🚀 The principle analysis of BERT can be seen as follows: Bert: pre training of deep bidirectional transformers for language understanding
🚀 The code implementation mainly uses huggingface's transformers Library (4.9.1) and torch Library (1.6.0)
pip install transformers
pip install torch
🚀 Let's talk about my approach first:
take the last four layers and splice them according to the dimension of 768. After splicing, it will be 4 * 768. Finally, concat is taken_ last_ 4layers [:, 0,:], that is, the output corresponding to the token [CLS] after concatenation of the last 4 layers. It is classified through a full connection layer.
⭐ Import related libraries first:
from transformers import BertTokenizer,BertModel,BertConfig from transformers import AdamW, get_linear_schedule_with_warmup import torch import torch.nn as nn from torch.utils.data import Dataset, DataLoader, TensorDataset from transformers import logging logging.set_verbosity_error() import pandas as pd import numpy as np
⭐ Import dataset (English movie review data):
dataset link: https://pan.baidu.com/s/1vhh5FmU01KqyjRtxByyxcQ
extraction code: bx4k
df = pd.read_csv('./Dataset.csv')
df.info()
df['sentiment'].value_counts()
it is divided into negative and positive labels, and the categories are relatively balanced:
1 12256
0 12244
Name: sentiment, dtype: int64
⭐ Text preprocessing:
segment the data set, and preprocess the text with the tokenizer of Bert base uncased pre training model. (calling each pre training model will have a corresponding tokenizer.)
x = list(df['review'])
y = list(df['sentiment'])
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
train_encoding = tokenizer(x_train, truncation=True, padding=True, max_length=64)
test_encoding = tokenizer(x_test, truncation=True, padding=True, max_length=64)
#You can view the dictionary this way
# vocab = tokenizer.vocab
# print(vocab['hello'])
After tokenzier, a dictionary will be returned with the following three key value pairs:
input_ids: the encoding of words (i.e. the index in the dictionary)
token_type_ids: identifies whether it is the first sentence or the second sentence
attention_mask: identify whether to fill
print(train_encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])
⭐ Data set encapsulation and batch processing:
here I have customized a data set to inherit torch utils. data. Dataset, which is a map dataset, must override the following two functions.
[Note: the inheritance and use of Datasets can be seen here: pytorch tip 5: Custom Dataset torch utils. data. Use of dataloader and Dataset]
# Read the Dataset and inherit the Dataset class of torch, which is convenient to encapsulate the Dataset with DataLoader later
class NewsDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
#The purpose of idx here is to make the following dataloaders be processed into iterators in batches and mapped to the corresponding data according to idx
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(int(self.labels[idx]))
return item
#Data set length. Through len (this instance object), you can view the length
def __len__(self):
return len(self.labels)
#Wrap the Dataset in the form of torch Dataset
train_dataset = NewsDataset(train_encoding, y_train)
test_dataset = NewsDataset(test_encoding, y_test)
# Single read to batch read
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=True)
#You can see what it looks like
#batch = next(iter(train_loader))
#print(batch)
#print(batch['input_ids'].shape)
⭐ Build BERT classification model:
first, load the pre training model, and then configure the number of layers and other parameters of the model through the config parameter. Then I defined a free_ The bert parameter to determine whether to freeze the bert layer (that is, whether to let it participate in training).
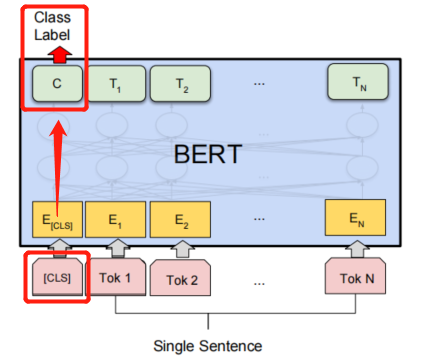
by setting this' output_ hidden_ The 'states' parameter is True, In order to make the model output the output status of all layers (including the output of the embedded layer and the 12 layers of the BERT model, a total of 13 layers). According to the practice in the paper, I took the last 4 layers and spliced them according to the dimension of 768, and then 4 * 768. Finally, I took concat_last_4layers[:,0,:], that is [CLS] This token corresponds to the output after the last four layers of concat. It is classified through a full connection layer.
