22 10:52:05 INFO MemoryStore: MemoryStore cleared 21/07/22 10:52:05 INFO BlockManager: BlockManager stopped 21/07/22 10:52:05 INFO BlockManagerMaster: BlockManagerMaster stopped 21/07/22 10:52:05 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 21/07/22 10:52:05 INFO SparkContext: Successfully stopped SparkContext 21/07/22 10:52:05 INFO ShutdownHookManager: Shutdown hook called 21/07/22 10:52:05 INFO ShutdownHookManager: Deleting directory /tmp/spark-86795505-2fa5-4e6e-9331-f26233e462b2
bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[4] /opt/module/spark-local/examples/jars/spark-examples_2.11-2.1.1.jar 20
– class: indicates the main class of the jar package to execute
–master local[2]
(1) local: if the number of threads is not specified, all calculations run in one thread without any parallel calculation
(2) local[K]: Specifies that K cores are used to run calculations. For example, local[4] runs 4 cores to execute calculations
(3) local [*]: automatically set the number of threads according to the maximum number of CPU cores. For example, the CPU has 4 cores, and Spark helps you automatically set 4 threads for computing
spark-examples_2.11-2.1.1.jar: the jar package to run
20: Input parameters to run the program (the number of times to calculate pi. The more times to calculate pi, the higher the accuracy. Here is only an application example to define parameters)
Official wordcount example
wordcount will realize the total number of words in multiple files and count the word frequency
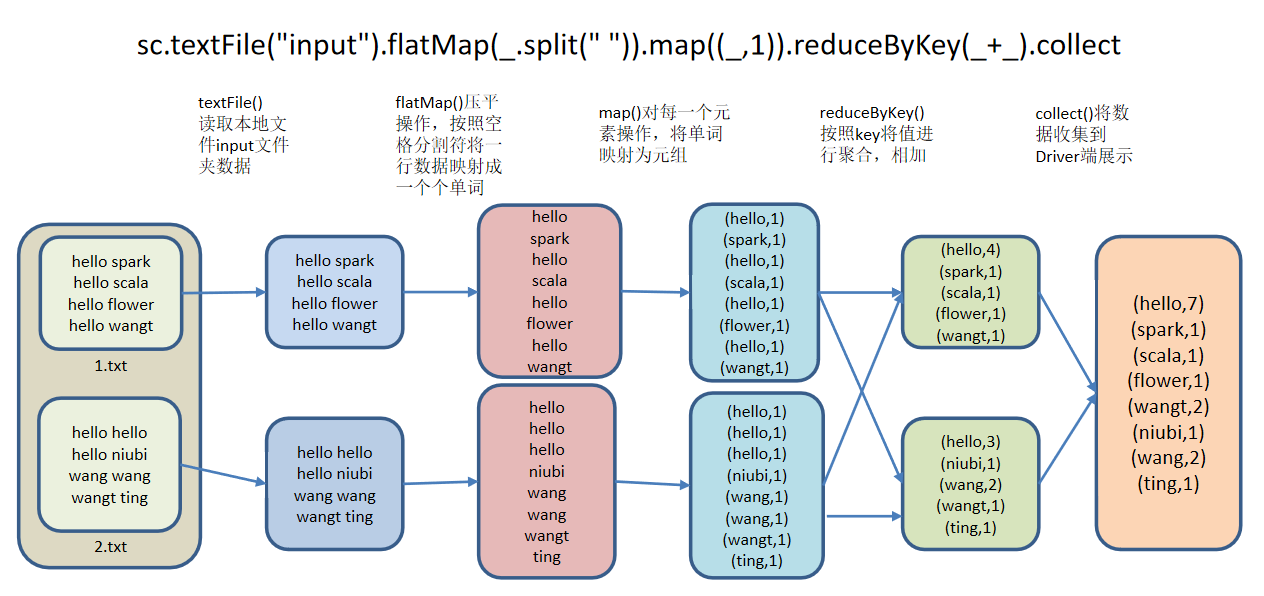
Create experiment directory and files
wangting@ops01:/opt/module/spark-local >mkdir input wangting@ops01:/opt/module/spark-local >cd input/ wangting@ops01:/opt/module/spark-local/input >echo "hello spark" >> 1.txt wangting@ops01:/opt/module/spark-local/input >echo "hello scala" >> 1.txt wangting@ops01:/opt/module/spark-local/input >echo "hello flower" >> 1.txt wangting@ops01:/opt/module/spark-local/input >echo "hello wangt" >> 1.txt wangting@ops01:/opt/module/spark-local/input >echo "hello hello" >> 2.txt wangting@ops01:/opt/module/spark-local/input >echo "hello niubi" >> 2.txt wangting@ops01:/opt/module/spark-local/input >echo "wang wang" >> 2.txt wangting@ops01:/opt/module/spark-local/input >echo "wangt ting" >> 2.txt wangting@ops01:/opt/module/spark-local/input >cat 1.txt hello spark hello scala hello flower hello wangt wangting@ops01:/opt/module/spark-local/input >cat 2.txt hello hello hello niubi wang wang wangt ting
Enter the spark shell command line
wangting@ops01:/opt/module/spark-local/input >cd ..
wangting@ops01:/opt/module/spark-local >bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/07/22 11:01:03 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
