Selected from medium com
By Carl M. Kadie
Machine heart compilation
Editors: Du Wei, Chen Ping
Just give it a try.
Python is one of the most popular programming languages for data scientists. It integrates high-quality analysis libraries, including NumPy, SciPy, natural language toolkit, etc. many of these libraries are implemented in C and C + +.
However, C and C + + have poor compatibility and do not provide thread safety per se. Some researchers began to turn to Rust and rewrite C + + extensions.
Carl M. Kadie, who has a doctorate in CS and machine learning, brought researchers nine rules for writing Python extensions in Rust by updating the bioinformatics package bed reader in Python. The following is the main content of the original blog.
A year ago, I was tired of the C + + extension of our software package bed reader. I rewritten it with Rust. Happily, the new extension is as fast as C/C + +, but has better compatibility and security. Along the way, I learned these nine rules, which can help you create better extension code. These nine rules {include:
1. Create a separate repository containing Rust and Python projects
2. Use mathurin & pyo3 to create Python label translator function in Rust
3. Let Rust translator function call nice Rust function
4. Pre allocate memory in Python
5. Translate nice Rust error handling to nice Python error handling
6. Multithreading with Rayon and ndarray::parallel returns any error
7. Allow the user to control the number of parallel threads
8. Translate nice dynamic type Python function into nice Rust generic function
9. Create Rust and Python tests
Among them, the word nice mentioned in this article refers to the creation of using best practices and native types. In other words: at the top of the code, write nice Python code; In the middle, use Rust to write translator code; At the bottom, write nice Rust code. The structure is shown in the figure below:

The above strategy may seem obvious, but following it can be tricky. This article provides practical advice and examples on how to follow each rule.
I experimented with bed reader, a Python package used to read and write PLINK Bed Files, a binary format used to store DNA data in bioinformatics. Files in bed format can reach TB. Bed reader allows users to access subsets of data quickly and randomly. It returns a NumPy array in int8, float32 or float64 selected by the user.
I hope the bed reader extension code has the following characteristics:
-
Faster than Python;
-
Compatible with NumPy;
-
Data parallel multithreading can be carried out;
-
Compatible with all other packages that execute data parallel multithreading;
-
Safe.
Our original C + + extension has the characteristics of high speed, NumPy compatibility, and data parallel multithreading using OpenMP. Unfortunately, the OpenMP runtime library has a Python package compatible version problem.
Rust provides the advantages of C + + extensions. In addition, rust solves the problem of runtime compatibility by providing data parallel multithreading without runtime library. In addition, the rust compiler ensures thread safety.
Creating Python extensions in Rust requires many design decisions. According to my experience in using bed reader, the following are my usage rules.
Rule 1: create a separate repository containing Rust and Python projects
The following table shows how to lay out a file:
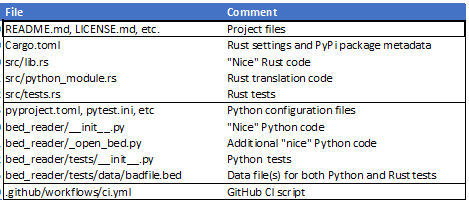
Use the 'cargo new' command commonly used by Rust to create a cargo Toml and Src / lib RS file. Python does not have setup Py file. Instead, cargo Toml contains PyPi package information, such as package name, version number, README file location, etc. To do this without setup Py, pyproject Toml must contain:
[build-system] requires = ["maturin==0.12.5"] build-backend = "maturin"
Generally speaking, Python is set up in pyproject In toml (if not, in files such as pytest.ini). The Python code is located in the subfolder bed_ In the reader.
Finally, we use GitHub operations to build, test, and prepare for deployment. The script is located at github/workflows/ci.yml.
Rule 2: use Maturin & pyo3 in Rust
Create Python callable translator function
Maturin is a PyPi package that can build and publish Python extensions through PyO3. PyO3 is a Rust crite for writing Python extensions in Rust.