[Note: please refer to the official api Manual of huggingface for the specific output of self.bert layer, because the input format of the model is different for different versions of transformers library.]
class my_bert_model(nn.Module):
def __init__(self, freeze_bert=False, hidden_size=768):
super().__init__()
config = BertConfig.from_pretrained('bert-base-uncased')
config.update({'output_hidden_states':True})
self.bert = BertModel.from_pretrained("bert-base-uncased",config=config)
self.fc = nn.Linear(hidden_size*4, 2)
#Do you want to freeze bert so that its parameters are not updated
if freeze_bert:
for p in self.bert.parameters():
p.requires_grad = False
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask)
all_hidden_states = torch.stack(outputs[2]) #Because the output is the output of all layers and is saved by tuples, it is converted into a matrix
concat_last_4layers = torch.cat((all_hidden_states[-1], #Take the output of the last 4 layers
all_hidden_states[-2],
all_hidden_states[-3],
all_hidden_states[-4]), dim=-1)
cls_concat = concat_last_4layers[:,0,:] #Take the output corresponding to the token [CLS] after the last four layers of concat
result = self.fc(cls_concat)
return result
⭐ Instantiate model, define loss function and optimizer:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device,'Can use')
model = my_bert_model().to(device)
criterion = nn.CrossEntropyLoss().to(device)
# optimization method
optim = AdamW(model.parameters(), lr=2e-5)
total_steps = len(train_loader) * 1
scheduler = get_linear_schedule_with_warmup(optim,
num_warmup_steps = 0, # Default value in run_glue.py
num_training_steps = total_steps)
⭐ Define training function:
# Training function
def train():
model.train()
total_train_loss = 0
iter_num = 0
total_iter = len(train_loader)
for batch in train_loader:
# Forward propagation
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask)
loss = criterion(outputs, labels)
total_train_loss += loss.item()
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 1.0) #Gradient cutting to prevent gradient explosion
# Parameter update
optim.step()
scheduler.step()
iter_num += 1
if(iter_num % 100==0):
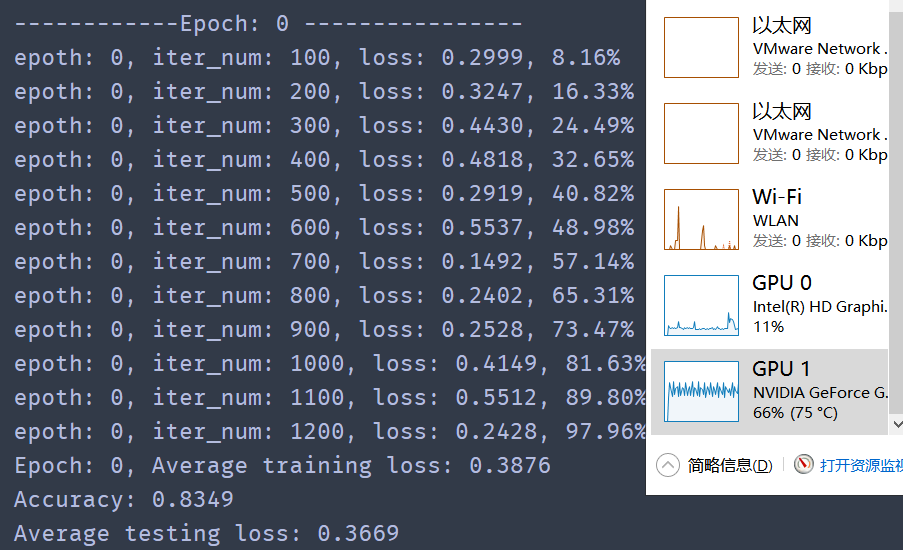
print("epoth: %d, iter_num: %d, loss: %.4f, %.2f%%" % (epoch, iter_num, loss.item(), iter_num/total_iter*100))
print("Epoch: %d, Average training loss: %.4f"%(epoch, total_train_loss/len(train_loader)))
⭐ Define test functions:
# Precision calculation
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
def validation():
model.eval()
total_eval_accuracy = 0
total_eval_loss = 0
with torch.no_grad():
for batch in test_dataloader:
# Normal propagation
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask)
loss = criterion(outputs, labels)
logits = outputs
total_eval_loss += loss.item()
logits = logits.detach().cpu().numpy()
label_ids = labels.to('cpu').numpy()
total_eval_accuracy += flat_accuracy(logits, label_ids)
avg_val_accuracy = total_eval_accuracy / len(test_dataloader)
print("Accuracy: %.4f" % (avg_val_accuracy))
print("Average testing loss: %.4f"%(total_eval_loss/len(test_dataloader)))
print("-------------------------------")
⭐ Run an epoch (about a few minutes) with GPU, and the accuracy rate is 83%, as follows:
for epoch in range(1):
print("------------Epoch: %d ----------------" % epoch)
train()
validation()