Author: Liang hang Wanli database DBA is good at database performance problem diagnosis, transaction and lock problem analysis, is responsible for dealing with problems in the daily operation and maintenance of MySQL, and is very interested in open source database related technologies.
- The original content of GreatSQL community cannot be used without authorization. Please contact Xiaobian and indicate the source for reprint.
1, Phenomenon description
During troubleshooting, it was found that the active and standby MySQL services were switched, and it was normal to view the MySQL service. The DBA did not switch, and the server did not maintain. Fortunately, the business has not been greatly affected. Why on earth is this?
Assume that the original primary server address is 172.16 87.72, the address of the original and standby primary server is 172.16 87.123.
2, Troubleshooting ideas
View various indicators of MySQL through monitoring
View the keepalived service switching log
MySQL error log information
3, Troubleshooting
3.1 check MySQL monitoring indicators through the monitoring system to determine the specific time of failure (roughly determine the switching time point through traffic)
Through monitoring, check the monitoring indicators of the current main database MySQL (supporting business), and check the one-day and fifteen day (taking the query quantity rate per second as an example)
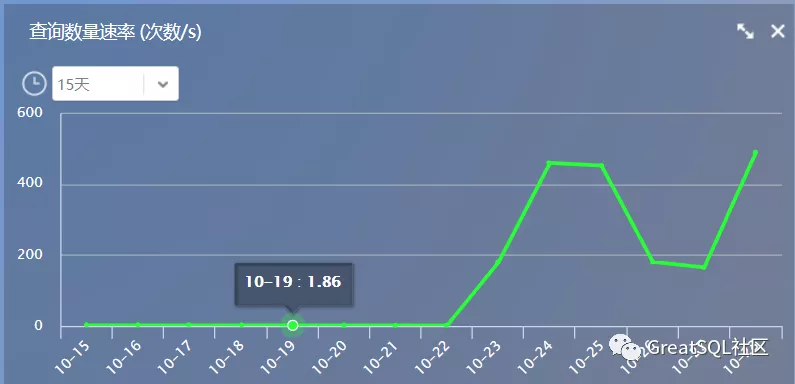
It is found that the number has increased sharply since the 22nd. It is preliminarily suspected that the master-slave switch may have occurred on the 22nd. Take a look at the broken line diagram of the standby database, and further confirm to check the dual enabled service switching log to determine the master-slave switching time
3.2 check keepalived to determine why master-slave switching occurs
Log in to 87.72 to view the keepalived switching log. The log information is as follows: Note: the system is ubuntu and keepalived does not specify the output log output, so keepalived will output the log to the system default log file syslog Log
shell> cat syslog.6|grep "vrrp" Oct 23 15:50:34 bjuc-mysql1 Keepalived_vrrp: VRRP_Script(check_mysql) failed Oct 23 15:50:34 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)' Oct 23 15:50:35 bjuc-mysql1 Keepalived_vrrp: VRRP_Instance(VI_74) Received higher prio advert Oct 23 15:50:35 bjuc-mysql1 Keepalived_vrrp: VRRP_Instance(VI_74) Entering BACKUP STATE Oct 23 15:50:35 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)' Oct 23 15:50:35 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)' Oct 23 15:50:35 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)' Oct 23 15:50:35 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)' Oct 23 15:50:56 bjuc-mysql1 Keepalived_vrrp: VRRP_Script(check_mysql) succeeded
Log analysis results
It can be found from the log that at Oct 23 15:50:34, the detection script failed to detect the MySQL service, resulting in vip switching. Then go to 87.123 to check the keepalived switching and determine the switching time
Oct 23 15:50:35 prod-UC-yewu-db-slave2 Keepalived_vrrp: VRRP_Instance(VI_74) forcing a new MASTER election Oct 23 15:50:36 prod-UC-yewu-db-slave2 Keepalived_vrrp: VRRP_Instance(VI_74) Transition to MASTER STATE Oct 23 15:50:37 prod-UC-yewu-db-slave2 Keepalived_vrrp: VRRP_Instance(VI_74) Entering MASTER STATE
Through the above log information, we found that the dual master switch occurred at Oct 23 15:50:35
3.3 questions? So why does the detection script fail?
