preface
This article belongs to the column "1000 problems to solve big data technology system", which is original by the author. Please indicate the source of quotation. Please help point out the deficiencies and errors in the comment area. Thank you!
Please refer to table of contents and references for this column 1000 problems to solve the big data technology system
catalogue
Spark SQL functions.scala source code analysis (I) Sort functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (II) Aggregate functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (III) Window functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (IV) non aggregate functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (V) Math Functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (VI) Misc functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (VII) String functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (VIII) DateTime functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (IX) Collection functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (x) Partition transform functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (XI) Scala UDF functions (based on Spark 3.3.0)
Spark SQL functions.scala source code analysis (XII) Java UDF functions (based on Spark 3.3.0)
text
ascii
/**
* Calculates the value of the first character of the string column and returns the result as an int column
*
* @group string_funcs
* @since 1.5.0
*/
def ascii(e: Column): Column = withExpr { Ascii(e.expr) }
usage
========== df.select(ascii($"a"), ascii($"b"), ascii($"c")).show() ========== +--------+--------+--------+ |ascii(a)|ascii(b)|ascii(c)| +--------+--------+--------+ | 97| 97| 0| +--------+--------+--------+
base64
/**
* Calculates the BASE64 encoding of the binary column and returns it as a string column.
* This is the opposite of unbase64.
*
* @group string_funcs
* @since 1.5.0
*/
def base64(e: Column): Column = withExpr { Base64(e.expr) }
usage
========== df.select(base64($"a"), base64($"b"), base64($"c")).show() ========== +---------+---------+---------+ |base64(a)|base64(b)|base64(c)| +---------+---------+---------+ | YWJj| YWFhQmI=| | +---------+---------+---------+
bit_length
/**
* Calculates the bit length of the specified string column.
*
* @group string_funcs
* @since 3.3.0
*/
def bit_length(e: Column): Column = withExpr { BitLength(e.expr) }
concat_ws
/**
* Concatenate multiple input string columns into one string column using the given delimiter.
*
* @group string_funcs
* @since 1.5.0
*/
@scala.annotation.varargs
def concat_ws(sep: String, exprs: Column*): Column = withExpr {
ConcatWs(Literal.create(sep, StringType) +: exprs.map(_.expr))
}
usage
========== df.select(concat_ws(";", $"a", $"b", $"c")).show() ==========
+---------------------+
|concat_ws(;, a, b, c)|
+---------------------+
| abc;aaaBb;|
+---------------------+
decode/encode
/**
* Use one of the provided character sets ("US-ASCII", "ISO-8859-1", "UTF-8", "UTF-16BE", "UTF-16LE", "UTF-16")
* Evaluates the first parameter from binary to string.
*
* If any parameter is empty, the result will also be empty.
*
* @group string_funcs
* @since 1.5.0
*/
def decode(value: Column, charset: String): Column = withExpr {
StringDecode(value.expr, lit(charset).expr)
}
/**
* Use one of the provided character sets ("US-ASCII", "ISO-8859-1", "UTF-8", "UTF-16BE", "UTF-16LE", "UTF-16")
* Evaluates the first parameter from a string to binary.
*
* If any parameter is empty, the result will also be empty.
*
* @group string_funcs
* @since 1.5.0
*/
def encode(value: Column, charset: String): Column = withExpr {
Encode(value.expr, lit(charset).expr)
}
usage
========== df.select(decode($"a", "utf-8")).show() ========== +----------------------+ |stringdecode(a, utf-8)| +----------------------+ | abc| +----------------------+ ========== df.select(encode($"a", "utf-8")).show() ========== +----------------+ |encode(a, utf-8)| +----------------+ | [61 62 63]| +----------------+
format_number/format_string
/**
* Format the numeric column x like '#, ####, ###, ###. ##' Format, using HALF_EVEN rounding mode rounds to d decimal places and returns the result as a string column.
*
* If d is 0, the result has no decimal point or fractional part. If d is less than 0, the result will be empty.
*
* @group string_funcs
* @since 1.5.0
*/
def format_number(x: Column, d: Int): Column = withExpr {
FormatNumber(x.expr, lit(d).expr)
}
/**
* Format the parameter in printf style and return the result as a string column.
*
* @group string_funcs
* @since 1.5.0
*/
@scala.annotation.varargs
def format_string(format: String, arguments: Column*): Column = withExpr {
FormatString((lit(format) +: arguments).map(_.expr): _*)
}
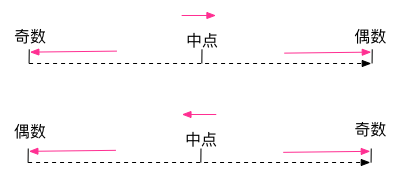
HALF_EVEN rounding mode: round to the nearest number. If the distance from two adjacent numbers is equal, round to the adjacent even number.