21/07/22 11:01:09 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
21/07/22 11:01:09 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
21/07/22 11:01:10 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://11.8.37.50:4040
Spark context available as 'sc' (master = local[*], app id = local-1626922864098).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
[note]:
- Spark submit and spark shell are just two ways of task execution
- Spark submit is to upload jar s to the cluster and execute spark tasks;
- Spark shell, which is equivalent to a command-line tool, is also an Application;
- When the spark shell is opened, a SparkSubmit process will be started. The port is 4040, which is the port number of the weiUI of the application. If the command line remains connected, the process port will survive. If the command line exits, the process port will also be closed.
Execute wordcount task
scala> sc.textFile("/opt/module/spark-local/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((ting,1), (scala,1), (hello,7), (flower,1), (spark,1), (niubi,1), (wangt,2), (wang,2))
[description]: (tab can be completed during command line operation)
def textFile(path: String,minPartitions: Int): org.apache.spark.rdd.RDD[String]
Textfile() - > read local file input folder data
def flatMap[U](f: String => TraversableOnce[U])(implicit evidence$4: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U]
Flatmap() - > flatten operation. Map a row of data into words according to the space separator
def map[U](f: String => U)(implicit evidence$3: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U]
Map() - > operate on each element to map words into tuples
def reduceByKey(func: (Int, Int) => Int): org.apache.spark.rdd.RDD[(String, Int)]
Reducebykey() - > aggregate and add values by key
def collect[U](f: PartialFunction[(String, Int),U](implicit evidence$29: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U] def collect():Array[(String,Int)]
Collect() - > collect data to the Driver side for display
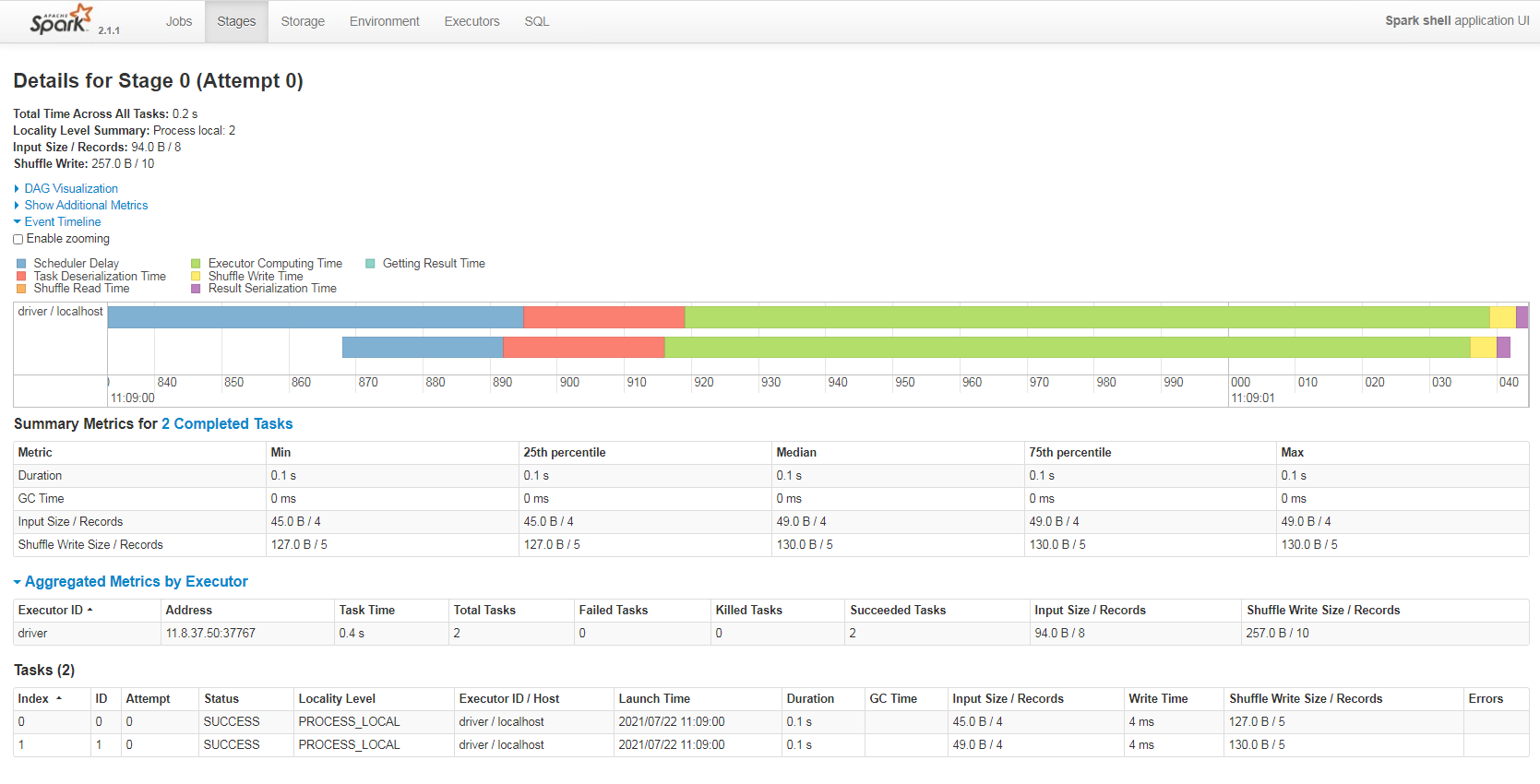
Page view
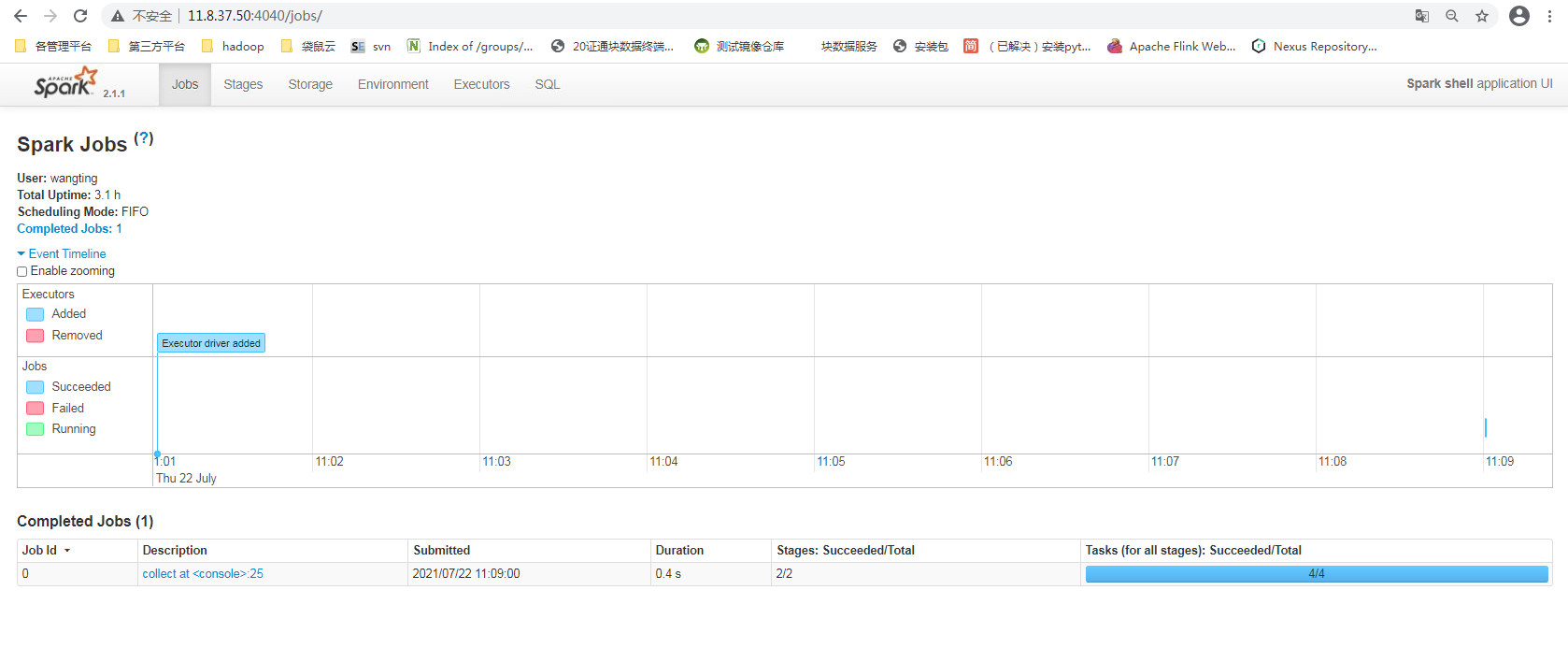
Click the corresponding job to see more detailed information
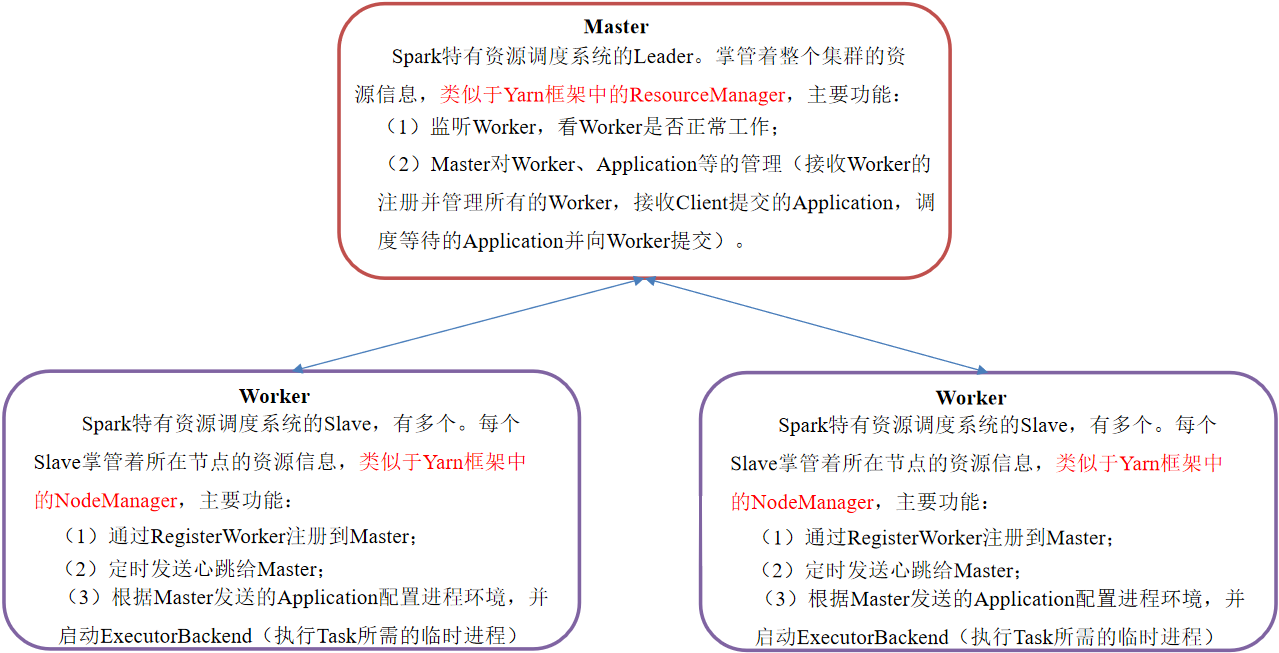
Cluster role introduction
Master & Worker
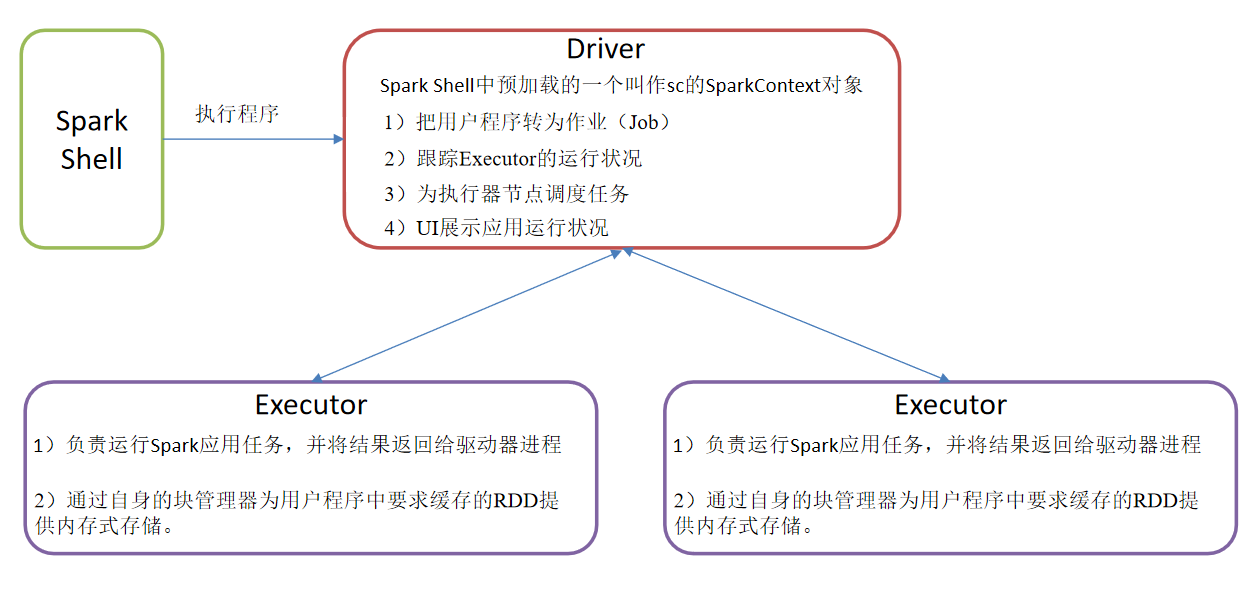
Driver & Executor
[note]:
-
Master and Worker are the daemons of Spark, that is, the processes necessary for Spark to run normally in a specific mode.
-
Driver and Executor are temporary programs that will only be started when specific tasks are submitted to Spark cluster
Introduction to deployment and use of Standalone mode
Standalone mode is Spark's own resource mobilization engine. It builds a Spark cluster composed of Master + Slave, and Spark runs in the cluster.