View detection script content
shell> cat check_mysql.sh #!/bin/bash export PATH=$PATH:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin USER=xxx PASSWORD=xxx PORT=3306 IP=127.0.0.1 mysql --connect-timeout=1 -u$USER -p$PASSWORD -h$IP -P$PORT -e "select 1;" exit $?
We found that the detection script is very simple. Execute the "select 1" command with a timeout of 1s. This sql does not affect any MySQL operations and consumes little performance. Why does it fail? Let's go to MySQL and check the log to see if we find anything
3.4 viewing MySQL logs
191023 15:50:54 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress 191023 15:50:55 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress 191023 15:50:55 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress 191023 15:50:56 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress 191023 15:50:56 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress 191023 15:50:57 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress 191023 15:50:58 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress 191023 15:50:58 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress 191023 15:50:59 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress 191023 15:51:28 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE ticket SET max_id=max_id+step WHERE biz_tag='p2p_file'', Error_code: 1205 191023 15:54:43 [ERROR] Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable. 191023 15:54:43 [Warning] Slave: Lock wait timeout exceeded; try restarting transaction Error_code: 1205 191023 15:54:43 [ERROR] Error running query, slave SQL thread aborted. Fix the problem, and restart the slave SQL thread with "SLAVE START". We stopped at log 'mysql-bin.001432' position 973809430 191023 16:04:13 [ERROR] Error reading packet from server: Lost connection to MySQL server during query ( server_errno=2013) 191023 16:04:13 [Note] Slave I/O thread killed while reading event 191023 16:04:13 [Note] Slave I/O thread exiting, read up to log 'mysql-bin.001432', position 998926454 191023 16:04:20 [Note] Slave SQL thread initialized, starting replication in log 'mysql-bin.001432' at position 973809430, relay log './mysql-relay-bin.000188' position: 54422 191023 16:04:20 [Note] 'SQL_SLAVE_SKIP_COUNTER=1' executed at relay_log_file='./mysql-relay-bin.000188', relay_log_pos='54422', master_log_name='mysql-bin.001432', master_log_pos='973809430' and new position at relay_log_file='./mysql-relay-bin.000188', relay_log_pos='54661', master_log_name='mysql-bin.001432', master_log_pos='973809669' 191023 16:04:20 [Note] Slave I/O thread: connected to master 'zhu@x:3306',replication started in log 'mysql-bin.001432' at position 998926454
It can be found from the log that MySQL reported a Server shutdown in progress error at 15:50:54, the master-slave relationship hung up at 15:54:43, and the master-slave relationship automatically returned to normal at 16:04:20. So what is the error? What does Server shutdown in progress mean? This error message is because in MySQL 5.5, if you actively kill a long slow query, and the sql also uses the sort buffer, a situation similar to MySQL restart will occur, and the connection will be closed.
Official bug address: https://bugs.mysql.com/bug.php?id=18256
Hurry to the online environment to see if your environment is MySQL 5.5
mysql> \s -------------- mysql Ver 14.14 Distrib 5.5.22, for debian-linux-gnu (x86_64) using readline 6.2 Connection id: 76593111 Current database: Current user: xxx@127.0.0.1 SSL: Not in use Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 5.5.22-0ubuntu1-log (Ubuntu) Protocol version: 10 Connection: 127.0.0.1 via TCP/IP Server characterset: utf8 Db characterset: utf8 Client characterset: utf8 Conn. characterset: utf8 TCP port: 3306 Uptime: 462 days 11 hours 50 min 11 sec Threads: 9 Questions: 14266409536 Slow queries: 216936 Opens: 581411 Flush tables: 605 Open tables: 825 Queries per second avg: 357.022
We can see that the online environment is MySQL version 5.5, with a running time of 462 days 11 hours 50 min 11 sec, which proves that the MySQL process has not been restarted. Then, through the error log (master-slave relationship restart) just now, we verified the MySQL bug so, keepalived. In this case, we found that MySQL is unavailable, resulting in failed.