usage
========== df.select(format_number(lit(5L), 4)).show() ==========
+-------------------+
|format_number(5, 4)|
+-------------------+
| 5.0000|
+-------------------+
========== df.select(format_number(lit(1.toByte), 4)).show() ==========
+-------------------+
|format_number(1, 4)|
+-------------------+
| 1.0000|
+-------------------+
========== df.select(format_number(lit(2.toShort), 4)).show() ==========
+-------------------+
|format_number(2, 4)|
+-------------------+
| 2.0000|
+-------------------+
========== df.select(format_number(lit(3.1322.toFloat), 4)).show() ==========
+------------------------+
|format_number(3.1322, 4)|
+------------------------+
| 3.1322|
+------------------------+
========== df.select(format_number(lit(4), 4)).show() ==========
+-------------------+
|format_number(4, 4)|
+-------------------+
| 4.0000|
+-------------------+
========== df.select(format_number(lit(5L), 4)).show() ==========
+-------------------+
|format_number(5, 4)|
+-------------------+
| 5.0000|
+-------------------+
========== df.select(format_number(lit(6.48173), 4)).show() ==========
+-------------------------+
|format_number(6.48173, 4)|
+-------------------------+
| 6.4817|
+-------------------------+
========== df.select(format_number(lit(BigDecimal("7.128381")), 4)).show() ==========
+--------------------------+
|format_number(7.128381, 4)|
+--------------------------+
| 7.1284|
+--------------------------+
========== df.select(format_string("aa%d%s", lit(123), lit("cc"))).show() ==========
+------------------------------+
|format_string(aa%d%s, 123, cc)|
+------------------------------+
| aa123cc|
+------------------------------+
initcap
/**
* Returns a new string of characters by converting the first letter of each word to uppercase.
* Words are separated by spaces.
* For example, "Hello world" will become "Hello world".
*
* @group string_funcs
* @since 1.5.0
*/
def initcap(e: Column): Column = withExpr { InitCap(e.expr) }
usage
========== df.select(initcap($"a"), initcap($"b"), initcap($"c")).show() ========== +----------+----------+----------+ |initcap(a)|initcap(b)|initcap(c)| +----------+----------+----------+ | Abc| Aaabb| | +----------+----------+----------+
instr
/**
* Locates the first occurrence of the substr column in a given string.
* If any parameter is null, null is returned.
* be careful:
* The location is not zero based, but a 1-based index.
* If substr is not found in str, 0 is returned.
*
* @group string_funcs
* @since 1.5.0
*/
def instr(str: Column, substring: String): Column = withExpr {
StringInstr(str.expr, lit(substring).expr)
}
usage
========== df.select(instr($"b", "aa")).show() ========== +------------+ |instr(b, aa)| +------------+ | 1| +------------+
length
/**
* Calculates the character length of a given string or the number of bytes of a binary string.
* The length of the string includes trailing spaces.
* The length of a binary string includes binary zeros.
*
* @group string_funcs
* @since 1.5.0
*/
def length(e: Column): Column = withExpr { Length(e.expr) }
usage
========== df.select(length($"a"), length($"b"), length($"c")).show() ========== +---------+---------+---------+ |length(a)|length(b)|length(c)| +---------+---------+---------+ | 3| 5| 0| +---------+---------+---------+
lower
/**
* Converts a string of characters to lowercase.
*
* @group string_funcs
* @since 1.3.0
*/
def lower(e: Column): Column = withExpr { Lower(e.expr) }
usage
========== df.select(lower($"b")).show() ========== +--------+ |lower(b)| +--------+ | aaabb| +--------+
levenshtein
/**
* Calculates the Levenshtein Distance between two given string columns.
* @group string_funcs
* @since 1.5.0
*/
def levenshtein(l: Column, r: Column): Column = withExpr { Levenshtein(l.expr, r.expr) }
Levinstein distance, also known as Levenshtein Distance, is a kind of editing distance. Refers to the minimum number of editing operations required to convert from one string to another between two strings. Allowed editing operations include replacing one character with another, inserting a character, and deleting a character.
For example, change the word kitten to sitting:
sitten (k→s)
sittin (e→i)
sitting (→g)
Russian scientist Vladimir levinstein put forward this concept in 1965.
usage
========== df.select(levenshtein($"a", $"b")).show() ========== +-----------------+ |levenshtein(a, b)| +-----------------+ | 4| +-----------------+
locate
/**
* Locate where substr first appears.
* be careful:
* The location is not zero based, but a 1-based index.
* If substr is not found in str, 0 is returned
*
* @group string_funcs
* @since 1.5.0
*/
def locate(substr: String, str: Column): Column = withExpr {
new StringLocate(lit(substr).expr, str.expr)
}
/**
* Locate the position where substr first appears in the string column, after position pos.
*
* be careful:
* The location is not zero based, but a 1-based index.
* If substr is not found in str, 0 is returned
*
* @group string_funcs
* @since 1.5.0
*/
def locate(substr: String, str: Column, pos: Int): Column = withExpr {
StringLocate(lit(substr).expr, str.expr, lit(pos).expr)
}
usage
========== df.select(locate("aa", $"b")).show() ==========
+----------------+
|locate(aa, b, 1)|
+----------------+
| 1|
+----------------+
========== df.select(locate("aa", $"b", 2)).show() ==========
+----------------+
|locate(aa, b, 2)|
+----------------+
| 2|
+----------------+
lpad
/**
* Fill the length of the character string from pad left to len.