This should be distinguished from the Standalone in Hadoop. Here, Standalone means that Spark is used only to build a cluster without the help of other frameworks. It's relative to Yarn and Mesos
Machine planning (3 sets):
ops01 11.8.37.50 master|worker
ops02 11.8.36.63 worker
ops03 11.8.36.76 worker
ops04 11.8.36.86 worker
[note]: configure the information in the / etc/hosts host resolution file
wangting@ops01:/opt/module >cat /etc/hosts 127.0.0.1 ydt-cisp-ops01 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 11.16.0.176 rancher.mydomain.com 11.8.38.123 www.tongtongcf.com 11.8.37.50 ops01 11.8.36.63 ops02 11.8.36.76 ops03 11.8.38.86 ops04 11.8.38.82 jpserver ydt-dmcp-jpserver wangting@ops01:/opt/module >
Unzip the installation package
wangting@ops01:/opt/software >tar -xf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
Directory rename
wangting@ops01:/opt/software >mv /opt/module/spark-2.1.1-bin-hadoop2.7 /opt/module/spark-standalone
Profile directory
wangting@ops01:/opt/software >cd /opt/module/spark-standalone/conf/ wangting@ops01:/opt/module/spark-standalone/conf > wangting@ops01:/opt/module/spark-standalone/conf >ll total 32 -rw-r--r-- 1 wangting wangting 987 Apr 26 2017 docker.properties.template -rw-r--r-- 1 wangting wangting 1105 Apr 26 2017 fairscheduler.xml.template -rw-r--r-- 1 wangting wangting 2025 Apr 26 2017 log4j.properties.template -rw-r--r-- 1 wangting wangting 7313 Apr 26 2017 metrics.properties.template -rw-r--r-- 1 wangting wangting 865 Apr 26 2017 slaves.template -rw-r--r-- 1 wangting wangting 1292 Apr 26 2017 spark-defaults.conf.template -rwxr-xr-x 1 wangting wangting 3960 Apr 26 2017 spark-env.sh.template
Modify the slave configuration definition cluster
wangting@ops01:/opt/module/spark-standalone/conf >mv slaves.template slaves wangting@ops01:/opt/module/spark-standalone/conf >vim slaves # limitations under the License. # # A Spark Worker will be started on each of the machines listed below. ops01 ops02 ops03 ops04
Modify spark env SH file, add master node
wangting@ops01:/opt/module/spark-standalone/conf >mv spark-env.sh.template spark-env.sh wangting@ops01:/opt/module/spark-standalone/conf >vim spark-env.sh SPARK_MASTER_HOST=ops01 SPARK_MASTER_PORT=7077
Distribute the spark standalone directory to each node
wangting@ops01:/opt/module >scp -r spark-standalone ops02:/opt/module/ wangting@ops01:/opt/module >scp -r spark-standalone ops03:/opt/module/ wangting@ops01:/opt/module >scp -r spark-standalone ops04:/opt/module/
Check port 8080 and spark process
# Starting spark shell will open port 8080 - > front end page at the same time; So let's see if it's occupied wangting@ops01:/home/wangting >sudo netstat -tnlpu|grep 8080 wangting@ops01:/home/wangting > wangting@ops01:/home/wangting >jps -l | grep spark wangting@ops01:/home/wangting >
Start spark standalone cluster
wangting@ops01:/home/wangting >cd /opt/module/spark-standalone/ wangting@ops01:/opt/module/spark-standalone >sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.master.Master-1-ops01.out ops04: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops04.out ops03: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops03.out ops01: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops01.out ops02: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops02.out ops04: failed to launch: nice -n 0 /opt/module/spark-standalone/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://ops01:7077 ops04: JAVA_HOME is not set ops04: full log in /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops04.out wangting@ops01:/opt/module/spark-standalone > wangting@ops01:/opt/module/spark-standalone >sudo netstat -tnlpu|grep 8080 tcp6 0 0 :::8080 :::* LISTEN 57689/java wangting@ops01:/opt/module/spark-standalone >jps -l | grep spark 57809 org.apache.spark.deploy.worker.Worker 57689 org.apache.spark.deploy.master.Master wangting@ops01:/opt/module/spark-standalone >