In cargo Toml contains these Rust dependencies:
[dependencies]
thiserror = "1.0.30"
ndarray-npy = { version = "0.8.1", default-features = false }
rayon = "1.5.1"
numpy = "0.15.0"
ndarray = { version = "0.15.4", features = ["approx", "rayon"] }
pyo3 = { version = "0.15.1", features = ["extension-module"] }
[dev-dependencies]
temp_testdir = "0.2.3"
In Src / lib RS bottom, including these two lines:
mod python_module; mod tests;
Rule 3: Rust translator function
Call nice Rust function
In Src / lib RS defines nice} Rust functions, which will do the core work of the package. They can input and output standard Rust types and try to follow Rust best practices. For example, for bed reader packages, read_no_alloc is a nice Rust function that reads and returns values from the PLINK Bed file.
However, python cannot call these functions directly. Therefore, in the file src/python_module.rs defines the Rust translator function that Python can call. The following is an example of the translator function:
#[pyfn(m)]
#[pyo3(name = "read_f64")]
fn read_f64_py(
_py: Python<'_>,
filename: &str,
iid_count: usize,
sid_count: usize,
count_a1: bool,
iid_index: &PyArray1<usize>,
sid_index: &PyArray1<usize>,
val: &PyArray2<f64>,
num_threads: usize,
) -> Result<(), PyErr> {
let iid_index = iid_index.readonly();
let sid_index = sid_index.readonly();
let mut val = unsafe { val.as_array_mut() };
let ii = &iid_index.as_slice()?;
let si = &sid_index.as_slice()?;
create_pool(num_threads)?.install(|| {
read_no_alloc(
filename,
iid_count,
sid_count,
count_a1,
ii,
si,
f64::NAN,
&mut val,
)
})?;
Ok(())
}
This function takes the file name, some integers related to the file size, and two one-dimensional NumPy arrays as inputs, which indicate which subset of the data to read. This function reads the value from the file and fills in val, which is a pre allocated two-dimensional NumPy array.
be careful
Convert Python NumPy 1-D array to Rust slices by:
let iid_index = iid_index.readonly(); let ii = &iid_index.as_slice()?;
Convert a Python NumPy 2d array to a 2-D Rust ndarray object by:
let mut val = unsafe { val.as_array_mut() };
Call read_no_alloc, this is Src / lib A nice Rust function in RS will complete the core work.
Rule 4: pre allocate memory in Python
Pre allocating memory for results in Python simplifies Rust code. On the python side, on the bed_reader/_open_bed.py, we can import the Rust translator function:
from .bed_reader import [...] read_f64 [...]
Then define a nice Python function to allocate memory, call the Rust translator function, and return the result.
def read([...]):
[...]
val = np.zeros((len(iid_index), len(sid_index)), order=order, dtype=dtype)
[...]
reader = read_f64
[...]
reader(
str(self.filepath),
iid_count=self.iid_count,
sid_count=self.sid_count,
count_a1=self.count_A1,
iid_index=iid_index,
sid_index=sid_index,
val=val,
num_threads=num_threads,
)
[...]
return val
Rule 5: Translate nice Rust error handling to nice Python error handling
To learn how to handle errors, let's read_ no_ Two possible errors are tracked in alloc (nice Rust function in src/lib.rs).
Example error 1: error from standard function. If the standard File::open function of Rust cannot find the file or cannot open the file, in this case, in the following line? This will cause the function to return some std::io::Error values.
let mut buf_reader = BufReader::new(File::open(filename)?);
In order to define a function that can return these values, we can give the function a return type result < (), BedErrorPlus >. When defining BedErrorPlus, we should include all STD:: IO:: errors, as shown below:
use thiserror::Error;
...
/// BedErrorPlus enumerates all possible errors
/// returned by this library.