* If the string column is longer than len, the return value will be shortened to len characters.
*
* @group string_funcs
* @since 1.5.0
*/
def lpad(str: Column, len: Int, pad: String): Column = withExpr {
StringLPad(str.expr, lit(len).expr, lit(pad).expr)
}
/**
* Fill the byte length from binary column to len with pad left.
* If the binary column is longer than len, the return value is shortened to len bytes.
*
* @group string_funcs
* @since 3.3.0
*/
def lpad(str: Column, len: Int, pad: Array[Byte]): Column = withExpr {
new BinaryLPad(str.expr, lit(len).expr, lit(pad).expr)
}
usage
========== df.select(lpad($"a", 10, " ")).show() ========== +--------------+ |lpad(a, 10, )| +--------------+ | abc| +--------------+
ltrim
/**
* Trims the space at the left end of the specified string value.
*
* @group string_funcs
* @since 1.5.0
*/
def ltrim(e: Column): Column = withExpr {StringTrimLeft(e.expr) }
/**
* Trims the specified string from the left end for the specified string column.
* @group string_funcs
* @since 2.3.0
*/
def ltrim(e: Column, trimString: String): Column = withExpr {
StringTrimLeft(e.expr, Literal(trimString))
}
usage
========== df.select(ltrim(lit(" 123"))).show() ==========
+-------------+
|ltrim( 123)|
+-------------+
| 123|
+-------------+
========== df.select(ltrim(lit("aaa123"), "a")).show() ==========
+---------------------------+
|TRIM(LEADING a FROM aaa123)|
+---------------------------+
| 123|
+---------------------------+
octet_length
/**
* Calculates the byte length of the specified string column.
*
* @group string_funcs
* @since 3.3.0
*/
def octet_length(e: Column): Column = withExpr { OctetLength(e.expr) }
regexp_extract/regexp_replace
/**
* Extracts a specific group that matches a Java regular expression from the specified string column.
* If the regular expression does not match, or the specified group does not match, an empty string is returned.
* If the specified group index exceeds the number of groups in the regular expression, an IllegalArgumentException is thrown.
*
* @group string_funcs
* @since 1.5.0
*/
def regexp_extract(e: Column, exp: String, groupIdx: Int): Column = withExpr {
RegExpExtract(e.expr, lit(exp).expr, lit(groupIdx).expr)
}
/**
* Replace all substrings in the specified string value that match regexp with rep
*
* @group string_funcs
* @since 1.5.0
*/
def regexp_replace(e: Column, pattern: String, replacement: String): Column = withExpr {
RegExpReplace(e.expr, lit(pattern).expr, lit(replacement).expr)
}
/**
* Replace all substrings in the specified string value that match regexp with rep
*
* @group string_funcs
* @since 2.1.0
*/
def regexp_replace(e: Column, pattern: Column, replacement: Column): Column = withExpr {
RegExpReplace(e.expr, pattern.expr, replacement.expr)
}
usage
========== df.select(regexp_extract(lit("abc123"), "(\\d+)", 1)).show() ==========
+--------------------------------+
|regexp_extract(abc123, (\d+), 1)|
+--------------------------------+
| 123|
+--------------------------------+
========== df.select(regexp_replace(lit("abc123"), "(\\d+)", "num")).show() ==========
+-------------------------------------+
|regexp_replace(abc123, (\d+), num, 1)|
+-------------------------------------+
| abcnum|
+-------------------------------------+
========== df.select(regexp_replace(lit("abc123"), lit("(\\d+)"), lit("num"))).show() ==========
+-------------------------------------+
|regexp_replace(abc123, (\d+), num, 1)|
+-------------------------------------+
| abcnum|
+-------------------------------------+
unbase64
/**
* Decodes the BASE64 encoded character string column and returns it as a binary column.
* This is the opposite of base64.
*
* @group string_funcs
* @since 1.5.0
*/
def unbase64(e: Column): Column = withExpr { UnBase64(e.expr) }
usage
========== df.select(unbase64(typedlit(Array[Byte](1, 2, 3, 4)))).show() ========== +---------------------+ |unbase64(X'01020304')| +---------------------+ | []| +---------------------+
rpad
/**
* Fill the length of the character string from pad right to len.
* If the string column is longer than len, the return value will be shortened to len characters.
*
* @group string_funcs
* @since 1.5.0
*/
def rpad(str: Column, len: Int, pad: String): Column = withExpr {
StringRPad(str.expr, lit(len).expr, lit(pad).expr)
}
/**
* Fill the byte length from binary column to len with pad right.
* If the binary column is longer than len, the return value is shortened to len bytes.
*
* @group string_funcs
* @since 3.3.0
*/
def rpad(str: Column, len: Int, pad: Array[Byte]): Column = withExpr {
new BinaryRPad(str.expr, lit(len).expr, lit(pad).expr)
}
usage
========== df.select(rpad($"a", 10, " ")).show() ========== +--------------+ |rpad(a, 10, )| +--------------+ | abc | +--------------+
repeat
/**
* Repeat the string column n times and return it as a new string column.