Processing JAVA_HOME is not set
Although the service is started successfully, when starting the cluster, the prompt on ops04 is: ops04: JAVA_HOME is not set
Switch to ops04 server
wangting@ops04:/opt/module/spark-standalone >echo $JAVA_HOME /usr/java8_64/jdk1.8.0_101 wangting@ops04:/opt/module/spark-standalone >vim sbin/spark-config.sh export JAVA_HOME=/usr/java8_64/jdk1.8.0_101
Switch back to master: ops01 restart the service
wangting@ops01:/opt/module/spark-standalone >sbin/stop-all.sh ops01: stopping org.apache.spark.deploy.worker.Worker ops03: stopping org.apache.spark.deploy.worker.Worker ops04: no org.apache.spark.deploy.worker.Worker to stop ops02: stopping org.apache.spark.deploy.worker.Worker stopping org.apache.spark.deploy.master.Master wangting@ops01:/opt/module/spark-standalone > wangting@ops01:/opt/module/spark-standalone >sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.master.Master-1-ops01.out ops01: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops01.out ops03: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops03.out ops04: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops04.out ops02: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops02.out wangting@ops01:/opt/module/spark-standalone >
The previous prompt has been handled
Browser view interface
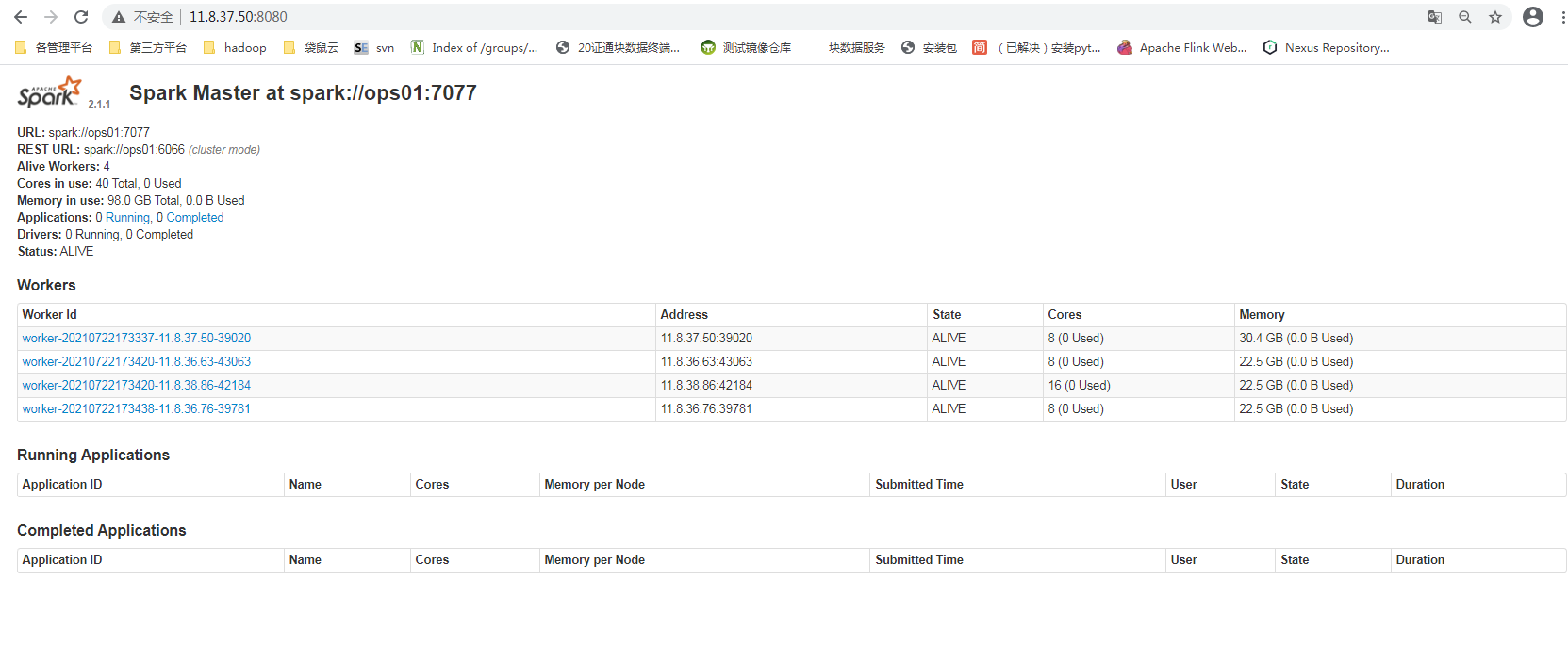
The official demo example calculates Pi
wangting@ops01:/opt/module/spark-standalone >bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://ops01:7077 /opt/module/spark-standalone/examples/jars/spark-examples_2.11-2.1.1.jar 20 Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 21/07/23 15:13:39 INFO SparkContext: Running Spark version 2.1.1 21/07/23 15:13:39 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 21/07/23 15:13:39 INFO SecurityManager: Changing view acls to: wangting 21/07/23 15:13:39 INFO SecurityManager: Changing modify acls to: wangting 21/07/23 15:13:39 INFO SecurityManager: Changing view acls groups to: 21/07/23 15:13:39 INFO SecurityManager: Changing modify acls groups to: 21/07/23 15:13:44 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 21/07/23 15:13:44 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 2.824153 s Pi is roughly 3.1423635711817854 # < < output results 21/07/23 15:13:44 INFO SparkUI: Stopped Spark web UI at http://11.8.37.50:4040 21/07/23 15:13:44 INFO StandaloneSchedulerBackend: Shutting down all executors 21/07/23 15:13:44 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down 21/07/23 15:13:44 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 21/07/23 15:13:44 INFO MemoryStore: MemoryStore cleared 21/07/23 15:13:44 INFO BlockManager: BlockManager stopped 21/07/23 15:13:44 INFO BlockManagerMaster: BlockManagerMaster stopped 21/07/23 15:13:44 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 21/07/23 15:13:44 INFO SparkContext: Successfully stopped SparkContext 21/07/23 15:13:44 INFO ShutdownHookManager: Shutdown hook called 21/07/23 15:13:44 INFO ShutdownHookManager: Deleting directory /tmp/spark-6547bdc7-5117-4c44-8f14-4328fa38ace6
Page view task status
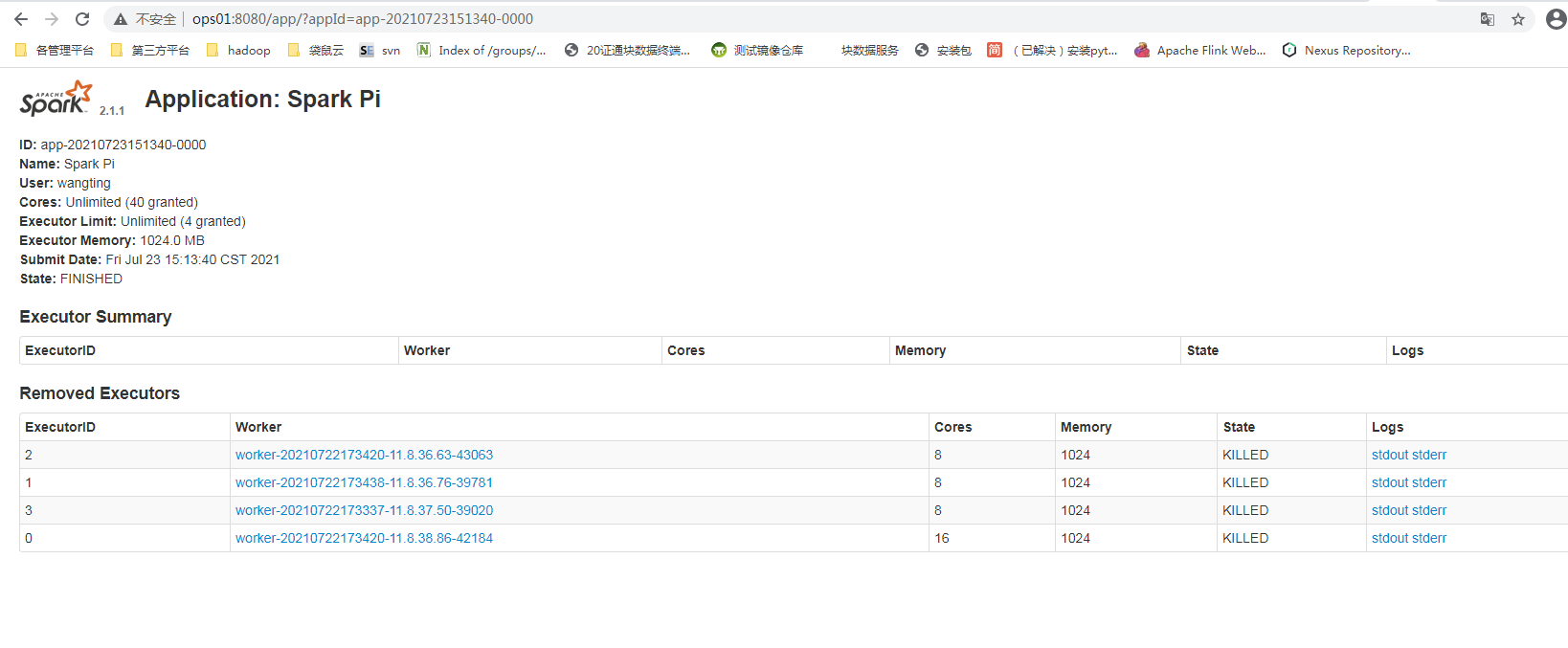
Specify resources to perform tasks
wangting@ops01:/opt/module/spark-standalone >bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://ops01:7077 --executor-memory 8G --total-executor-cores 4 /opt/module/spark-standalone/examples/jars/spark-examples_2.11-2.1.1.jar 20 wangting@ops01:/opt/module/spark-standalone >
Page to view new task status resource changes
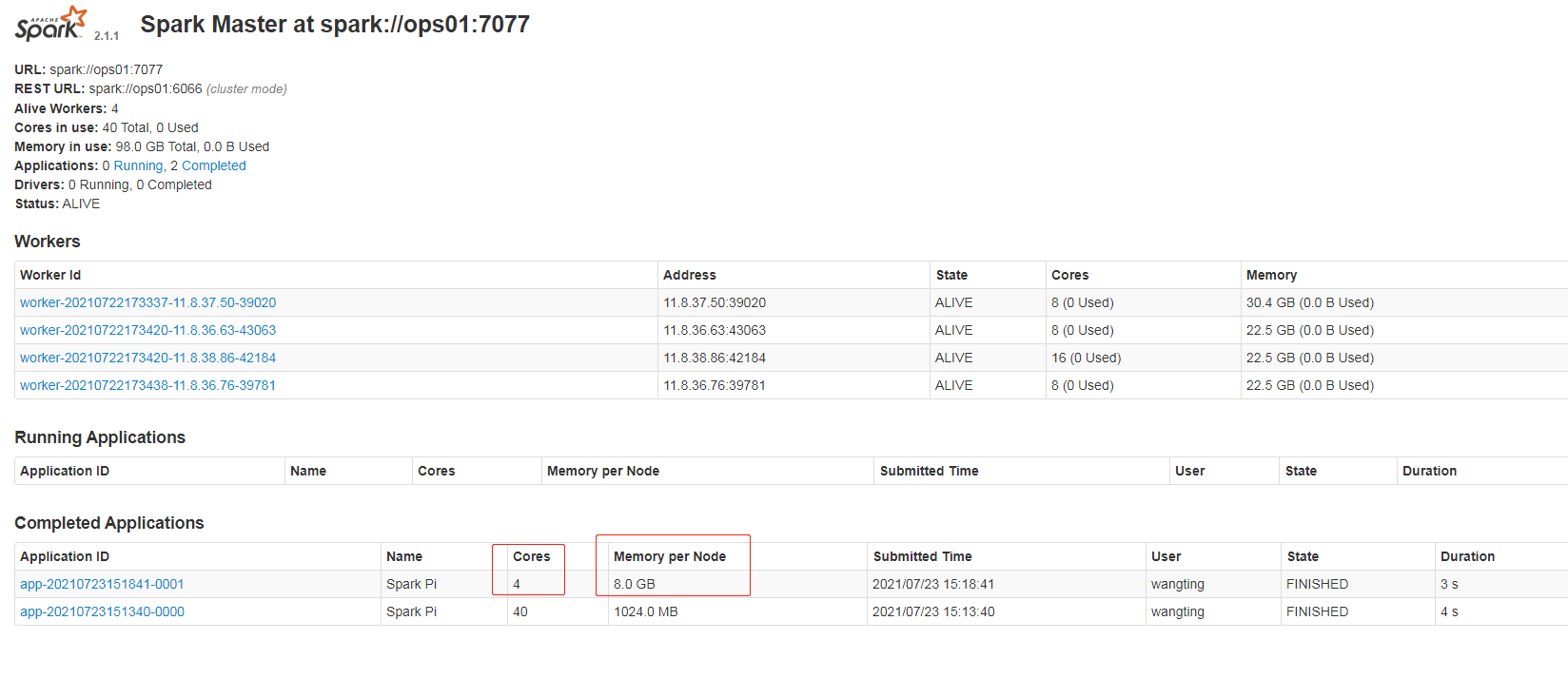
Configure history service
[note]: the hdfs environment is installed by default. If you don't need to build and deploy it first, you can use the local version only for experimental testing; If you build a cluster, you already have an hdfs cluster environment by default.