3.5 let's dig deeper. What causes slow sql to be kill ed?
We continue to find the slow log at the corresponding time point
# Time: 191023 15:50:39 # User@Host: dstatusnet[dstatusnet] @ [x] # Query_time: 35.571088 Lock_time: 0.742899 Rows_sent: 1 Rows_examined: 72 SET timestamp=1571817039; SELECT g.id,g.group_pinyin, g.external_type,g.external_group_id,g.mount_id,g.is_display as group_type,g.nickname,g.site_id,g.group_logo,g.created,g.modified,g.misc,g.name_update_flag as name_flag, g.logo_level,g.group_status,g.conversation, g.only_admin_invite,g.reach_limit_count,g.water_mark FROM user_group AS g LEFT JOIN group_member as gm ON g.id = gm.group_id WHERE g.is_display in (1,2,3) AND gm.profile_id = 7382782 AND gm.join_state != 2 AND UNIX_TIMESTAMP(g.modified) > 1571722305 ORDER BY g.modified ASC LIMIT 0, 1000; # User@Host: dstatusnet[dstatusnet] @ [x] # Query_time: 34.276504 Lock_time: 8.440094 Rows_sent: 1 Rows_examined: 1 SET timestamp=1571817039; SELECT conversation, is_display as group_type, group_status FROM user_group WHERE id=295414; # Time: 191023 15:50:40 # User@Host: dstatusnet[dstatusnet] @ [x] # Query_time: 31.410245 Lock_time: 0.561083 Rows_sent: 0 Rows_examined: 7 SET timestamp=1571817040; SELECT id, clientScope, msgTop FROM uc_application where site_id=106762 AND msgTop=1; # User@Host: dstatusnet[dstatusnet] @ [x] # Query_time: 38.442446 Lock_time: 2.762945 Rows_sent: 2 Rows_examined: 38 SET timestamp=1571817040; SELECT g.id,g.group_pinyin, g.external_type,g.external_group_id,g.mount_id,g.is_display as group_type,g.nickname,g.site_id,g.group_logo,g.created,g.modified,g.misc,g.name_update_flag as name_flag, g.logo_level,g.group_status,g.conversation, g.only_admin_invite,g.reach_limit_count,g.water_mark FROM user_group AS g LEFT JOIN group_member as gm ON g.id = gm.group_id WHERE g.is_display in (1,2,3) AND gm.profile_id = 9867566 AND gm.join_state != 2 AND UNIX_TIMESTAMP(g.modified) > 1571796860 ORDER BY g.modified ASC LIMIT 0, 1000; # Time: 191023 15:50:46 # User@Host: dstatusnet[dstatusnet] @ [x] # Query_time: 40.481602 Lock_time: 8.530303 Rows_sent: 0 Rows_examined: 1 SET timestamp=1571817046; update heartbeat set modify=1571817004 where session_id='89b480936c1384305e35b531221b705332a4aebf'; # Time: 191023 15:50:41 # User@Host: dstatusnet[dstatusnet] @ [x] # Query_time: 32.748755 Lock_time: 0.000140 Rows_sent: 0 Rows_examined: 3 SET timestamp=1571817041; SELECT id,nickname,mount_id,is_display,external_type,misc,site_id,conversation as conv_id,only_admin_invite,reach_limit_count,water_mark, group_logo,logo_level,created,modified,name_update_flag as name_flag, group_pinyin, group_status,external_group_id,event_id FROM user_group WHERE id in(1316262,1352179,1338753) AND UNIX_TIMESTAMP(modified) > 1571023021 ORDER BY created ASC; # Time: 191023 15:50:46 # User@Host: dstatusnet[dstatusnet] @ [x] # Query_time: 40.764872 Lock_time: 4.829707 Rows_sent: 0 Rows_examined: 7 SET timestamp=1571817046; SELECT id,nickname,mount_id,is_display,external_type,misc,site_id,conversation as conv_id,only_admin_invite,reach_limit_count,water_mark, group_logo,logo_level,created,modified,name_update_flag as name_flag, group_pinyin, group_status,external_group_id,event_id FROM user_group WHERE id in(673950,1261923,1261748,1262047,1038545,1184675,1261825) AND UNIX_TIMESTAMP(modified) > 1571744114 ORDER BY created ASC;
As shown above, it is found that this sql has been executed many times during this time period, and the time has exceeded 30~60s. This is a seriously slow sql
3.6 so what operation executes kill?