*
* @group string_funcs
* @since 1.5.0
*/
def repeat(str: Column, n: Int): Column = withExpr {
StringRepeat(str.expr, lit(n).expr)
}
usage
========== df.select(repeat($"a", 3)).show() ========== +------------+ |repeat(a, 3)| +------------+ | abcabcabc| +------------+
rtrim
/**
* Trims the space at the right end of the specified string value
*
* @group string_funcs
* @since 1.5.0
*/
def rtrim(e: Column): Column = withExpr { StringTrimRight(e.expr) }
/**
* Trims the specified string from the right end for the specified string column.
*
* @group string_funcs
* @since 2.3.0
*/
def rtrim(e: Column, trimString: String): Column = withExpr {
StringTrimRight(e.expr, Literal(trimString))
}
usage
========== df.select(rtrim(lit("123 "))).show() ==========
+-------------+
|rtrim(123 )|
+-------------+
| 123|
+-------------+
========== df.select(rtrim(lit("123aaa"), "a")).show() ==========
+----------------------------+
|TRIM(TRAILING a FROM 123aaa)|
+----------------------------+
| 123|
+----------------------------+
soundex
/**
* Returns the soundex code of the specified expression.
*
* @group string_funcs
* @since 1.5.0
*/
def soundex(e: Column): Column = withExpr { SoundEx(e.expr) }
soundex is an algorithm that converts any text string into an alphanumeric pattern that describes its voice representation. soundex takes into account similar pronunciation characters and syllables, so that string pronunciation comparison rather than letter comparison.
usage
========== df.select(soundex($"a"), soundex($"b")).show() ========== +----------+----------+ |soundex(a)|soundex(b)| +----------+----------+ | A120| A100| +----------+----------+
split
/**
* Split str around the match of the given pattern.
*
* @param str String expression to split
* @param pattern A string representing a regular expression. The regular expression string should be a Java regular expression.
*
* @group string_funcs
* @since 1.5.0
*/
def split(str: Column, pattern: String): Column = withExpr {
StringSplit(str.expr, Literal(pattern), Literal(-1))
}
/**
* Split str around match for given pattern
*
* @param str String expression to split
* @param pattern A string representing a regular expression. The regular expression string should be a Java regular expression.
* @param limit An integer expression that controls the number of times a regular expression is applied.
* limit Greater than 0: the length of the result array will not exceed the limit, and the last entry of the result array will contain all inputs except the last matching regular expression.
* limit Less than or equal to 0: the regular expression will be applied as many times as possible, and the result array can be of any size.
*
* @group string_funcs
* @since 3.0.0
*/
def split(str: Column, pattern: String, limit: Int): Column = withExpr {
StringSplit(str.expr, Literal(pattern), Literal(limit))
}
usage
========== df.select(split(lit("a;b;c"), ";")).show() ==========
+-------------------+
|split(a;b;c, ;, -1)|
+-------------------+
| [a, b, c]|
+-------------------+
========== df.select(split(lit("a;b;c"), ";", 2)).show() ==========
+------------------+
|split(a;b;c, ;, 2)|
+------------------+
| [a, b;c]|
+------------------+
========== df.select(split(lit("a;b;c"), ";", 0)).show() ==========
+------------------+
|split(a;b;c, ;, 0)|
+------------------+
| [a, b, c]|
+------------------+
========== df.select(split(lit("a;b;c"), ";", -1)).show() ==========
+-------------------+
|split(a;b;c, ;, -1)|
+-------------------+
| [a, b, c]|
+-------------------+
substring/substring_index
/**
* The substring starts from pos. when str is of String type, the length is len or returns the byte array slice starting from POS in the byte array. When str is of Binary type, the length is
* len
*
* @Note that the location is not zero based, but a 1-based index.
*
* @group string_funcs
* @since 1.5.0
*/
def substring(str: Column, pos: Int, len: Int): Column = withExpr {
Substring(str.expr, lit(pos).expr, lit(len).expr)
}
/**
* Returns a substring in the string str before the number of occurrences of the delimiter delim.
* If the count is positive, everything to the left of the final delimiter is returned (counting from the left).
* If count is negative, each character to the right of the final separator is returned (counting from the right).
* substring_index Performs case sensitive matching when searching for delim.
*
* @group string_funcs
*/
def substring_index(str: Column, delim: String, count: Int): Column = withExpr {
SubstringIndex(str.expr, lit(delim).expr, lit(count).expr)
}
usage
========== df.select(substring(lit("abcdef"), 2, 5)).show() ==========
+-----------------------+
|substring(abcdef, 2, 5)|
+-----------------------+
| bcdef|
+-----------------------+
========== df.select(substring_index(lit("www.shockang.com"), ".", 2)).show() ==========
+---------------------------------------+
|substring_index(www.shockang.com, ., 2)|
+---------------------------------------+
| www.shockang|
+---------------------------------------+
overlay
/**
* Overwrite the specified part of src with replace, starting from the byte position pos of src and continuing with len bytes.
*
* @group string_funcs
* @since 3.0.0
*/
def overlay(src: Column, replace: Column, pos: Column, len: Column): Column = withExpr {
Overlay(src.expr, replace.expr, pos.expr, len.expr)
}
/**
* Starting from the byte position pos of src, overwrite the specified part of src with replace.