Since the running status of the historical task cannot be seen on the Hadoop 102:4040 page after the spark shell is stopped, the historical server is configured to record the running status of the task during development
wangting@ops01:/opt/module/spark-standalone >cd conf/ # Modify profile wangting@ops01:/opt/module/spark-standalone/conf >mv spark-defaults.conf.template spark-defaults.conf wangting@ops01:/opt/module/spark-standalone/conf > wangting@ops01:/opt/module/spark-standalone/conf >vim spark-defaults.conf # spark.eventLog.enabled true spark.eventLog.dir hdfs://ops01:8020/directory # Add / directory directory on hdfs wangting@ops01:/opt/module/spark-standalone/conf >hdfs dfs -ls / 2021-07-23 15:24:45,730 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 15 items drwxr-xr-x - wangting supergroup 0 2021-03-17 11:44 /20210317 drwxr-xr-x - wangting supergroup 0 2021-03-19 10:51 /20210319 drwxr-xr-x - wangting supergroup 0 2021-04-24 17:05 /flume -rw-r--r-- 3 wangting supergroup 338075860 2021-03-12 11:50 /hadoop-3.1.3.tar.gz drwxr-xr-x - wangting supergroup 0 2021-05-13 15:31 /hbase drwxr-xr-x - wangting supergroup 0 2021-05-26 16:56 /origin_data drwxr-xr-x - wangting supergroup 0 2021-06-10 10:31 /spark-history drwxr-xr-x - wangting supergroup 0 2021-06-10 10:39 /spark-jars drwxr-xr-x - wangting supergroup 0 2021-06-10 11:11 /student drwxr-xr-x - wangting supergroup 0 2021-04-04 11:07 /test.db drwxr-xr-x - wangting supergroup 0 2021-03-19 11:14 /testgetmerge drwxr-xr-x - wangting supergroup 0 2021-04-10 16:23 /tez drwx------ - wangting supergroup 0 2021-04-02 15:14 /tmp drwxr-xr-x - wangting supergroup 0 2021-04-02 15:25 /user drwxr-xr-x - wangting supergroup 0 2021-06-10 11:43 /warehouse wangting@ops01:/opt/module/spark-standalone/conf >hdfs dfs -mkdir /directory 2021-07-23 15:25:14,573 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS wangting@ops01:/opt/module/spark-standalone/conf >hdfs dfs -ls / | grep directory drwxr-xr-x - wangting supergroup 0 2021-07-23 15:25 /directory # Modify spark env configuration wangting@ops01:/opt/module/spark-standalone/conf >vim spark-env.sh export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://ops01:8020/directory -Dspark.history.retainedApplications=30" wangting@ops01:/opt/module/spark-standalone/conf > # Distribution profile wangting@ops01:/opt/module/spark-standalone/conf >scp spark-env.sh spark-defaults.conf ops02:/opt/module/spark-standalone/conf/ wangting@ops01:/opt/module/spark-standalone/conf >scp spark-env.sh spark-defaults.conf ops03:/opt/module/spark-standalone/conf/ wangting@ops01:/opt/module/spark-standalone/conf >scp spark-env.sh spark-defaults.conf ops04:/opt/module/spark-standalone/conf/ # Start history service wangting@ops01:/opt/module/spark-standalone >sbin/start-history-server.sh starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.history.HistoryServer-1-ops01.out wangting@ops01:/opt/module/spark-standalone > # Perform the task again wangting@ops01:/opt/module/spark-standalone >bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://ops01:7077 --executor-memory 8G --total-executor-cores 4 /opt/module/spark-standalone/examples/jars/spark-examples_2.11-2.1.1.jar 20
Access the historical task page via ip:18080
http://11.8.37.50:18080/
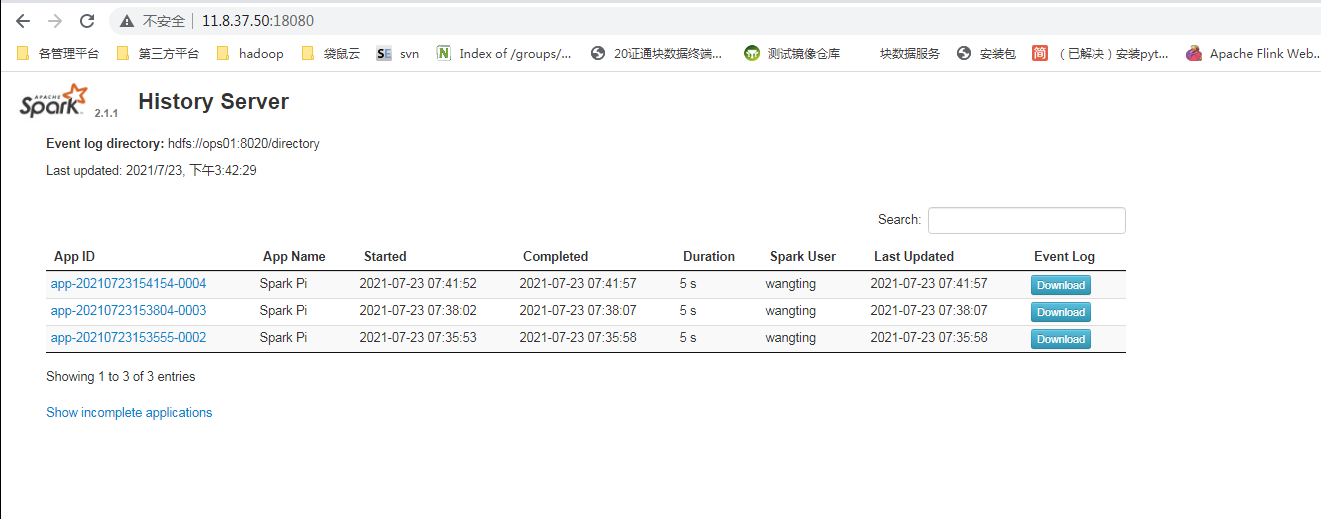
Because the standalone here is only used for experiments, and the high availability related operations are not considered temporarily. The high availability is omitted. Generally, the yarn mode is mainly used in the formal environment in China, and the mesos mode is used abroad
Introduction to deployment and use of Yarn mode
In the yarn mode, hadoop clusters, hdfs and yarn clusters need to be prepared in advance; In the previous article, I wrote the deployment method: hadoop introduction deployment document
| service | ops01(8C32G) | ops02(8C24G) | ops03(8C24G) | ops04(8C24G) | version |
|---|---|---|---|---|---|
| Hdfs | NameNode | Datanode | SecondaryNameNode | Datanode | 3.1.3 |
| Yarn | NodeManager | ReSourceManager / NodeManager | NodeManager | NodeManager | 3.1.3 |
| MapReduce | √ JobHistoryServer | √ | √ | √ | 3.1.3 |
Stop spark cluster in Standalone mode
