1, Environment introduction
Install the Ubuntu virtual machine using VirtualBox. Install Hadoop and Eclipse 3.0 in Ubuntu 8 compiler. Download and install JAVA environment, Download jdk and complete the pseudo distributed environment configuration of Hadoop. Import all the required JAR packages encountered by the compiler in Eclipse. Start Hadoop, download the Hadoop Eclipse plugin from the website, extract it and add it to Eclipse, so that the MapReduce program can be successfully compiled and run in Eclipse.
2, Import jar package
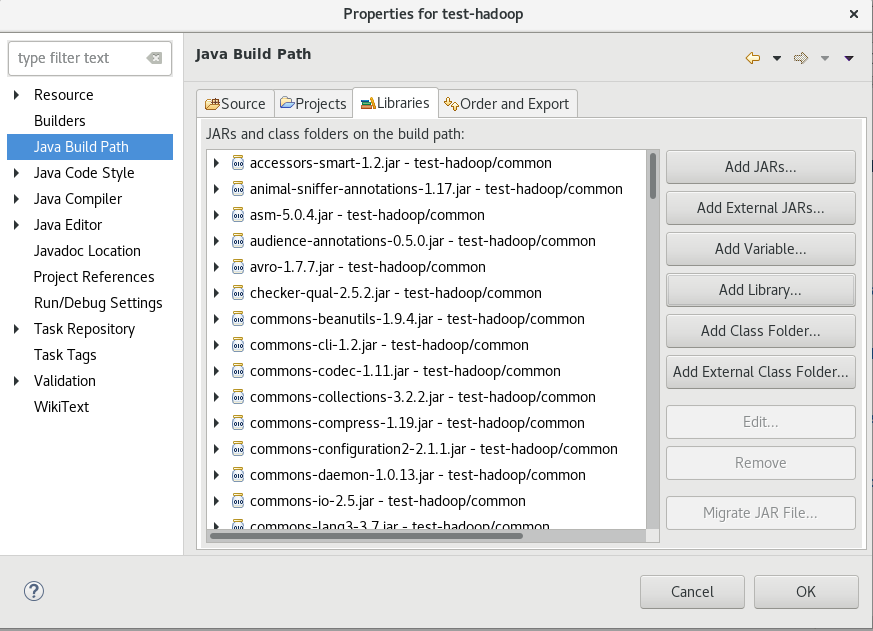
The jar packages to be imported are
3, Data source and data upload
Collect English profiles of major poets in Baidu, store them in the text and name them ZJH txt. Install enhancements in VirtualBox software and use its two-way drag file function to make zjh.com with word frequency statistics Txt to the desktop in hadoop.
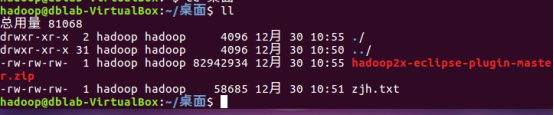
IV. viewing data upload results
Use the command to see if the file exists:
Put ZJH Txt to hdfs. Use the - ls command to view:
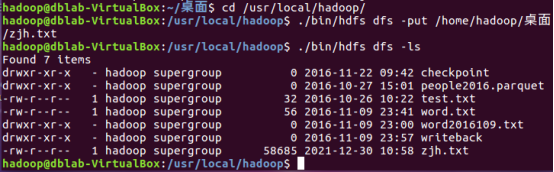
V. description of data processing process
Open the Eclipse software and click window -- > Open Perspective -- > Other:
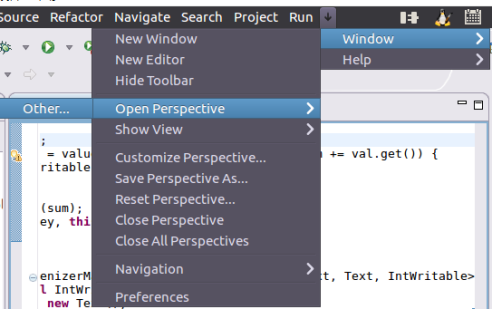
Select the Map/Reduce view:
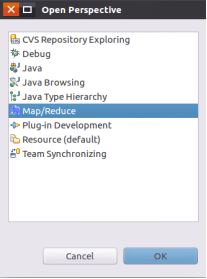
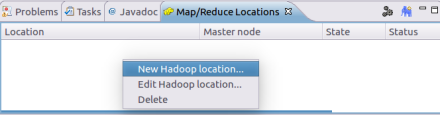
Right click in the generated Map/Reduce view and select New Hadoop Location:
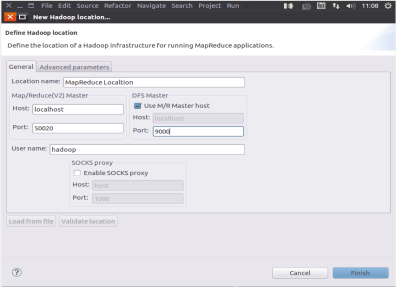
Set the location name and set the host port of the host: 9000:
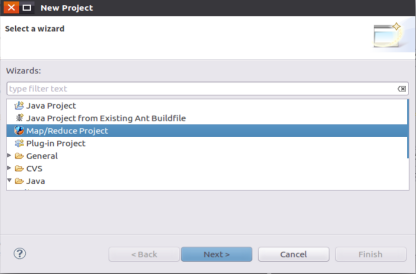
New project -- > map / reduce project:
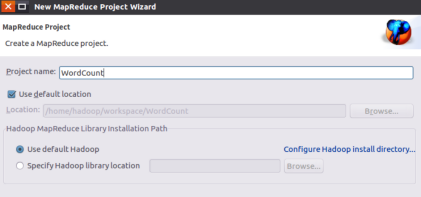
Name the project WordCount:
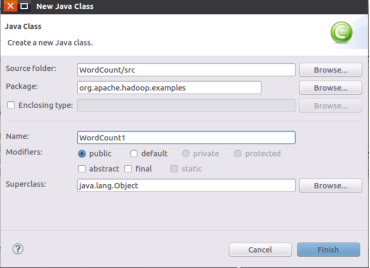
Create a new JAVA Class after the project is generated:
After creating the class, copy the following code to wordcount Java file:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}Use the command line / usr/local/hadoop/etc/hadoop to copy the modified configuration file to the src folder under the WordCount project:
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/workspace/WordCount/src cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/workspace/WordCount/src cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/workspace/WordCount/src