*
* @group string_funcs
* @since 3.0.0
*/
def overlay(src: Column, replace: Column, pos: Column): Column = withExpr {
new Overlay(src.expr, replace.expr, pos.expr)
}
usage
========== df.select(overlay(lit("abcdef"), lit("abc"), lit(4), lit(1))).show() ==========
+--------------------------+
|overlay(abcdef, abc, 4, 1)|
+--------------------------+
| abcabcef|
+--------------------------+
========== df.select(overlay(lit("abcdef"), lit("abc"), lit(4))).show() ==========
+---------------------------+
|overlay(abcdef, abc, 4, -1)|
+---------------------------+
| abcabc|
+---------------------------+
sentences
/**
* Splits a string into an array of sentences, where each sentence is an array of words.
*
* @group string_funcs
* @since 3.2.0
*/
def sentences(string: Column, language: Column, country: Column): Column = withExpr {
Sentences(string.expr, language.expr, country.expr)
}
/**
* Splits a string into an array of sentences, where each sentence is an array of words.
* Use the default locale.
*
* @group string_funcs
* @since 3.2.0
*/
def sentences(string: Column): Column = withExpr {
Sentences(string.expr)
}
usage
========== df.select(sentences(lit("We all have a home called China"), lit("zh"), lit("CN"))).show() ==========
+---------------------------------------------+
|sentences(We all have a home called China, zh, CN)|
+---------------------------------------------+
| [[We all have a home, His name is China]]|
+---------------------------------------------+
========== df.select(sentences(lit("We all have a home called China"))).show() ==========
+-----------------------------------------+
|sentences(We all have a home called China, , )|
+-----------------------------------------+
| [[We all have a home, His name is China]]|
+-----------------------------------------+
translate
/**
* Converts any character in src to a character in replaceString.
* replaceString Characters in correspond to characters in matchingString.
* Conversion occurs when any character in the string matches a character in matchingString.
*
* @group string_funcs
* @since 1.5.0
*/
def translate(src: Column, matchingString: String, replaceString: String): Column = withExpr {
StringTranslate(src.expr, lit(matchingString).expr, lit(replaceString).expr)
}
usage
========== df.select(translate(lit("abcdef"), "def", "123")).show() ==========
+---------------------------+
|translate(abcdef, def, 123)|
+---------------------------+
| abc123|
+---------------------------+
trim
/**
* Trims the spaces at both ends of the specified character string column.
*
* @group string_funcs
* @since 1.5.0
*/
def trim(e: Column): Column = withExpr { StringTrim(e.expr) }
/**
* Trims the specified string trimString at e both ends of the specified string column.
*
* @group string_funcs
* @since 2.3.0
*/
def trim(e: Column, trimString: String): Column = withExpr {
StringTrim(e.expr, Literal(trimString))
}
usage
========== df.select(trim(lit(" abc "))).show() ==========
+---------------+
|trim( abc )|
+---------------+
| abc|
+---------------+
========== df.select(trim(lit("aaabcaaaa"), "a")).show() ==========
+---------------------------+
|TRIM(BOTH a FROM aaabcaaaa)|
+---------------------------+
| bc|
+---------------------------+
upper
/**
* Converts a string of characters to uppercase.
*
* @group string_funcs
* @since 1.3.0
*/
def upper(e: Column): Column = withExpr { Upper(e.expr) }
usage
========== df.select(upper($"b")).show() ========== +--------+ |upper(b)| +--------+ | AAABB| +--------+
practice
code
package com.shockang.study.spark.sql.functions
import com.shockang.study.spark.util.Utils.formatPrint
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
/**
*
* @author Shockang
*/
object StringFunctionsExample {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.OFF)
val spark = SparkSession.builder().appName("StringFunctionsExample").master("local[*]").getOrCreate()
import spark.implicits._
val df = Seq(("abc", "aaaBb", "")).toDF("a", "b", "c")
// ascii
formatPrint("""df.select(ascii($"a"), ascii($"b"), ascii($"c")).show()""")
df.select(ascii($"a"), ascii($"b"), ascii($"c")).show()
// base64
formatPrint("""df.select(base64($"a"), base64($"b"), base64($"c")).show()""")
df.select(base64($"a"), base64($"b"), base64($"c")).show()
// concat_ws
formatPrint("""df.select(concat_ws(";", $"a", $"b", $"c")).show()""")
df.select(concat_ws(";", $"a", $"b", $"c")).show()
// decode/encode
formatPrint("""df.select(decode($"a", "utf-8")).show()""")
df.select(decode($"a", "utf-8")).show()
formatPrint("""df.select(encode($"a", "utf-8")).show()""")
df.select(encode($"a", "utf-8")).show()
// format_number/format_string