wangting@ops01:/opt/module/spark-standalone >sbin/stop-all.sh ops01: stopping org.apache.spark.deploy.worker.Worker ops04: stopping org.apache.spark.deploy.worker.Worker ops03: stopping org.apache.spark.deploy.worker.Worker ops02: stopping org.apache.spark.deploy.worker.Worker stopping org.apache.spark.deploy.master.Master wangting@ops01:/opt/module/spark-standalone >
Unzip the spark package and rename it
wangting@ops01:/opt/module/spark-standalone >cd /opt/software/ wangting@ops01:/opt/software >tar -xf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/ wangting@ops01:/opt/software >cd /opt/module/ wangting@ops01:/opt/module >mv spark-2.1.1-bin-hadoop2.7 spark-yarn wangting@ops01:/opt/module >cd spark-yarn/
Modify the configuration spark env
Finally, add configuration item: YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop (define Hadoop installation configuration path)
wangting@ops01:/opt/module/spark-yarn >cd conf/ wangting@ops01:/opt/module/spark-yarn/conf >mv spark-env.sh.template spark-env.sh wangting@ops01:/opt/module/spark-yarn/conf >vim spark-env.sh YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
Start HDFS and YARN
Confirm that HDFS and YARN cluster have been started (started under hadoop/sbin /)
In this step, each environment is different, depending on where you deploy locally and on which server the master of each component is located
wangting@ops01:/opt/module/hadoop-3.1.3 >sbin/start-dfs.sh Starting namenodes on [ops01] Starting datanodes Starting secondary namenodes [ops03] wangting@ops02:/opt/module/hadoop-3.1.3/sbin >./start-yarn.sh Starting resourcemanager Starting nodemanagers
The official demo example calculates Pi
wangting@ops01:/opt/module/spark-yarn >bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
/opt/module/spark-yarn/examples/jars/spark-examples_2.11-2.1.1.jar \
20
2021-07-26 11:41:56,166 INFO spark.SparkContext: Running Spark version 2.1.1
2021-07-26 11:41:56,606 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2021-07-26 11:41:56,784 INFO spark.SecurityManager: Changing view acls to: wangting
2021-07-26 11:41:56,784 INFO spark.SecurityManager: Changing modify acls to: wangting
2021-07-26 11:41:56,785 INFO spark.SecurityManager: Changing view acls groups to:
2021-07-26 11:41:56,786 INFO spark.SecurityManager: Changing modify acls groups to:
2021-07-26 11:41:56,786 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(wangting); groups with view permissions: Set(); users with modify permissions: Set(wangting); groups with modify permissions: Set()
2021-07-26 11:42:21,960 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 0.933 s
2021-07-26 11:42:21,965 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.150791 s
Pi is roughly 3.139429569714785 # < < output results
2021-07-26 11:42:21,976 INFO server.ServerConnector: Stopped Spark@61edc883{HTTP/1.1}{0.0.0.0:4040}
2021-07-26 11:42:21,977 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6063d80a{/stages/stage/kill,null,UNAVAILABLE,@Spark}
2021-07-26 11:42:21,977 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5ae76500{/jobs/job/kill,null,UNAVAILABLE,@Spark}
2021-07-26 11:42:22,010 INFO cluster.YarnClientSchedulerBackend: Stopped
2021-07-26 11:42:22,015 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
2021-07-26 11:42:22,027 INFO memory.MemoryStore: MemoryStore cleared
2021-07-26 11:42:22,027 INFO storage.BlockManager: BlockManager stopped
2021-07-26 11:42:22,033 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
2021-07-26 11:42:22,037 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
2021-07-26 11:42:22,038 INFO spark.SparkContext: Successfully stopped SparkContext
2021-07-26 11:42:22,040 INFO util.ShutdownHookManager: Shutdown hook called
2021-07-26 11:42:22,041 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-d3cf3aec-be6f-41f0-a950-4521641e6179
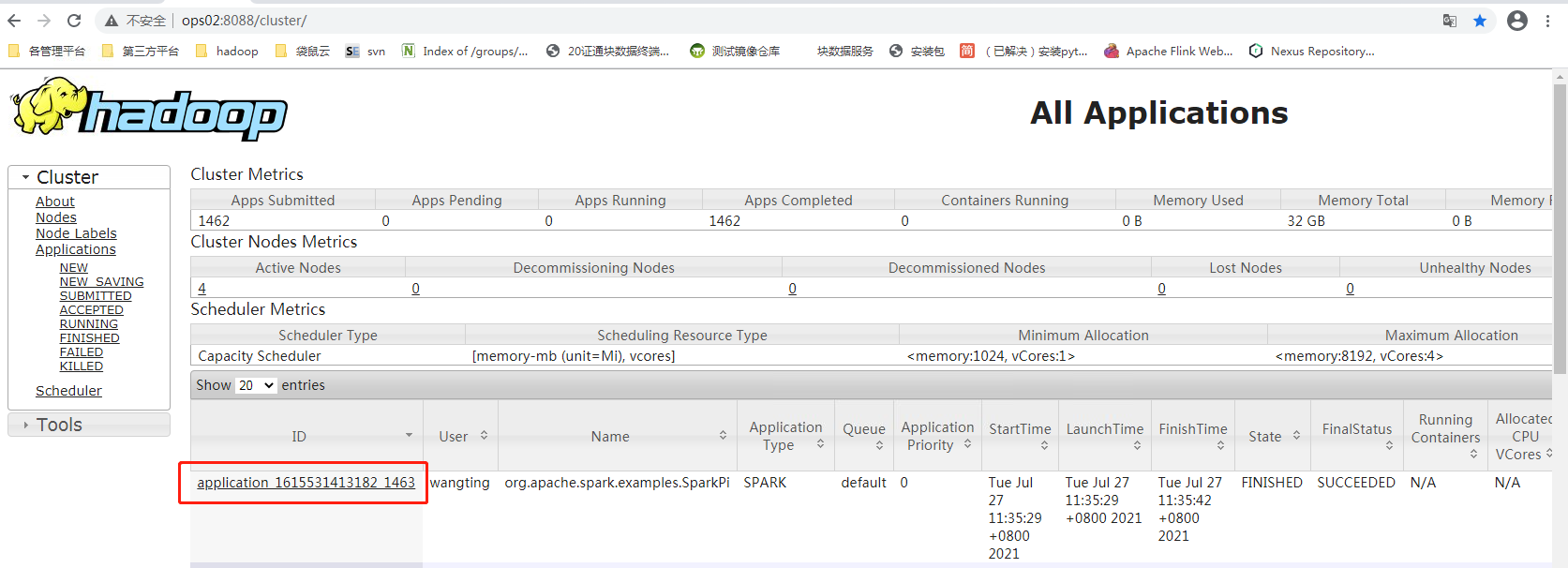
View cluster yarn resourcemanager 8088 port
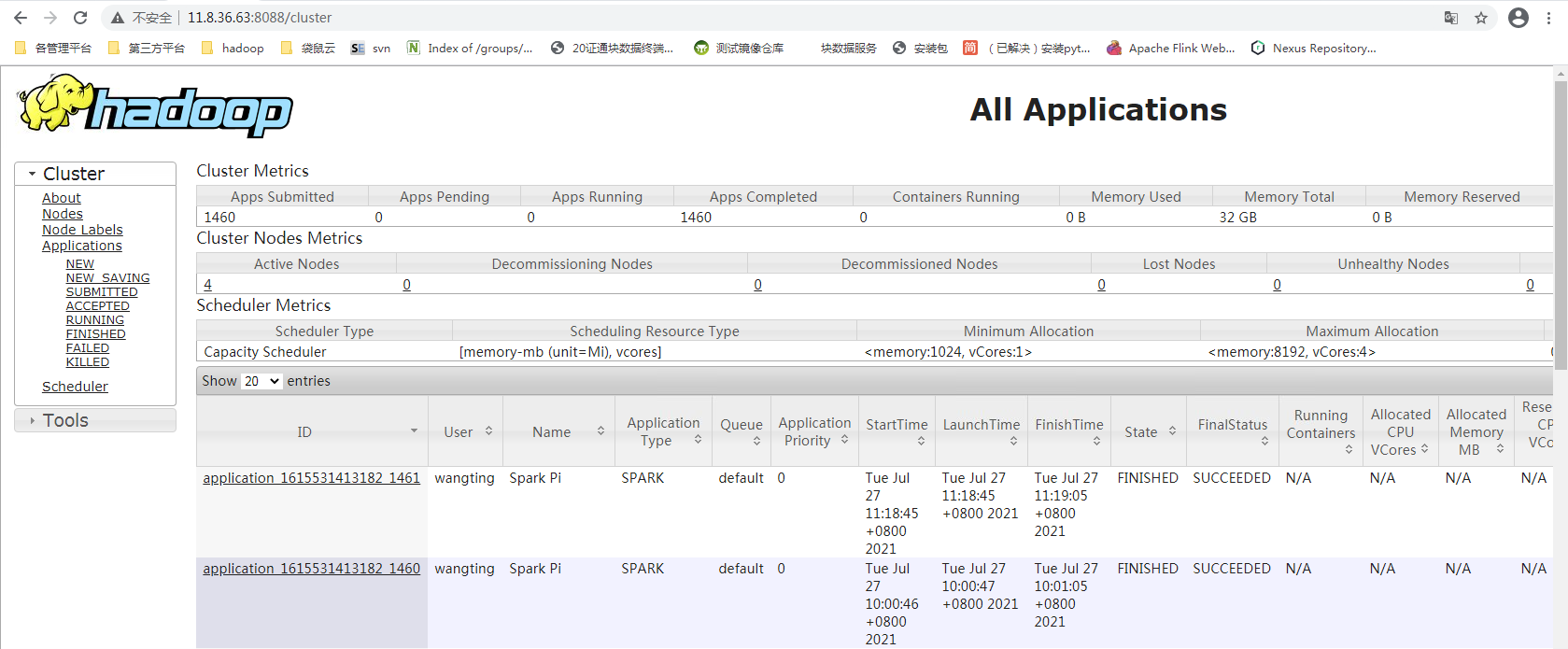
You can see the historical job record
Spark yarn operation process
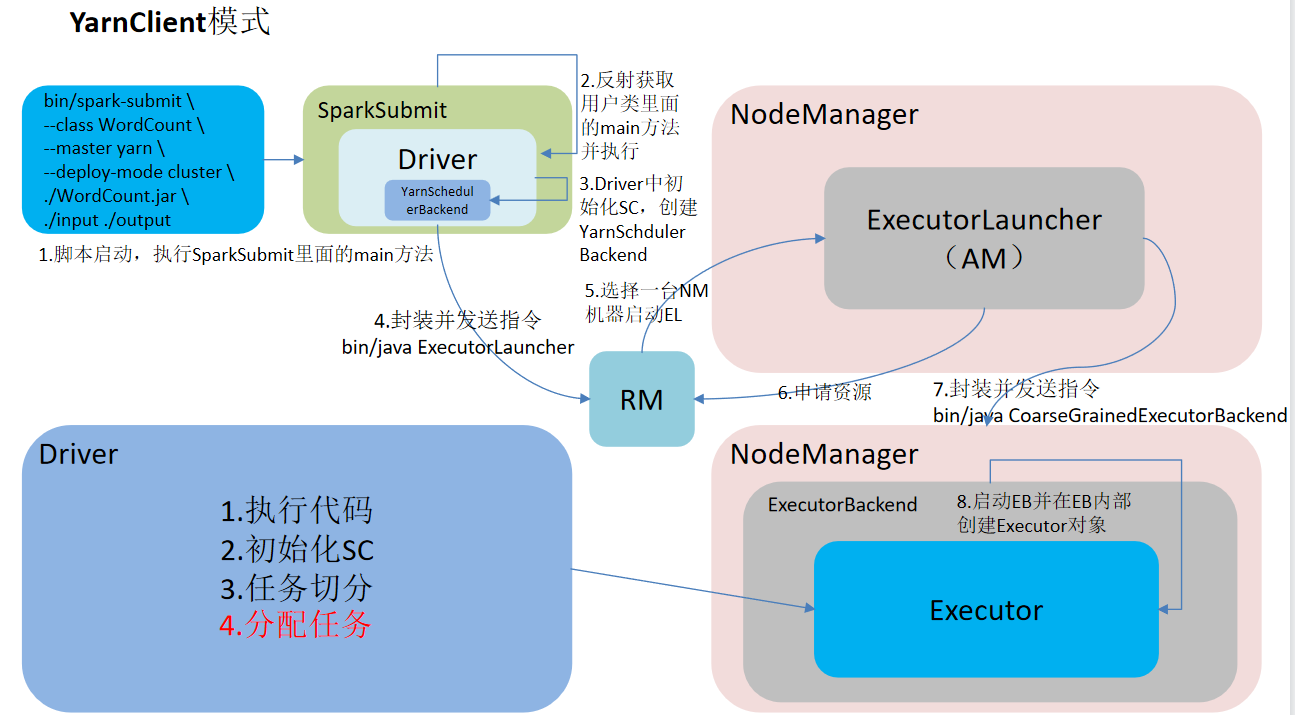
Spark has two modes: yarn client and yarn cluster. The main difference is that the running node of the Driver program.
Yarn client: the Driver program runs on the client and is suitable for interaction and debugging. I hope to see the output of the app immediately.