/// Based on https://nick.groenen.me/posts/rust-error-handling/#the-library-error-type
#[derive(Error, Debug)]
pub enum BedErrorPlus {
#[error(transparent)]
IOError(#[from] std::io::Error),
#[error(transparent)]
BedError(#[from] BedError),
#[error(transparent)]
ThreadPoolError(#[from] ThreadPoolBuildError),
}
This is nice Rust error handling, but Python doesn't understand it. Therefore, in Src / Python_ module. In RS, we need to translate. First, define the translator function read_f64_py to return PyErr; Secondly, a converter from BedErrorPlus to PyErr is implemented. The converter creates the correct Python error class (IOError, ValueError, or IndexError) with the correct error message. As follows:
impl std::convert::From<BedErrorPlus> for PyErr {
fn from(err: BedErrorPlus) -> PyErr {
match err {
BedErrorPlus::IOError(_) => PyIOError::new_err(err.to_string()),
BedErrorPlus::ThreadPoolError(_) => PyValueError::new_err(err.to_string()),
BedErrorPlus::BedError(BedError::IidIndexTooBig(_))
| BedErrorPlus::BedError(BedError::SidIndexTooBig(_))
| BedErrorPlus::BedError(BedError::IndexMismatch(_, _, _, _))
| BedErrorPlus::BedError(BedError::IndexesTooBigForFiles(_, _))
| BedErrorPlus::BedError(BedError::SubsetMismatch(_, _, _, _)) => {
PyIndexError::new_err(err.to_string())
}
_ => PyValueError::new_err(err.to_string()),
}
}
}
Example error 2: function specific error. If nice function read_no_alloc can open the file, but then realize that the file format is wrong? It should raise a custom error as follows:
if (BED_FILE_MAGIC1 != bytes_vector[0]) || (BED_FILE_MAGIC2 != bytes_vector[1]) {
return Err(BedError::IllFormed(filename.to_string()).into());
}
Bederror:: the custom error of illformed type is in Src / lib Defined in RS:
use thiserror::Error;
[...]
// https://docs.rs/thiserror/1.0.23/thiserror/
#[derive(Error, Debug, Clone)]
pub enum BedError {
#[error("Ill-formed BED file. BED file header is incorrect or length is wrong.'{0}'")]
IllFormed(String),
[...]
}
The remaining error handling is the same as in example error 1.
Finally, for Rust and Python, the results of both standard and custom errors belong to specific error types with informational error messages.
Rule 6: multithreading with Rayon and ndarray::parallel returns any errors
Rust Rayon crate provides simple and lightweight data parallel multithreading. The ndarray::parallel module applies Rayon to arrays. The usual pattern is to parallelize columns (or rows) across one or more 2D arrays. One challenge is to return any error messages from parallel threads. I'll focus on two ways to parallelize array operations through error handling. Both of the following examples appear in Src / lib. For bed reader RS file.
Method 1: par_bridge().try_for_each
Rayon's par_bridge turns sequential iterators into parallel iterators. If an error is encountered, use try_ for_ The each method can stop all processing as soon as possible.
In this example, we traverse two things compressed (zip) together:
-
Binary data of DNA location;
-
The columns of the output array.
Then, the binary data is read sequentially, but the data of each column is processed in parallel. We stopped making any mistakes.
[... not shown, read bytes for DNA location's data ...]
// Zip in the column of the output array
.zip(out_val.axis_iter_mut(nd::Axis(1)))
// In parallel, decompress the iid info and put it in its column
.par_bridge() // This seems faster that parallel zip
.try_for_each(|(bytes_vector_result, mut col)| {
match bytes_vector_result {
Err(e) => Err(e),
Ok(bytes_vector) => {
for out_iid_i in 0..out_iid_count {
let in_iid_i = iid_index[out_iid_i];
let i_div_4 = in_iid_i / 4;
let i_mod_4 = in_iid_i % 4;
let genotype_byte: u8 = (bytes_vector[i_div_4] >> (i_mod_4 * 2)) & 0x03;
col[out_iid_i] = from_two_bits_to_value[genotype_byte as usize];
}
Ok(())
}
}
})?;
Method 2: par_azip!
Par of ndarray package_ azip! Macros allow one or more arrays or array fragments to be compressed together in parallel. In my opinion, this is very readable. However, it does not directly support error handling. Therefore, we can add error handling by saving any errors to the result list.
Here is an example of a utility function. The complete utility function calculates Statistics (mean and variance) from three count and sum arrays and works in parallel. If an error is found in the data, the error is recorded in the result list. After all processing is completed, check the result list for errors.
[...]
let mut result_list: Vec<Result<(), BedError>> = vec![Ok(()); sid_count];
nd::par_azip!((mut stats_row in stats.axis_iter_mut(nd::Axis(0)),
&n_observed in &n_observed_array,
&sum_s in &sum_s_array,
&sum2_s in &sum2_s_array,
result_ptr in &mut result_list)
{
[...some code not shown...]