formatPrint("""df.select(format_number(lit(5L), 4)).show()""")
df.select(format_number(lit(5L), 4)).show()
formatPrint("""df.select(format_number(lit(1.toByte), 4)).show()""")
df.select(format_number(lit(1.toByte), 4)).show()
formatPrint("""df.select(format_number(lit(2.toShort), 4)).show()""")
df.select(format_number(lit(2.toShort), 4)).show()
formatPrint("""df.select(format_number(lit(3.1322.toFloat), 4)).show()""")
df.select(format_number(lit(3.1322.toFloat), 4)).show()
formatPrint("""df.select(format_number(lit(4), 4)).show()""")
df.select(format_number(lit(4), 4)).show()
formatPrint("""df.select(format_number(lit(5L), 4)).show()""")
df.select(format_number(lit(5L), 4)).show()
formatPrint("""df.select(format_number(lit(6.48173), 4)).show()""")
df.select(format_number(lit(6.48173), 4)).show()
formatPrint("""df.select(format_number(lit(BigDecimal("7.128381")), 4)).show()""")
df.select(format_number(lit(BigDecimal("7.128381")), 4)).show()
formatPrint("""df.select(format_string("aa%d%s", lit(123), lit("cc"))).show()""")
df.select(format_string("aa%d%s", lit(123), lit("cc"))).show()
// initcap
formatPrint("""df.select(initcap($"a"), initcap($"b"), initcap($"c")).show()""")
df.select(initcap($"a"), initcap($"b"), initcap($"c")).show()
// instr
formatPrint("""df.select(instr($"b", "aa")).show()""")
df.select(instr($"b", "aa")).show()
// length
formatPrint("""df.select(length($"a"), length($"b"), length($"c")).show()""")
df.select(length($"a"), length($"b"), length($"c")).show()
// lower
formatPrint("""df.select(lower($"b")).show()""")
df.select(lower($"b")).show()
// levenshtein
formatPrint("""df.select(levenshtein($"a", $"b")).show()""")
df.select(levenshtein($"a", $"b")).show()
// locate
formatPrint("""df.select(locate("aa", $"b")).show()""")
df.select(locate("aa", $"b")).show()
formatPrint("""df.select(locate("aa", $"b", 2)).show()""")
df.select(locate("aa", $"b", 2)).show()
// lpad
formatPrint("""df.select(lpad($"a", 10, " ")).show()""")
df.select(lpad($"a", 10, " ")).show()
// ltrim
formatPrint("""df.select(ltrim(lit(" 123"))).show()""")
df.select(ltrim(lit(" 123"))).show()
formatPrint("""df.select(ltrim(lit("aaa123"), "a")).show()""")
df.select(ltrim(lit("aaa123"), "a")).show()
// regexp_extract/regexp_replace
formatPrint("""df.select(regexp_extract(lit("abc123"), "(\\d+)", 1)).show()""")
df.select(regexp_extract(lit("abc123"), "(\\d+)", 1)).show()
formatPrint("""df.select(regexp_replace(lit("abc123"), "(\\d+)", "num")).show()""")
df.select(regexp_replace(lit("abc123"), "(\\d+)", "num")).show()
formatPrint("""df.select(regexp_replace(lit("abc123"), lit("(\\d+)"), lit("num"))).show()""")
df.select(regexp_replace(lit("abc123"), lit("(\\d+)"), lit("num"))).show()
// unbase64
formatPrint("""df.select(unbase64(typedlit(Array[Byte](1, 2, 3, 4)))).show()""")
df.select(unbase64(typedlit(Array[Byte](1, 2, 3, 4)))).show()
// rpad
formatPrint("""df.select(rpad($"a", 10, " ")).show()""")
df.select(rpad($"a", 10, " ")).show()
// repeat
formatPrint("""df.select(repeat($"a", 3)).show()""")
df.select(repeat($"a", 3)).show()
// rtrim
formatPrint("""df.select(rtrim(lit("123 "))).show()""")
df.select(rtrim(lit("123 "))).show()
formatPrint("""df.select(rtrim(lit("123aaa"), "a")).show()""")
df.select(rtrim(lit("123aaa"), "a")).show()
// soundex
formatPrint("""df.select(soundex($"a"), soundex($"b")).show()""")
df.select(soundex($"a"), soundex($"b")).show()
// split
formatPrint("""df.select(split(lit("a;b;c"), ";")).show()""")
df.select(split(lit("a;b;c"), ";")).show()
formatPrint("""df.select(split(lit("a;b;c"), ";", 2)).show()""")
df.select(split(lit("a;b;c"), ";", 2)).show()
formatPrint("""df.select(split(lit("a;b;c"), ";", 0)).show()""")
df.select(split(lit("a;b;c"), ";", 0)).show()
formatPrint("""df.select(split(lit("a;b;c"), ";", -1)).show()""")
df.select(split(lit("a;b;c"), ";", -1)).show()
// substring/substring_index
formatPrint("""df.select(substring(lit("abcdef"), 2, 5)).show()""")
df.select(substring(lit("abcdef"), 2, 5)).show()
formatPrint("""df.select(substring_index(lit("www.shockang.com"), ".", 2)).show()""")
df.select(substring_index(lit("www.shockang.com"), ".", 2)).show()
// overlay
formatPrint("""df.select(overlay(lit("abcdef"), lit("abc"), lit(4), lit(1))).show()""")
df.select(overlay(lit("abcdef"), lit("abc"), lit(4), lit(1))).show()
formatPrint("""df.select(overlay(lit("abcdef"), lit("abc"), lit(4))).show()""")
df.select(overlay(lit("abcdef"), lit("abc"), lit(4))).show()
// sentences
formatPrint("""df.select(sentences(lit("We all have a home called China"), lit("zh"), lit("CN"))).show()""")
df.select(sentences(lit("We all have a home called China"), lit("zh"), lit("CN"))).show()