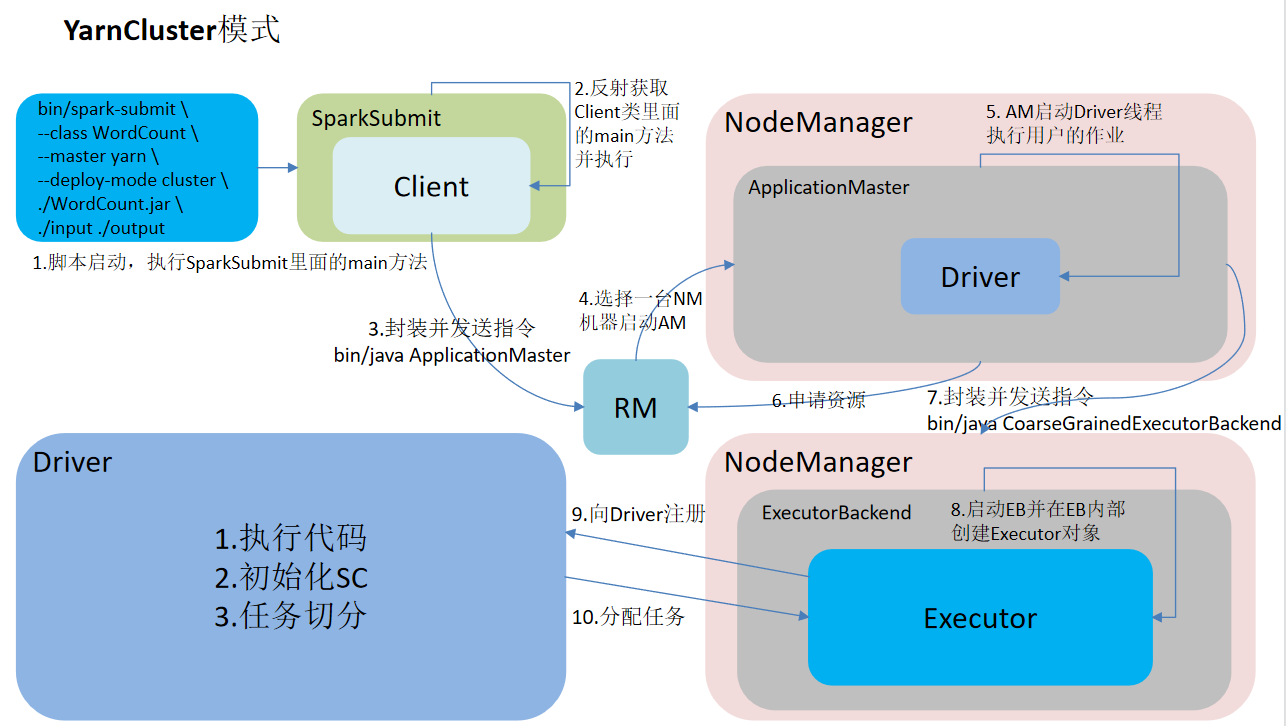
The yarn cluster: Driver program runs on the APPMaster started by the resource manager and is suitable for production environments.
Client mode
wangting@ops01:/opt/module/spark-yarn >bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ ./examples/jars/spark-examples_2.11-2.1.1.jar \ 10
You can directly see the output results on the console
Client mode task flow
Cluster mode
wangting@ops01:/opt/module/spark-yarn >bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ ./examples/jars/spark-examples_2.11-2.1.1.jar \ 10
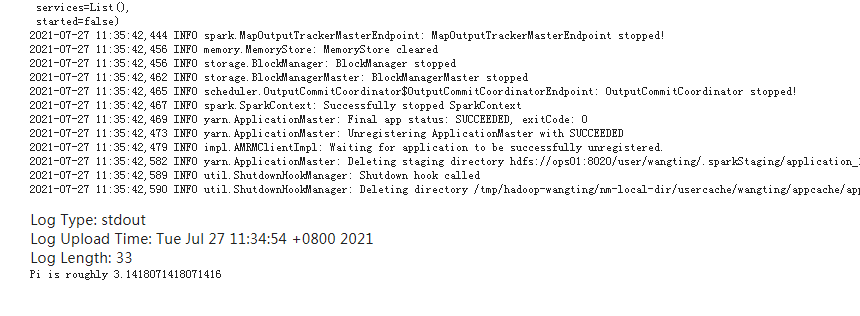
Click in the task and you can see the final Pi output in the log output
Cluster mode task flow
Centralized spark mode comparison (excluding mesos)
| pattern | Number of Spark installed machines | Process to start | Owner |
|---|---|---|---|
| Local mode | 1 | nothing | Spark |
| Standalone mode | 3 | Master and Worker | Spark |
| Yarn mode | 1 | Rely on existing Yan and HDFS | Hadoop |
Spark port grooming
1) Spark history server port number: 18080 (similar to Hadoop history server port number: 19888)
2) Spark Master Web port number: 8080 (similar to the NameNode Web port number of Hadoop: 9870 (50070))
3) Internal communication service port number of Spark Master: 7077 (similar to port 8020 (9000) of Hadoop)
4) Spark view current spark shell running task port number: 4040
5) Hadoop YARN task running status viewing port number: 8088
Local development environment + wordcount case
First install the idea code management tool, install the java environment, scala environment, idea configuration maven environment, etc. you can baidu by yourself.
Spark Shell is only used more when testing and verifying our programs. In the production environment, programs are usually compiled in the IDE, then printed into Jar packages, and then submitted to the cluster. The most commonly used is to create a maven project and use Maven to manage the dependency of Jar packages.
Programming
1) Create a Maven project
2) Prepare some wordcount materials
3) Import project dependencies
pom.xml file
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wangting</groupId>
<artifactId>spark_wt_test</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<finalName>WordCount</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
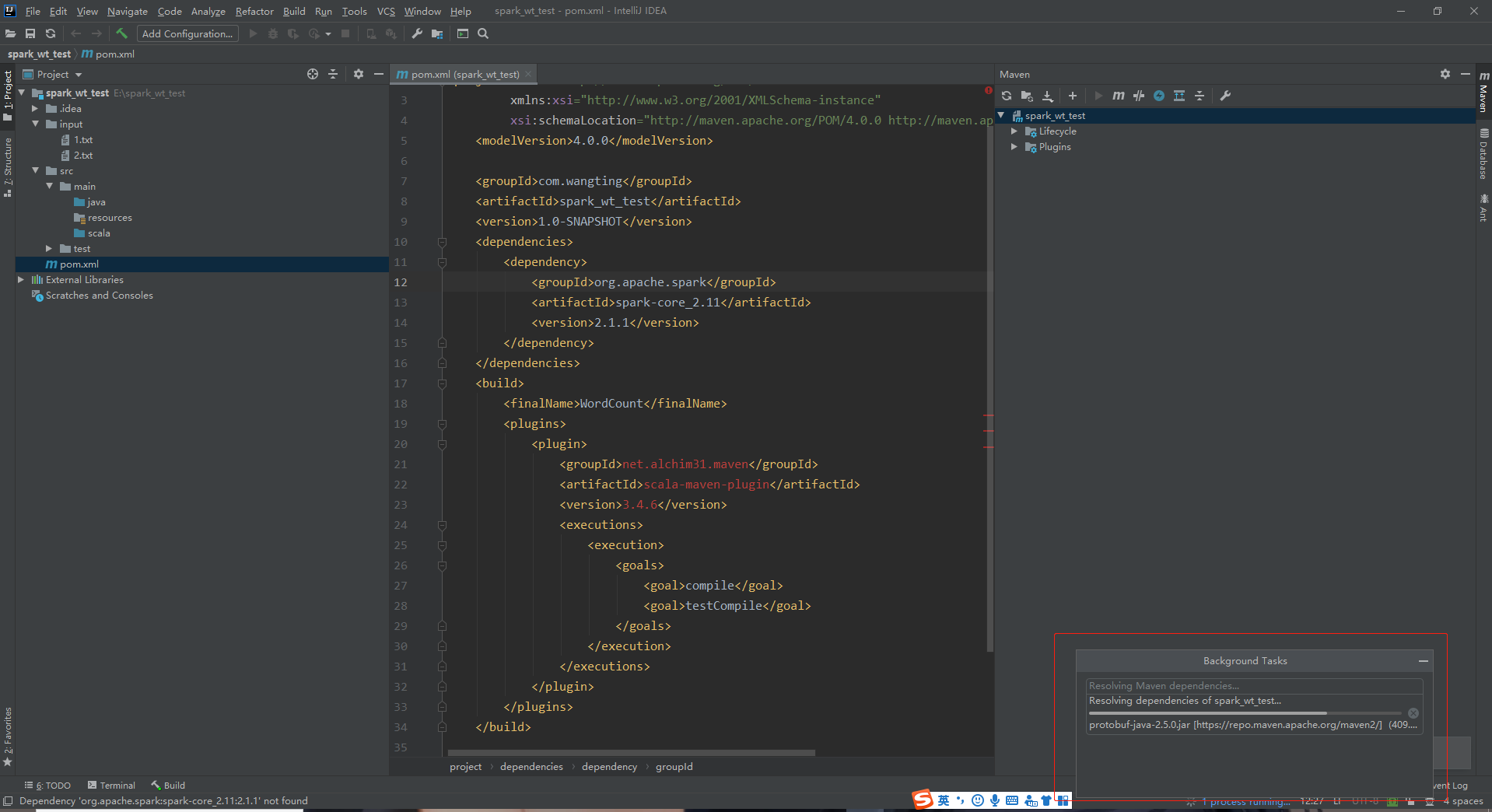
[note]:
- The new project is maven project, and the project name can be customized
- Create a new input directory under the project directory and a new 1. 0 directory under the input directory txt ; 2.txt is used as the calculation data source
1.txt
hello niubi nihao niubiplus scala niubi spark niubi scala spark
2.txt
hello wangting nihao wang scala ting spark wangting scala spark
- In POM After adding and configuring in XML, click maven update component on the right. At this time, there will be a download dependency process and wait patiently for the download to complete
- Create a scala directory in src/main, right-click mark directory as to change it to root, and the color is the same as java
- Create a new package in scala: com wangting. spark ; This can be customized
- On COM wangting. Create a new Scala class under spark package; The name is WordCount and the type is Object
package com.wangting.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//Create a SparkConf profile
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//Create a SparkContext object
val sc: SparkContext = new SparkContext(conf)
//sc.textFile("").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
//Read external files
val textRDD: RDD[String] = sc.textFile("E:\\spark_wt_test\\input\\1.txt")
//Cut and flatten the read content
val flatMapRDD: RDD[String] = textRDD.flatMap(_.split(" "))
//Structure conversion of the content in the data set - counting
val mapRDD: RDD[(String, Int)] = flatMapRDD.map((_, 1))