Right click the blank space of the item to enter run as -- > run configuration:
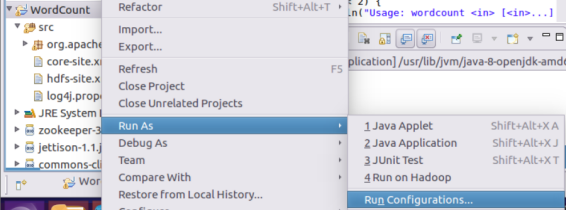
Set in the Arguments option. Here I use ZJH directly Txt when the input file is input, the outputTest folder is customized to store the files generated by the running results.
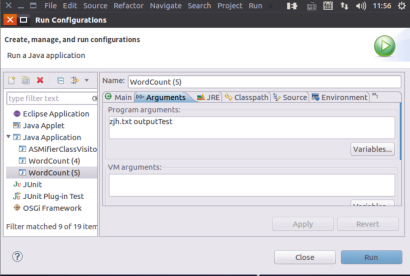
After setting the input and output parameters, click Run. You can see the prompt of successful operation.
Vi. download of processing results and display of command line
Use the command in hdfs in hadoop to check whether OutputTest is generated:
$ ./bin/hdfs dfs -ls
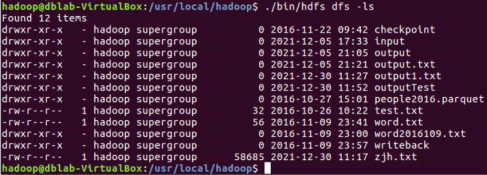
Use the - ls command to view the files stored in the outputTest folder:
$ ./bin/hdfs dfs -ls outputTest

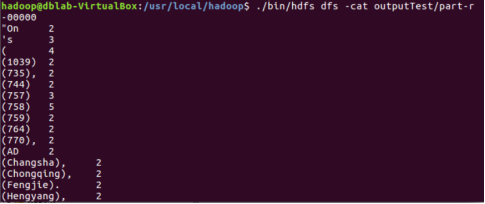
Use the - cat command to open outputTest/part-r-00000:
$ ./bin/hdfs dfs -cat outputTest/part-r-00000
Use the command to download the outputTest folder to the local outputTest folder.
$ ./bin/hdfs dfs -get outputTest ./outputTest

Check whether the outputTest folder exists in / usr/local/hadoop and open it
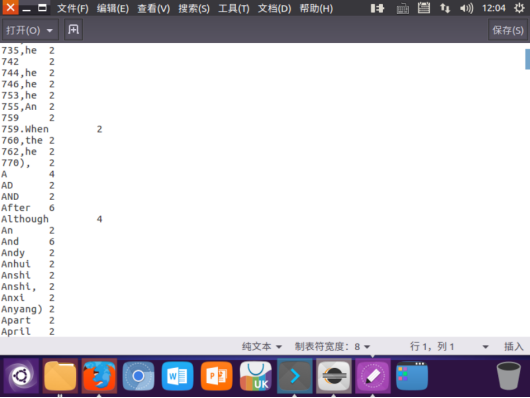
Open part-r-00000 for storing word frequency statistics results
VII. Experience summary
In this hadoop operation, eclipse is used to count the word frequency of hdfs file system files in hadoop. From the most basic installation of hadoop, configuration of environment variables, installation of software or plug-ins to the realization of functions, there will be more or less difficulties in each stage, including incorrect configuration of environment variable parameters and incorrect input of version parameters in the command, I grew up from a variety of small problems and constantly improved my mastery of hadoop. In the process of this big homework, I found that I had been familiar with the experimental process from the ignorant little white rookie to now. From so many experiments, I even began to become familiar with the command code. In the input and output directories of WordCount, there was an error that the file was not uploaded to the hdfs file system without knowing the message.
i/output can also be skillfully used in this experiment. Finally, I learned the new command to view the word frequency statistics results after the compilation and operation of the program in hdfs. I also learned the commands to download the files or folders of the hdfs file system to the local and view the files. Through the teacher's teaching and after-school experiment, I blindly followed the copy and paste command in the experimental manual at the beginning without understanding the usage and content of the command. Up to now, I have been familiar with and love hadoop, I also understand the function and function of hadoop in my study, and how convenient the strong computing function in many fields brings to computing. After class, I will also study hadoop deeply in other ways.
reference
[1]. Guo Moruo Li Bai and Du Fu Beijing: China Chang'an publishing house, 2010
[2]. The woods are raining Principle and application of big data technology Second edition Beijing: People's Posts and Telecommunications Press, 2017
[3].Tom White.Hadoop authoritative guide 4th Edition Beijing: Tsinghua University Press, 2018
[4]. Dong Xicheng Detailed explanation of big data technology system: principle, architecture and practice Beijing: China Machine Press
[5].Hadoop in Action. Hadoop actual combat Beijing: People's Posts and Telecommunications Press