formatPrint("""df.select(sentences(lit("We all have a home called China"))).show()""")
df.select(sentences(lit("We all have a home called China"))).show()
// translate
formatPrint("""df.select(translate(lit("abcdef"), "def", "123")).show()""")
df.select(translate(lit("abcdef"), "def", "123")).show()
// trim
formatPrint("""df.select(trim(lit(" abc "))).show()""")
df.select(trim(lit(" abc "))).show()
formatPrint("""df.select(trim(lit("aaabcaaaa"), "a")).show()""")
df.select(trim(lit("aaabcaaaa"), "a")).show()
// upper
formatPrint("""df.select(upper($"b")).show()""")
df.select(upper($"b")).show()
}
}
output
========== df.select(ascii($"a"), ascii($"b"), ascii($"c")).show() ==========
+--------+--------+--------+
|ascii(a)|ascii(b)|ascii(c)|
+--------+--------+--------+
| 97| 97| 0|
+--------+--------+--------+
========== df.select(base64($"a"), base64($"b"), base64($"c")).show() ==========
+---------+---------+---------+
|base64(a)|base64(b)|base64(c)|
+---------+---------+---------+
| YWJj| YWFhQmI=| |
+---------+---------+---------+
========== df.select(concat_ws(";", $"a", $"b", $"c")).show() ==========
+---------------------+
|concat_ws(;, a, b, c)|
+---------------------+
| abc;aaaBb;|
+---------------------+
========== df.select(decode($"a", "utf-8")).show() ==========
+----------------------+
|stringdecode(a, utf-8)|
+----------------------+
| abc|
+----------------------+
========== df.select(encode($"a", "utf-8")).show() ==========
+----------------+
|encode(a, utf-8)|
+----------------+
| [61 62 63]|
+----------------+
========== df.select(format_number(lit(5L), 4)).show() ==========
+-------------------+
|format_number(5, 4)|
+-------------------+
| 5.0000|
+-------------------+
========== df.select(format_number(lit(1.toByte), 4)).show() ==========
+-------------------+
|format_number(1, 4)|
+-------------------+
| 1.0000|
+-------------------+
========== df.select(format_number(lit(2.toShort), 4)).show() ==========
+-------------------+
|format_number(2, 4)|
+-------------------+
| 2.0000|
+-------------------+
========== df.select(format_number(lit(3.1322.toFloat), 4)).show() ==========
+------------------------+
|format_number(3.1322, 4)|
+------------------------+
| 3.1322|
+------------------------+
========== df.select(format_number(lit(4), 4)).show() ==========
+-------------------+
|format_number(4, 4)|
+-------------------+
| 4.0000|
+-------------------+
========== df.select(format_number(lit(5L), 4)).show() ==========
+-------------------+
|format_number(5, 4)|
+-------------------+
| 5.0000|
+-------------------+
========== df.select(format_number(lit(6.48173), 4)).show() ==========
+-------------------------+
|format_number(6.48173, 4)|
+-------------------------+
| 6.4817|
+-------------------------+
========== df.select(format_number(lit(BigDecimal("7.128381")), 4)).show() ==========
+--------------------------+
|format_number(7.128381, 4)|
+--------------------------+
| 7.1284|
+--------------------------+
========== df.select(format_string("aa%d%s", lit(123), lit("cc"))).show() ==========
+------------------------------+
|format_string(aa%d%s, 123, cc)|
+------------------------------+
| aa123cc|
+------------------------------+
========== df.select(initcap($"a"), initcap($"b"), initcap($"c")).show() ==========
+----------+----------+----------+
|initcap(a)|initcap(b)|initcap(c)|
+----------+----------+----------+
| Abc| Aaabb| |
+----------+----------+----------+
========== df.select(instr($"b", "aa")).show() ==========
+------------+
|instr(b, aa)|
+------------+
| 1|
+------------+
========== df.select(length($"a"), length($"b"), length($"c")).show() ==========
+---------+---------+---------+
|length(a)|length(b)|length(c)|
+---------+---------+---------+
| 3| 5| 0|
+---------+---------+---------+
========== df.select(lower($"b")).show() ==========
+--------+
|lower(b)|
+--------+
| aaabb|
+--------+
========== df.select(levenshtein($"a", $"b")).show() ==========
+-----------------+
|levenshtein(a, b)|
+-----------------+
| 4|
+-----------------+
========== df.select(locate("aa", $"b")).show() ==========
+----------------+
|locate(aa, b, 1)|
+----------------+
| 1|
+----------------+
========== df.select(locate("aa", $"b", 2)).show() ==========
+----------------+
|locate(aa, b, 2)|
+----------------+
| 2|
+----------------+
========== df.select(lpad($"a", 10, " ")).show() ==========
+--------------+
|lpad(a, 10, )|
+--------------+
| abc|
+--------------+
========== df.select(ltrim(lit(" 123"))).show() ==========
+-------------+
|ltrim( 123)|
+-------------+
| 123|
+-------------+
========== df.select(ltrim(lit("aaa123"), "a")).show() ==========
+---------------------------+