});
// Check the result list for errors
result_list.par_iter().try_for_each(|x| (*x).clone())?;
[...]
Rayon and ndarray::parallel provide many other good data parallel processing methods.
Rule 7: allow users to control the number of parallel threads
In order to make better use of the user's other code, the user must be able to control the number of parallel threads that can be used by each function.
In the nice Python read function below, the user can get an optional num_threadsargument. If the user does not set it, python will set it through this function:
def get_num_threads(num_threads=None):
if num_threads is not None:
return num_threads
if "PST_NUM_THREADS" in os.environ:
return int(os.environ["PST_NUM_THREADS"])
if "NUM_THREADS" in os.environ:
return int(os.environ["NUM_THREADS"])
if "MKL_NUM_THREADS" in os.environ:
return int(os.environ["MKL_NUM_THREADS"])
return multiprocessing.cpu_count()
Then on the Rust side, we can define create_pool. This auxiliary function starts from num_threads constructs a Rayon ThreadPool object.
pub fn create_pool(num_threads: usize) -> Result<rayon::ThreadPool, BedErrorPlus> {
match rayon::ThreadPoolBuilder::new()
.num_threads(num_threads)
.build()
{
Err(e) => Err(e.into()),
Ok(pool) => Ok(pool),
}
}
Finally, in the Rust translator function read_f64_py, we start from create_pool(num_threads)?.install(...) Internal call read_no_alloc (a good Rust function). This limits all Rayon functions to the num we set_ threads.
[...]
create_pool(num_threads)?.install(|| {
read_no_alloc(
filename,
[...]
)
})?;
[...]
Rule 8: Translate nice dynamically typed Python functions into nice Rust generic functions
The user of the nice Python read function can specify the dtype (int8, float32, or float64) of the returned NumPy array. From this selection, the function finds the appropriate Rust translator function (read_i8(_py), read_f32(_py) or read_f64(_py), and then call the function.
def read(
[...]
dtype: Optional[Union[type, str]] = "float32",
[...]
)
[...]
if dtype == np.int8:
reader = read_i8
elif dtype == np.float64:
reader = read_f64
elif dtype == np.float32:
reader = read_f32
else:
raise ValueError(
f"dtype'{val.dtype}'not known, only"
+ "'int8', 'float32', and 'float64' are allowed."
)
reader(
str(self.filepath),
[...]
)
The three Rust translator functions call the same Rust function, that is, in Src / lib Read defined in RS_ no_ alloc. The following is the translator function read_ 64 (also known as read_64_py):
#[pyfn(m)]
#[pyo3(name = "read_f64")]
fn read_f64_py(
[...]
val: &PyArray2<f64>,
num_threads: usize,
) -> Result<(), PyErr> {
[...]
let mut val = unsafe { val.as_array_mut() };
[...]
read_no_alloc(
[...]
f64::NAN,
&mut val,
)
[...]
}
We are in Src / lib Niceread is defined in rs_ no_ Alloc function. That is, the function applies to any type of TOut with the correct characteristics. The relevant parts of the code are as follows:
fn read_no_alloc<TOut: Copy + Default + From<i8> + Debug + Sync + Send>(
filename: &str,
[...]
missing_value: TOut,
val: &mut nd::ArrayViewMut2<'_, TOut>,
) -> Result<(), BedErrorPlus> {
[...]
}
Organizing code in nice Python, translator Rust and nice Rust allows us to provide Python users with dynamically typed code while still writing beautiful general-purpose code with Rust.
Rule 9: create Rust and Python tests
You may just want to write Python tests that call Rust. However, you should also write Rust tests. Adding Rust tests allows you to run tests interactively and debug interactively. The Rust test also provides a way for you to get the Rust version of the package in the future. In the sample project, both sets of tests are from {bed_reader/tests/data reads the test file.
Where feasible, I also recommend writing a pure Python version of the function, and then you can use these slow Python functions to test the results of the fast Rust function.
Finally, about CI scripts, such as bed reader / CI YML, you should run both Rust and Python tests.
Original link: https://towardsdatascience.com/nine-rules-for-writing-python-extensions-in-rust-d35ea3a4ec29