After inquiry and troubleshooting, it is found that we use the automatic killing function through Pt kill, and the configured query timeout is 30s
shell> ps -aux|grep 87.72 Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ root 3813 0.0 0.0 218988 8072 ? Ss Oct19 9:54 perl /usr/bin/pt-kill --busy-time 30 --interval 10 --match-command Query --ignore-user rep|repl|dba|ptkill --ignore-info 40001 SQL_NO_CACHE --victims all --print --kill --daemonize --charset utf8 --log=/tmp/ptkill.log.kill_____xxx_____172.16.87.72 -h172.16.87.72 -uxxxx -pxxxx shell> cat /tmp/ptkill.log.kill_____xxx_____172.16.87.72 2019-10-23T15:45:37 KILL 75278028 (Query 39 sec) statusnet SELECT t.conv_id, t.notice_id, t.thread_type, t.parent_conv_id, t.seq, t.reply_count, t.last_reply_seq1, t.last_reply_seq2, t.revocation_seq, t.creator_id, t.status, t.operator_id, t.extra1 FROM notice_thread t WHERE parent_conv_id = 3075773 and notice_id in (1571816367355,1571814620251,1571814611880,1571814601809,1571814589604,1571814578823,1571814568507,1571814559399,1571812785487,1571812769810) 2019-10-23T15:45:37 KILL 75277932 (Query 39 sec) statusnet SELECT t.conv_id, t.notice_id, t.thread_type, t.parent_conv_id, t.seq, t.reply_count, t.last_reply_seq1, t.last_reply_seq2, t.revocation_seq, t.creator_id, t.status, t.operator_id, t.extra1 FROM notice_thread t WHERE parent_conv_id = 6396698 and notice_id in (18606128) 2019-10-23T15:45:37 KILL 75191686 (Query 39 sec) statusnet SELECT id,nickname,mount_id,is_display,external_type,misc,site_id,conversation as conv_id,only_admin_invite,reach_limit_count,water_mark, group_logo,logo_level,created,modified,name_update_flag as name_flag, group_pinyin, group_status,external_group_id,event_id FROM user_group WHERE id in(988091,736931,843788,739447,737242,1252702,736180,1150776) AND UNIX_TIMESTAMP(modified) > 1571740050 ORDER BY created ASC
It was found that PT kill took the initiative to kill it. Combined with the previous discovery, the truth is already in front of us
3.7 why did the sql run for such a long time and report only this time?
Let's compare the slow logs of other times with the current time
# User@Host: dstatusnet[dstatusnet] @ [x] # Query_time: 2.046068 Lock_time: 0.000079 Rows_sent: 1 Rows_examined: 1 SET timestamp=1572306496; SELECT ... FROM user_group WHERE id in(693790) AND UNIX_TIMESTAMP(modified) > 0 ORDER BY created ASC;
We found a rule that when there id in (single value), it is basically two seconds. When there are multiple values, the time is not fixed. This conclusion needs to be further confirmed by other evidence
4, So how do we solve it?
Solutions and avoidance:
-
You can choose to upgrade the version of MySQL (the highest version of 5.7)
-
Optimize sql with business
Enjoy GreatSQL 😃
This article is composed of blog one article multi posting platform OpenWrite release!