|TRIM(LEADING a FROM aaa123)|
+---------------------------+
| 123|
+---------------------------+
========== df.select(regexp_extract(lit("abc123"), "(\\d+)", 1)).show() ==========
+--------------------------------+
|regexp_extract(abc123, (\d+), 1)|
+--------------------------------+
| 123|
+--------------------------------+
========== df.select(regexp_replace(lit("abc123"), "(\\d+)", "num")).show() ==========
+-------------------------------------+
|regexp_replace(abc123, (\d+), num, 1)|
+-------------------------------------+
| abcnum|
+-------------------------------------+
========== df.select(regexp_replace(lit("abc123"), lit("(\\d+)"), lit("num"))).show() ==========
+-------------------------------------+
|regexp_replace(abc123, (\d+), num, 1)|
+-------------------------------------+
| abcnum|
+-------------------------------------+
========== df.select(unbase64(typedlit(Array[Byte](1, 2, 3, 4)))).show() ==========
+---------------------+
|unbase64(X'01020304')|
+---------------------+
| []|
+---------------------+
========== df.select(rpad($"a", 10, " ")).show() ==========
+--------------+
|rpad(a, 10, )|
+--------------+
| abc |
+--------------+
========== df.select(repeat($"a", 3)).show() ==========
+------------+
|repeat(a, 3)|
+------------+
| abcabcabc|
+------------+
========== df.select(rtrim(lit("123 "))).show() ==========
+-------------+
|rtrim(123 )|
+-------------+
| 123|
+-------------+
========== df.select(rtrim(lit("123aaa"), "a")).show() ==========
+----------------------------+
|TRIM(TRAILING a FROM 123aaa)|
+----------------------------+
| 123|
+----------------------------+
========== df.select(soundex($"a"), soundex($"b")).show() ==========
+----------+----------+
|soundex(a)|soundex(b)|
+----------+----------+
| A120| A100|
+----------+----------+
========== df.select(split(lit("a;b;c"), ";")).show() ==========
+-------------------+
|split(a;b;c, ;, -1)|
+-------------------+
| [a, b, c]|
+-------------------+
========== df.select(split(lit("a;b;c"), ";", 2)).show() ==========
+------------------+
|split(a;b;c, ;, 2)|
+------------------+
| [a, b;c]|
+------------------+
========== df.select(split(lit("a;b;c"), ";", 0)).show() ==========
+------------------+
|split(a;b;c, ;, 0)|
+------------------+
| [a, b, c]|
+------------------+
========== df.select(split(lit("a;b;c"), ";", -1)).show() ==========
+-------------------+
|split(a;b;c, ;, -1)|
+-------------------+
| [a, b, c]|
+-------------------+
========== df.select(substring(lit("abcdef"), 2, 5)).show() ==========
+-----------------------+
|substring(abcdef, 2, 5)|
+-----------------------+
| bcdef|
+-----------------------+
========== df.select(substring_index(lit("www.shockang.com"), ".", 2)).show() ==========
+---------------------------------------+
|substring_index(www.shockang.com, ., 2)|
+---------------------------------------+
| www.shockang|
+---------------------------------------+
========== df.select(overlay(lit("abcdef"), lit("abc"), lit(4), lit(1))).show() ==========
+--------------------------+
|overlay(abcdef, abc, 4, 1)|
+--------------------------+
| abcabcef|
+--------------------------+
========== df.select(overlay(lit("abcdef"), lit("abc"), lit(4))).show() ==========
+---------------------------+
|overlay(abcdef, abc, 4, -1)|
+---------------------------+
| abcabc|
+---------------------------+
========== df.select(sentences(lit("We all have a home called China"), lit("zh"), lit("CN"))).show() ==========
+---------------------------------------------+
|sentences(We all have a home called China, zh, CN)|
+---------------------------------------------+
| [[We all have a home, His name is China]]|
+---------------------------------------------+
========== df.select(sentences(lit("We all have a home called China"))).show() ==========
+-----------------------------------------+
|sentences(We all have a home called China, , )|
+-----------------------------------------+
| [[We all have a home, His name is China]]|
+-----------------------------------------+
========== df.select(translate(lit("abcdef"), "def", "123")).show() ==========
+---------------------------+
|translate(abcdef, def, 123)|
+---------------------------+
| abc123|
+---------------------------+
========== df.select(trim(lit(" abc "))).show() ==========
+---------------+
|trim( abc )|
+---------------+
| abc|
+---------------+
========== df.select(trim(lit("aaabcaaaa"), "a")).show() ==========
+---------------------------+
|TRIM(BOTH a FROM aaabcaaaa)|
+---------------------------+
| bc|
+---------------------------+
========== df.select(upper($"b")).show() ==========
+--------+
|upper(b)|
+--------+
| AAABB|
+--------+