//Summarize the number of occurrences of the same word
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
//Collect the executed structure
val res: Array[(String, Int)] = reduceRDD.collect()
res.foreach(println)
/* //Create a SparkConf profile
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//Create a SparkContext object
val sc: SparkContext = new SparkContext(conf)
//One line of code
sc.textFile(args(0)).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile(args(1))
*/
//Release resources
sc.stop()
}
}
xml add package configuration
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<mainClass>com.wangting.spark.WordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
Note the location of plugin configuration build - plugins - plugin
Process combing
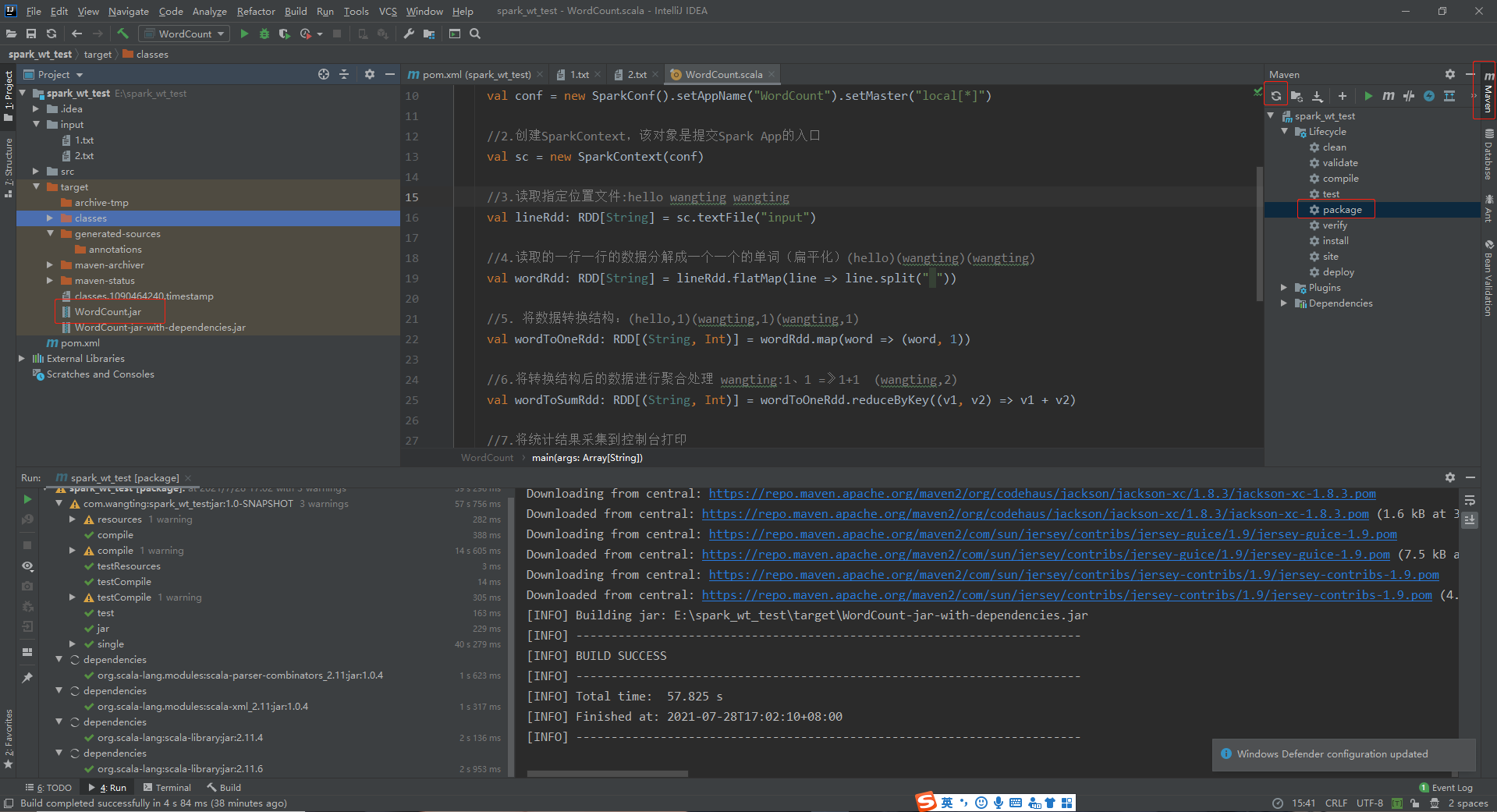
[note]:
The above is just a review of the development process. Each step must be different in the actual scene. Here is just to familiarize yourself with the steps of the development process
-
Prepare idea and configure maven environment
-
Create a maven project
-
In the project, you can create an input directory and write some materials instead of hdfs to get data to test the code
-
Create a directory Scala (sources root) of the same type as java in src/main
-
Note that the dependency configuration in the pom file is increased. After the addition, you can find maven near the upper right. Click the button to find the first similar update to download the dependency locally
-
You can put the code maintenance management under the scala package
-
Finally, you can use package to package in the Lifecycle option in maven
-
After packaging, there will be a target directory under the project directory; The package name is WordCount defined in pom. If there is no problem with the process, there will be a WordCount Jar package
-
Finally, transfer the jar package to the server to run the jar package, and the whole development process is completed
Associated source code
1. Download the zip package of spark-2.1.1 source code from the official website and unzip it locally
When the source code is not associated to the source code block, click the option 2. Download method
3. Select choose resources, and select the path of the extracted spark source directory in the path selection
4. After associating the corresponding path, click ok to complete the import
Local execution part version error reporting processing
Due to the version problem, if the local operating system is Windows and Hadoop related things are used in the program, such as writing files to HDFS, the following exceptions will be encountered
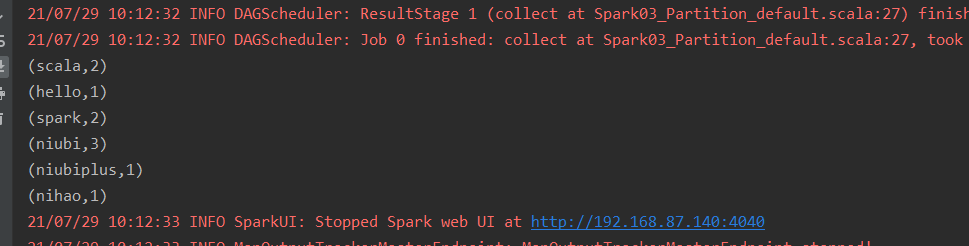
21/07/29 10:07:41 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278) at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:300) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:293) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:76) at org.apache.hadoop.mapred.FileInputFormat.setInputPaths(FileInputFormat.java:362) at org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$29.apply(SparkContext.scala:1013) at org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$29.apply(SparkContext.scala:1013) at org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:179) at org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:179) at scala.Option.foreach(Option.scala:257) at org.apache.spark.rdd.HadoopRDD.getJobConf(HadoopRDD.scala:179) at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:198) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
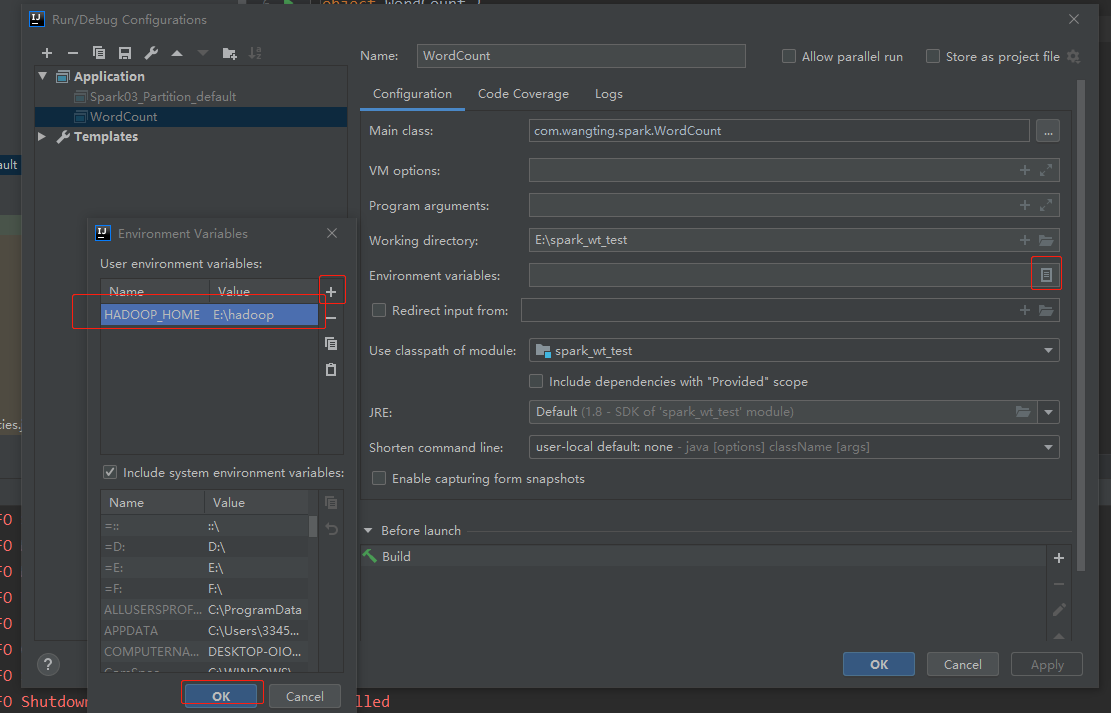
[note]: you only need to configure such a parameter. It doesn't matter whether there is hadoop deployment in the actual path. Just ensure that this parameter is available and the process can go through, because the local static file is called during the actual code test
After processing the error of adding environmental parameters: